CRUD는 만들기, 읽기, 업데이트 및 삭제의 약자입니다. 2부에서는 읽기용 R을 살펴보고 SQL을 사용하여 Couchbase에서 데이터를 읽기 위한 ASP.NET Core 엔드포인트를 빌드합니다.
다음 내용을 반드시 읽어보세요. 이 시리즈의 1부를 참조하여 ASP.NET Core "위시리스트" 프로젝트의 설정 및 구성에 대해 알아보세요.
SQL++ 읽기
Couchbase는 NoSQL 데이터베이스 중에서 유일하게 전체 SQL 구현 (SQL++, 일명 N1QL)을 사용하여 JSON 데이터를 쿼리할 수 있습니다.
SQL++는 "SQL과 유사한" 언어가 아닙니다. SQL++를 사용하면 다음과 같은 이점이 있습니다. 조인, CTE/WITH, 업데이트, 삽입, 삭제, MERGE, 집계/그룹 기준, 시작/커밋/롤백등 다양한 기능을 제공합니다.
그 외에도("++") 다음과 같은 JSON 데이터를 처리하는 기능도 제공됩니다. 누락, NEST, ARRAY_* 함수, OBJECT_* 함수등 다양한 기능을 제공합니다.
이 간단한 CRUD 애플리케이션에서는 SQL++를 사용하겠습니다. 선택 쿼리(및 인덱스)를 반환합니다. 모두 위시리스트에서 항목을 삭제합니다.
첫 번째 SQL++ 쿼리 작성
먼저, SQL++ 쿼리를 작성하여 모든 위시리스트 항목을 바로 카펠라 쿼리 워크벤치.
우선 시도해 보세요:
|
1 |
SELECT * FROM demo._default.wishlist; |
이 작업을 수행하면 오류 메시지가 표시됩니다. 다음과 같은 메시지가 표시됩니다:
|
1 |
`no index available on keyspace default:demo._default.wishlist that matches your query. Use CREATE PRIMARY INDEX` ... |
이는 예상되는 동작입니다. (대부분의) Couchbase의 SQL++ 쿼리는 사용 가능한 인덱스가 하나 이상 없으면 실행되지 않습니다.
문제 없습니다. 간단한 기본 색인 를 다음과 같이 명령합니다:
|
1 |
CREATE PRIMARY INDEX `ix_wishlist` ON `demo`.`_default`.`wishlist` |
기본 인덱스는 일반적으로 일반적인 프로덕션 환경에서는 사용하지 않는 것이 좋지만 개발 환경에서는 다음을 보장하기 때문에 매우 유용합니다. any SQL++ 쿼리는 인덱싱된 컬렉션에서 실행됩니다(제대로 인덱싱된 컬렉션만큼 효율적이지는 않지만). 좀 더 복잡한 SQL++ 쿼리를 생성하기 시작하면 "쿼리 워크벤치의 '조언' 버튼 를 사용하여 더 효율적인 인덱스 생성 방법을 제안받을 수 있습니다( 선택 * 할 수 있을 때마다 😆).
인덱스를 생성한 후 위의 작업을 다시 시도합니다. 선택 쿼리를 다시 실행하면 다음과 같은 결과가 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[ { "wishlist": { "name": "Skyline Chili T-Shirt" } }, { "wishlist": { "name": "Joey Votto jersey" } } ] |
거의 다 왔습니다. 이 오브젝트 배열이 C#로 직렬화된다고 상상해 보세요. 목록. 객체가 컬렉션 이름으로 중첩되어 있기 때문에 제대로 작동하지 않습니다. 그래서 저는 컬렉션에 다음과 같이 별칭을 붙이는 습관이 생겼습니다:
|
1 |
SELECT w.* FROM demo._default.wishlist w; |
결과를 생성합니다:
|
1 2 3 4 5 6 7 8 |
[ { "name": "Skyline Chili T-Shirt" }, { "name": "Joey Votto jersey" } ] |
좋아 보이지만 아직 빠진 것이 있습니다. 문서 키에 사용한 GUID는 어디에 있나요? Couchbase는 이를 데이터로 저장하지 않고 다음과 같이 저장합니다. 메타데이터. SQL++는 META() 함수를 사용하여 메타데이터를 쿼리할 수 있습니다. 사용 META().id 이렇게요:
|
1 |
SELECT META(w).id, w.* FROM demo._default.wishlist w; |
그리고 마침내 다음과 같은 결과를 얻었습니다:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "id": "2dab198b-1836-4409-9bdf-17275a2b2462", "name": "Skyline Chili T-Shirt" }, { "id": "31c9cc33-8dfe-440c-bd1b-bb038939d2e0", "name": "Joey Votto jersey" } ] |
이것은 다음과 같이 멋지게 직렬화됩니다. 위시리스트 항목 객체를 사용하여 파트 1에서 만든 클래스를 사용합니다.
ASP.NET Core에서 SQL++ 사용
방금 작성한 SQL++ 쿼리를 ASP.NET Core 엔드포인트로 가져와 보겠습니다.
In 선물 컨트롤러라는 엔드포인트를 만듭니다. GetAll:
|
1 2 3 4 5 6 |
[HttpGet] [Route("api/getall")] public async Task<IActionResult> GetAll() { } |
SQL++를 실행하려면 다음과 같은 유형의 객체를 가져와야 합니다. 클러스터. SQL++는 클러스터 수준(버킷, 범위, 컬렉션이 아닌)에서 실행됩니다. JOIN/UNION 를 추가할 수 있습니다.) 돌아가서 다음을 추가할 수 있습니다. 클러스터 공급자 를 생성자 매개변수로 사용할 수 있습니다. 이 엔드포인트가 SQL++에서만 작동한다면 좋은 생각일 것입니다. 하지만 1부에서 만든 것을 그대로 사용하겠습니다. 다음과 같은 유형의 객체가 있습니다. 버킷 공급자. 해당 객체에서 다음과 같은 유형의 객체를 가져올 수 있습니다. 클러스터:
|
1 2 3 4 5 6 7 8 9 |
[HttpGet] [Route("api/getall")] public async Task<IActionResult> GetAll() { var bucket = await _bucketProvider.GetBucketAsync("demo"); var cluster = bucket.Cluster; // ... snip ... } |
A 클러스터 객체는 ASP.NET Core가 다양한 방식으로 Couchbase 클러스터와 상호 작용하는 방식입니다. 현재로서는 QueryAsync 메서드를 사용합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[HttpGet] [Route("api/getall")] public async Task<IActionResult> GetAll() { var bucket = await _bucketProvider.GetBucketAsync("demo"); var cluster = bucket.Cluster; var result = await cluster.QueryAsync<WishlistItem>( "SELECT META(w).id, w.* FROM demo._default.wishlist w;" ); return Ok(result); } |
다음 사항이 있는지 확인하세요. 사용 문 상단에 있는 GiftsController.cs file:
|
1 2 3 4 5 |
using AspNetCoreTutorial.Models; using Microsoft.AspNetCore.Mvc; using Couchbase; using Couchbase.Query; using Couchbase.Extensions.DependencyInjection; |
한 가지 더 주의할 점이 있습니다. SQL++를 실행할 때, 여러 가지 (스캔) 일관성 옵션. 기본값은 ScanConsistency.NotBounded. 이 설정은 쿼리 엔진이 not 인덱스 업데이트가 완료될 때까지 기다렸다가 결과를 반환합니다. 이것이 가장 성능이 좋은 옵션입니다. 그러나 어떤 상황에서는 더 강력한 인덱스 일관성이 필요할 수 있습니다. 카우치베이스는 다음을 제공합니다. 요청 플러스 그리고 AtPlus.
ASP.NET 코어 엔드포인트 체험하기
Visual Studio에서, Ctrl+F5 를 클릭하면 앱이 시작됩니다. 브라우저에 OpenAPI/Swagger 페이지가 표시됩니다.
(무시 날씨 예보)를 클릭합니다(방금 Visual Studio 템플릿과 함께 제공됨).
엔드포인트를 클릭하여 사용해 보세요. 지정할 매개변수가 없으므로 그냥 실행.
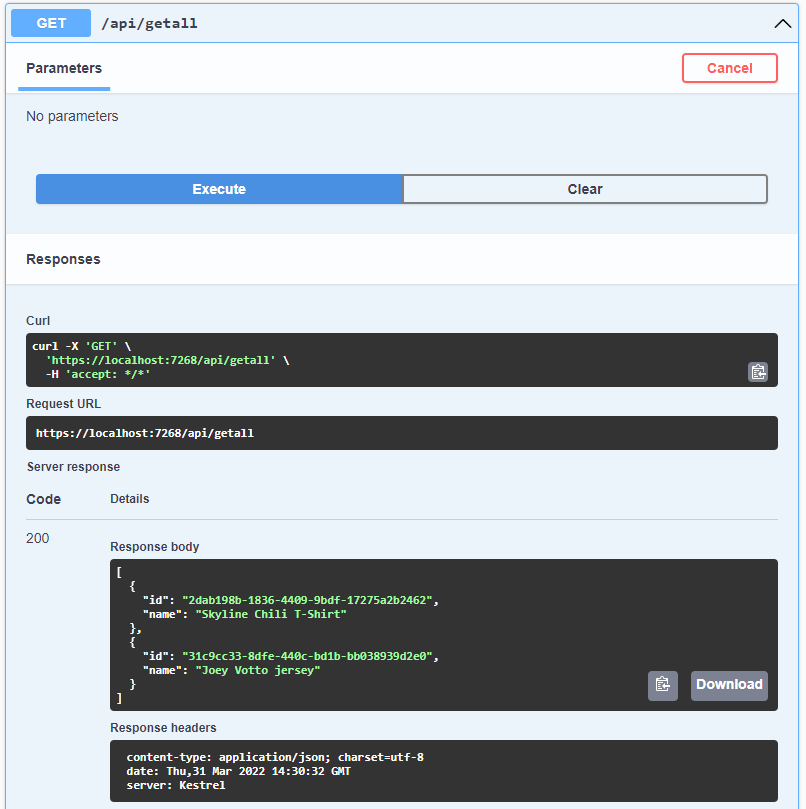
이제 CRUD의 "R"이 제자리에 있습니다.
다음 단계는 무엇인가요?
ASP.NET Core 프로젝트는 카우치베이스 카펠라에 연결되어 있으며, SQL++를 통해 데이터를 읽고 있습니다.
다음 블로그 게시물에서는 또 다른 "읽기" 엔드포인트를 만들겠습니다. SQL++ 대신 데이터를 액세스하고 읽을 수 있는 더 빠른 또 다른 방법을 살펴보겠습니다.
그동안은 그렇게 하셔야 합니다:
-
- 아카펠라 무료 체험 신청하기
- 다음 내용을 확인하세요. .NET용 카우치베이스 플레이그라운드 브라우저에서 바로 실행할 수 있는 예제입니다.