Couchbase 7.1을 사용하면 수백 테라바이트의 JSON 데이터를 저장하고 밀리초 만에 쿼리할 수 있습니다. 7.1의 새로운 스토리지 엔진, 카우치베이스 마그마, 는 Couchbase를 가장 비용 효율적이고 성능이 뛰어난 데이터베이스로 만들어 TCO를 낮춥니다.
Magma 스토리지 엔진을 통해 Couchbase 7.1은 데이터 집약적인 사용 사례에 이상적인 데이터베이스가 됩니다. 이러한 사용 사례의 몇 가지 예로는 IoT 및 로깅과 같은 쓰기 작업이 많은 애플리케이션, 고객 포털과 같은 대용량 데이터 세트가 있는 읽기 작업이 많은 애플리케이션, 메타데이터 및 콘텐츠 스토어(사진/비디오 스토어), 사용자 프로필과 같은 대용량 데이터 세트가 있는 혼합 워크로드 등이 있습니다.
마그마의 장점과 사용 방법에 대해 자세히 알아보세요.
마그마 TCO 절감
마그마는 최소한의 메모리로도 작동할 수 있도록 설계되어 1%의 낮은 메모리 대 데이터 비율로 안정적으로 작동합니다. 예를 들어 노드에 1TB의 데이터를 저장하려는 경우, 주로 디스크에서 모든 데이터에 액세스하려는 경우 Magma를 실행하는 데 10GB의 메모리만 필요합니다. 작업 세트에 대해 인메모리(밀리초 미만) 액세스 속도를 원한다면 작업 세트를 나타내는 메모리 대 데이터 비율을 사용하는 것이 좋습니다.
Magma는 노드당 더 많은 양의 데이터를 저장할 수도 있습니다. 노드당 최대 10TB의 데이터를 테스트하고 인증했습니다(기본 및 복제 데이터 포함). 따라서 100TB의 데이터를 저장하려면 Couchbase 클러스터에 10대의 서버만 있으면 됩니다.
카우치스토어라는 기존 카우치베이스 스토리지 엔진에 익숙하다면, 카우치스토어는 최소 10%의 메모리 대 데이터 비율이 필요하며 노드당 2~3TB 이하의 데이터를 권장한다는 사실을 알고 계실 것입니다.
메모리 대 데이터 비율이 10%에서 1%로 감소하고 노드 밀도가 10TB의 데이터로 증가하면 대부분의 시나리오에서 서버가 10배 감소하고 이에 따라 TCO가 10배 절감됩니다.
마그마 성능 향상
For 디스크 기반 워크로드마그마는 성능을 크게 향상시킵니다. 성능 개선의 몇 가지 주요 사항은 다음과 같습니다:
-
- 혼합 디스크 기반 워크로드에 대해 현재 스토리지 엔진(Couchstore) 대비 4배의 처리량을 제공합니다. YCSB 벤치마크를 사용하여 사내에서 정기적으로 테스트합니다(아래 차트 참조).
- 읽기 지연 시간이 10배 개선되었습니다: 일반 SSD에서 99.9% 백분위수 < 10ms.
- 처리량 및 지연 시간 2배 개선 지속적인 내구성 쓰기 ACID 트랜잭션 워크로드에 사용됩니다.
- 20% 더 나은 압축으로 디스크 공간 소비를 줄입니다.

위는 정기적으로 실행되는 수정된 차트입니다. YCSB 워크로드 G. 읽기-수정-쓰기 워크로드에서 4배 이상의 처리량 향상을 보여줍니다. 100% 읽기-수정-쓰기 워크로드를 균일한 분포로 실행했습니다. 상주 비율은 약 30%이므로, 이 워크로드는 약 70%의 읽기가 디스크로 이동하는 디스크 사용량이 많은 워크로드입니다. 조각화 비율은 마그마와 카우치스토어 모두에 대해 50%로 설정되었습니다.
마그마의 마법
Magma는 어떻게 TCO와 성능에 대한 이러한 이점을 모두 달성할 수 있을까요? Magma는 Couchbase에서 자체 개발한 독점 아키텍처를 기반으로 다음과 같은 기능을 결합합니다. 로그 구조화된 병합 트리(LSM) 를 로그 구조화된 객체 저장소에서 값 분리와 함께 사용할 수 있습니다. 이 조합은 다음과 같은 상용 LSM 기반 스토리지 엔진에 비해 읽기 증폭, 쓰기 증폭, 공간 증폭에 대한 효율성 지표가 훨씬 뛰어난 스토리지 엔진을 생성합니다. RocksDB.
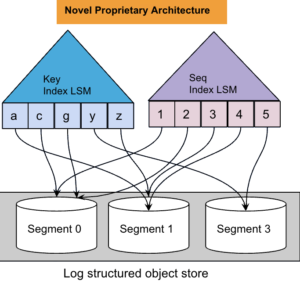
마그마 스토리지 엔진 아키텍처.
마그마는 지속적으로 진행되는 마이크로 압축을 통해 확장 가능한 증분 압축을 지원하므로 압축으로 인한 읽기 또는 쓰기 중단이 눈에 띄지 않습니다. 또한 압축은 병렬로 이루어지므로 기본 IO 하위 시스템 병렬성의 이점을 활용할 수 있습니다. 또한 세분화되고 지속적인 압축은 공간 증폭을 줄여 필요한 디스크 공간의 총량을 줄여줍니다. Magma는 문서 수준 압축만 하는 것보다 더 나은 압축률을 제공하는 블록 압축을 수행하여 필요한 디스크 공간의 양을 더욱 줄여줍니다.
Magma 사용 방법
일단 카우치베이스 클러스터 설정를 클릭하면 스토리지 엔진을 Magma로 선택한 Couchbase 버킷(버킷은 카우치베이스에서 데이터베이스와 같습니다)을 만들 수 있습니다. 예, 버킷별로 Magma 스토리지 엔진을 선택할 수 있습니다. Magma 버킷 몇 개와 Couchstore 버킷 몇 개가 포함된 단일 Couchbase 클러스터를 가질 수 있습니다. 이렇게 하면 기존 Couchbase 클러스터에서 Magma를 더 쉽게 사용해 볼 수 있습니다. Magma가 이상적인 데이터 집약적 사용 사례의 경우, 클러스터에 Magma 전용 버킷이 필요할 것입니다.
마그마 버킷의 경우 배출 방법을 다음과 같이 설정하는 것이 좋습니다. 전체 이는 특히 낮은 메모리 대 데이터 비율로 실행하는 경우 키까지 캐시에서 퇴출됨을 의미합니다). 전체 배출은 마그마 버킷의 기본 선택 사항입니다.
Magma를 선택 항목으로 하여 버킷을 생성한 후에는 이 버킷을 사용하여 Couchbase API를 사용하여 데이터를 로드하고 쿼리할 수 있습니다.
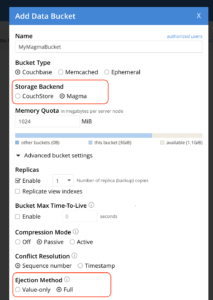
카우치베이스 관리자 UI에서 마그마 버킷 생성하기.
TCO 절감을 위한 다음 단계
Magma 스토리지 엔진은 수백 테라바이트의 데이터로 구성된 대규모 데이터 세트를 위한 고성능 디스크 지향 데이터베이스로 Couchbase 7.1을 만들어 줍니다. 필요한 메모리 대 데이터 비율이 1%로 낮기 때문에 필요한 서버 수에 비해 TCO를 크게 절감할 수 있습니다. Couchbase 7.1은 이전에는 비용이 많이 들었던 사용 사례를 해결하고 데이터가 급격하게 증가하는 곳에서 TCO를 절감할 수 있습니다. 지금 Couchbase를 다운로드하여 이 새로운 혁신을 직접 체험해 보세요.
다음 리소스를 통해 자세히 알아보세요: