Estoy ocupado trabajando en algunos SQL Server a Servidor Couchbase pero mientras tanto, he pensado en dejaros una castaña de JSON para el fin de semana de Navidad.
Wikibase tiene una enorme base de datos de información. Todo tipo de información. Y está disponible para descargar en formato JSON. Bueno, todavía no sé exactamente qué voy a hacer con ella, pero pensé que sería útil importar esos datos a Couchbase para poder ejecutar algunas consultas N1QL en ella.
Para ello, voy a utilizar cbimport.
Obtener los datos de Wikibase
Descargas de Wikibase están disponibles en JSON, XML y RDF.
El archivo que descargué era wikidata-20161219-all.json.bz2que pesa más de 6 GB. Lo descomprimí a wikidata-20161219-all.jsonque son casi 100 GB. Esto es un montón de datos empaquetados en un solo archivo.
Dentro del archivo, los datos están estructurados como un gran array JSON que contiene objetos JSON. Mi objetivo era crear un documento Couchbase para cada objeto JSON de ese array.
Uso de cbimport
cbimport es una práctica utilidad para importar datos (JSON y CSV) que vienen con Couchbase Server.
Es necesario que le digas a esta herramienta de línea de comandos:
-
json o csv ⇒ Qué tipo de archivo está importando
-
-c ⇒ Dónde está tu cluster
-
-b ⇒ El nombre del cubo al que quieres importar
-
-u y -p ⇒ Credenciales del clúster
-
-d ⇒ La URL al conjunto de datos a importar (como mi archivo es local, uso un
archivo://URL)
También he utilizado estas opciones:
-
-generar-clave ⇒ Indica a cbimport cómo construir la clave de cada documento. Si cada documento tiene una
idpor ejemplo, podría especificar una plantilla de%id%para utilizarlo como clave -
-formato lista ⇒ Indica a cbimport el formato del fichero. Algunas opciones son Líneas, Lista, Muestra. Usé "Lista" porque el JSON está todo en un archivo, pero no es un objeto JSON por línea.
Uso de cbimport en los datos de Wikibase
Tengo Couchbase Server instalado en la unidad E. Desde la carpeta donde está el archivo wikidata json (el mío se llama wikidata-20161219-all.json, pero el tuyo puede ser diferente) ejecuté:
E:CouchbaseServerbincbimport.exe json -c couchbase://localhost -u Administrador -p contraseña -b wikibase file://wikidata-20161219-all.json --generate-key %id% --format list
Basado en el Documentación sobre el modelo de datos de WikibaseSabía que habría un id en cada elemento con un valor único. Por eso utilicé %id%. Se puede generar una clave más compleja con el relativamente robusto plantillas generadoras de claves que ofrece cbimport.
Mientras cbimport se ejecutaba, monitoricé cuidadosamente el uso de memoria de cbimport, ya que temía que tuviera algún problema con el enorme conjunto de datos. Pero no hubo problema, no superó los 21mb de uso de RAM mientras se ejecutaba.
Empecé con 512mb de RAM y moví a 924mb de RAM a mi bucket en Couchbase durante la importación. Sólo tengo un nodo. Por lo tanto, esperaba que esto significara que una gran cantidad de expulsiones de la caché tendría lugar. Eso es lo que ocurrió.
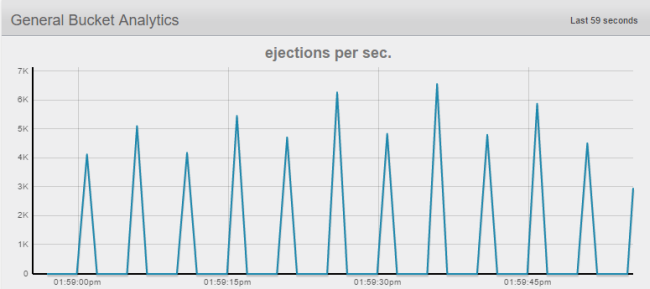
El archivo total es de 99gb, así que no hay forma de que quepa todo en la RAM de mi escritorio. En producción, 99 +gb no sería poco realista para caber en la memoria RAM con un puñado de nodos. Como wikibase sigue creciendo, podría ser acomodado por Fácil escalabilidad de Couchbase: basta con acumular otro servidor y seguir adelante.
Tarda mucho en ejecutarse en mi ordenador de sobremesa. De hecho, mientras escribo esta entrada del blog, todavía se está ejecutando. Ha llegado a 5,2 millones de documentos y sigue (no sé cuántos registros hay en total, pero el uso del disco está actualmente en 9,5gb, así que creo que me queda un largo camino por recorrer).
Cuando esté terminado, espero poder ejecutar algunas consultas N1QL interesantes con estos datos (hay algunas ejemplos que ofrece Wikibase que utilizan un motor de consulta "Gremlin en lugar de SQL).
Resumen
Si estás interesado en trabajar con los datos de Wikibase o cualquier gran repositorio de datos que ya esté en formato JSON, es muy fácil llevarlos a Couchbase con cbimport.
Ahora que tengo un gran conjunto de datos de Wikibase, mi próximo objetivo será averiguar algunas cosas interesantes que podría utilizar N1QL para consultar los datos.
Si tiene alguna pregunta, deje un comentario o Háblame en Twitter.
Hola Matthew,
Gran artículo, sólo quería hacer un comentario sobre cómo se ejecuta cbimport en diferentes sistemas operativos, ya que hay ligeras diferencias. También parece que los caracteres de barra desaparecieron del comando, que debería parecerse a la siguiente (esperemos que no se matan en el comentario, también):
E:\Couchbase\Server\bin\cbimport.exe json -c couchbase://localhost -u Administrator -p password -b wikibase file://wikidata-20161219-all.json -generate-key %id% -format list
Entonces, ¿cómo ejecutar cbimport en Mac OS, Windows y Linux? Supongamos que estamos cargando documentos en el bucket "por defecto" desde un archivo con formato CSV "prueba.csv" mientras estamos conectados como "prueba.usuario". El archivo CSV tiene la columna EXPERIMENT_ID; utilizaremos sus valores como claves del documento. Couchbase se ejecuta en localhost (127.0.0.1).
Mac OS (desde la ventana del terminal):
>> cd /Aplicaciones/Servidor Couchbase.app/Contenidos/Recursos/couchbase-core/bin
>> ./cbimport csv -c couchbase://127.0.0.1:8091 -u Administrador -p contraseña -b por defecto -d file:///Usuarios/prueba.usuario/Escritorio/prueba.csv -g csv::%EXPERIMENT_ID%
Tenga en cuenta los tres caracteres de barra en el prefijo de protocolo "file:///", a menos que el archivo se encuentre en el directorio actual (entonces es "file://test.csv").
Windows (desde el símbolo del sistema):
>> cd "C:\Archivos de Programa\Couchbase\Server\bin"
>> cbimport.exe csv -c couchbase://127.0.0.1:8091 -u Administrador -p contraseña -b por defecto -d archivo://C:/Usuarios/prueba.usuario/Escritorio/prueba.csv -g csv::%EXPERIMENT_ID%
Observe los dos caracteres de barra oblicua en el prefijo de protocolo "file://".
Ubuntu Linux (desde la ventana del terminal):
>> cd /opt/couchbase/bin
>> ./cbimport csv -c couchbase://127.0.0.1:8091 -u Administrador -p contraseña -b por defecto -d file:///home/test.user/test.csv -g csv::%EXPERIMENT_ID%
Tenga en cuenta los tres caracteres de barra en el prefijo de protocolo "file:///", a menos que el archivo se encuentre en el directorio actual (entonces es "file://test.csv").
[...] Uso de cbimport para importar datos de Wikibase a documentos JSON [...]