지난 주요 릴리스인 Couchbase Server 5.0에서는 다음을 도입했습니다. 플라즈마 - 새로운 스토리지 엔진 에 대한 지원도 제공합니다. 인덱스 복제본 색인 서비스에서. 다음 릴리스에서는 이러한 새로운 기능을 지속적으로 추가할 예정입니다.
테마는 다음과 같습니다. 민첩성, 성능 그리고 관리 효율성 향상 에서 계속해서 눈에 띄는 Couchbase Server 5.5의 새로운 릴리스.
카우치베이스 서버 5.5에 도입된 주요 기능은 다음과 같습니다. 인덱싱 개선되었습니다:
분할 인덱스
카우치베이스의 글로벌 보조 인덱스는 전통적으로 단일 노드에 상주해 왔습니다. 즉, 인덱스 노드는 전통적으로 수직으로만 확장할 수 있었습니다. 이렇게 하면 쿼리가 연속된 결과를 가져올 때마다 성능이 향상되었습니다(예: OFFSET 및 LIMIT 절을 사용한 페이지 매김). 그러나 인덱스가 단일 노드에 맞지 않는 경우, 술어에 따라 수동으로 여러 개의 인덱스로 분할해야 했고, 이로 인해 부분 인덱스가 발생했습니다.
다음을 만들 수 있습니다. 분할 인덱스 해시 기반 체계를 기반으로 고객은 단일 인덱스를 자동으로 분할하여 여러 개의 작은 노드에 분산시킬 수 있습니다.
예를 들어 다음과 같이 분할하는 경우 유형 에서 여행 샘플 버킷 및 쿼리 기준 icao 그리고 국가를 누르면 분할된 인덱스가 자동으로 사용됩니다.
|
1 2 3 |
만들기 INDEX `PART_IDX_TS` 켜기 `여행-샘플`(`icao`,`국가`) 파티션 BY 해시(`유형`); 선택 * FROM `여행-샘플` 어디 유형='항공사' AND icao = 'MLA' AND 국가 = '미국'; |
일반적으로 파티션 키는 다음과 같이 사용하는 것이 좋습니다. 불변 필드 또는 N1QL 표현식 는 자주 업데이트되지 않는 필드인 불변 필드에 적용됩니다. 사용자는 다음을 수행할 수도 있습니다. 하나 이상의 필드를 파티션 키로 지정합니다..
다음 중 하나를 선택할 수도 있습니다. 파티션 복제본. 노드 장애 조치 중에 손실된 파티션은 재조정 중에 자동으로 재구축됩니다. 분할 인덱스를 사용해야 하는 경우와 사용하지 말아야 하는 경우에 대한 자세한 사용 사례와 분할 인덱스의 내부 세부 사항은 향후 문서에서 확인할 수 있습니다.
혜택: 쿼리 노드는 이제 다음 대상으로 쿼리를 발행할 수 있습니다. 병렬로 여러 인덱스 파티션 를 사용하여 결과를 다시 가져올 수 있으며, 이는 특히 집계 쿼리에 유용합니다. 또한 N1QL 쿼리에 ORDER BY 절이 없는 경우, 즉 인덱스 서비스에서 가져온 결과를 정렬할 필요가 없는 경우에도 도움이 됩니다. 술어에 지정된 파티션만 스캔하므로 쿼리 성능이 향상됩니다. 파티션의 복제본을 보유함으로써, 스캔은 파티션 간에 로드 밸런싱됩니다.
자세히 보기... 카우치베이스 서버 5.5의 인덱스 파티셔닝
인덱스에 대한 집계 푸시다운
인덱스 푸시다운 최적화(오프셋, 순서 지정, 복합 술어 등 다양한 연산용) 이미 존재 를 효율적이고 성능이 뛰어난 쿼리 처리를 위한 효과적인 도구로 Couchbase Server에 도입했습니다. 이제 집계(예: 카운트, 합계, 최소, 최대, 평균)와 GROUP BY도 Index Service로 푸시됩니다. 자세히 알아보기 여기.
혜택: N1QL 쿼리가 더 빨라지고, 인덱스와 쿼리 노드 간의 데이터 전송이 줄어들며, 쿼리 노드의 처리 오버헤드가 줄어듭니다.
'인덱스 변경'을 소개합니다.
이 새로운 선언적 명령은 관리자가 한 노드에서 다른 노드로 인덱스를 이동할 수 있는 기능을 제공합니다. 이전 Couchbase Server 5.0에서는 REST API를 사용하여 이 작업이 가능했지만, 선언적 체계는 관리를 단순화하고 훨씬 더 직관적입니다. 인덱스의 토폴로지는 유지되지만 이 명령은 관리자가 인덱스 배치를 보다 세밀하게 제어할 수 있도록 해줍니다. 새 명령은 어떻게 사용하나요? 클릭 여기 를 참조하세요. 이 지시어를 사용하여 인덱스의 이름을 변경하거나 인덱싱된 속성을 변경할 수 없다는 점에 유의하세요.
혜택 : 인덱스 복제본을 이동하는 DML 작업을 지정하기만 하면 인덱스를 더 쉽게 관리할 수 있습니다.
- 인덱스 변경에 대해 자세히 알아보기 구문 및 문서의 예제
개선된 인덱스 관리 콘솔
Couchbase 관리 콘솔의 인덱스 탭이 새롭게 바뀝니다. 이제 인덱스 이름으로 검색할 수 있을 뿐만 아니라 노드 이름, 버킷 이름, 인덱스 이름에 따라 다양한 보기 레이아웃을 가질 수 있습니다. 다음을 쉽게 식별할 수 있는 시각적 단서가 추가되었습니다. 파티션 인덱스.
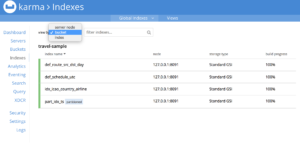
Couchbase 관리 콘솔의 색인 탭
혜택 : 인덱스 노드 전체에서 인덱스 상태의 가독성이 향상됩니다.
REST API 모니터링
다양한 인덱스 사용 매개변수에 대한 인사이트를 제공하는 새로운 REST 엔드포인트가 도입되었습니다. REST 엔드포인트를 사용하여 액세스할 수 있는 통계에는 두 가지 종류가 있습니다:
인덱스 수준 통계 (다음을 통해 액세스 가능) 호스트:인덱서-포트/api/stats//)
- 캐시_히트_퍼센트 - 관리되는 캐시에서 제공된 메모리 액세스 비율
- data_size - 인덱스가 소비하는 실제 데이터 크기
- disk_size - 인덱스가 소비하는 총 디스크 파일 크기
- frag_percent - 인덱스 조각화의 백분율입니다. 참고: 100KB 미만의 작은 인덱스 크기에서는 인덱스 디스크 파일의 정적 오버헤드가 인덱스 조각화 비율을 부풀립니다.
- items_count - 현재 인덱싱된 총 문서 수(재시작 시 새로 고침)
- 숫자_문서_인덱스드 - 마지막 시작 이후 인덱서에서 색인한 문서 수
- num_docs_pending - 색인화 대기 중인 문서 수
- num_docs_queued - 인덱싱을 위해 대기 중인 문서 수
- num_requests - 마지막 시작 이후 인덱서가 제공한 요청 수
- num_rows_returned - 마지막 시작 이후 인덱서가 제공한 행 수
- 거주자_퍼센트 - 메모리에 보관된 데이터의 백분율
- 스캔 바이트 읽기 - 마지막 시작 이후 스캔에서 읽은 바이트 수
- 총_스캔-기간 - 마지막 시작 이후 인덱서가 행을 스캔하는 데 사용한 총 시간
노드 수준 통계 (다음을 통해 액세스 가능) 호스트:인덱서-포트/API/통계)
위에서 언급한 각 인덱스 수준 통계를 포함하며 다음도 포함됩니다.
- 인덱서_상태 - 인덱서의 현재 상태(예: 활성/일시 중지)
- memory_quota - 노드에서 사용하는 메모리 양(바이트)
- memory_used - 인덱서에 할당된 메모리 할당량(사용자가 구성 가능, 바이트 단위)
위의 통계는 클러스터 전체에서 집계되지 않습니다.
또한 다음 두 개의 매개변수는 관리 콘솔에서 볼 수 있으며, REST 엔드포인트를 통해 액세스할 수 있습니다(ForestDB에서는 사용할 수 없음):
- 레이치 히트 퍼센트
- 거주자_퍼센트
- memory_used
혜택 : RESTful 엔드포인트를 사용하여 선택한 관리 제어 영역에서 인덱스 통계를 사용함으로써 인덱스 동작을 더 잘 이해할 수 있습니다.
여러분의 의견을 듣고 싶습니다. 아래에 의견을 남겨 주시거나 포럼에서. 새로운 카우치베이스 서버 5.5 릴리스.