플렉스 인덱스 설명
플렉스 인덱스란 무엇인가요? 데이터베이스 엔진의 핵심 작업 중 하나는 그 안에 있는 데이터의 검색과 검색을 효율적으로 관리하는 방법입니다. 리소스 소비와 성능 사이의 효율성과 균형은 모든 데이터베이스에서 가장 중요한 측면입니다. B-Tree, 반전, 그래프, 공간 등 다양한 유형의 데이터베이스 인덱스는 서로 다른 검색 요구 사항을 충족하도록 설계되었습니다. 인덱스는 검색 성능에 필수적이지만, 사용할 적절한 인덱스 유형을 선택하는 것 또한 그 효과에 큰 차이를 가져올 수 있습니다. 인덱싱되는 데이터 요소의 특성에 따라 최적의 인덱스 유형이 결정되는 경우가 많기 때문입니다.
카우치베이스에서 글로벌 보조 색인은 B-Tree 구조를 사용해 빠른 정확도 및 범위 검색을 제공하고, 전체 텍스트 검색은 반전된 색인 구조를 사용해 효율적인 용어 검색을 제공합니다. 이러한 각 유형의 인덱스는 확장성이 뛰어날 뿐만 아니라 고유한 기능도 제공합니다. B-Tree는 선택도가 높은 값(예: 주문 번호 등 보다 뚜렷한)에 가장 일반적으로 사용되는 인덱스이며, 반전 인덱스는 검색 가능한 용어의 선택도가 낮을 가능성이 있는 텍스트 콘텐츠를 색인하는 데 가장 잘 사용됩니다.
사용자와 직접 인터페이스하는 애플리케이션에는 검색 기능이 필요하며, 이러한 애플리케이션에는 텍스트 검색뿐만 아니라 정확한 검색이 필요한 경우가 많습니다. 이러한 검색 기능은 여러 검색 서비스나 별도의 검색 API를 통해 제공되는 경우가 많기 때문에 애플리케이션 개발의 복잡성이 높아질 수 있습니다.
이러한 요구를 해결하기 위해 Couchbase는 v6.5에 N1QL SEARCH() 함수를 도입했습니다. 이 기능을 사용하면 N1QL 쿼리에서 검색어뿐만 아니라 관련성 점수로도 결과가 예측되는 텍스트 검색에 검색()과 일치 및 범위 검색에 SQL 술어를 모두 사용할 수 있습니다. 이렇게 하면 검색에 퍼지 요소가 추가되고 언어 인식 기능도 추가됩니다.
N1QL SEARCH() 기능을 통해 애플리케이션은 처음으로 Couchbase N1QL 언어를 사용하여 단일 API에서 두 쿼리 검색 서비스에 모두 액세스할 수 있습니다. 이 통합은 많은 이점을 제공합니다. 그중에서도 가장 중요한 것은 서로 다른 API를 처리할 필요가 없고 더 많은 검색 처리를 백엔드 서비스에 위임할 수 있어 애플리케이션 개발 프로세스가 간소화된다는 점입니다.
Couchbase 6.6에서는 다음과 같이 N1QL/FTS 통합을 한 단계 더 발전시켰습니다. 카우치베이스 플렉스 인덱스.
플렉스 인덱스란 무엇인가요?
플렉스 인덱스는 표준 N1QL 술어만을 사용하여 Couchbase 쿼리 서비스에서 검색 기능을 활용할 수 있는 기능입니다. 즉, N1QL 쿼리에서 FTS 인덱스를 활용하기 위해 FTS 구문이나 SEARCH() 함수를 사용할 필요가 없습니다.
검색 데이터 유형 지원에는 텍스트, 날짜/시간, 숫자, 부울이 포함됩니다. 하지만 텍스트의 경우 키워드 검색만 지원됩니다.
키워드 검색 - 는 인덱스에 추가하기 전에 텍스트 필드가 처리되는 방식을 나타냅니다. FTS 인덱스에서 표준 분석기는 색인화하기 전에 텍스트를 개별 용어로 구문 분석하는 반면에 키워드 분석기는 인덱스에 전체 텍스트를 사용합니다.
플렉스 인덱스의 작동 방식을 이해하기 위해 이 검색 조건의 쿼리가 있다고 가정해 보겠습니다: 영업 활동 관리 시스템에서 고객인 'Horizon Communications'와 관련된 모든 활동을 찾고자 하며, 2020년 8월에 발생했고 모스콘 센터에서 열린 마케팅 이벤트 중에 이루어졌습니다.
|
1 2 3 4 5 |
SELECT * FROM crm WHERE type='activity' AND event.location = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
또한 이 GSI 인덱스가 있다고 가정합니다:
|
1 2 3 |
CREATE INDEX adv_account_name_event_site_actdate ON `crm`(`account`.`name`,`event`.`location`,`act_date`) WHERE type='activity' |
이 쿼리는 작성된 대로 위의 GSI 지수를 활용합니다:
- 모든 쿼리 술어는 인덱스에 포함됩니다.
- 쿼리에는 술어
유형인덱스의 필터와 일치하는 ='활동'으로 설정합니다. - 실제로 인덱스는 선행 키만 있으면 고려됩니다.
계정.이름가 술어 중 하나이고 쿼리가유형='활동'.
쿼리 계획:

함께 플렉스 인덱스를 클릭하면 이제 쿼리 서비스에 쿼리에 FTS 인덱스 사용을 고려하도록 요청할 수 있는 옵션이 있습니다.
|
1 2 3 4 5 |
SELECT * FROM crm USE INDEX (USING FTS) WHERE type='activity' AND event.site = 'Moscone Center' AND account.name = 'Horizon Communications' AND act_date BETWEEN '2020-08-01' AND '2020-08-31' |
"인덱스 사용(FTS 사용)" 힌트는 쿼리에 도움이 될 수 있는 FTS 인덱스가 있는 경우 이를 사용하도록 쿼리 서비스에 제안합니다.
그리고 아래와 같이 정의된 FTS 인덱스가 있는 경우:
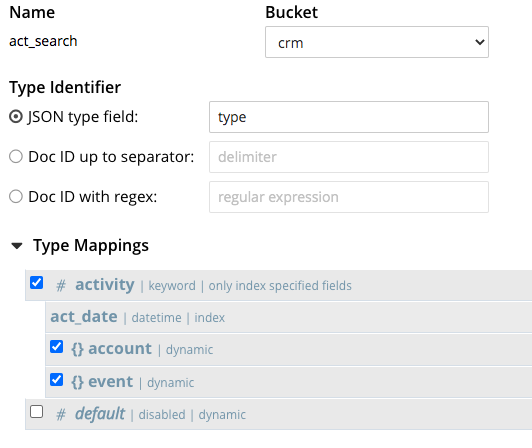
그리고 act_search 인덱스의 정의는 다음과 같습니다:
- 여기에는
유형의 문서만 포함하도록 인덱스 콘텐츠를 제한하는 매핑입니다.유형= '활동'. - 여기에는 하위 필드가 포함됩니다.
act_date. - 여기에는 다음에 대한 두 가지 하위 매핑이 포함됩니다.
계정그리고이벤트객체입니다. - 이 기능은
키워드분석기.
이 경우 act_search 는 위의 N1QL 쿼리에 완벽하게 적합하며, 위와 같이 인덱스 사용(FTS 사용) 힌트를 사용하면 쿼리에서 act_search FTS 지수.
쿼리 계획:

간단히 말해서 카우치베이스 플렉스 인덱스 는 표준 N1QL 술어 구문을 사용하는 N1QL 쿼리가 GSI 또는 FTS 인덱스를 투명하게 활용할 수 있는 기능을 제공합니다. N1QL 문을 수정하지 않고도.
하지만 플렉스 인덱스의 가치는 FTS를 사용하기 위한 더 간단한 구문뿐만 아니라 다음 섹션에서 설명할 FTS 인덱스의 다양한 기능에서도 찾을 수 있습니다.
그렇다면 플렉스 인덱스는 언제 사용해야 할까요?
높은 수준에서, 플렉스 인덱스 는 검색을 제공하는 애플리케이션에서 흔히 볼 수 있는 많은 문제를 해결할 수 있습니다.
- N1QL 문의 검색 조건이 미리 정해져 있지 않은 경우, 즉 사용자의 선택에 따라 다양한 수의 술어가 포함될 수 있는 경우가 많습니다. 그리고 모든 검색 조건을 포괄하는 인덱스를 생성하는 것도 어렵습니다.
- 검색 조건에 AND/OR 조합과 같은 논리 연산자를 사용하여 많은 술어를 포함하는 검색 기능을 제공하는 애플리케이션입니다.
- 검색 조건에 배열 또는 여러 배열의 배열 요소를 포함하는 검색과 같이 계층적 문서 요소에 대한 술어가 포함된 경우.
- 애플리케이션에 FTS의 강력한 기능이 필요하지만 다른 개체의 관련 정보를 포함하기 위해 SQL 집계 및 JOIN도 필요한 경우.
- 또는 단순히 FTS 구문 대신 N1QL 술어 구문을 사용하고 싶을 수도 있습니다.
플렉스 인덱스는 기존 애플리케이션에서 소급하여 사용할 수도 있습니다. use_fts 매개변수를 쿼리 API 호출에 추가합니다.
1) 검색 패턴이 미리 정해져 있지 않습니다.
최종 사용자에게 검색 기능을 제공할 때 항상 어려운 점은 사용자가 무엇을 검색할 수 있도록 허용할 것인가 하는 점입니다. 표준 지침에 따르면 사용자의 필요에 따라 결정하도록 되어 있습니다. 그러나 검색 가능한 필드가 몇 가지 주요 필드에 국한되지 않고 객체의 모든 필드를 포괄할 수 있는 복잡한 시스템에서는 기본 데이터베이스 시스템이 지원할 수 있는 기능에 따라 검색에 대한 결정이 내려지는 경우가 많습니다.
빠른 조회를 위해 기존의 B-Tree 인덱스를 기반으로 하는 애플리케이션은 이러한 유형의 검색 요구 사항을 위한 유연한 프레임워크를 제공하는 데 있어 부족한 경우가 많습니다.
이 문서를 참고하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
"activity" : { "id": "act1000", "title": "Announcing Couchbase Flex Index CB6.6", "reference": "24-i2y5J3928", "dept": "st55", "region": "00528", "notes": "Review the 100 N1QL Flex Index queries that ElasticSQL cannot do. The important point here is that Couchbase has integrated Text Search capability into its N1QL. Whereas ElasticSearch, relatively new SQL, has added SQL to its search engine....", "owner": { "id": "usr24", "name": "John Higgins" }, "priority": "Medium", "act_type": "Appointment", "event": { "name": "N1QL Flex Index vs. ElasticSQL", "location": "Moscone Center", "theme": "CouchbaseRed", "vendor": "Kempinski" }, "account": { "id": "acc134", "name": "Horizon Communications" }, "act_date": "2020-08-06", "appointment": { "duration": 90, "start_date": "2020-08-06 11:00:00", "contacts": [ { "id": "contact2493", "title": "SalesRep", "name": "Miranda Sullivan", "email": "msullivan@horizoncell.com", "phone": "778-096-1351" } ], "participants": [ { "role": "Support Analyst", "userid": "usr57", "name": "Raven Peterson" }, { "role": "Product Specialist", "userid": "usr24", "name": "John Higgins" } ], "type": "activity" } |
강조 표시된 13개의 필드는 사용자가 검색할 수 있는 모든 가능한 필드입니다. 그렇다면 사용자에게 검색 기능을 제공하려면 어떤 색인 전략을 사용해야 할까요?
| 인덱스 전략 | 장점 | 단점 |
| 13개의 개별 인덱스 생성 | 1- 단일 필드 검색에 효율적입니다. | 1-검색에 둘 이상의 필드가 있는 경우 여러 인덱스가 사용되므로 교차 스캔이 발생하여 성능에 영향을 미칩니다.
2-더 많은 검색 필드가 포함됨에 따라 점점 더 비효율적임 |
| 자주 사용하는 검색 조합에 대한 복합 색인 만들기 | 1- 빠른 응답 시간 | 1-특정 검색 조합만 지원되므로 유연성이 떨어집니다.
2-App UI는 인덱스 선행 키가 있는지 확인해야 합니다. |
| 모든 검색 조합에 대한 복합 색인 생성 | 1- 가장 빠른 응답 시간 | 1- 총 인덱스 수(13개!)는 비실용적입니다. |
| 검색 엔진 활용 - ElasticSearch 또는 Couchbase FTS | 1- 빠른 응답 시간
2-단일 인덱스만 필요합니다. |
1-검색 엔진을 활용하려면 애플리케이션을 다시 작성해야 합니다.
2-더 복잡한 애플리케이션 코드 3-유지 관리 비용 |
위의 옵션 목록에서 가장 유연한 검색 기능을 위해서는 ElasticSearch 또는 Couchbase FTS와 유사한 검색 엔진을 사용해야 한다는 것은 분명합니다. 그러나 이러한 검색 엔진을 특별히 염두에 두고 애플리케이션을 개발하지 않는 한, 검색 구문을 변환하고 API를 변경하는 노력은 사소하지 않을 것입니다.
바로 이 지점에서 Couchbase Flex Index의 가치가 빛을 발합니다. 이 새로운 기능을 통해 개발자는 표준 N1QL 술어를 사용하여 N1QL 쿼리 문을 작성할 수 있으며, 쿼리 서비스는 FTS 인덱스를 투명하게 활용할 수 있습니다.
2) 모든 술어 조합으로 쿼리하기
GSI B-Tree와 FTS 텍스트 인덱스의 주요 차이점 중 하나는 키 필드가 구축되는 방식입니다. GSI B-Tree 인덱스는 인덱스의 모든 키 필드를 함께 연결하여 노드 키를 구성하기 때문에 인덱스를 고려하기 전에 쿼리에 선행 키가 있어야만 하는 주된 이유가 됩니다. 반면에 FTS 인덱스는 각 필드에 대해 별도의 반전된 인덱스를 생성합니다. 이 설계를 사용하면 인덱싱된 필드 중 하나 이상이 있는 모든 쿼리에 대해 FTS 인덱스를 고려할 수 있습니다.
13개의 서로 다른 술어가 있는 다음 쿼리를 고려해 보겠습니다. 유형='활동 술어.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Communications' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
최상의 성능을 얻으려면 쿼리에 대한 인덱스가 있어야 하며, 가장 좋은 인덱스는 ADVISE에서 제공하는 커버링 인덱스입니다:
|
1 2 3 4 5 |
CREATE INDEX adv_idx13 ON crm` (`account`.`name`,`event`.`vendor`,`account`.`id`,`event`.`location`, `event`.`theme`,`priority`,`owner`.`name`,`dept`,`event`.`name`, `owner`.`id`,`region`,`act_date`,`title`) WHERE `type` = 'activity' |
쿼리 계획:

하지만 만약 그렇다면 어떻게 될까요?
- 쿼리에 선행 키가 없습니다.
계정.이름? - 쿼리에 13개의 술어가 다양하게 조합되어 있나요?
GSI는 정확한 쿼리 술어를 알 수 있는 가장 좋은 인덱스입니다. 그러나 조건어 집합을 미리 결정할 수 없는 애드혹 쿼리를 지원해야 하는 애플리케이션의 경우 FTS 사용을 고려하는 것이 가장 좋습니다.
이제 다음 FTS 지수를 고려해 보겠습니다.
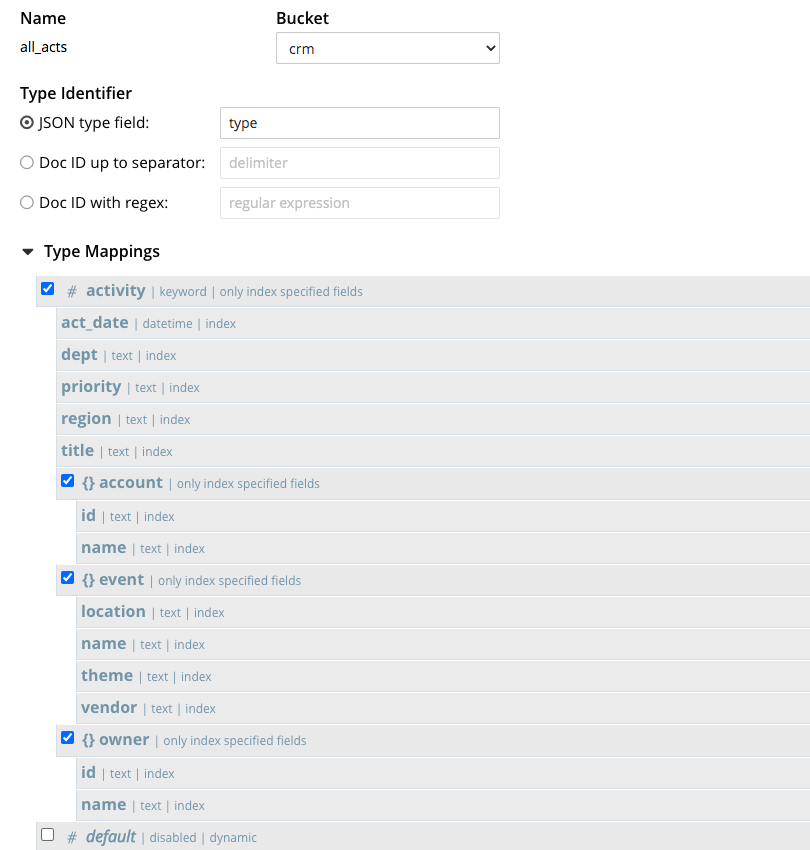
참고:
- 인덱스에는
유형매핑을 사용하여 문서에유형= '활동'이 인덱스에 포함됩니다. 다음을 참조하세요. FTS 유형 매핑 문서에서 자세한 내용을 확인하세요. - 인덱스는 키워드 분석기를 사용하므로 데이터 값이 개별 용어로 구문 분석되지 않고 인덱스 전체에 추가됩니다.
- 각 필드는 GSI 인덱스와 거의 동일한 방식으로 개별적으로 인덱싱됩니다. 다른 모든 옵션은 키워드 검색과 관련이 없으므로 선택되지 않습니다. 다음을 참조하세요. FTS 하위 매핑 문서에서 자세한 내용을 확인하세요.

이 FTS 인덱스를 사용하면 위와 동일한 쿼리이지만 인덱스 사용(FTS를 사용하는 모든_행위) 힌트를 입력하면 쿼리 서비스에 FTS 인덱스 사용을 대신 고려하도록 지시합니다. 인덱스 이름 all_acts 는 선택 사항입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempinski' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'John Higgins' |
쿼리 계획:

쿼리 실행:

주요 참고 사항: 쿼리는 다양한 수의 술어와 모든 필드 조합을 가질 수 있으며, 쿼리는 여전히 FTS 인덱스를 고려해야 합니다.
3) 논리 연산자 조합을 사용한 유연한 인덱스 쿼리 - AND/OR
술어 조합과 관련한 FTS 인덱스의 장점은 각 인덱스 필드가 생성되는 방식에서도 더욱 확장됩니다. 인덱싱된 각 필드는 자체적으로 반전된 구조를 가지고 있고 Bleve 루틴이 각 검색 조건에 대해 비트맵을 생성하기 때문에, AND/OR/NOT과 같은 술어 조합은 B-Tree 인덱스의 교차 스캔에 비해 훨씬 더 효율적으로 처리됩니다.
아래 예제에서는 쿼리에 여러 논리 연산자 OR이 있더라도 all_acts FTS 지수는 여전히 고려 대상입니다.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM crm a USE INDEX (USING FTS) WHERE a.type='activity' AND ( a.dept = 'iA88' OR a.region > '59416' ) AND a.priority = 'High' AND ( a.act_date BETWEEN '2018-01-01' AND '2018-08-31' OR a.event.location = 'Moscone Center' ) AND ( a.account.id = 'acc100' OR a.owner.name = 'Amanda Morrison') LIMIT 10 |
쿼리 계획:

쿼리 실행:
![]()
4) 쿼리에 여러 배열 술어가 포함된 경우
FTS 인덱스의 다양성은 검색 조건에서 인덱싱된 필드의 하위 집합만으로 인덱스를 사용할 수 있는 기능이나 검색 결과를 논리 연산자와 효율적으로 결합할 수 있는 기능에만 그치지 않습니다. 또한 FTS 인덱스가 배열 요소를 처리하는 방식은 N1QL 쿼리가 배열 술어를 얼마든지 가질 수 있도록 해줍니다.
이제 배열 술어를 사용하여 쿼리를 더 확장해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT * FROM crm a WHERE a.type='activity' USE INDEX (USING FTS) /* 1 */ AND a.title LIKE 'Announcing Couchbase Flex Index%' /* 2 */ AND a.dept = 'st55' /* 3 */ AND a.region = '00528' /* 4 */ AND a.priority = 'High' /* 5 */ AND a.act_date BETWEEN '2020-08-01' AND '2020-08-31' /* 6 */ AND a.event.location = 'Moscone Center South' /* 7 */ AND a.event.name = 'N1QL Flex Index vs ElasticSQL' /* 8 */ AND a.event.vendor = 'Kempskinki' /* 9 */ AND a.event.theme = 'CouchbaseRed' /* 10 */ AND a.account.id = 'acc134' /* 11 */ AND a.account.name = 'Horizon Cellular' /* 12 */ AND a.owner.id = 'usr24' /* 13 */ AND a.owner.name = 'Binh Le' /* 14 */ AND ANY pa IN a.participants SATISFIES pa.name LIKE 'Randy%' END /* 15 */ AND ANY co IN a.appointment.contacts SATISFIES co.title LIKE 'System Arch%' END |
하지만 아래와 같이 두 배열을 인덱스에 하위 매핑으로 추가해야 합니다.
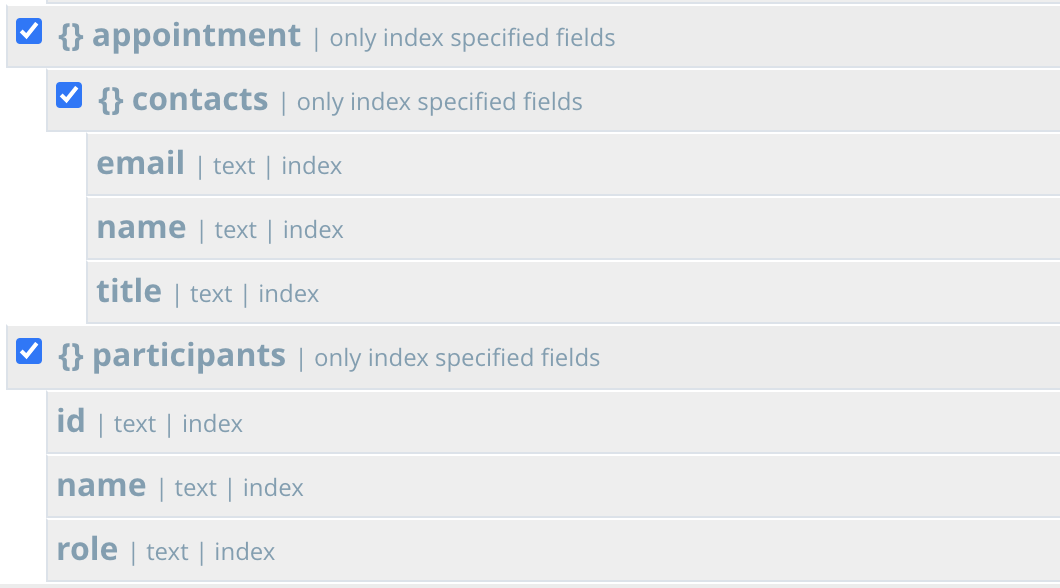
5) 차이점 검색 구문
이 사용 사례는 주로 키워드 검색에 FTS를 사용하며 검색 술어 구문과 같은 간단한 SQL을 선호하는 경우입니다.

N1QL 및 제한 없는 검색
최신 엔터프라이즈 애플리케이션에는 정확한 검색과 텍스트 검색이 모두 필요합니다. 정확한 검색을 위해 대부분의 RDBMS는 요구 사항을 충족하기 위해 B-Tree 기반 인덱스를 제공합니다. 텍스트 검색에 대한 요구 사항으로 인해 ElasticSearch 및 Solr와 같은 Lucene 기반 검색 엔진의 인기가 높아졌습니다.
- 이제 Oracle NoSQL이 ElasticSearch와 통합되었습니다: https://docs.oracle.com/en/database/other-databases/nosql-database/18.1/full-text-search/index.html#NSFTL-GUID-E409CC44-9A8F-4043-82C8-6B95CD939296
- 또한, 오라클 엔터프라이즈 RDBMS 기반 애플리케이션은 CX 애플리케이션 제품군을 사용하여 옵션으로 ElasticSearch 기능을 제공합니다. https://www.oracle.com/webfolder/technetwork/tutorials/tutorial/cloud/r13/wn/engagement/releases/20B/20B-engagement-wn.htm
그러나 고도로 정규화된 RDBMS 데이터 모델에 ElasticSearch 기능을 도입하는 데는 여러 가지 어려움이 따릅니다.
- ElasticSearch를 설정하기 위한 리소스 요구 사항과 ElasticSearch 데이터베이스에 대한 RDBMS 데이터를 수집하기 위한 스토리지 요구 사항입니다.
- 루씬 기반 검색은 데이터베이스 조인을 지원하지 않으므로 데이터 모델을 광범위하게 비정규화해야 합니다.
- ElasticSearch API를 사용하여 검색을 구현하기 위한 개발 노력.
ElasticSearch를 사용하고자 하는 고객들을 위한 노력은 이러한 NoSQL 데이터베이스에서 SQL이 채택된 주요 이유 중 하나입니다.
- SQL을 사용한 Elasticsearch. https://www.elastic.co/what-is/elasticsearch-sql
- SQL을 사용한 Elasticsearch용 Opendistro. https://opendistro.github.io/for-elasticsearch/features/SQL%20Support.html
- MongoDB는 Atlas 제품에서 Lucene을 사용하여 MQL에 검색 기능을 추가했습니다. https://www.mongodb.com/atlas/search
그러나 이러한 데이터베이스의 SQL 구현에는 여러 가지 제한 사항이 있습니다.
- ElasticSQL 제한 사항: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- 집합 작업 조인 등을 지원하지 않습니다.
- 창 기능이 없습니다.
- MongoDB의 MQL 검색 통합에는 여러 가지 제한 사항이 있습니다.
- 온프레미스 제품이 아닌 Atlas 검색 서비스에서만 사용할 수 있습니다.
- 검색은 집계() 파이프라인 내에서 첫 번째 작업만 할 수 있습니다.
- 집계 파이프라인(aggregate()) 내에서만 사용할 수 있으므로 업데이트 또는 삭제와 함께 술어로 사용할 수 없습니다.
반면에 Couchbase는 수년 동안 N1QL과 전체 텍스트 검색을 제공해 왔습니다. 이 쿼리 언어는 성숙한 데이터베이스에서 볼 수 있는 모든 연산을 지원하며, 규칙 기반 및 비용 기반 쿼리 최적화와 같은 조인, 집계, RDBMS와 같은 연산을 모두 지원합니다. 가장 중요한 것은 N1QL 언어가 기본적으로 JSON 문서와 함께 작동할 수 있도록 NEST, UNNEST 및 ARRAY 연산과 같은 추가 구조입니다.
검색 기능과 관련하여 Couchbase N1QL의 중요한 점은 Couchbase 전체 텍스트 검색이 N1QL 언어에 완벽하게 통합되어 있다는 점입니다.
- Couchbase 6.5 N1QL 검색 기능. https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- 카우치베이스 6.6 플렉스 인덱스(이 글의 주제). https://docs.couchbase.com/server/6.6/n1ql/n1ql-language-reference/flex-indexes.html
N1QL의 강력한 기능을 갖춘 플렉스 인덱스
다음은 i) 영업팀이 모든 고객과 작업한 시간을 다음과 같이 분석하려는 요구 사항에 대한 N1QL 쿼리의 예입니다. 산업를 반환하고 ii) 상위 3개 기술 세트 이러한 고객과 함께 일한 영업 팀원들의 이야기를 들어보세요.
이 쿼리는 카우치베이스 플렉스 인덱스가 모든 N1QL 기능의 조합과 함께 사용될 수 있음을 보여줍니다.

플렉스 인덱스 고려 사항
지금까지 예제를 통해 Flex 인덱스 기능이 어떻게 단일 다중 필드 FTS 인덱스를 활용하여 다양한 유형의 술어 조합과 여러 배열을 가진 쿼리를 모두 충족시킬 수 있는지 설명했지만, GSI를 사용하면 여러 인덱스가 필요할 것입니다. 그렇다면 GSI 대신 FTS 인덱스를 사용하면 인덱스 크기에 어떤 영향이 있을까요? 아래 표는 제 로컬 Couchbase 설정의 인덱스 크기를 보여줍니다.
색인 크기
아래 표는 CRM 활동 모델 데이터 집합을 기반으로 한 인덱스 크기의 예입니다.
문서 크기: 1.5K. 문서 수: 500K
| 색인 옵션 | GSI 인덱스 크기 | FTS 인덱스 크기 | 스토리지 차이 |
| 13개 필드에 대한 색인 | 205 MB | 252 MB | +25% |
| 13개 필드 + 모두 두 배열의 요소 | N/A | 357 MB | - |
위 표의 목적은 두 가지 유형의 인덱스의 정확한 크기를 제공하기 위한 것이 아니라 두 인덱스 간의 상대적인 크기 차이를 제공하기 위한 것입니다.
- FTS 인덱스는 GSI 인덱스에 비해 크기가 약 25% 더 큽니다. 이 수치는 샘플 데이터와 인덱싱된 필드의 분포를 반영합니다.
- 배열 요소를 사용하면 많은 비용을 절감할 수 있습니다.
- FTS 인덱스는 두 배열의 모든 요소를 단일 인덱스에 포함할 수 있습니다.
쿼리 성능
카우치베이스 인덱싱과 전체 텍스트 검색 인덱싱 서비스는 다차원 확장 및 고가용성을 통해 확장하도록 설계되었습니다. 즉, 이러한 서비스는 서로 다른 목표를 충족하도록 설계되었습니다. 인덱싱 서비스는 지연 시간이 길고 처리량이 많은 요구사항에 가장 적합합니다. 이러한 쿼리의 검색 조건은 작은 결과 집합으로 잘 정의되어 있을 것으로 예상됩니다. 반면에 FTS 서비스는 고급 분석기를 지원하여 퍼지 요소를 추가하고 언어를 인식하며 각 결과에 대한 관련성 점수를 제공하도록 설계되었습니다.
- 플렉스 인덱스에 기반한 쿼리에는 항상
fetch단계로 넘어가지 않습니다. 이는 쿼리 서비스가 여전히 쿼리 처리에서필터단계입니다. - 인덱스에 대한 집계 푸시다운과 같은 쿼리 성능 최적화는 GSI에서만 사용할 수 있으며 Flex Index에서는 사용할 수 없습니다.
- 지원되는 인덱스 쿼리는 GSI에서만 사용할 수 있습니다.
- Flex Index를 사용하면 페이지 매김을 FTS로 푸시다운할 수 없으므로 쿼리 수준에서 쿼리 페이지 매김이 수행됩니다.
- JOIN 쿼리의 경우, FTS 검색 쿼리에 사용할 수 있는 필드만 Flex Index에 전달됩니다.
요약
많은 NoSQL 데이터베이스가 텍스트 검색뿐만 아니라 정확히 일치하는 검색을 수행할 수 있는 기능을 제공하기 위해 MQL을 통해 간접적으로 SQL을 모방하거나 ElasticSQL에서 SQL을 직접 사용하여 쿼리 언어를 개선하려고 노력하고 있지만, 많은 NoSQL 데이터베이스가 텍스트 검색뿐만 아니라 정확히 일치하는 검색을 수행할 수 있는 기능을 제공하기 위해 노력하고 있습니다. 오직 Couchbase N1QL Flex Index만이 N1QL SEARCH()를 통해 이 두 가지 유형의 검색을 모두 원활하게 제공하며, 이제 N1QL Flex Index에서 표준 술어를 사용할 수 있습니다. SQL 지식만 있으면 두 가지 유형의 검색을 모두 활용할 수 있는 애플리케이션을 개발할 수 있습니다. 또한, 텍스트 검색은 모든 N1QL 기능, JOIN/Aggregation/CTE 및 고급 분석 창 함수, JSON 문서를 위한 NEST/UNNEST/ARRAY와도 결합할 수 있습니다.
참조
- 이 문서에서 사용된 활동 관리 데이터 모델 샘플 데이터 세트입니다. https://couchbase-sample-datasets.s3.us-east-2.amazonaws.com/crm.tar
Couchbase Server 6.6 리소스 살펴보기