공동 저자: 틸 웨스트만, 엔지니어링 부문 선임 이사
소개
Couchbase Analytics는 Couchbase Server에서 제공되는 모든 서비스 중에서 "가장 최근에 출시된" 서비스입니다. 이 새로운 서비스는 배송, 장바구니 분석, 매장 상품 배치, 항공권 예약, 호텔 재고 등 다양한 사용 사례에서 빠른 시간 내에 인사이트를 제공합니다. 카우치베이스 서버는 가장 까다로운 사용 사례에서도 탁월한 성능을 제공하며, 분석 서비스에 대한 기대치도 이와 다르지 않습니다. 지난 몇 달 동안 다양한 배포 토폴로지에 Analytics를 배포한 고객을 위해 N1QL(JSON용 SQL) 쿼리를 최적화했습니다. "애널리틱스 쿼리 플랜을 어떻게 해석할 수 있나요?"라는 반복적인 요청에 따라 블로그 게시물 시리즈를 통해 애널리틱스 쿼리 플랜을 자세히 설명해 드리겠습니다.
이 블로그 게시물 1부에서는 실행 프레임워크에 대한 배경 지식을 제공한 다음 간단한 쿼리에 대한 계획을 설명합니다. 이 시리즈의 다음 블로그에서는 조인, 인덱스 액세스 및 집계를 포함한 보다 복잡한 쿼리에 대한 계획을 설명하겠습니다.
배경
Couchbase Analytics는 쿼리 및 인덱스 서비스에서 제공하는 기능을 보완하기 위해 Couchbase Server에 병렬 데이터 관리 기능을 추가합니다. Couchbase Analytics에는 전체 MPP(대규모 병렬 처리) 기반 쿼리 프로세서가 있어 단일 쿼리 처리 작업을 Couchbase 데이터 플랫폼 클러스터의 모든 Analytics 노드에서 분할 처리합니다. 따라서 애드혹 조인, 집합 집계 및 그룹화 작업과 같은 복잡한 분석 쿼리를 빠르고 확장 가능한 방식으로 실행할 수 있습니다.
아래 그림은 애널리틱스 엔진에서 쿼리가 처리되는 방식을 개념적으로 단순화한 것입니다. 이 그림은 단일 노드에서 일어나는 일을 나타내며 쿼리 엔진의 MPP 측면에 대한 세부 사항은 숨겨져 있습니다.
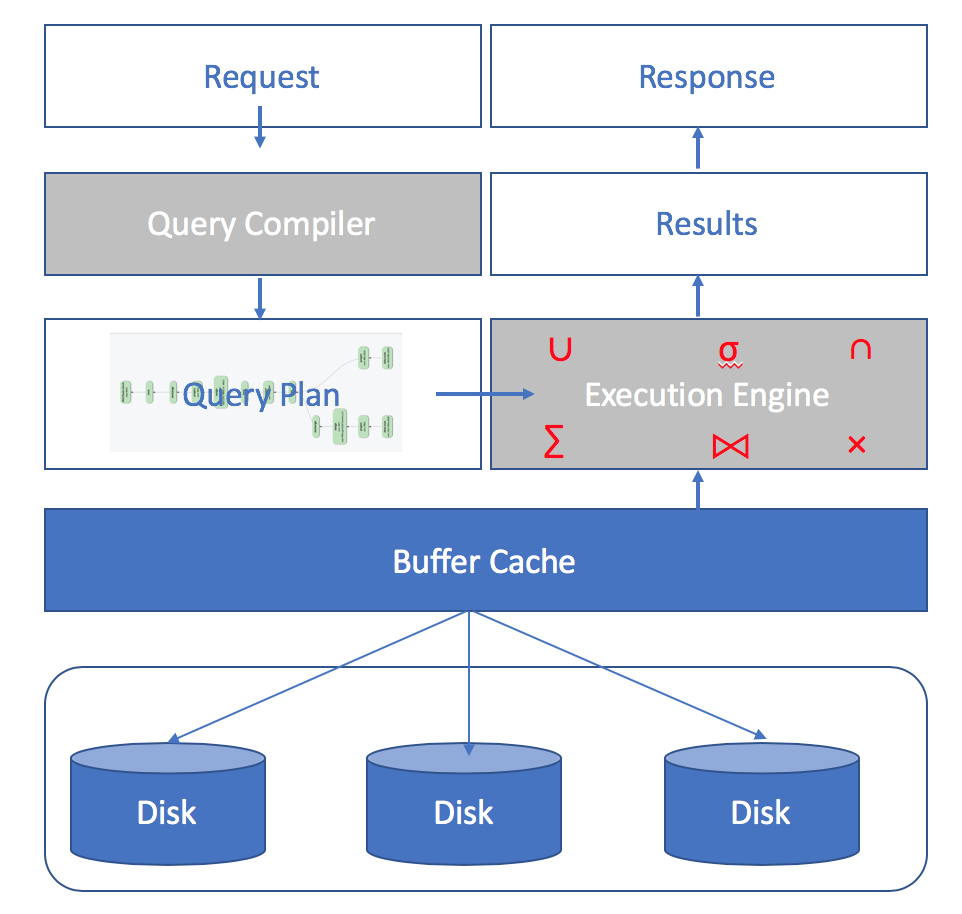
- 요청이 애널리틱스 서비스에 제출되고 인증이 완료되면 쿼리 문자열이 쿼리 컴파일러로 전달됩니다.
- 쿼리 컴파일러는 쿼리를 구문 분석하고 번역하여 최적화된 쿼리 플랜을 생성합니다. 쿼리 계획은 연산자와 커넥터의 트리(또는 DAG)입니다. 이러한 연산자는 관계형 데이터베이스의 관계형 대수 연산자와 유사합니다. 여기서 가장 큰 차이점은 Couchbase Analytics의 연산자가 중첩 및 스키마 없는 JSON 데이터도 처리할 수 있다는 것입니다. 자세한 내용은 이 블로그 게시물의 범위를 벗어난 것이지만, 이 블로그 게시물에서 자세한 내용을 확인할 수 있습니다. 비디오 프레젠테이션 카우치베이스 애널리틱스의 수석 아키텍트인 마이크 캐리 교수의 글입니다.
- 쿼리 계획은 쿼리 계획의 연산자를 평가하는 실행 엔진으로 전달됩니다. 분석은 빅데이터를 위해 설계되었으며 다음과 같은 작업을 원활하게 처리할 수 있습니다. 필요에 따라 메모리에서 디스크로 데이터를 흘려보낼 수 있습니다.
- 버퍼 캐시는 실행 엔진에서 디스크에서 저장된 데이터를 읽고 필요에 따라 더 빠르게 액세스할 수 있도록 메모리에 데이터를 캐시하는 데 사용됩니다.
- 실행 결과는 응답 핸들러로 전달됩니다.
- 그런 다음 응답 처리기는 결과를 클라이언트에 다시 전달합니다.
쿼리 계획
A 쿼리 계획은 실행 엔진을 통한 문서의 경로를 설명합니다. 계획의 작업은 각 적격 문서에 대해 실행됩니다.
아래에서 캘리포니아에 있는 모든 양조장의 이름을 선택하는 매우 간단한 쿼리를 통해 이를 설명해 보겠습니다.
|
1 2 3 |
select name from breweries where state=”California” |
계획을 읽는 가장 좋은 방법은 바텀업 방식입니다. 이를 통해 데이터 액세스 방식과 쿼리 실행을 위한 단계를 파악할 수 있습니다.
쿼리 요금제 연산자 설명
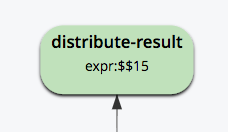 배포 결과: 쿼리 결과를 수신하는 계획의 루트입니다. 클라이언트가 결과를 요청하면(동기식 또는 비동기식) 각 노드에서 결과를 검색하여 클라이언트로 전송합니다.
배포 결과: 쿼리 결과를 수신하는 계획의 루트입니다. 클라이언트가 결과를 요청하면(동기식 또는 비동기식) 각 노드에서 결과를 검색하여 클라이언트로 전송합니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.
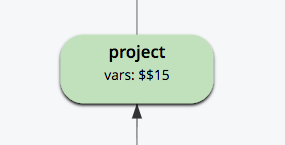
프로젝트: $$양조장 필드를 투사하고 $$15(양조장 이름 포함)를 유지합니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.
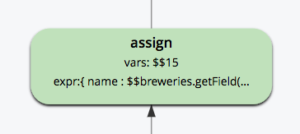
할당: 이 연산자는 하나 이상의 표현식을 평가합니다. 을 호출하여 결과를 새 변수에 할당합니다. 이 경우 "name" 키의 값은 변수 $15에 할당됩니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.

선택: 선택: 쿼리에 정의된 술어에 따라 일치하는 레코드를 선택합니다. 이 경우 '캘리포니아'에 속하는 양조장 레코드가 선택되고 나머지는 필터링됩니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.
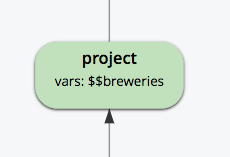
프로젝트: $$16과 $$17을 모두 투사하고 $$브루어리를 유지합니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.
 데이터 스캔: 데이터 집합 "breweries"에서 각 레코드를 읽습니다. "vars"는 이 작업의 결과로 생성되는 변수의 목록입니다. 각 레코드의 첫 번째 키는 $$16에 할당되고, 전체 레코드는 $$breweries에 할당되며, 일부 레코드 메타데이터는 $$17에 할당됩니다.
데이터 스캔: 데이터 집합 "breweries"에서 각 레코드를 읽습니다. "vars"는 이 작업의 결과로 생성되는 변수의 목록입니다. 각 레코드의 첫 번째 키는 $$16에 할당되고, 전체 레코드는 $$breweries에 할당되며, 일부 레코드 메타데이터는 $$17에 할당됩니다.
이것은 클러스터의 모든 노드에서 분할되는 병렬 작업입니다.
설명 계획은 Couchbase Server에서 실행 중인 분석 쿼리를 최적화하는 데 유용한 도구이며, 이 소개를 통해 계획을 이해하고 해석하는 데 도움이 될 것입니다. 최신 버전을 다운로드하여 직접 사용해 볼 수 있습니다. 카우치베이스 서버 6.5 에 접속하여 포럼 를 클릭해 질문에 대한 답변을 확인하세요.