Couchbase는 고유한 메모리 우선 아키텍처와 SQL의 민첩성과 JSON의 강력한 성능을 결합한 N1QL을 결합하여 대규모 성능을 구현하는 엔터프라이즈 데이터 플랫폼으로, 전체 텍스트 검색, 이벤트, 분석 및 글로벌 보조 인덱싱과 같은 기본 제공 기능을 갖추고 있습니다.
기술 서비스 전반에 걸쳐 현대적이고 안정적인 맞춤형 사용자 경험을 제공하는 것을 목표로 하는 기업은 일반적으로 여러 개의 Couchbase 노드 클러스터를 프로비저닝합니다. 이러한 다양한 클러스터는 단순히 재해 복구/백업 메커니즘 역할을 하는 추가 클러스터를 보유할 뿐만 아니라 다양한 업종, 사용 사례 및 미션 크리티컬 시스템에 걸쳐 규모에 맞게 동일한 성능을 제공합니다. Couchbase의 직관적인 사용자 인터페이스는 다양한 유지 관리 및 관리 작업(예: 재조정, 노드 추가, 장애 조치 등)을 위한 여러 원클릭 기능을 제공함으로써 클러스터와 데이터 버킷을 원활하고 쉽게 관리할 수 있지만, 전체 Couchbase 에코시스템에 대한 전체적인 관점을 갖는 것이 점점 더 중요해지고 있습니다. 특정 조직에서 데이터의 지리적 위치 또는 여러 세그먼트, 비용 센터 또는 업종에 걸쳐 있는 여러 마이크로서비스를 지원하기 위해 여러 클러스터를 배포하는 경우 특히 그렇습니다.
시작하기: 성능 지표 내보내기
사용 카우치베이스 익스포터 (커뮤니티 파트너가 개발한 TOTVS 랩)와 함께 프로메테우스및 Grafana이제 하나 이상의 클러스터의 주요 성능 메트릭을 내보내고 그래픽 대시보드를 통해 다양한 성능 측면을 시각화할 수 있습니다. 다음 스냅샷은 2개의 Couchbase 클러스터에 대한 모니터링 대시보드 샘플을 보여줍니다:
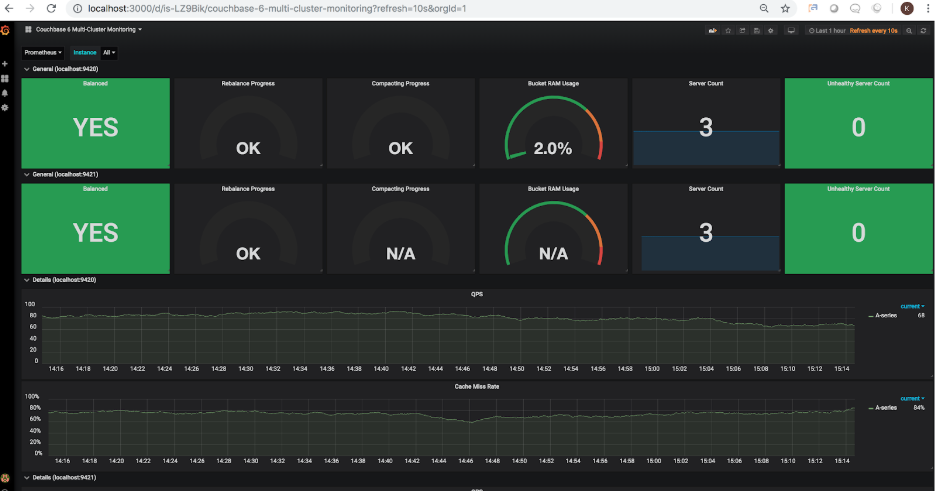
다음은 Couchbase Exporter, Prometheus 및 Grafana를 설치하고 구성하는 방법에 대한 자세한 안내입니다:
먼저, 이 모든 작업을 수행하는 데 필요한 오픈 소스 구성 요소를 설치하는 것부터 시작하겠습니다.
카우치베이스 익스포터
GitHub 리포지토리를 복제하여 Couchbase Exporter를 설치합니다. https://github.com/totvslabs/couchbase-exporter 를 클릭하고 소스로부터 빌드하거나 다음에서 최신 릴리스의 바이너리를 다운로드하여 https://github.com/totvslabs/couchbase-exporter/releases - 설치가 완료되면 다음 구문을 사용하여 모니터링할 각 Couchbase Server 클러스터에 대해 별도의 Couchbase Exporter 프로세스를 실행해야 합니다:
|
1 |
./couchbase-exporter --couchbase.username Administrator --couchbase.password password --web.listen-address=":9420" --couchbase.url="https://52.38.xx.xx:8091" |
기본적으로 카우치베이스 익스포터는 포트 9420에서 실행되며, 다음 포트에 연결을 시도합니다. 다음에서 실행되는 카우치베이스 서버 https://localhost:8091를 지정할 수도 있지만, 대부분의 사용자에게는 사용 가능한 포트 번호와 해당 Couchbase 클러스터를 명시적으로 지정하는 것이 가장 좋습니다(기존 클러스터의 모든 노드의 IP 주소로 충분함). 이 튜토리얼의 목적상, 이 글을 쓰는 시점에 52.38.xx.xx 및 52.40.xx.xx에 위치한 2개의 AWS EC2 데모 클러스터에 대해 2개의 Couchbase Exporter 인스턴스를 실행할 것입니다. Couchbase Exporter의 두 번째 인스턴스는 다음을 사용하여 시작됩니다:
|
1 |
$ ./couchbase-exporter --couchbase.username Administrator --couchbase.password password --web.listen-address=":9421" --couchbase.url="https://52.40.xx.xx:8091" |
다음은 이 두 Couchbase Exporter 인스턴스를 실행하는 스크린샷입니다. 참고 이러한 인스턴스는 이제 https://localhost:9420 그리고 https://localhost:9421, 를 각각 생성합니다. 이 두 URL은 나중에 Prometheus를 구성하는 데 사용됩니다.


프로메테우스
에 설명된 단계에 따라 원하는 설치 방법을 사용하여 Prometheus를 설치합니다. https://prometheus.io/docs/prometheus/latest/installation/ - 설치가 완료되면 이제 Prometheus 바이너리와 동일한 디렉터리에서 사용할 수 있는 prometheus.yml 파일을 편집할 수 있습니다. 이 YAML 파일을 수정하여 1단계에서 구성한 Couchbase Exporter 대상을 지정해야 합니다. 이 예제에서는 YAML 파일의 scrape_configs 섹션을 다음과 같이 수정합니다:
|
1 2 3 4 5 6 7 8 9 |
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'couchbase' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9420', 'localhost:9421'] |
scrape_configs 섹션이 Couchbase Exporter 인스턴스를 가리키도록 수정되면, 이제 다음과 같이 Prometheus를 시작할 수 있습니다:
|
1 |
$. /prometheus --config.file=prometheus.yml |
이제 Prometheus가 시작되고 포트 9090을 통해 액세스할 수 있어야 합니다(예 https://localhost:9090)
Grafana
에 설명된 단계에 따라 원하는 설치 방법으로 Grafana를 설치합니다. https://docs.grafana.org/installation/ - 설치가 완료되면 Grafana를 시작할 수 있어야 합니다(예 $ sudo service grafana-server start ) 포트 3000에서 액세스합니다(예 https://localhost:3000) - 기본 사용자 이름과 비밀번호는 다음과 같습니다. 관리자/관리자를 사용할 수 있지만, 조직의 보안 정책에 따라 이러한 자격 증명을 설정하는 것이 좋습니다.
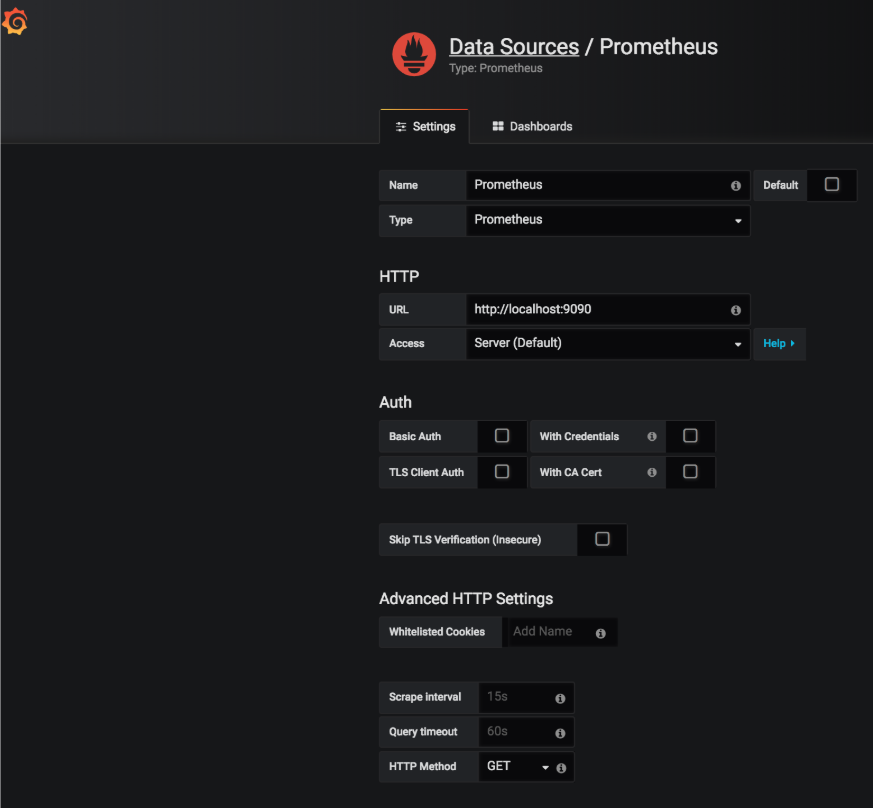
이제 Grafana가 설치 및 시작되었으므로 다음과 같이 Prometheus 데이터 소스를 추가하고 구성해 보겠습니다:
성능 지표 시각화하기:
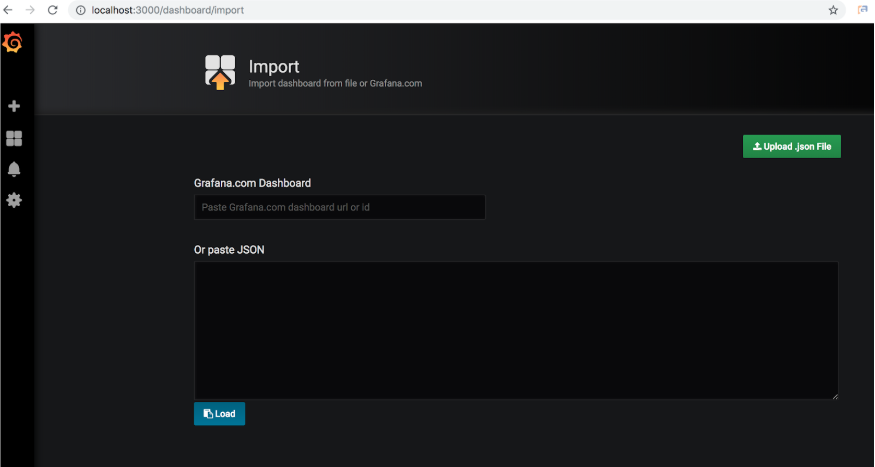
이제 Couchbase Exporter, Prometheus 및 Grafana가 올바르게 설치 및 구성되었으므로 이제 다음을 사용하여 샘플 Grafana 대시보드를 가져옵니다. 이 샘플 JSON. 이 대시보드는 예시용 샘플 대시보드일 뿐이며 특정 사용 사례에 대해 모니터링할 메트릭에 대한 권장 사항을 구성하지 않습니다. 조직에서는 개별 사용 사례와 관련된 특정 Couchbase 메트릭이 포함된 사용자 지정 대시보드가 필요할 수 있으므로 이 예가 반드시 특정 목적에 맞는 것은 아닙니다.
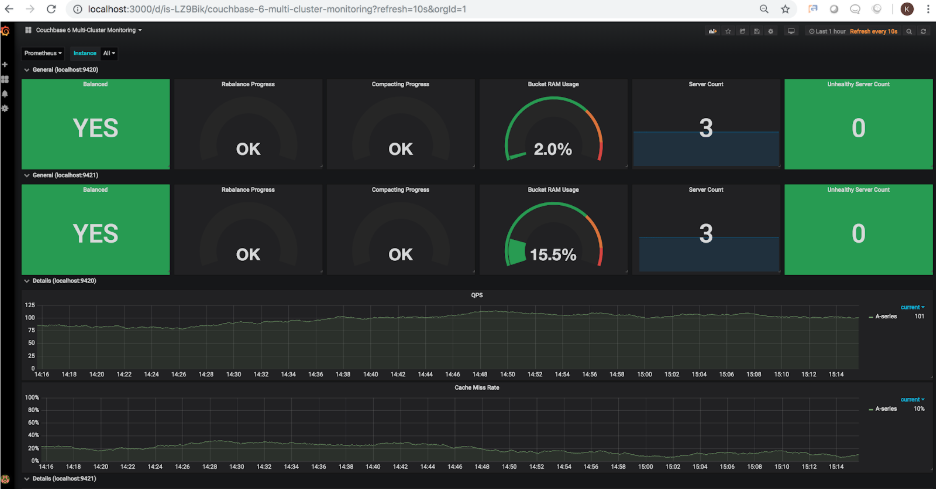
대시보드를 가져오면 Grafana에서 로드할 수 있어야 합니다. 다음 스크린샷은 1단계에서 구성된 2개의 클러스터의 상태를 보여줍니다.
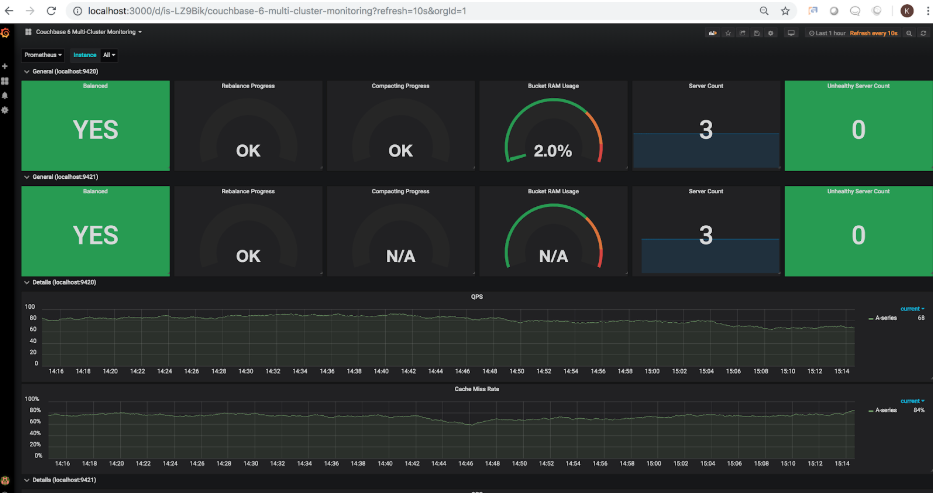
두 번째 클러스터의 버킷 RAM 사용량이 N/A로 표시되는 것을 보셨을 것입니다. 이는 두 번째 클러스터에 현재 버킷이 없다는 사실을 올바르게 반영합니다. 계속해서 해당 클러스터에 샘플 버킷을 추가해 보겠습니다. 샘플 버킷이 추가되면 대시보드가 새로 고쳐져 업데이트된 버킷 RAM 사용량이 15.5%로 표시됩니다(이 비율은 클러스터에 할당된 RAM에 따라 달라집니다):
각 클러스터는 처음에 3개의 노드로 구성되었습니다. 이제 두 번째 클러스터에 네 번째 노드를 추가해 보겠습니다. 노드가 추가되면 새로 고쳐진 대시보드에 다음과 같이 표시됩니다:
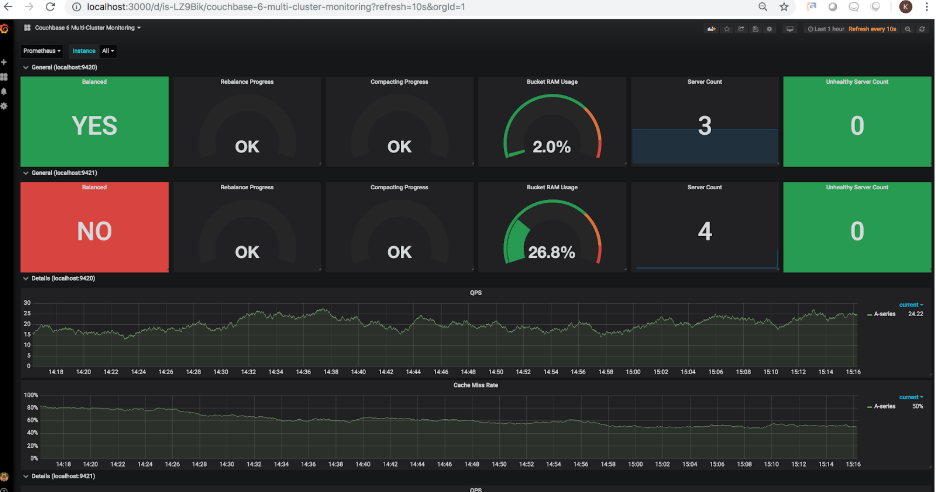
4번째 노드가 추가되고 클러스터가 재조정되지 않았기 때문에 서버 카운트가 총 4개의 노드를 표시하도록 업데이트되었지만 재조정 상태는 다음과 같습니다. 리밸런싱이 완료되지 않았음을 올바르게 표시합니다. 계속해서 리밸런싱. 카우치베이스 UI를 통해 리밸런싱이 트리거되면 새로고침된 대시보드에 다음이 표시됩니다:
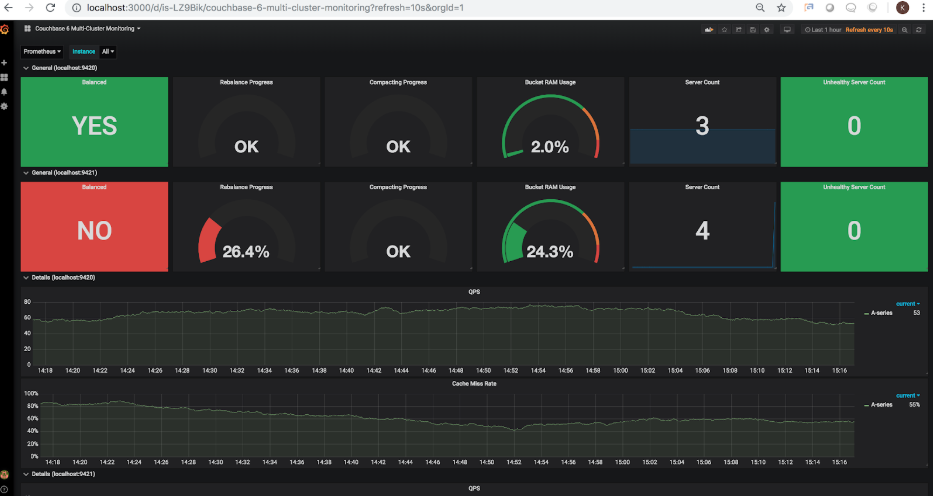
보시다시피 리밸런싱 표시기는 이제 26.4%의 진행률을 표시하고 있습니다. 일단 재조정이 완료되면 새로 고쳐진 대시보드에 다음과 같은 내용이 표시됩니다:
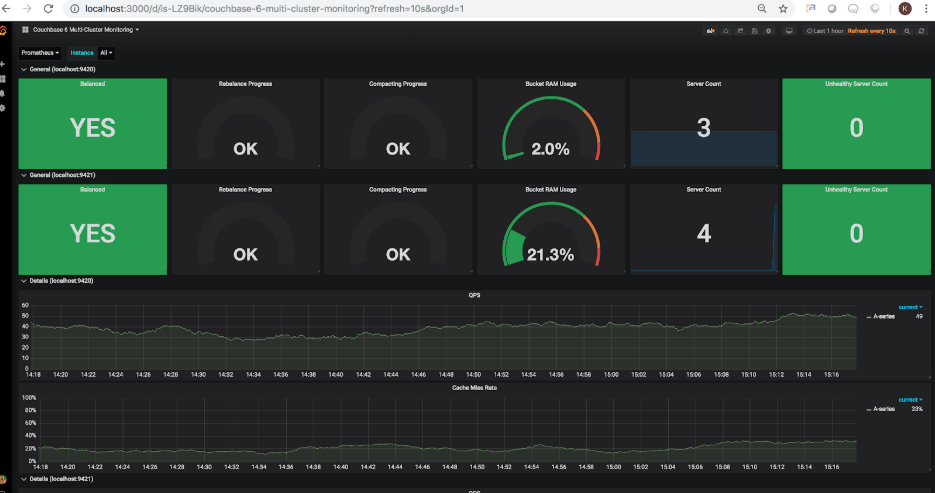
이제 재조정이 완료되었으며, 클러스터에 추가되는 노드의 용량을 반영하기 위해 버킷 RAM 사용량이 21.3%로 표시되어 3개 샘플 버킷의 실제 전체 사용량이 줄어든 것을 확인할 수 있습니다.
요약합니다:
이 블로그에서는 여러 Couchbase 클러스터를 모니터링하기 위해 Prometheus, Grafana, Couchbase Exporter를 설치했습니다. Grafana 대시보드를 사용하면 Couchbase Server 클러스터의 주요 메트릭과 성능 지표를 한 곳에서 시각적으로 모니터링할 수 있습니다. 또한 Prometheus를 사용하면 특정 메트릭이 특정 임계값에 미달하거나 초과할 때 특정 조건에 대한 알림을 사용자 또는 메일링 리스트에 보내는 알림 규칙을 구성할 수 있습니다.
아래는 이 블로그에서 사용된 리소스입니다:
좋은 글 감사합니다!
여러분도 관심을 가질 만한 Couchbase용 익스포터도 작성했습니다. 이 내보내기는 Couchbase API에서 모든 메트릭을 스크랩하며, 심지어 XDCR도 스크랩하고 Prometheus 및 Grafana 샘플 구성도 추가했습니다.
내보내기는 아직 약간의 개선이 필요하지만 바로 사용할 수 있습니다:
https://github.com/leansys-team/couchbase_exporter
그리고 도커 버전도 있습니다:
https://hub.docker.com/r/blakelead/couchbase-exporter
꼭 확인해 보세요, 여러분의 시간을 투자할 만한 가치가 있다고 생각합니다(그리고 제게도 피드백을 부탁드립니다 :)).
Prometheus로 모니터링을 시작하기에 좋은 글입니다. 공유해 주셔서 감사합니다!
이 글에서는 통합 부분을 잘 다루었지만 모니터링 도구 솔루션을 만드는 데 중요한 확장성, 고가용성, 장애 복구, 사용자 지정 및 자동화 범위에 대해서는 많은 부분을 놓쳤습니다.
다음 글에서 이 모든 것에 대해 설명해 보았습니다.
https://medium.com/@ashishrana160796/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-55f7d460f37
꼭 한번 살펴보세요. 시간 내어 보실 가치가 있기를 바랍니다. 또한 개발된 솔루션에 대한 피드백도 부탁드립니다.
1TP5자동화 1TP5카우치베이스 1TP5프로메테우스 1TP5그라파나 1TP5모니터링 1TP5경고 1TP5확장성 1TP5오픈소스 개발
이 통합 도구에 대한 기사 및 분석 링크가 업데이트되었습니다: https://hackernoon.com/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-ge1v6263t
기사 릴레이를 통해 클러스터 내부에서 일어나는 일에 대한 자세한 내용을 확인할 수 있습니다.
클러스터에 설정했습니다. 3 노드 클러스터가 있습니다.
1 (인덱스) 노드
2(데이터, 쿼리 및 검색) 노드.
노드별로 어떤 메트릭을 확인해야 하고 전체 클러스터에서 어떤 메트릭을 확인해야 하나요?