안녕하세요, 여러분! 저는 일본에서 근무하는 솔루션 엔지니어 코지입니다. couchbase.com에서 첫 포스팅을 하게 되어 정말 기대가 됩니다!
이 블로그에서는 Couchbase Server와 Apache NiFi를 통합하는 방법에 대해 설명하겠습니다.
목차:
NiFi란?
Apache NiFi 는 데이터 라우팅, 변환 및 시스템 중개 로직의 강력하고 확장 가능한 지시형 그래프를 지원하는 최상위 Apache 프로젝트입니다. 최근 호튼웍스는 다음과 같은 기능을 제공한다고 발표했습니다. 호튼웍스 데이터 흐름 (HDF). NiFi는 IoAT(만물인터넷) 사용 사례를 지원하기 위해 HDF에서 핵심 데이터 흐름 처리 엔진으로 사용됩니다. 자세한 내용은 해당 링크를 참조하세요.
NiFi, Couchbase, 그리고 나
카우치베이스에서 저의 공식 직함은 '솔루션 엔지니어'이며, 프리세일즈 업무가 주된 업무입니다. 하지만 저는 코드 작성도 좋아합니다. 코드를 작성하면 기술 지식을 최신 상태로 유지할 수 있고, 궁극적으로 고객에게 더 나은 솔루션을 제공하는 데 도움이 됩니다.
며칠 전, 카우치베이스 서버 액세스를 위한 Nifi 프로세서 세트가 Nifi의 코드베이스에 추가되었습니다. 제가 기여했습니다! 자세한 검토 과정을 통해 NiFi 커미터들과 함께 작업하는 것은 좋은 경험이었습니다. 포괄적인 개발자 가이드 문서가 프로젝트에 착수하는 데 큰 도움이 되었습니다.
기여 프로세스가 어떻게 진행되었는지 궁금하다면 다음 링크를 참조하세요:
-
JIRA: NIFI-992: 카우치베이스 서버 프로세서
소개는 여기까지입니다. 이제 NiFi 구성에 대해 자세히 알아보고 Couchbase Server를 통합하는 방법을 설명해 보겠습니다!
NiFi 주요 구성 요소
NiFi를 다운로드한 후 시작하고 브라우저를 통해 GUI 데이터 흐름 디자이너에 액세스할 수 있습니다. 다음은 숙지해야 할 몇 가지 주요 구성 요소입니다:
-
흐름 파일: NiFi 흐름 내에서 스트리밍되는 모든 데이터는 다음과 같은 객체로 전송됩니다. 흐름 파일. 불투명한 내용과 임의의 속성 집합이 있습니다. 예, 실제로 파일처럼 보입니다.
-
프로세서: Linux 명령어처럼 한 가지 작업을 잘 처리하도록 설계된 작은 처리 모듈입니다. 현재 약 80개의 프로세서가 있습니다. 파일 처리, 데이터베이스 액세스, HTTP 및 기타 프로토콜 처리 등의 기능을 수행합니다.
-
관계: 각 프로세서는 관계라는 파이프로 연결됩니다. 일부 프로세서는 성공, 실패 또는 원본과 같은 여러 관계를 갖습니다. 처리된 FlowFile은 이 관계를 통해 다음 프로세서로 전송됩니다.
프로세스 그룹별로 데이터 흐름 구성
NiFi 데이터 흐름에서 '프로세스 그룹'은 흐름이 복잡해질 때 매우 유용하게 사용할 수 있습니다. 여러 개의 흐름을 구성한 다음 각 프로세스 그룹을 개별적으로 시작/중단할 수 있습니다. 이 데모 데이터 흐름에서는 두 개의 프로세스 그룹, 즉 '트윗을 카우치베이스 샘플로 보내기'와 '카우치베이스 문서 샘플 덤프'를 설정했습니다.
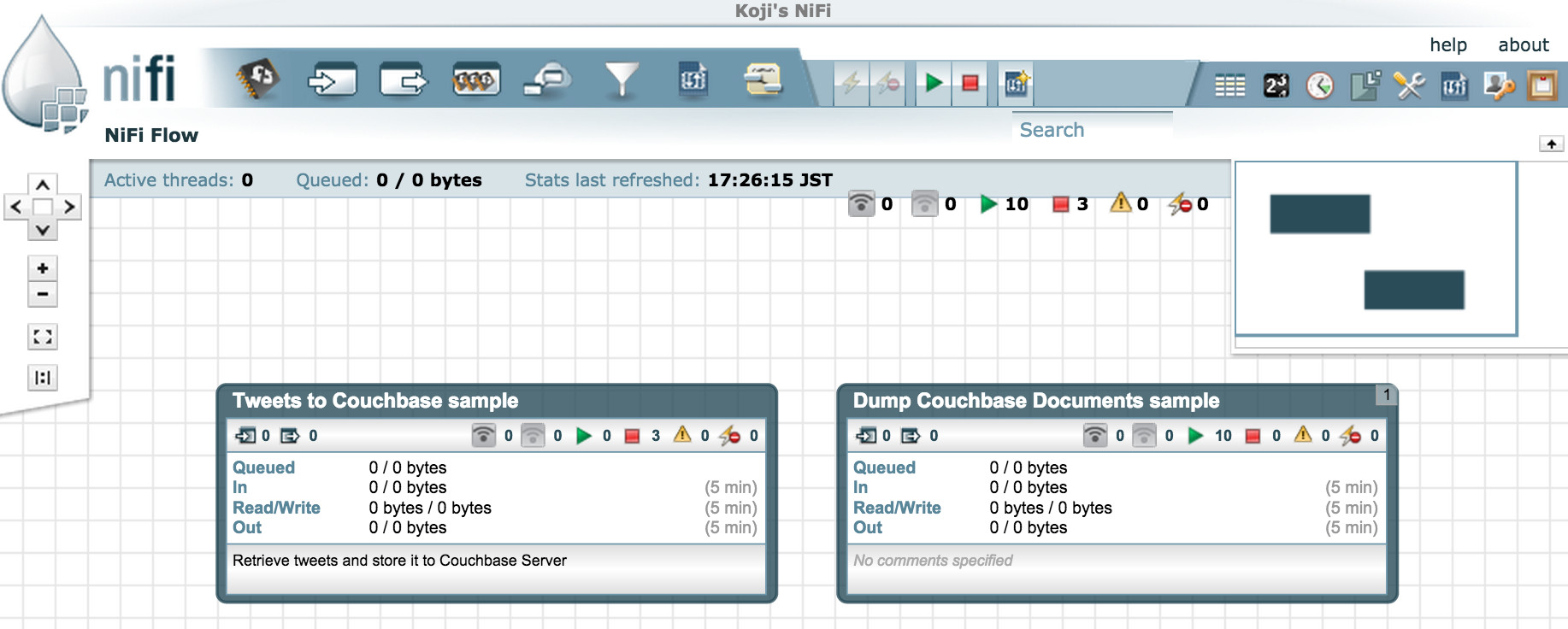
카우치베이스 서버 연결 설정: 카우치베이스클러스터서비스
Couchbase Server 클러스터에 대한 연결을 구성하는 방법을 설명하겠습니다.
실제 NiFi 데이터 흐름에서는 클러스터에서 데이터를 넣고 가져오기 위해 Couchbase 프로세서를 여러 번 사용해야 합니다. 따라서 각 프로세서에서 연결 설정을 구성하는 것은 좋은 생각이 아닙니다. 그렇게 하면 클러스터 설정이 여기저기 흩어져 있기 때문에 대상 클러스터를 변경하기가 어렵습니다.
이 문제를 방지하기 위해 NiFi는 컨트롤러 서비스라는 메커니즘을 제공하여 프로세서 간에 공유할 수 있는 중앙 구성 요소를 구성합니다. NiFi에는 RDBMS에 연결 풀링을 제공하는 컨트롤러 서비스와 같은 일부 기존 컨트롤러 서비스가 포함되어 있습니다. 그래서 저는 그 설계를 따라 CouchbaseClusterService를 구현했습니다.
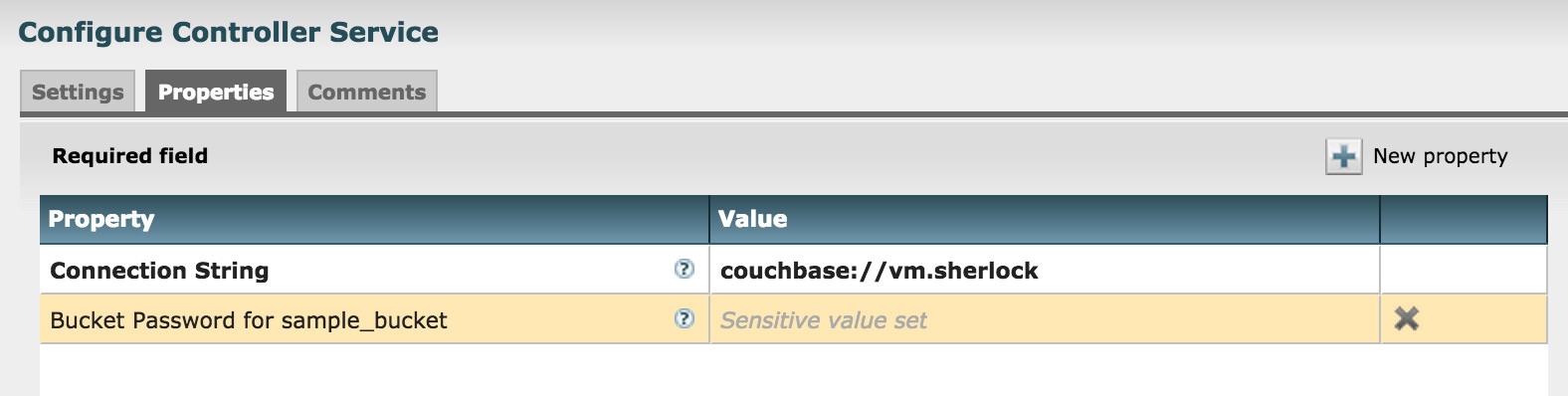
연결 문자열을 설정하여 액세스할 Couchbase Server 클러스터를 지정할 수 있습니다. 버킷에 비밀번호가 필요한 경우 여기서도 비밀번호를 설정할 수 있습니다. NiFi 구성에는 정적 및 동적 두 가지 유형의 속성이 있습니다. "연결 문자열"은 정적 속성이고 "{버킷_이름}의 버킷 비밀번호"는 동적 속성입니다. "새 속성" 버튼을 클릭하여 새 동적 속성 설정을 추가하여 다른 버킷에 대한 비밀번호를 지정할 수 있습니다.
다시 한 번 중요한 것은 모든 클러스터 수준 구성이 이 CouchbaseClusterService에 의해 관리된다는 것입니다. 다른 Couchbase 클러스터로 작업하려면 다른 CouchbaseClusterService를 추가하고 적절하게 구성하기만 하면 됩니다.
PutCouchbaseKey 예제: 카우치베이스 서버에 트윗 저장하기
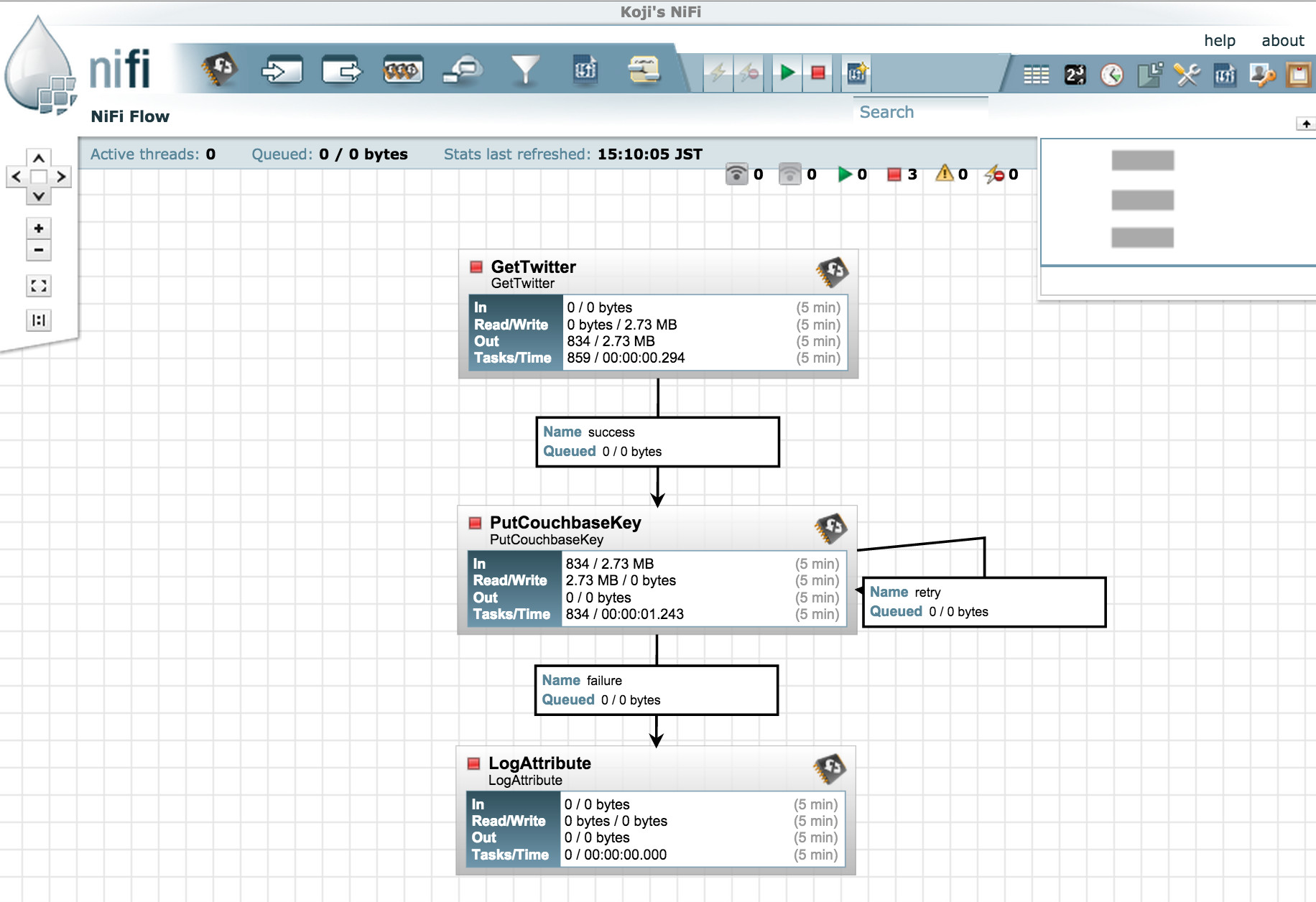
트위터 피드 처리는 스트림 데이터 흐름을 설명하는 데 사용할 수 있는 일반적인 예시입니다. 다음 이미지에서 볼 수 있듯이 NiFi와 Couchbase를 사용하면 매우 쉽게 처리할 수 있습니다:
-
GetTwitter: NiFi는 다양하고 유용한 프로세서 와 같이 다른 시스템과 쉽게 통합할 수 있습니다.
-
PutCouchbaseKey: 각 트윗은 FlowFile로 전송됩니다. 여기서는 FlowFile UUID를 Couchbase 문서 ID로 사용하여 저장합니다. 이미지에서 볼 수 있듯이 PutCouchbaseKey는 자체 "재시도" 관계를 가집니다. 일시적인 서버 측 오류로 인해 발생할 수 있는 경우와 같이 FlowFile이 CouchbaseExceptions로 실패하고 다시 시도할 수 있는 경우 "다시 시도" 관계로 전송합니다. 잘못된 구성이나 기타 심각한 오류와 같이 오류를 복구할 수 없는 경우에는 해당 플로우파일이 "실패" 관계로 전송됩니다.
-
LogAttibute: 플로우 끝에 LogAttribute 프로세서를 추가했는데, LogAttribute는 플로우 파일의 속성 및 콘텐츠에 대한 로그 메시지를 출력할 수 있습니다. 이는 발생할 수 있는 문제를 디버깅할 때 유용합니다.
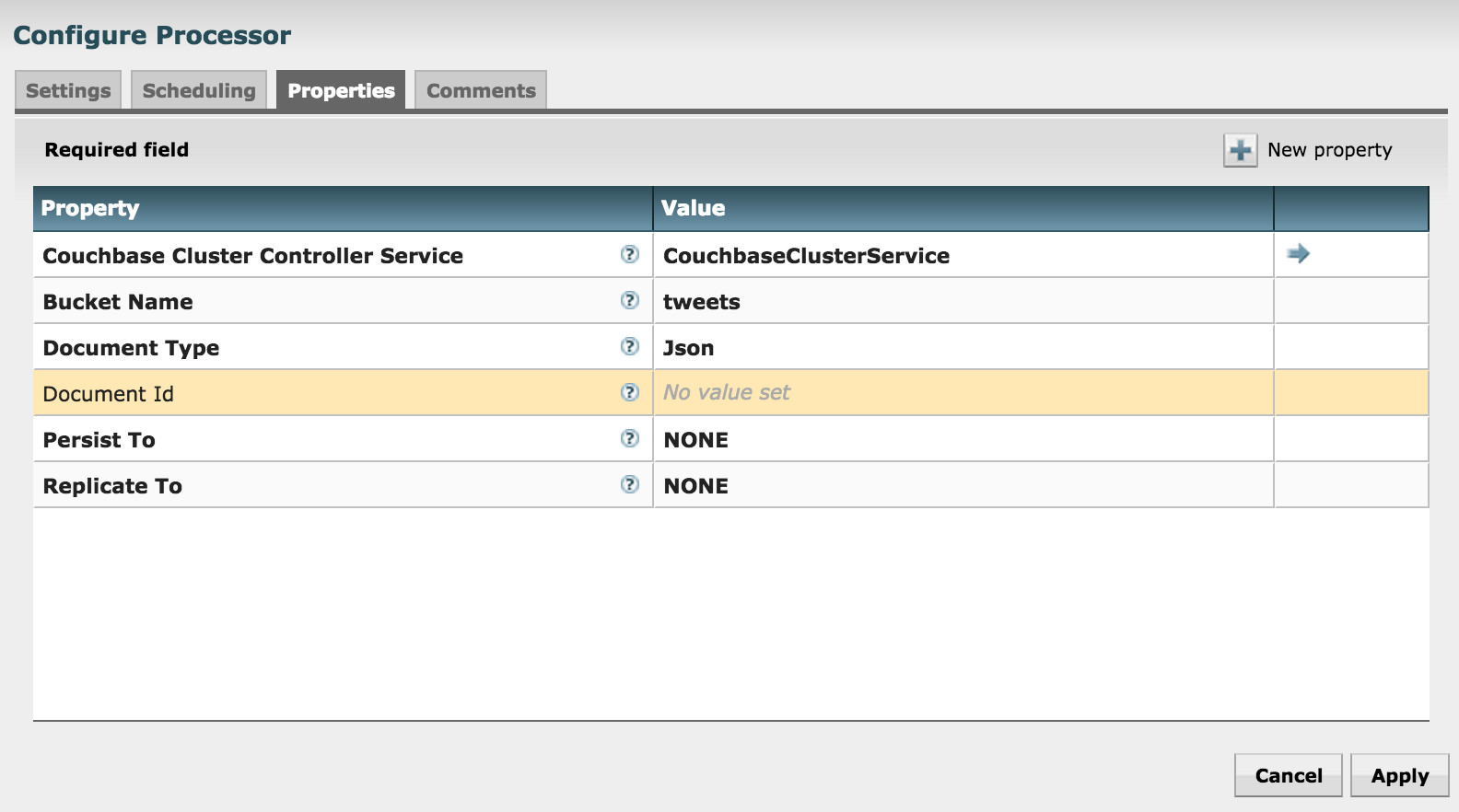
PutCouchbaseKey 구성을 살펴보겠습니다:
-
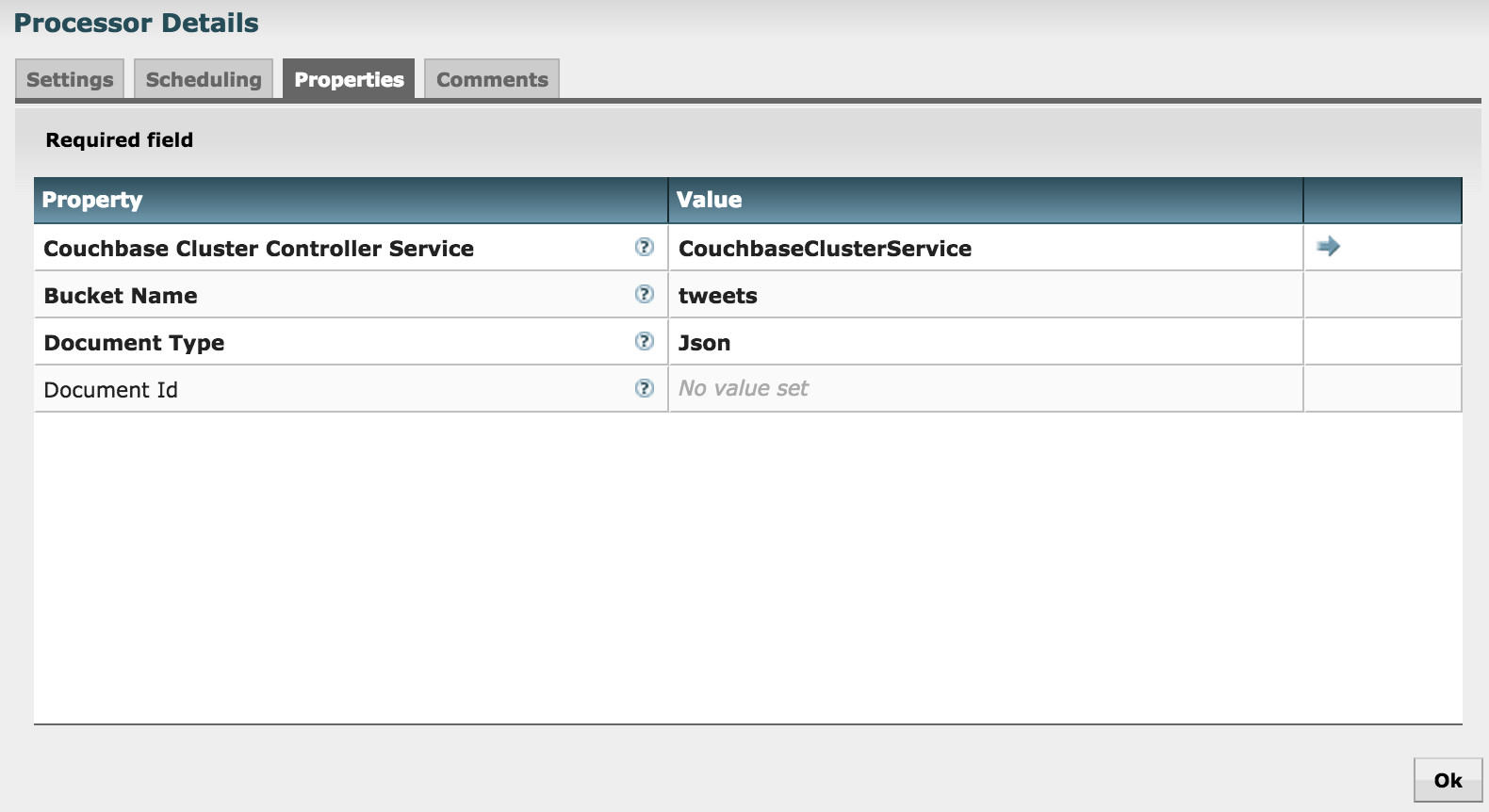
카우치베이스 클러스터 컨트롤러 서비스는 앞서 설명한 중앙 집중식 카우치베이스 컨트롤러 서비스를 말합니다.
-
버킷 이름은 콘텐츠를 저장할 버킷의 이름입니다.
-
문서 유형은 Json 또는 바이너리입니다.
-
프로세서가 FlowFile UUID를 문서 ID로 사용하도록 하기 위해 Document Id 속성을 비워 두었습니다. 또는 다음과 같이 지정할 수 있습니다. NiFi 표현식 언어 를 클릭하여 다른 속성 값을 사용하거나 문서 ID를 계산할 수 있습니다.
이제 CouchbaseClusterService와 프로세서를 구성했으니 NiFi 데이터 플로우를 시작하겠습니다. 녹색 삼각형 버튼을 누르기만 하면 됩니다. 그러면 트윗이 카우치베이스에 저장되고 있음을 확인할 수 있습니다!
GetCouchbaseKey 예제: 특정 Couchbase 문서를 하나의 Zip 파일로 다운로드하기
다른 시스템으로 보내거나 부분 백업을 하기 위해 Couchbase Server에서 특정 문서 집합을 다운로드하고 싶을 수 있습니다.
이를 위해 다음 이미지와 같이 데이터 흐름을 구성했습니다. 이전 트위터 예제보다 더 복잡하며 몇 가지 다른 유형의 프로세서를 사용합니다:
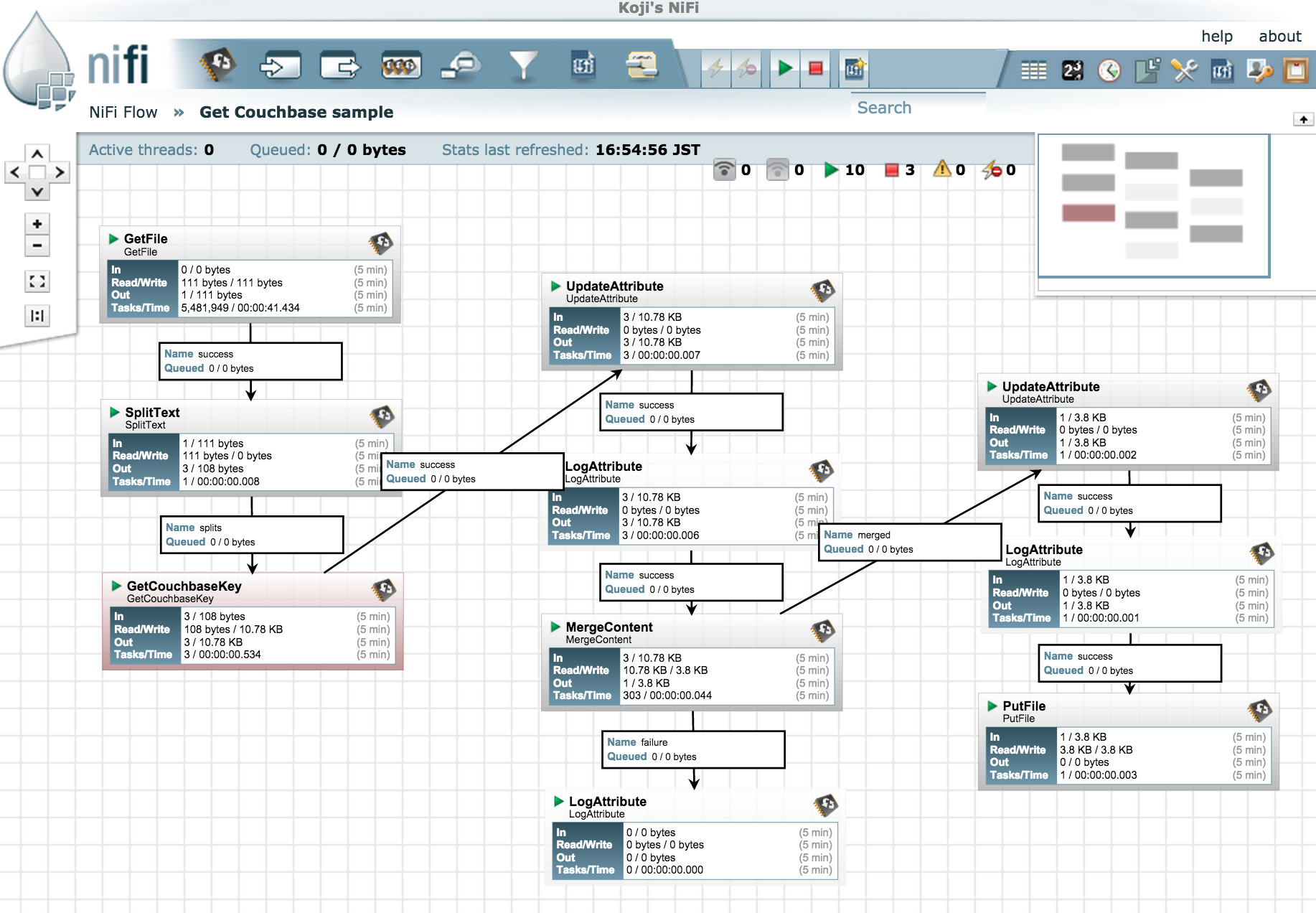
각 프로세서의 기능을 설명해 드리겠습니다:
-
GetFile: 지정된 디렉터리를 감시하고 대상 파일이 그 디렉터리에 들어가면 그 내용을 다음 프로세서로 전송합니다.
-
SplitText: 파일의 콘텐츠를 분할하여 각 줄을 FlowFile로 전송합니다.
-
GetCouchbaseKey: 들어오는 FlowFile 콘텐츠를 문서 ID로 사용하여 Couchbase에서 문서를 가져옵니다.
-
업데이트 속성: 최종 Zip 파일에 사용되는 실제 파일 이름에 Couchbase 문서 ID를 사용하기 위해 여기에 "couchbase.doc.id" 속성을 "파일 이름"에 복사했습니다.
-
MergeContent: 여러 개의 FlowFile을 하나의 Zip 파일로 병합 및 압축합니다.
-
업데이트 속성: "${now():format('yyyyMMdd_HHmmss')}.zip" 표현식을 사용하여 Zip 파일명을 현재 날짜로 설정합니다.
-
PutFile: 마지막으로 Zip 파일을 지정된 디렉터리에 넣습니다.
실제 디렉토리와 파일은 아래와 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 디렉토리 및 파일 drwxr-xr-x 2 누룩 휠 68B 10월 2 16:19 카우치베이스-덤프-in/ drwxr-xr-x 2 누룩 휠 68B 10월 2 16:29 카우치베이스-덤프-out/ -rw-r--r-- 1 누룩 휠 111B 10월 2 16:25 in.dat # 가져올 카우치베이스 문서 ID를 지정하세요. 누룩@Kojis-MacBook-Pro:tmp$ cat in.dat 000069ee-cf4d-46bb-a11d-de09a00cd82c 00021100-bb6c-4327-8cad-16474f5cd928 0004b561-1ea4-4e46-8455-2040481d638e # GetFile은 원본 파일을 삭제하여 다시 처리되지 않도록 합니다. # 다른 디렉터리에 파일을 생성하는 것이 좋습니다, #를 누른 다음 파일을 입력 디렉토리에 넣습니다. #(선택 사항, 원본 파일 보관 가능) 누룩@Kojis-MacBook-Pro:tmp$ cp in.dat 카우치베이스-덤프-in/ # NiFi 처리 후 Zip 파일이 생성됩니다. 누룩@Kojis-MacBook-Pro:tmp$ ll 카우치베이스-덤프-out/ 합계 8 -rw-r--r-- 1 누룩 휠 3.8K 10월 2 16:51 20151002_165136.zip # Zip 파일을 압축을 풀고 그 안에 JSON 파일이 저장되어 있는지 확인합니다. 누룩@Kojis-MacBook-Pro:카우치베이스-덤프-out$ 압축 해제 20151002_165136.zip 아카이브: 20151002_165136.zip 인플레이션: 000069ee-cf4d-46bb-a11d-de09a00cd82c 인플레이션: 00021100-bb6c-4327-8cad-16474f5cd928 인플레이션: 0004b561-1ea4-4e46-8455-2040481d638e |
이제 GetCouchbaseKey 구성을 살펴보겠습니다:
-
PutCouchbaseKey와 마찬가지로 Couchbase에 대한 연결은 ControllerService에서 구성됩니다.
-
들어오는 FlowFile 콘텐츠를 문서 ID로 사용하도록 하기 위해 문서 ID를 비워 두었습니다. 여기에서 표현식 언어를 지정하여 문서 ID를 구성할 수도 있습니다.
결론
프로그램을 작성하지 않고도 이와 같은 작업을 자동화할 수 있다는 것이 환상적이지 않나요? 지금은 간단한 키/값 액세스 프로세서만 제공되지만 창의적으로 사용할 수 있습니다! 앞으로 더 많은 프로세서를 추가하여 NiFi에서 View 및 N1QL 쿼리를 사용할 수 있도록 할 계획이며, 새로운 기능으로 다시 찾아뵙기를 고대하고 있습니다.
감사합니다, 행복한 데이터 처리!