소개
데이터베이스 시스템에는 세 가지 중요한 사항이 있습니다: 성능, 성능, 성능. NoSQL 데이터베이스 시스템에는 세 가지 중요한 사항이 있습니다: 규모에 맞는 성능, 규모에 맞는 성능, 규모에 맞는 성능.
인덱스 옵션을 이해하고, 올바른 키, 올바른 순서, 올바른 표현식을 사용하여 올바른 인덱스를 생성하는 것은 Couchbase에서 쿼리 성능과 규모에 맞는 성능을 발휘하는 데 매우 중요합니다. 다음 사항에 대해 논의했습니다. JSON용 데이터 모델링 그리고 JSON 쿼리 에 대해 설명했습니다. 이 글에서는 Couchbase에서 JSON에 대한 인덱싱 옵션에 대해 설명합니다.
Couchbase 5.0에는 세 가지 유형의 인덱스 카테고리가 있습니다. 각 카우치베이스 클러스터는 표준 글로벌 보조 인덱스 또는 메모리에 최적화된 글로벌 보조 인덱스 중 하나의 인덱스 카테고리만 가질 수 있습니다.
| 표준 보조: 릴리스 4.0 이상 |
|
| 메모리 최적화 지수: 4.5 이상 |
|
| 표준 보조: 릴리스 5.0 |
|
표준 보조 인덱스(4.0부터 4.6.x까지) 저장소는 ForestDB 스토리지 엔진을 사용해 B-Tree 인덱스를 저장하고 버퍼에 최적의 작업 데이터 세트를 유지합니다. 즉, 인덱스의 총 크기는 각 인덱스 노드에서 사용 가능한 메모리 양보다 훨씬 클 수 있습니다.
메모리 최적화 인덱스는 새로운 잠금 없는 스킵리스트를 사용해 인덱스를 유지하고 인덱스 데이터의 100%를 메모리에 보관합니다. 메모리 최적화 인덱스(MOI)는 인덱스 스캔 대기 시간이 더 짧고 데이터의 변형을 훨씬 더 빠르게 처리할 수 있습니다.
5.0의 표준 보조 인덱스는 엔터프라이즈 에디션의 플라즈마 스토리지 엔진을 사용하며, MOI와 같은 잠금 없는 스킵 목록을 사용하지만 메모리에 맞지 않는 대용량 인덱스를 지원합니다.
세 가지 유형의 인덱스는 모두 다중 버전 동시성 제어(MVCC)를 구현하여 일관된 인덱스 스캔 결과와 높은 처리량을 제공합니다. 클러스터 설치 중에 인덱스 유형을 선택합니다.
이 글의 목표는 쿼리를 효율적으로 실행할 수 있도록 각 서비스에서 생성하는 다양한 인덱스에 대한 개요를 제공하는 것입니다. 이 글의 목표는 이 두 가지 유형의 인덱스 서비스를 설명하거나 비교 및 대조하는 것이 아닙니다. Couchbase 5.0에서 출시된 전체 텍스트 검색 인덱스(FTS)는 다루지 않습니다.
이제 여행 샘플 데이터 집합을 만들고 이러한 인덱스를 사용해 보세요.
웹 콘솔에서 다음 주소로 이동합니다. 설정->샘플 버킷 를 클릭하여 여행 샘플을 설치합니다.
다음은 생성할 수 있는 다양한 인덱스입니다.
- 기본 색인
- 명명된 기본 인덱스
- 보조 색인
- 복합 보조 인덱스
- 기능 색인
- 배열 색인
- ALL 배열
- 모든 고유 배열
- 부분 색인
- 적응형 인덱스
- 중복 인덱스
- 커버링 인덱스
배경
카우치베이스는 분산형 데이터베이스입니다. JSON을 사용하는 유연한 데이터 모델을 지원합니다. 버킷의 각 문서에는 사용자가 생성한 고유 문서 키가 있습니다. 이 고유성은 데이터를 삽입하는 동안 적용됩니다.
다음은 문서 예시입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id, travel FROM `travel-sample` travel WHERE type = 'airline' limit 1; [ { "id": "airline_10", "travel": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ] |
인덱스 유형
1. 기본 색인
에 기본 인덱스를 생성합니다. 'travel-sample':
기본 인덱스는 단순히 전체 버킷의 문서 키에 대한 인덱스입니다. Couchbase 데이터 계층은 문서 키에 고유성 제약 조건을 적용합니다. 기본 인덱스는 Couchbase의 다른 모든 인덱스와 마찬가지로 비동기적으로 유지됩니다. 데이터의 최신성을 설정하는 방법은 일관성 수준 를 입력하세요.
이 인덱스의 메타데이터는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM system:indexes WHERE name = ‘#primary’; "indexes": { "datastore_id": "https://127.0.0.1:8091", "id": "f6e3c75d6f396e7d", "index_key": [], "is_primary": true, "keyspace_id": "travel-sample", "name": "#primary", "namespace_id": "default", "state": "online", "using": "gsi" } |
메타데이터는 인덱스에 대한 추가 정보를 제공합니다: 인덱스가 있는 위치(datastore_id), 인덱스의 상태(state), 인덱싱 방법(사용) 등입니다.
기본 인덱스는 쿼리에 필터(술어)가 없거나 다른 인덱스 또는 액세스 경로를 사용할 수 있는 경우 전체 버킷 스캔(기본 스캔)에 사용됩니다. Couchbase에서는 여러 키 스페이스(서로 다른 유형의 문서, 고객, 주문, 재고 등)를 하나의 버킷에 저장합니다. 따라서 기본 스캔을 수행할 때 쿼리는 색인을 사용하여 문서 키를 가져오고 버킷에 있는 모든 문서를 가져온 다음 필터를 적용합니다. 이것은 매우 비용이 많이 듭니다.
문서 키 디자인은 여러 부분으로 구성된 기본 키 디자인과 다소 유사합니다.
Lastname:firstname:customerid
Example: smith:john:X1A1849
Couchbase에서는 키 앞에 문서 유형을 접두사로 붙이는 것이 가장 좋습니다. 이 문서는 고객 문서이므로 접두사 앞에 CX를 붙이겠습니다. 이제 키는 다음과 같습니다:
|
1 |
Example: CX:smith:john:X1A1849 |
따라서 같은 버킷에 다른 유형의 문서가 있을 수 있습니다.
|
1 |
ORDERS type: OD:US:CA:294829 |
|
1 |
ITEMS type: IT:KD93823 |
이는 모범 사례일 뿐입니다. 버킷 내에서 고유해야 한다는 점을 제외하면 Couchbase에서 문서 키의 형식이나 구조에는 제한이 없습니다.
이제 다양한 키가 있는 문서가 있고 기본 색인이 있는 경우 다음 쿼리를 효율적으로 사용할 수 있습니다.
예 1: 특정 문서 키를 찾고 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE META().id = “CX:smith:john:X1A1849”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smith:john:X1A1849\"", "inclusion": 3, "low": "\"CX:smith:john:X1A1849\"" } ] } ], } |
전체 문서 키를 알고 있는 경우 다음 문을 사용하여 인덱스 액세스를 완전히 피할 수 있습니다.
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”]
명세서에 두 개 이상의 문서를 넣을 수 있습니다.
|
1 |
SELECT * FROM sales USE KEYS [“CX:smith:john:X1A1849”, “CX:smithjr:john:X2A1492”] |
예 2: 패턴을 찾습니다. 모든 고객 문서를 가져옵니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE “CX:%”; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX;\"", "inclusion": 1, "low": "\"CX:\"" }" ] } ], } |
예 3: 모든 고객을 다음과 같이 확보하세요. "smith" 를 성으로 사용합니다.
다음 쿼리는 기본 인덱스를 효율적으로 사용하여 특정 범위의 고객만 가져옵니다. 참고: 이 스캔은 대소문자를 구분합니다. 대소문자를 구분하지 않는 스캔을 수행하려면 문서 키의 UPPER() 또는 LOWER()를 사용하여 보조 인덱스를 만들 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT * FROM sales WHERE META().id LIKE "CX:smith%"; { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CX:smiti\"", "inclusion": 1, "low": "\"CX:smith\"" } ] } ], } |
예 4: 일부 애플리케이션에서는 이메일 주소가 고유 값이기 때문에 문서의 일부로 사용하는 것이 일반적입니다. 이 경우 "@gmail.com"을 사용하는 모든 고객을 찾아야 합니다. 이것이 일반적인 요구 사항이라면 이메일 주소의 역방향을 키로 저장하고 선행 문자열 패턴을 스캔하기만 하면 됩니다.
Email:johnsmith@gmail.com; key: reverse("johnsmith@gmail.com") => moc.liamg@htimsnhoj
Email: janesnow@yahoo.com key: reverse("janesnow@yahoo.com") => moc.oohay@wonsenaj
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT * FROM sales WHERE meta().id LIKE (reverse("@yahoo.com") || "%"); { "#operator": "IndexScan2", "index": "#primary", "index_id": "4c92ab0bcca9690a", "keyspace": "sales", "namespace": "default", "spans": [ { "range": [ { "high": "\"moc.oohayA\"", "inclusion": 1, "low": "\"moc.oohay@\"" } ] } ], } |
2. 명명된 기본 색인
Couchbase 5.0에서는 간단한 매개변수인 CREATE INDEX를 사용하여 인덱스의 복제본을 여러 개 만들 수 있습니다. 다음은 인덱스의 복사본 3개를 생성하며 클러스터에 최소 3개의 인덱스 노드가 있어야 합니다.
|
1 2 |
CREATE PRIMARY INDEX ON 'travel-sample' WITH {"num_replica":2}; CREATE PRIMARY INDEX `def_primary` ON `travel-sample` ; |
기본 인덱스의 이름을 지정할 수도 있습니다. 기본 인덱스의 나머지 기능은 인덱스 이름을 제외하고는 동일합니다. 이 기능의 좋은 점은 5.0 이전 Couchbase 버전에서 서로 다른 이름을 사용하여 여러 개의 기본 인덱스를 가질 수 있다는 것입니다. 중복 인덱스는 고가용성뿐만 아니라 인덱스 전체에 쿼리 부하를 분산하는 데 도움이 됩니다. 이는 기본 인덱스와 보조 인덱스 모두에 해당됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT meta().id as documentkey, `travel-sample` airline FROM `travel-sample` WHERE type = 'airline' limit 1; { "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
3. 보조 색인
보조 인덱스는 모든 키-값 또는 문서-키에 대한 인덱스입니다. 이 인덱스는 문서 내의 모든 키가 될 수 있습니다. 키는 스칼라, 객체, 배열 등 어떤 것이든 될 수 있습니다. 쿼리는 인덱스를 활용하기 위해 쿼리 엔진과 동일한 유형의 객체를 사용해야 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE INDEX travel_name ON `travel-sample`(name); name is a simple scalar value. { "name": "Air France" } CREATE INDEX travel_geo on `travel-sample`(geo); geo is an object embedded within the document. Example: "geo": { "alt": 12, "lat": 50.962097, "lon": 1.954764 } Creating indexes on keys from nested objects is straightforward. CREATE INDEX travel_geo on `travel-sample`(geo.alt); CREATE INDEX travel_geo on `travel-sample`(geo.lat); |
스케줄 필드는 항공편 세부 정보가 포함된 객체 배열입니다. 전체 배열을 인덱싱합니다. 전체 배열을 찾는 경우가 아니라면 유용하지 않습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE INDEX travel_schedule ON `travel-sample`(schedule); Example: "schedule": [ { "day": 0, "flight": "AF198", "utc": "10:13:00" }, { "day": 0, "flight": "AF547", "utc": "19:14:00" }, { "day": 0, "flight": "AF943", "utc": "01:31:00" }, { "day": 1, "flight": "AF356", "utc": "12:40:00" }, { "day": 1, "flight": "AF480", "utc": "08:58:00" }, { "day": 1, "flight": "AF250", "utc": "12:59:00" } ] |
4. 복합 보조 인덱스
여러 개의 필터(술어)가 있는 쿼리를 사용하는 것이 일반적입니다. 따라서 인덱스가 한정된 문서 키만 반환할 수 있도록 여러 개의 키가 있는 인덱스가 필요합니다. 또한 쿼리가 인덱스의 키만 참조하는 경우, 쿼리 엔진은 데이터 노드로 이동하지 않고 인덱스 스캔 결과에서 쿼리에 간단히 응답합니다. 이것은 일반적으로 악용되는 성능 최적화 방법입니다.
|
1 |
CREATE INDEX idx_stctln ON `travel-sample` (state, city, name.lastname) |
각 키는 단순한 스칼라 필드, 객체 또는 배열일 수 있습니다. 인덱스 필터링을 활용하려면 필터가 쿼리 필터에서 해당 객체 유형을 사용해야 합니다. 인덱스에서 필터링해야 하는 경우 보조 인덱스의 키에 문서 키(meta().id)를 명시적으로 포함할 수 있습니다.
인덱스를 악용하는 쿼리와 악용할 수 없는 쿼리를 살펴보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
1.SELECT * FROM `travel-sample` WHERE state = 'CA'; The predicate matches the leading key of the index. So, this query uses the index to fully evaluate the predicate (state = ‘CA’). 2.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor'; The predicates match the leading two keys. So this is good fit as well. 3.SELECT * FROM `travel-sample` WHERE state = 'CA' AND city = 'Windsor' AND name.lastname = 'smith'; The three predicates in this query matches the three index keys perfectly. So, this is a good match. 4.SELECT * FROM `travel-sample` WHERE city = 'Windsor' AND name.lastname = 'smith'; In this query, although predicates match two of the index keys, the leading key isn’t matched. So, the index cannot and is not used for this query plans. 5.SELECT * FROM `travel-sample` WHERE name.lastname = 'smith'; Similar to previous query, this query has the predicate on the third key of the index. So, this index cannot be used. 6.SELECT * FROM `travel-sample` WHERE state = 'CA' AND name.lastname = 'smith'; This query has predicate on first and the third key. While this index is and can be chosen, we cannot push down the predicate after skipping an index key (second key in this case). So, only the first predicate (state = "CA") will be pushed down to index scan. "#operator": "IndexScan2", "index": "idx_stctln", "index_id": "dadbb12da565ed28", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" } ] } 7.SELECT * FROM `travel-sample` WHERE state IS NOT MISSING AND city = 'Windsor' AND name.lastname = 'smith'; This is a modified version of query 4 above. To use this index, the query needs to have an additional predicate (state IS NOT MISSING) assuming that represents your application requirement. |
5. 기능(표현식) 색인
데이터베이스에 대문자와 소문자가 혼합된 이름이 있는 것이 일반적입니다. 'John'을 검색해야 하는 경우 'John', 'john' 등의 모든 조합을 검색해야 합니다. 검색 방법은 다음과 같습니다.
CREATE INDEX travel_cxname ON `travel-sample`(LOWER(name));
검색 문자열을 소문자로 입력하면 인덱스에서 이미 소문자로 입력된 값을 효율적으로 검색합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLAIN SELECT * FROM `travel-sample` WHERE LOWER(name) = "john"; { "#operator": "IndexScan", "index": "travel_cxname", "index_id": "2f39d3b7aac6bbfe", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "\"john\"" ], "Inclusion": 3, "Low": [ "\"john\"" ] } } ] } |
이 함수 인덱스에서는 복잡한 표현식을 사용할 수 있습니다.
CREATE INDEX travel_cx1 ON `travel-sample`(LOWER(name), length*width, round(salary));
또한 다음 섹션에서 배열을 반환하는 표현식에서 배열 인덱스를 만들 수 있다는 것을 알게 될 것입니다.
6. 배열 색인
JSON은 계층적입니다. 최상위 수준에는 스칼라 필드, 객체 또는 배열이 있을 수 있습니다. 각 객체는 다른 객체와 배열을 중첩할 수 있습니다. 각 배열은 다른 객체와 배열을 가질 수 있습니다. 등등. 중첩은 계속됩니다.
이렇게 풍부한 구조가 있는 경우 하위 개체 내에서 특정 배열이나 필드를 색인하는 방법은 다음과 같습니다.
배열, 일정을 고려하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
schedule: [ { "day" : 0, "special_flights" : [ { "flight" : "AI111", "utc" : ”1:11:11" }, { "flight" : "AI222", "utc" : ”2:22:22" } ] }, { "day": 1, "flight": "AF552", "utc": "14:41:00” } ] CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END) |
이 인덱스 키는 인덱싱할 요소만 명확하게 참조하기 위한 배열의 표현식입니다. schedule은 우리가 역참조하는 배열입니다. v는 배열 내의 각 요소/객체를 참조하도록 암시적으로 선언한 변수입니다. schedule v.day는 배열 schedule의 각 객체 내의 요소를 참조합니다.
아래 쿼리는 배열 인덱스를 활용합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
EXPLAIN SELECT * FROM `travel-sample` WHERE ANY v IN SCHEDULE SATISFIES v.day = 2 END; { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan", "index": "travel_sched", "index_id": "db7018bff5f10f17", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ "2" ], "Inclusion": 3, "Low": [ "2" ] } } ], "using": "gsi" } |
키는 일반화된 표현식이므로 인덱싱하기 전에 데이터에 추가 로직과 처리를 유연하게 적용할 수 있습니다. 예를 들어, 각 배열의 요소에 함수형 인덱싱을 생성할 수 있습니다. 배열 내의 객체 또는 요소의 개별 필드를 참조하기 때문에 인덱스 생성크기 및 검색이 효율적입니다. 위의 인덱스는 배열 내의 고유 값만 저장합니다. 배열의 모든 요소를 인덱스에 저장하려면 표현식에 DISTINCT 수정자를 사용합니다.
CREATE INDEX travel_sched ON `travel-sample` (ALL DISTINCT ARRAY v.day FOR v IN schedule END)
배열 인덱스는 위와 같이 정적 값 또는 배열을 반환하는 표현식으로 만들 수 있습니다. TOKENS() 는 객체에서 토큰 배열을 반환하는 표현식 중 하나입니다. 이 배열에 인덱스를 생성하고 인덱스를 사용하여 검색할 수 있습니다.
Couchbase 5.0에서는 배열 인덱스를 더 간단하게 생성하고 일치시킬 수 있습니다. 키에 ALL(또는 ALL DISTINCT) 접두사를 제공하면 배열 키가 됩니다.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx_cx6 ON `travel-sample`(ALL TOKENS(public_likes)) WHERE type = ‘hotel’; SELECT t.name, t.country, t.public_likes FROM `travel-sample` t WHERE t.type = 'hotel’ AND ANY p IN TOKENS(public_likes) SATISFIES p = 'Vallie' END; |
배열 인덱스는 배열의 배열 내 요소에도 만들 수 있습니다. 배열 표현식의 중첩 수준에는 제한이 없습니다. 쿼리 표현식은 인덱스 표현식과 일치해야 합니다.
7. 부분 색인
지금까지 만든 인덱스는 전체 버킷에 대한 인덱스를 생성합니다. 카우치베이스 데이터 모델은 JSON이고 JSON 스키마는 유연하기 때문에 인덱스에 인덱스 키가 없는 문서에 대한 항목이 포함되지 않을 수 있습니다. 이는 예상되는 일입니다. 각 유형의 행이 별개의 테이블에 있는 관계형 시스템과 달리, 카우치베이스 버킷에는 다양한 유형의 문서가 있을 수 있습니다. 일반적으로 고객은 고유한 유형을 구분하기 위해 유형 필드를 포함합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "airline": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" }, "documentkey": "airline_10" } |
항공사 문서의 색인을 만들려면 색인의 WHERE 절에 유형 필드를 추가하기만 하면 됩니다.
CREATE INDEX travel_info ON `travel-sample`(name, id, icoo, iata) WHERE type = 'airline';
이렇게 하면 (유형 = '항공사')가 있는 문서에만 인덱스가 생성됩니다. 쿼리에서 다른 필터와 함께 필터(유형 = '항공사')를 포함해야 이 인덱스가 자격을 갖추게 됩니다.
인덱스의 WHERE 절에서 복잡한 술어를 사용할 수 있습니다. 부분 인덱스를 활용하는 다양한 사용 사례가 있습니다:
- 모드 함수를 사용하여 큰 인덱스를 여러 인덱스로 분할합니다.
- 큰 인덱스를 여러 인덱스로 분할하고 각 인덱스를 별개의 인덱서 노드에 배치합니다.
- 값 목록을 기반으로 인덱스를 분할합니다. 예를 들어 각 주에 대한 인덱스를 가질 수 있습니다.
- WHERE 절의 범위 필터를 통해 인덱스 범위 분할을 시뮬레이션합니다. 한 가지 기억해야 할 것은 Couchbase N1QL 쿼리는 쿼리 블록당 하나의 분할된 인덱스를 사용한다는 것입니다. 쿼리가 단일 쿼리에서 여러 분할된 인덱스를 활용하도록 하려면 UNION ALL을 사용하세요.
8. 적응형 인덱스
적응형 인덱스는 전체 문서 또는 문서 내 필드 집합에 단일 인덱스를 생성합니다. 이것은 {"key": value} 쌍을 단일 인덱스 키로 사용하는 폼 또는 배열 인덱스입니다. 그 목적은 쿼리가 기존 인덱스에서 인덱스의 선행 키와 일치해야 하는 번거로움을 피하기 위한 것입니다.
적응형 인덱스에는 두 가지 장점이 있습니다:
- 키 공간의 여러 술어는 동일한 인덱스의 다른 섹션을 사용하여 평가할 수 있습니다.
- 인덱스 키를 재정렬하기 위해 인덱스를 여러 개 만들지 마세요.
- 인덱스 키 순서를 피하세요.
예시:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX `ai_self` ON `travel-sample`(DISTINCT PAIRS(ai_self)) WHERE type = "airport"; EXPLAIN SELECT * FROM `travel-sample` WHERE faa = "SFO" AND `type` = "airport"; { "#operator": "IntersectScan", "scans": [ { "#operator": "IndexScan2", "index": "ai_self", "index_id": "c564a55225d9244c", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "[\"faa\", \"SFO\"]", "inclusion": 3, "low": "[\"faa\", \"SFO\"]" } ] } ], "using": "gsi" } ... ] } |
다른 술어가 포함된 쿼리에도 동일한 인덱스를 사용할 수 있습니다. 이렇게 하면 문서가 커짐에 따라 생성해야 하는 인덱스의 수를 줄일 수 있습니다.
|
1 2 3 4 |
EXPLAIN SELECT * FROM `travel-sample` WHERE city = "Seattle" AND `type` = "airport"; |
사용 시 고려 사항
- 각 속성 필드에는 인덱스 항목이 있으므로 인덱스의 크기가 매우 클 수 있습니다.
- 적응형 인덱스는 배열 인덱스입니다. 배열 인덱스의 제한에 묶여 있습니다.
자세한 내용은 다음 문서를 참조하세요. 적응형 인덱스 를 참조하세요.
9. 중복 색인
이것은 실제로 특별한 유형의 인덱스가 아니라 Couchbase 인덱싱의 기능입니다. 고유한 이름을 가진 중복 인덱스를 만들 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i2 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; CREATE INDEX i3 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’; |
세 인덱스 모두 동일한 키, 동일한 WHERE 절을 가지고 있으며 유일한 차이점은 인덱스의 이름입니다. CREATE INDEX의 WITH 절을 사용하여 실제 위치를 선택할 수 있습니다. 쿼리 최적화 중에 쿼리는 이름 중 하나를 선택합니다. 계획에서 이를 확인할 수 있습니다. 쿼리 런타임 중에 이러한 인덱스는 로드를 분산하기 위해 라운드 로빈 방식으로 사용됩니다. 이를 통해 스케일 아웃, 다차원 확장, 성능 및 고가용성을 제공합니다. 나쁘지 않죠!
Couchbase 5.0에서는 중복 인덱스가 더 간단해졌습니다. 고유한 이름을 가진 인덱스를 여러 개 생성하는 대신 필요한 복제 인덱스의 수만 지정하면 됩니다.
|
1 2 3 4 |
CREATE INDEX i1 ON `travel-sample`(LOWER(name),id, icoo) WHERE type = ‘airline’ WITH {"num_replica" : 2 }; |
이렇게 하면 인덱스 i1 외에 2개의 인덱스 복사본이 추가로 생성됩니다. 로드 밸런싱 및 HA 기능은 동등한 인덱스와 동일합니다.
10. 커버링 인덱스
쿼리에 대한 인덱스 선택은 전적으로 쿼리의 WHERE 절에 있는 필터에 따라 달라집니다. 인덱스 선택이 완료되면 엔진은 쿼리를 분석하여 인덱스의 데이터만 사용하여 답변할 수 있는지 확인합니다. 가능하다면 쿼리 엔진은 전체 문서 검색을 건너뜁니다. 이것은 인덱스를 설계할 때 고려해야 할 성능 최적화입니다.
지금 모두 함께!
이제 분할된 복합 함수형 배열 인덱스를 조합해 보겠습니다!
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX travel_all ON `travel-sample`( iata, LOWER(name), UPPER(callsign), ALL DISTINCT ARRAY p.model FOR p IN jets END), TO_NUMBER(rating), meta().id ) WHERE LOWER(country) = "united states" AND type = "airline" WITH {"num_replica" : 2} |
인덱스 생성 규칙.
지금까지 인덱스의 유형에 대해 살펴보았습니다. 이제 워크로드에 맞는 인덱스를 설계하는 방법을 살펴보겠습니다.
규칙 #1: 키 사용
카우치베이스에서 버킷의 각 문서에는 사용자가 생성한 고유 키가 있습니다. 문서는 이 키를 해싱하여 여러 노드에 분산됩니다( 일관된 해싱). 문서 키가 있으면 애플리케이션에서 직접 문서를 가져올 수 있습니다(SDK를 통해). 문서 키가 있더라도 N1QL을 통해 문서를 가져오고 일부 후처리를 하고 싶을 수도 있습니다. 이때는 USE KEYS 메서드를 사용합니다.

예시:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT name, address FROM `travel-sample` h USE KEYS [ "hotel_10025", "hotel_10026", "hotel_10063", "hotel_10064", "hotel_10138", "hotel_10142", "hotel_10158", "hotel_10159", "hotel_10160", "hotel_10161", "hotel_10180", "hotel_10289", "hotel_10290", "hotel_10291", "hotel_1072", "hotel_10848", "hotel_10849", "hotel_10850", "hotel_10851", "hotel_10904" ] WHERE h.country = "United Kingdom" AND ARRAY_LENGTH(public_likes) > 3; |
USE KEYS 액세스 방법은 조인할 때도 사용할 수 있습니다. 다음은 예시입니다:
SELECT * FROM ORDERS o USE KEYS ["ord::382"] INNER JOIN CUSTOMER c ON KEYS o.id;
카우치새 5.0에서 인덱스는 각 FROM 절의 첫 번째 키공간(버킷)을 처리하는 데만 사용됩니다. 그 이후의 키 공간은 문서를 직접 가져와서 처리합니다.
SELECT * FROM ORDERS o INNER JOIN CUSTOMER c ON KEYS o.id WHERE o.state = "CA";
이 문에서는 사용 가능한 경우 인덱스 온(상태)을 통해 ORDERS 키스페이스를 처리합니다. 그렇지 않으면 기본 인덱스를 사용하여 ORDERS를 스캔합니다. 그런 다음 ORDERS 문서에서 ID와 일치하는 CUSTOMER 문서를 가져옵니다.
규칙 #2: 커버링 인덱스 사용
이 글의 앞부분에서 인덱스 유형에 대해 설명했습니다. 올바른 인덱스는 두 가지 용도로 사용됩니다:
- 쿼리 작업 집합을 줄여 쿼리 성능 속도 향상
- 추가 데이터도 저장하고 제공하세요.
인덱스에 저장된 데이터로 쿼리에 대한 답을 완전히 얻을 수 있는 경우, 쿼리는 다음과 같다고 합니다. 커버 에 의해 커버링 인덱스. 쿼리의 전부는 아니더라도 대부분을 포함하도록 해야 합니다. 이렇게 하면 쿼리 서비스의 처리 부담이 줄어들고 데이터 서비스에서 추가로 가져오는 작업이 줄어듭니다.
인덱스 선택은 여전히 쿼리의 술어를 기반으로 수행됩니다. 인덱스 선택이 완료되면 옵티마이저는 인덱스에 쿼리에 필요한 모든 속성이 포함되어 있는지 평가하고 커버된 인덱스 경로 액세스를 생성합니다.
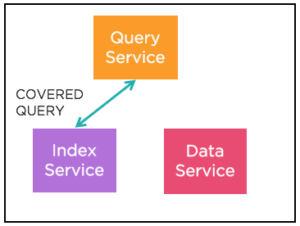
예시:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE INDEX idx_cx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; /* The query below won’t be covered since you said: SELECT * */ SELECT * FROM CUSTOMER WHERE state = 'CA’ AND status = 'premium'; /* The index has all three fields required by the query. */ /* Query will be covered, as shown in the explain plan. */ SELECT status, state, city FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; { "#operator": "IndexScan2", "covers": [ "cover ((`CUSTOMER`.`state`))", "cover ((`CUSTOMER`.`city`))", "cover (((`CUSTOMER`.`name`).`lastname`))", "cover ((meta(`CUSTOMER`).`id`))" ], "filter_covers": { "cover ((`CUSTOMER`.`status`))": "premium" }, "index": "idx_cx3", "index_id": "18f8209144215971", "index_projection": { "entry_keys": [ 0, 1 ] } |
인덱스의 WHERE 절에 있는 상태 필드(status = 'premium')도 포함된다는 점에 유의하세요. 인덱스의 모든 문서에는 값이 'premium'인 status라는 필드가 있다는 것을 알고 있습니다. 이 값을 간단히 투영할 수 있습니다. 설명의 "Filter_covers" 필드에 이 정보가 표시됩니다.
인덱스에 필드가 있는 한, 쿼리는 전체 문서를 가져오지 않고도 인덱서에서 데이터를 가져온 후 추가 필터링, 조인, 집계, 페이지 매김을 수행할 수 있습니다.
규칙 #3: 인덱스 복제 사용
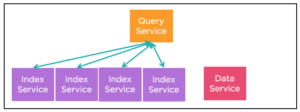
Couchbase 클러스터에는 여러 인덱스 서비스가 있습니다. Couchbase 5.0 이전에는 수동으로 복제본(등가) 인덱스를 만들어 처리량, 로드 밸런싱 및 고가용성을 개선할 수 있었습니다.
5.0 이전 버전:
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx2 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; CREATE INDEX idx3 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium'; |
이 세 인덱스의 동등성을 인정하는 이유는 핵심 표현식과 WHERE 절이 다음과 같기 때문입니다. 정확히 동일합니다.
쿼리 최적화 단계에서 N1QL 엔진은 쿼리 계획을 생성하기 위해 인덱스 스캔을 위한 세 개의 인덱스 중 하나를 선택합니다(다른 요구 사항이 충족된다는 가정 하에). 쿼리 실행 중에 쿼리는 스캔 패키지를 준비하고 인덱스 스캔 요청을 보냅니다. 이 과정에서 로드 통계에 따라 그 중 한 곳으로 요청을 보냅니다. 시간이 지남에 따라 각 인덱스는 비슷한 부하를 갖게 될 것입니다.
복제 인덱스(동등한 인덱스)를 만드는 이 프로세스는 간단한 매개변수를 사용하여 더 쉽게 수행할 수 있습니다.
|
1 2 3 4 |
CREATE INDEX idx1 ON CUSTOMER(state, city, name.lastname) WHERE status = 'premium' WITH { "num_replica":2 }; |
이는 서로 다르지만 동일한 인덱스 세 개를 생성하는 것과 같습니다.
규칙 #4: 버킷/키 공간이 아닌 워크로드 기준 인덱싱
각 쿼리에 대한 전체 애플리케이션 워크로드와 서비스 수준 계약(SLA)을 고려하세요. 처리량이 많고 밀리초의 지연 시간이 요구되는 쿼리에는 사용자 정의 및 복제 인덱스가 필요하지만, 다른 쿼리에는 인덱스를 공유할 수 있습니다.
단순히 설정 및 가져오기 작업을 수행하거나 USE KEYS로 쿼리를 실행할 수 있는 키스페이스가 있을 수 있습니다. 이러한 키스페이스에는 인덱스가 필요하지 않습니다.
쿼리를 분석하여 공통 술어, 키 스페이스의 투영을 찾습니다. 공통 술어를 기반으로 인덱스 수를 최적화할 수 있습니다. 쿼리 중 하나에 선행 키에 술어가 없는 경우, 인덱스를 공유할 수 있도록 (필드가 누락되지 않음) 추가하는 것이 합당한지 확인하세요.
애플리케이션이나 쿼리를 개발하는 동안 기본 인덱스를 사용하는 것은 괜찮습니다. 그러나 테스트하기 전에 '기본 인덱스' 섹션에 설명된 애플리케이션 사용 사례가 아니라면 올바른 인덱스를 생성하고 시스템에서 기본 인덱스를 삭제하세요. 프로덕션 환경에 기본 인덱스가 있고 쿼리가 인덱스의 전체 스팬으로 전체 기본 스캔을 수행하게 되면 문제가 발생할 수 있습니다. Couchbase에서 기본 인덱스는 버킷의 모든 문서를 색인합니다.
Couchbase의 모든 보조 인덱스에는 최소한 문서 유형에 대한 조건이 있는 WHERE 절이 있어야 합니다. 이것은 시스템에 의해 강제되지는 않지만 좋은 설계입니다.
|
1 2 3 |
CREATE INDEX def_route_src_dst ON `travel-sample` (`sourceairport`, `destinationairport`) WHERE (`type` = "route"); |
올바른 인덱스를 만드는 것은 성능 최적화를 위한 모범 사례 중 하나입니다. 최상의 성능을 얻기 위해 해야 할 일은 이것뿐만이 아닙니다. 클러스터 구성, 튜닝, SDK 구성, 준비된 문 사용 등이 모두 중요한 역할을 합니다.
규칙 #5: 예상이 아닌 예측으로 인덱싱하기
이것은 당연한 규칙처럼 보입니다. 하지만 가끔씩 이런 실수를 하는 사람들을 만나게 됩니다.
쿼리를 생각해 보세요:
|
1 2 3 4 |
SELECT city, state, status FROM CUSTOMER WHERE state = 'CA' AND status = 'premium'; |
쿼리에서 다음 인덱스 중 하나를 사용할 수 있습니다:
|
1 2 3 4 5 6 |
Create index i1 on CUSTOMER(state); Create index i2 on CUSTOMER(status); Create index i3 on CUSTOMER(state, status); Create index i4 on CUSTOMER(status, state); Create index i5 on CUSTOMER(state) WHERE status = “premium”; Create index i6 on CUSTOMER(status) WHERE status = “CA”; |
인덱스가 쿼리를 완전히 포함하도록 하려면 인덱스 3-6에 도시 필드를 추가하기만 하면 됩니다.
그러나 도시를 선행 키로 사용하는 인덱스가 있는 경우 최적화 도구는 해당 인덱스를 선택하지 않습니다.
|
1 2 3 |
Create index i7 O ON CUSTOMER(city, state) WHERE status = “premium”; |
인덱스를 최적화하기 위해 다양한 시나리오에서 인덱스 스캔이 어떻게 작동하는지에 대한 자세한 도움말을 참조하세요: https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
규칙 #6: SLA를 충족하기 위해 인덱스 추가하기
관계형 데이터베이스의 경우 성능, 성능, 성능 이 세 가지가 가장 중요했습니다.
NoSQL 데이터베이스의 경우 규모에 맞는 성능, 규모에 맞는 성능, 규모에 맞는 성능이라는 세 가지가 가장 중요합니다.
노트북에서 기본적인 성능 테스트를 실행하는 쿼리와 클러스터에서 처리량이 많고 지연 시간이 짧은 쿼리를 실행하는 것은 전혀 다른 문제입니다. 다행히도 Couchbase에서는 다차원 확장 덕분에 병목 리소스를 쉽게 식별하고 독립적으로 확장할 수 있습니다. Couchbase의 각 서비스는 데이터, 인덱스, 쿼리라는 별개의 서비스로 추상화되어 있습니다. Couchbase 콘솔에는 각 서비스에 대한 통계가 독립적으로 제공됩니다.
쿼리에 대한 인덱스를 생성하고 워크로드에 맞게 인덱스를 최적화한 후에는 복제 인덱스 간에 스캔의 부하가 분산되므로 대기 시간을 개선하기 위해 복제본(동등한) 인덱스를 추가할 수 있습니다.
규칙 #7: 정렬을 피하기 위한 인덱스
인덱스에는 이미 인덱스 키의 정렬된 순서대로 데이터가 있습니다. 스캔 후 인덱스는 인덱스 키 순서대로 결과를 반환합니다.
|
1 2 3 |
CREATE INDEX idx3 ON `travel-sample`(state, city, name.lastname) WHERE status = 'premium'; |
데이터는 주, 도시, 이름.성의 순서로 저장되고 반환됩니다. 따라서 state, city, name.lastname의 순서로 데이터가 예상되는 쿼리가 있는 경우 인덱스를 사용하면 정렬을 피할 수 있습니다.
아래 예제에서는 인덱스의 세 번째 키인 name.lastname을 기준으로 결과가 정렬되어 있습니다. 따라서 name.lastname을 기준으로 결과 집합을 정렬해야 합니다. 설명은 계획에 이 정렬이 필요한지 여부를 알려줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] } ] } } ] }, { "#operator": "Order", "sort_terms": [ { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY name.lastname;" } |
아래 쿼리는 인덱스 키와 완벽하게 일치합니다. 따라서 정렬이 필요하지 않습니다. 설명 출력에서 주문 연산자가 누락되었습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
EXPLAIN SELECT state, city, name.lastname FROM `travel-sample` WHERE status = ‘premium’ AND state = ‘CA’ AND city LIKE ‘san%’ ORDER BY state, city, name.lastname; { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`state`))", "cover ((`travel-sample`.`city`))", "cover (((`travel-sample`.`name`).`lastname`))", "cover ((meta(`travel-sample`).`id`))" ], "filter_covers": { "cover ((`travel-sample`.`status`))": "premium" }, "index": "idx3", "index_id": "19a5aed899d281fe", "index_projection": { "entry_keys": [ 0, 1, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "maxParallelism": 1, "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "(((cover ((`travel-sample`.`status`)) = \"premium\") and (cover ((`travel-sample`.`state`)) = \"CA\")) and (cover ((`travel-sample`.`city`)) like \"san%\"))" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`state`))" }, { "expr": "cover ((`travel-sample`.`city`))" }, { "expr": "cover (((`travel-sample`.`name`).`lastname`))" } ] }, { "#operator": "FinalProject" } ] } } ] } ] }, "text": "SELECT state, city, name.lastname \nFROM `travel-sample`\nWHERE status = 'premium' AND state = 'CA' AND city LIKE 'san%'\nORDER BY state, city, name.lastname;" } |
페이지 매김 사용 사례를 보기 전까지는 인덱스 정렬 순서를 활용하는 것이 중요해 보이지 않을 수 있습니다. 쿼리에 오프셋과 제한을 지정한 경우, 애플리케이션이 신경 쓰지 않거나 필요하지 않은 문서를 효율적으로 제거하기 위해 인덱스를 사용할 수 있습니다. 페이지 매김 사용 사례는 페이지 매김에 대한 자세한 내용은.
N1QL 옵티마이저는 먼저 쿼리의 술어(필터)를 기반으로 인덱스를 선택한 다음, 인덱스가 모든 쿼리 참조를 투영 및 순서대로 커버할 수 있는지 확인합니다. 그 후, 옵티마이저는 정렬을 제거하고 OFFSET 및 LIMIT 푸시다운을 결정하려고 시도합니다. 설명은 오프셋과 제한이 인덱스 스캔으로 푸시되었는지 여부를 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
"keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "100", "spans": [ { "exact": true, "range": [ { "high": "\"CA\"", "inclusion": 3, "low": "\"CA\"" }, { "high": "\"sao\"", "inclusion": 1, "low": "\"san\"" } ] } ] |
규칙 #8: 인덱스 수
시스템에서 가질 수 있는 인덱스 수에는 인위적인 제한이 없습니다. 데이터가 있는 버킷에 많은 수의 인덱스를 생성하는 경우, 데이터 서비스와 인덱스 서비스 간의 데이터 전송이 효율적으로 이루어질 수 있도록 지연된 빌드 옵션을 사용하세요.
규칙 #9: 삽입, 삭제, 업데이트 중 인덱싱
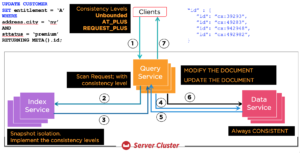
인덱스는 비동기적으로 유지됩니다. 키-값 API 또는 N1QL 문을 통한 데이터 업데이트는 버킷의 문서만 업데이트합니다. 인덱스는 스트림을 통해 변경 알림을 수신하고 변경 사항을 인덱스에 적용합니다. 다음은 UPDATE 문의 작업 순서입니다. 이 문은 인덱스를 사용하여 업데이트할 문서를 한정하고, 문서를 가져와서 업데이트한 다음, 문서를 다시 쓰고 UPDATE 문에서 요청한 모든 데이터를 반환합니다.
규칙 #11: 인덱스 키 순서 및 예측 유형
쿼리 사용자가 인덱스의 처음 N개의 연속된 키에 의해 생성한 인덱스 스캔 요청입니다. 따라서 인덱스 키의 순서가 중요합니다.
다양한 술어가 포함된 쿼리를 생각해 보세요:
|
1 2 3 4 5 |
SELECT cid, address FROM CUSTOMER WHERE state = ‘CA’ AND type = ‘premium’ AND zipcode IN [29482, 29284, 29482, 28472] AND salary < 50000 AND age > 45; |
이것은 인덱스의 키 순서에 대한 일반적인 규칙입니다. 키는 더 간단한 스칼라 속성이나 스칼라 값을 반환하는 표현식(예: UPPER(name.lastname))일 수 있습니다.
- 우선 순위는 평등 술어가 있는 키입니다. 이 쿼리에서는 상태와 유형에 대한 것입니다. 같은 유형의 술어가 여러 개 있는 경우 아무 조합이나 선택합니다.
- 두 번째 우선 순위는 IN 술어가 있는 키입니다. 이 쿼리에서는 우편번호에 있습니다.
- 세 번째 우선 순위는 (<)보다 작은 술어입니다. 이 경우 급여에 해당합니다.
- 네 번째 우선 순위는 사이 술어입니다. 이 쿼리에는 사이 술어가 없습니다.
- 다섯 번째 우선 순위는 보다 큰(>) 술어입니다. 이 쿼리에서는 나이에 대한 것입니다.
- 여섯 번째 우선 순위는 배열 술어입니다: UNNEST 뒤에 오는 술어인 ANY 또는 EVERY AND ANY입니다.
- 쿼리를 포함할 수 있도록 인덱스에 필드를 추가하세요.
- 이 분석을 수행한 후 WHERE 절로 이동할 수 있는 표현식을 찾습니다. 예를 들어, 이 경우 type = "premium"은 사용자가 고객 유형을 식별하기 위해 type 필드를 지정하므로 이동할 수 있습니다.
이를 통해 다음과 같은 인덱스가 만들어집니다.
|
1 2 3 4 5 |
CREATE INDEX idx_order ON CUSTOMER ( state, zipcode, salary, age, address, cid ) WHERE type = "premium"; |
규칙 #12: 설명 및 프로필을 읽는 방법 이해하기
아무리 많은 규칙을 따르더라도 쿼리 계획과 프로파일링을 이해하고, 부하가 걸린 시스템을 모니터링하고, 이를 조정해야 합니다. 쿼리 계획과 프로파일링 정보를 이해하고 분석하는 능력은 쿼리와 워크로드를 튜닝하는 데 있어 핵심입니다. 이러한 주제에 대한 두 개의 훌륭한 문서가 있습니다. 예제를 살펴보고 사용해 보세요.
- https://dzone.com/articles/understanding-index-scans-in-couchbase-50-n1ql-que
- https://www.couchbase.com/blog/profiling-monitoring-update-2/
참조
- Nitro: NoSQL 글로벌 보조 인덱스를 위한 빠르고 확장 가능한 인메모리 스토리지 엔진: https://vldb2016.persistent.com/industrial_track_papers.php
- 카우치베이스: https://www.couchbase.com
- 카우치베이스 문서: https://docs.couchbase.com
- N1QL: 실무 가이드: https://www.couchbase.com/blog/n1ql-practical-guide-second-edition/
- 인덱스 어드바이저: 인덱스 생성 규칙: https://www.slideshare.net/journalofinformix/couchbase-n1ql-index-advisor
안녕하세요, 케샤브,
저는 CB를 처음 사용하므로 양해해 주시기 바랍니다.
이 블로그에서 다음과 같이 언급되었습니다.
"따라서 기본 스캔을 수행할 때 쿼리는 색인을 사용하여 문서 키를 가져오고 버킷의 모든 문서를 가져온 다음 필터를 적용합니다. 따라서 이것은 매우 비용이 많이 듭니다."
나는 이것을 여러 곳에서 읽었으며 기본 색인을 피해야한다는 말을 들었습니다. 그 이유를 이해할 수 없습니까? 오라클이나 다른 RDBMS에서는 기본 / 고유 키 기반 조회가 가장 빠르거나 가장 좋습니다. N1QL 쿼리에 술어가 없으면 전체 버킷을 검색하므로 기본 인덱스를 사용하여 모든 키를 검색하므로 비용이 많이 든다는 것을 알고 있습니다. 하지만 술어에 키가 지정되어 있으면 가장 빠르지 않을까요?
예제 1에서는 술어에 특정 키가 언급되어 있습니다. 그렇다면 getid('key')와 거의 비슷하지 않나요?
고마워요
안녕하세요 pccb,
문서 키(버킷 내의 고유 키)가 있는 경우, 기본 제공 액세스 방법이 있으며 N1QL에서 가장 효율적인 방법입니다.
SELECT * FROM mybucket USE KEYS "cx:482:gn:284";
이를 위해 기본 인덱스를 발행하여 사용할 수도 있습니다:
SELECT * FROM mybucket WHERE meta().id = "cx:482:gn:284";
기본 인덱스를 사용하여 메타().id에서 스마트 범위 스캔을 수행할 수 있습니다:
SELECT * FROM mybucket WHERE meta().id LIKE "cx:482:gn:%";
주의해야 할 사항은 다음과 같습니다:
1. 카우치베이스 버킷은 고객, 주문, 항목 등 모든 유형의 문서를 문서화할 수 있습니다. 기본 인덱스는 이러한 모든 문서 유형에 적용됩니다.
2. 개발자/사용자가 동일성 또는 제한된 범위 스캔을 수행하도록 쿼리를 신중하게 구성한 경우 기본 인덱스를 사용해도 괜찮습니다.
3. 그러나 누군가 이러한 가이드라인 없이 쿼리를 실행하거나 프로덕션 환경에서 다른 적격 인덱스 없이 쿼리를 실행하면, 결국 전체 인덱스와 버킷의 모든 문서를 스캔하고 가져오는 기본 스캔을 사용하게 됩니다. 일반적으로 이는 프로덕션 환경에서 좋지 않은 일입니다.
안녕하세요,
인덱스를 피할 수 있는 방법, 즉 CB가 인덱스를 사용하지 않도록 하는 방법이 있나요?
우리가 달성하고자 하는 목표는 다음과 같습니다:
개발자가 쿼리를 시험해 볼 수 있도록 기본 인덱스가 있을 것입니다. 그러나 개발자가 필요한 인덱스를 포함한 쿼리를 완성한 후에는 기본 인덱스를 사용하지 않는지 확인하면서 쿼리를 실행했으면 좋겠습니다. 그 이유는 적절한 보조 인덱스를 생성한 후에도 쿼리가 여전히 기본 인덱스를 사용하고 있고 개발자가 이를 인식하지 못했을 수 있기 때문입니다. 따라서 기본 인덱스 사용을 피할 수 있는 방법이 있다면 해당 옵션을 사용하여 쿼리를 실행할 것입니다.
고마워요
피드백을 보내주셔서 감사합니다. 이 기능을 추가하기 위해 개선 작업을 진행했습니다: https://issues.couchbase.com/browse/MB-32109
오타가 있거나 제가 놓친 것이 있나요?
CREATE INDEX travel_sched ON
여행 샘플(모든 구분 배열 v.day FOR v IN 일정 종료)
"모두 구분"이 유효한 구문이며 그 의미는 무엇인가요? 문서에서 찾을 수 없습니다!
고마워요