Couchbase에서 데이터는 항상 다음을 사용하여 파티션됩니다. 일관된 해시 문서 키의 값을 데이터 노드에 저장되는 vbukets에 저장합니다. 카우치베이스 글로벌 보조 지수(GSI) 는 색인 작업을 추상화하여 Couchbase 데이터 플랫폼 내에서 별개의 서비스로 실행됩니다. 하나의 인덱스가 모든 유형의 문서를 포괄할 수 있다면 모든 것이 좋습니다. 하지만 인덱스를 분할해야 하는 경우가 있습니다.
- 용량: 단일 노드로는 큰 인덱스를 저장할 수 없으므로 용량을 늘려야 합니다.
- 쿼리 안정성: 부분 인덱스를 사용하여 인덱스를 수동으로 분할하는 작업을 하기 위해 쿼리를 다시 작성하지 않으려는 경우.
- 성능: 단일 인덱스가 SLA를 충족할 수 없음
이 문제를 해결하기 위해 Couchbase 5.5는 인덱스의 자동 해시 분할을 도입했습니다. 버킷 데이터를 여러 노드로 해시하는 데 익숙해져 있습니다. 인덱스 파티셔닝을 사용하면 인덱스를 여러 노드로 해시할 수도 있습니다. 대칭성이 좋습니다.
인덱스 생성은 간단합니다. CREATE 인덱스 정의에 PARTITION BY 절을 추가하기만 하면 됩니다.
|
1 2 3 4 5 |
CREATE INDEX ih ON customer(state, name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} |
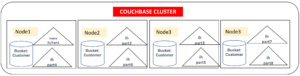
이것은 시스템에서 다음과 같은 메타 데이터로 나타납니다: indexes. 해시 표현식이 있는 새 필드 파티션에 주목하세요. HASH(state)는 논리적으로 인덱스의 이름을 지정하는 기준입니다. 고객.ih 는 여러 개의 물리적 인덱스 파티션으로 나뉩니다. 기본적으로 인덱스 파티션의 수는 16개이며, num_partition 매개변수를 지정하여 변경할 수 있습니다. 위의 예에서는 인덱스에 대해 8개의 파티션을 생성합니다. 고객.ih.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
select * from system:indexes where keyspace_id = "customer" and name = "ih" ; { "indexes": { "condition": "(`type` = \"cx\")", "datastore_id": "https://127.0.0.1:8091", "id": "b3ce745f84256319", "index_key": [ "`state`", "`name`", "`zip`", "`status`" ], "keyspace_id": "customer", "name": "ih", "namespace_id": "default", "partition": "HASH(`state`)", "state": "online", "using": "gsi" } } |
이제 다음 쿼리를 실행합니다. 쿼리가 인덱스를 사용하기 위해 해시 키에 추가 술어를 지정할 필요는 없습니다. 인덱스 스캔은 인덱스 스캔의 일부로 모든 인덱스 파티션을 스캔하기만 하면 됩니다.
|
1 2 3 4 5 6 7 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051"; |
그러나 해시 키에 같음 술어가 있는 경우, 인덱스 스캔은 올바른 데이터 범위를 가진 올바른 인덱스 파티션을 감지하고 나머지 인덱스 노드는 인덱스 스캔에서 제거합니다. 이렇게 하면 인덱스 스캔이 매우 효율적입니다.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051" and state = "CA"; |
이제 이 인덱스가 앞서 언급한 세 가지 사항에 대해 어떻게 도움이 되는지 살펴보겠습니다: 용량, 안정성, 성능입니다.
용량
쿼리 고객.ih 는 클러스터의 인덱스 노드 중 하나에 저장된 각 파티션과 함께 지정된 수만큼 분할됩니다. 인덱서는 확률적 최적화 알고리즘을 사용하여 각 노드에서 사용 가능한 여유 리소스에 따라 인덱서 노드 집합에 파티션을 배포하는 방법을 결정합니다. 또는 인덱스를 특정 노드 집합으로 제한하려면 nodes 매개변수를 사용합니다. 이 인덱스는 8개의 인덱스 파티션을 생성하고 지정된 4개의 인덱스 노드에 각각 4개씩 저장합니다.
|
1 2 3 4 5 6 |
CREATE INDEX ih ON customer(state, name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8, "nodes":["172.23.125.32:9001", "172.23.125.28:9001", "172.23.93.82:9001","172.23.45.20:9001" ]} |
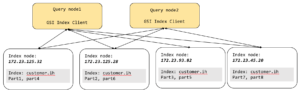
따라서 이 해시 분할 인덱스를 사용하면 하나의 논리적 인덱스(고객.ih)는 여러 개의 물리적 인덱스 파티션(이 경우 8개의 파티션)으로 분할되어 쿼리에 단일 인덱스로 착각하게 합니다.
이 인덱스는 여러 물리적 노드를 사용하기 때문에 더 많은 디스크, 메모리 및 CPU 리소스를 사용할 수 있습니다. 이러한 노드의 저장 공간이 증가하면 더 큰 인덱스를 만들 수 있습니다.
평소처럼 쿼리를 작성하여 적어도 선행 인덱스 키(예: 이름) 중 하나에 WHERE 절(유형 = "cx")만을 술어로 지정합니다.
신뢰성
Couchbase 5.0 인덱싱의 제한 사항:
Couchbase 5.0 이전까지는 아래와 같이 인덱스를 수동으로 분할할 수 있었습니다. CREATE INDEX의 WHERE 절을 사용하여 수동으로 분할해야 했습니다. 상태당 하나씩 다음 인덱스를 고려합니다. node 매개 변수를 사용하여 특정 인덱스 노드에 배치하거나 인덱스가 인덱스 노드 내에서 자동으로 분산되도록 할 수 있습니다.
|
1 2 3 4 5 6 |
CREATE INDEX i1 ON customer(name, zip, status) WHERE state = "CA"; CREATE INDEX i2 ON customer(name, zip, status) WHERE state = "NV"; CREATE INDEX i3 ON customer(name, zip, status) WHERE state = "OR"; CREATE INDEX i4 ON customer(name, zip, status) WHERE state = "WA"; |
state에 대한 동일시 술어를 사용하는 간단한 쿼리의 경우 모두 잘 작동합니다.
|
1 2 3 4 5 |
SELECT * FROM customer WHERE state = "CA" and name = "acme" and zip = "94051"; |
이 수동 파티셔닝에는 두 가지 문제가 있습니다.
- 상태에 대한 약간 복잡한 술어가 있는 다음을 고려해 보겠습니다. 술어(state IN ["CA", "OR"])는 인덱스의 WHERE 절의 하위 집합이 아니므로 아래 쿼리에는 어떤 인덱스도 사용할 수 없습니다.
|
1 2 3 4 5 6 |
SELECT * FROM customer WHERE state IN ["CA", "OR"] and name = ACME; SELECT * FROM customer WHERE state > "CA" and name = ACME; |
2. 데이터를 새로운 상태로 가져오는 경우 이를 미리 인지하고 인덱스를 만들어야 합니다.
|
1 2 3 |
SELECT * FROM customer WHERE state = "CO" and name = ACME |
숫자 필드인 경우 MOD() 함수를 사용할 수 있습니다.
|
1 2 3 4 5 6 |
CREATE INDEX ix1 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 0); CREATE INDEX ix2 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 1); CREATE INDEX ix3 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 2); CREATE INDEX ix4 ON customer(name, zip, status) WHERE (MOD(cxid) % 4 = 3); |
각 쿼리 블록을 우회하는 이 작업도 하나의 인덱스만 사용할 수 있으며, WHERE 절의 술어 중 하나와 일치하도록 쿼리를 신중하게 작성해야 합니다.
솔루션:
위 그림에서 볼 수 있듯이 쿼리와 인덱스 간의 상호 작용은 각 쿼리 노드 내부에 있는 GSI 클라이언트를 통해 이루어집니다. 각 GSI 클라이언트는 마치 하나의 논리적 인덱스(고객.ih) 8개의 물리적 인덱스 파티션 위에 있습니다.
GSI 클라이언트는 모든 인덱스 스캔 요청을 받은 다음 술어를 사용하여 쿼리에 필요한 데이터가 있는 인덱스 파티션을 식별할 수 있는지 확인합니다. 이것이 바로 파티션 가지치기(일명 파티션 제거) 프로세스입니다. 해시 기반 파티셔닝 체계의 경우, 같음과 IN 절 술어는 파티션 가지치기의 이점을 얻습니다. 다른 모든 표현식은 분산 수집 방식을 사용합니다. 논리적 제거 후, GSI 클라이언트는 나머지 노드로 요청을 전송하고 결과를 가져와 병합한 후 결과를 쿼리로 다시 보냅니다. 이 방법의 가장 큰 장점은 수동 분할 표현식에 대한 걱정 없이 쿼리를 작성할 수 있다는 것입니다.
아래 예제 쿼리에는 해시 키인 state에 대한 술어도 없습니다. 아래 쿼리는 파티션 제거의 이점을 얻지 못합니다. 따라서 GSI 클라이언트는 모든 인덱스 파티션에 대한 스캔을 병렬로 실행한 다음 각 인덱스 스캔의 결과를 병합합니다. 이 방법의 가장 큰 장점은 부분 인덱스 표현식과 일치하도록 수동 파티셔닝 표현식에 대한 걱정 없이 쿼리를 작성하면서도 클러스터 리소스의 전체 용량을 그대로 사용할 수 있다는 것입니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX ih1 ON customer(name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051"; |
아래 쿼리에서 해시 키의 추가 술어(state = "CA")는 파티션 가지치기의 이점을 누릴 수 있습니다. 쿼리 처리의 경우, 해시 키에 같음 술어가 있는 간단한 쿼리의 경우 인덱스의 여러 파티션에 작업 부하를 균일하게 분산시킬 수 있습니다. 위에서 설명한 그룹화 및 집계를 포함한 복잡한 쿼리의 경우, 스캔, 부분 집계가 병렬로 수행되므로 쿼리 지연 시간이 개선됩니다.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM customer WHERE type = "cx" and name = "acme" and zip = "94051" and state = "CA"; |
하나 이상의 키를 해시하여 인덱스를 만들 수 있으며, 각 키는 표현식이 될 수 있습니다. 다음은 몇 가지 예시입니다.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX idx1 ON customer(name) PARTITION BY HASH(META().id); CREATE INDEX idx2 ON customer(name) PARTITION BY HASH(name, zip); CREATE INDEX idx3 ON customer(name) PARTITION BY HASH(SUBSTR(name, 5, 10)); CREATE INDEX idx3 ON customer(name) PARTITION BY HASH(SUBSTR(META().id, POSITION(META().id, "::")+2), zip) |
성능
대부분의 데이터베이스 기능의 경우 성능이 가장 중요합니다. 좋은 벤치마크를 통해 입증된 뛰어난 성능이 없다면 그 기능은 그저 예쁜 구문 다이어그램에 불과합니다!
인덱스 파티셔닝은 두 가지 방식으로 성능을 개선합니다.
- 스케일 아웃. 파티션이 여러 노드로 분산되어 인덱스 스캔을 위한 CPU 및 메모리 가용성을 높입니다.
- 병렬 스캔. 올바른 술어는 쿼리에 파티션 가지치기의 이점을 제공합니다. 가지치기 프로세스 후에도 모든 인덱스의 스캔은 병렬로 수행됩니다.
- 병렬 그룹화 및 집계 DZone 문서 Couchbase N1QL 쿼리에서 인덱스 그룹화 및 집계 이해하기 에서는 인덱스를 사용한 그룹화 및 집계의 핵심 성능 향상에 대해 설명합니다.
- 인덱스 병렬 스캔(및 그룹화, 집계)의 병렬 처리 여부는 최대 병렬 처리 매개변수를 설정합니다. 이 매개 변수는 쿼리 노드 및/또는 쿼리 요청별로 설정할 수 있습니다.
다음 인덱스와 쿼리를 고려하세요:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ih1 ON customer(name, zip, status) PARTITION BY HASH(state) WHERE type = "cx" WITH {"num_partition":8} select zip, count(1) zipcount from customer where type = "cx" and name is not missing group by zip; |
인덱스가 HASH(state)로 분할되어 있지만 상태 술어가 쿼리에서 누락되었습니다. 이 쿼리의 경우, 인덱스 파티션의 개별 스캔 내에서 파티션 가지치기를 수행하거나 그룹을 생성할 수 없습니다. 따라서 쿼리와의 부분 집계 후에 병합 단계가 필요합니다(설명에는 표시되지 않음). 이러한 부분 집계는 병렬로 이루어지므로 쿼리 지연 시간이 줄어든다는 점을 기억하세요.
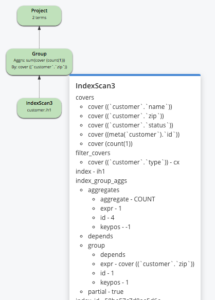
다음 인덱스와 쿼리를 고려하세요:
|
1 2 3 4 5 |
CREATE INDEX ih2 ON customer(state, city, zip, status) PARTITION BY HASH(zip) WHERE type = "cx" WITH {"num_partition":8} |
예 a:
|
1 2 3 4 5 6 |
select state, count(1) zipcount from customer where state is not missing group by state, city, zip; |
위의 예에서 그룹 기준은 인덱스의 선행 키(주, 도시, 우편)에 있고 해시 키(우편)는 그룹 기준 절의 일부입니다. 이렇게 하면 쿼리가 인덱스를 스캔하고 필요한 그룹을 간단히 생성하는 데 도움이 됩니다.
예제 b:
|
1 2 3 4 5 6 7 8 |
select zip, count(1) zipcount from customer where type = "cx" and city = "San Francisco" and state = "CA" group by zip; |
위의 예에서 그룹 by는 인덱스의 세 번째 키(zip)에 있고 해시 키(zip)는 그룹 by 절의 일부입니다. 술어 절(WHERE 절)에서, 앞의 인덱스 키(state 및 city) 앞에 하나의 동일성 술어가 zip 키 앞에 있습니다. 따라서 쿼리 결과에 영향을 주지 않고 그룹에 의해 암시적으로 키(주, 도시)를 포함합니다. 이렇게 하면 쿼리가 인덱스를 스캔하고 필요한 그룹을 간단히 생성하는 데 도움이 됩니다.
예제 c:
|
1 2 3 4 5 6 7 8 |
select zip, count(1) zipcount from customer where type = "cx" and city like "San%" and state = "CA" group by zip; |
위의 예에서 그룹 기준은 인덱스의 세 번째 키(zip)에 있고 해시 키(zip)는 그룹 기준 절의 일부입니다. 술어 절(WHERE 절)에는 도시에 대한 범위 술어가 있습니다. 인덱스 키(city)가 해시 키(zip) 앞에 있습니다. 따라서 인덱스 스캔의 일부로 부분 집계를 생성한 다음 쿼리가 이러한 부분 집계를 병합하여 최종 결과 집합을 생성합니다.
요약:
인덱스 파티션을 사용하면 인덱스의 용량을 늘리고, 쿼리 안정성을 개선하며, 쿼리 성능을 높일 수 있습니다. Couchbase 스케일아웃 아키텍처를 활용하면 인덱스는 용량, 정확성, 성능 및 TCO를 개선합니다.
참조:
- 카우치베이스 문서: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html
- 카우치베이스 N1QL 문서: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html#
Keshav님께, 항상 훌륭한 기사를 제공해 주셔서 감사합니다.
몇 가지 질문 : 해시로 파티션 인덱스를 생성하는 동안 "num_partition":8을 사용하는 경우 클러스터에 8 개의 인덱서 노드가 있어야한다는 의미입니까 ? 아니면이 #는 상호 배타적이며 이것과 상관 관계가없고 관리자의 max_parallelism 설정과 만 상관 관계가있을 수 있습니까 ?
또한 관리자 설정에서 "서버"를 상향 조정하면 쿼리 성능에 차이가 있는지 도와 주시겠습니까?
도와주셔서 감사합니다.
각 노드는 인덱스의 여러 파티션을 가질 수 있습니다. 8개의 파티션이 있는 인덱스를 갖기 위해 인덱스 노드가 8개일 필요는 없습니다.
servers 매개변수는 쿼리 노드에서 최대 동시 쿼리 수를 제한합니다. CPU가 남아 있고 동시 쿼리 수를 늘리는 경우에만 성능(처리량)이 향상됩니다. 단일 쿼리의 성능은 개선되지 않습니다.
또한 활발한 포럼이 운영되고 있습니다. 포럼에서 언제든지 질문해 주세요. https://www.couchbase.com/forums/