
In the last major release, Couchbase Server 5.0, we introduced Plasma – New Storage Engine and also the support for Index Replicas in the Index Service. We have continued to build on these new features in our upcoming release.
The themes of agility, performance and better manageability continue to remain prominent in the new release of Couchbase Server 5.5.
Couchbase Server 5.5 introduces the following key Indexing improvements:
Partitioned Indexes
Global Secondary Indexes in Couchbase have traditionally resided on a single node. This means that index nodes have, traditionally, only been able to scale up vertically. This improved performance whenever queries would fetch contiguous results – a la pagination with OFFSET and LIMIT clauses. But, if an index could not fit into a single node, then it had to be manually split into multiple indexes based on a predicate – this led to partial indexes.
With the ability to create Partitioned Indexes based on a hash based scheme, customers can automatically split a single index and spread them across multiple smaller nodes.
For example, if we partition by type on the travel-sample bucket and query by icao and country, then the partitioned index is automatically used.
CREATE INDEX `part_idx_ts` ON `travel-sample`(`icao`,`country`) PARTITION BY hash(`type`);
SELECT * FROM `travel-sample` WHERE type='airline' AND icao = 'MLA' AND country = 'United States';We generally recommend the partition key to be an immutable field or a N1QL expression applied on an immutable field – a field that is not often updated. The user can also specify one or more fields as partition keys.
One could also have replicas of partitions. Partitions lost during node failover will be rebuilt automatically during rebalancing. Detailed use-cases of when to use partitioned indexes and when not-to, along with the internal details of partitioned indexes, will be coming in future documentation.
Benefits: Query nodes can now issue queries to multiple index partitions in parallel and get the results back; this especially benefits aggregation queries. It also helps those cases where there is no ORDER BY clause in the N1QL query, which means that the results fetched from index service need not be sorted. Only those partitions are scanned which are specified in a predicate, leading to more performant queries. By having replicas of partitions, scans are load balanced across them.
Read more… Index Partitioning in Couchbase Server 5.5
Aggregation Pushdown to Indexes
Index pushdown optimizations (for various operations like offset, ordering, composite predicates, etc.) already exist in Couchbase Server as effective tools for efficient and performant query processing. Now, aggregations (like COUNT, SUM, MIN, MAX, AVG) along with GROUP BY are also pushed down to Index Service. Learn more here.
Benefits: Faster N1QL queries, lower data transfer between index and query nodes and lower the processing overhead on query nodes.
Introducing ‘ALTER INDEX’
This new declarative command provides administrators with the ability to move indexes from one node to another. Earlier, in Couchbase Server 5.0, this was possible using the REST API, but the declarative scheme simplifies administration and is much more intuitive. The topology of the index is maintained, but the command gives finer grained control to administrators on index placement. How do you use the new command? Click here to learn more. Do note that the indexes cannot be renamed, nor can the attributes on which they have been indexed be altered using this directive.
Benefits : Easier management of indexes by simply specifying a DML operation to move index replicas.
- Learn more about ALTER INDEX syntax and examples in the documentation
Revamped Index Administration Console
The Index tab in the Couchbase Admin Console gets a new face-lift. Now you can not only search by index names, but also have different view layouts based on node names, bucket names and index names. Visual cues have been added to easily identify partitioned indexes.
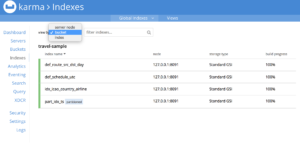
Benefits : Better readability of the state of indexes across the index nodes.
Monitoring REST APIs
New REST endpoints have been introduced that offer insights into various index usage parameters. There are two kinds of statistics that will be accessible using the REST endpoints:
Index Level Statistics (accessible via host:indexer-port/api/stats/<bucket_name>/<index_name>)
- cache_hit_percent – Percentage of memory accesses that were served from the managed cache
- data_size – Actual data size consumed by the index
- disk_size – Total disk file size consumed by the index
- frag_percent – Percentage fragmentation of the index. Note: at small index sizes of less than a hundred kB, the static overhead of the index disk file will inflate the index fragmentation percentage
- items_count – Current total indexed document count (Refreshed on restart)
- num_docs_indexed – Number of documents indexed by the indexer since last startup
- num_docs_pending – Number of documents pending to be indexed
- num_docs_queued – Number of documents queued to be indexed
- num_requests – Number of requests served by the indexer since last startup
- num_rows_returned – Number of rows served by the indexer since last startup
- resident_percent – Percentage of the data held in memory
- scan_bytes_read – Number of bytes read by a scan since last startup
- total_scan_duration – Total time spent by Indexer in scanning rows since last startup
Node Level Statistics (accessible via host:indexer-port/api/stats)
Includes each of the index level stats (mentioned above) and also includes
- indexer_state – Current state of the indexer (eg. Active/Paused)
- memory_quota – Amount of memory used by the node (in Bytes)
- memory_used – Memory quota assigned to Indexer (User configurable, in Bytes)
The above statistics are not aggregated across the cluster.
Also, the following two parameters will be visible in the Admin Console, in addition to being accessible via the REST endpoints (not available for ForestDB):
- rache_hit_percent
- resident_percent
- memory_used
Benefits : Understand the index behaviour better by using the RESTful endpoints to consume the Index Statistics in the Management Control Plane of choice.
We would love to know what you think. Do leave your comments below or on our Forum. Download the new Couchbase Server 5.5 release.
Leave a comment
You must be logged in to post a comment.