Las consultas analíticas ad hoc típicas tienen que procesar muchos más datos de los que caben en la memoria. Consecuentemente, esas consultas tienden a estar limitadas por E/S. Cuando el servicio Analytics fue introducido en Couchbase 6.0, permitió a los usuarios especificar múltiples "Analytics Disk Paths" durante la inicialización del nodo. En este artículo, realizamos un par de experimentos en diferentes instancias en la nube para mostrar cómo configurar correctamente múltiples "Analytics Disk Paths" y cómo esta característica puede ser utilizada para acelerar las consultas de Analytics.
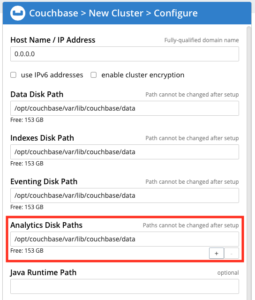
Figura 1: Especificación de las rutas de disco de Analytics durante la inicialización del nodo
Durante la inicialización del nodo, se puede utilizar cualquier ruta única del sistema de archivos como "Ruta de disco de análisis", independientemente del dispositivo de almacenamiento físico real en el que resida esta ruta. Se pueden utilizar múltiples rutas que residan en el mismo dispositivo. Los datos del servicio Analytics se dividen en todas las "rutas de disco Analytics" especificadas en todos los nodos que tienen el servicio Analytics. Por ejemplo, si un cluster tiene dos nodos con el servicio Analytics y uno de los nodos tiene especificadas 4 "Rutas de Disco Analytics", y el otro nodo tiene 8 "Rutas de Disco Analytics", cada conjunto de datos creado en Analytics tendrá un total de 12 particiones (particiones de datos).
Durante la ejecución de la consulta, el motor de consulta MPP de Analytics intenta leer y procesar simultáneamente los datos de todas las particiones de datos. Por ello, las operaciones de entrada/salida por segundo (IOPS) del disco físico real en el que reside cada partición de datos desempeñan un papel fundamental a la hora de determinar el tiempo de ejecución de la consulta.
Los dispositivos de almacenamiento modernos, como los SSD, tienen IOPS mucho mayores y pueden gestionar mejor las lecturas simultáneas que los HDD. Por lo tanto, tener una única partición de datos en dispositivos con altas IOPS no utilizará completamente sus capacidades. Para simplificar la configuración del caso típico de un nodo que tiene un único dispositivo de almacenamiento moderno, el servicio Analytics crea automáticamente múltiples particiones de datos dentro del mismo dispositivo de almacenamiento si y sólo si se especifica una única "Ruta de Disco Analytics" durante la inicialización del nodo. El número de particiones de datos creadas automáticamente se basa en esta fórmula:
|
1 2 |
Maximum partitions to create = Min((Analytics Memory in MB / 1024), 16) Actual created partitions = Min(node virtual cores, Maximum partitions to create) |
Por ejemplo, si un nodo tiene 8 núcleos virtuales y el servicio de Análisis fue configurado con memoria >= 8GB, se crearán 8 particiones de datos en ese nodo. Del mismo modo, si un nodo tiene 32 núcleos virtuales y se configuró con memoria >= 16GB, sólo se crearán 16 particiones ya que las particiones máximas que se crearán automáticamente tienen un límite superior de 16 particiones.
Para mostrar el impacto en el rendimiento del número de particiones de datos por disco, realizamos un par de experimentos en diferentes tipos de instancia en Amazon Web Services EC2 utilizando Couchbase Server 6.5 Beta 2. Los datos utilizados en los experimentos son una versión JSONificada del famoso TPC-DS donde cada fila se convirtió en un documento JSON con un campo adicional que identifica el nombre de la tabla a la que pertenece el documento. Se generaron datos TPC-DS de muestra y se cargaron en un bucket denominado tpcds. En ambos experimentos, al servicio Analytics se le asignaron 32 GB de memoria.
Experimento 1: Instancia única con 8 núcleos virtuales y 1 SSD NVMe
En este experimento, creamos 3 conjuntos de datos en el servicio Analytics, como se indica a continuación:
|
1 2 3 |
CREATE DATASET store_sales ON tpcds WHERE table_name='store_sales'; CREATE DATASET date_dim ON tpcds WHERE table_name='date_dim'; CREATE DATASET item ON tpcds WHERE table_name='item'; |
Utilizamos la siguiente consulta de cualificación TPC-DS tras convertirla en una consulta N1QL for Analytics para medir el tiempo de respuesta bajo dos configuraciones diferentes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT dt.d_year, item.i_brand_id brand_id, item.i_brand brand, sum(ss.ss_ext_sales_price) sum_agg FROM date_dim dt, store_sales ss, item WHERE dt.d_date_sk = ss.ss_sold_date_sk AND ss.ss_item_sk = item.i_item_sk AND item.i_manufact_id = 128 AND dt.d_moy=11 GROUP BY dt.d_year, item.i_brand, item.i_brand_id ORDER BY dt.d_year, sum_agg DESC, brand_id LIMIT 100; |
Para la primera configuración, especificamos dos "Analytics Disk Paths" en el mismo disco, lo que dio lugar a que cada conjunto de datos tuviera 2 particiones de datos. En cuanto a la segunda configuración, sólo se especificó una "Datos analíticos Se especificó "Rutas", lo que activó la opción de configuración automática. Como el nodo tiene 8 núcleos virtuales, se crearon automáticamente 8 particiones de datos. La figura 2 muestra los tiempos medios de respuesta de consulta para estas dos configuraciones. En términos de tiempo medio de respuesta de consulta, la configuración automática con 8 particiones fue más del doble de rápida que la configuración con sólo 2 particiones de datos. Esta mejora se debió a una mejor utilización del único SSD NVMe, ya que este tipo de disco puede gestionar 8 lecturas simultáneas. Además, dado que esta consulta implica agrupación y clasificación, el procesamiento de los datos de forma concurrente en 8 particiones se tradujo en una mejora significativa del rendimiento de la consulta.
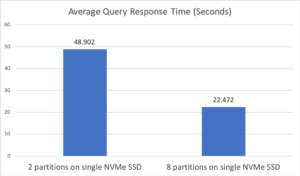
Figura 2: Tiempo medio de respuesta de la consulta del Experimento 1
Experimento 2: Instancia única con 8 núcleos virtuales y 6 discos duros
En este experimento, intentaremos escanear un mayor volumen de datos creando un único conjunto de datos que contenga todos los datos del bucket tpcds de la siguiente manera:
|
1 |
CREATE DATASET tpcds on tpcds; |
Utilizamos la siguiente consulta de N1QL for Analytics que da como resultado el escaneo de todos los datos utilizando dos configuraciones diferentes:
|
1 2 3 |
SELECT SUM(ss_ext_sales_price) FROM tpcds WHERE table_name = "store_sales"; |
Para la primera configuración, se especificó una única "Ruta de datos analíticos"; esto dio lugar a que el sistema creara automáticamente 8 particiones en un directorio solo HDD. En la segunda configuración, se especificaron 6 "rutas de datos analíticos" y cada ruta se ubicó en un disco duro físico diferente, lo que dio lugar a 6 particiones de datos. La figura 3 muestra el tiempo medio de respuesta de las dos configuraciones. En la primera configuración, la realización de 8 lecturas simultáneas en un único disco duro dio lugar a un rendimiento deficiente. Uno de los principales motivos es que no se utiliza el ancho de banda de E/S de los otros 5 discos duros. Además, la concurrencia de 8 lecturas en un único disco duro provocaba un mayor movimiento de los brazos del disco, lo que aumentaba el coste medio de una E/S de disco. La segunda configuración, que utilizó los 6 discos duros simultáneamente, mejoró el rendimiento en más de 7 veces.
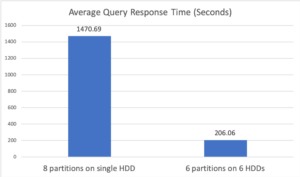
Figura 3: Tiempo medio de respuesta de las consultas del Experimento 2
Conclusión:
El motor Analytics es un completo procesador de consultas paralelas que admite uniones, agregaciones y ordenaciones paralelas, basadas en los mejores algoritmos extraídos de más de 30 años de I+D en MPP relacional, pero para datos JSON. Mediante dos experimentos, demostramos el importante impacto en el rendimiento que pueden tener las distintas opciones de configuración de las "rutas de disco analíticas". También demostramos cómo el motor Analytics puede utilizar múltiples discos físicos, cuando están disponibles, para acelerar significativamente las consultas Analytics.