¿Por qué la búsqueda semántica necesita selectividad?
Hasta ahora, considerábamos una incrustación vectorial como una entidad completa e independiente, centrada exclusivamente en el significado que codifica. Aunque esto permite la búsqueda semántica, a menudo con un alto grado de similitudse limita a la similitud entre la consulta y el conjunto de datos.
No se podía confiar en que la oferta de búsqueda de similitudes vectoriales satisficiera predicados exactos. El prefiltrado pretende colmar exactamente esta laguna, buscando vectores similares sólo entre los que satisfacen algunos criterios de filtrado.
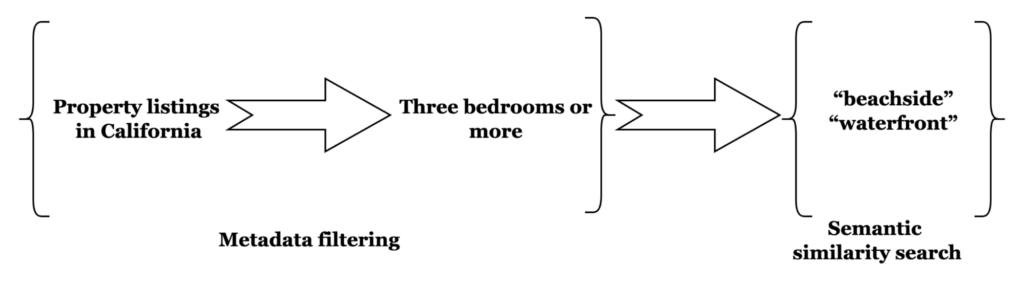
Es el equivalente en incrustación de limitar tu búsqueda, ya sea de trabajo o de una propiedad, a una ubicación. Por ejemplo, si quiere una vivienda en primera línea de playa en un estado concreto. También quiere limitar su búsqueda a las que tienen tres dormitorios o más. Recorrer los listados sin un método para filtrar por estos criterios es casi inviable dada la gran cantidad de listados.
Con el prefiltrado, puede limitar su búsqueda a una ubicación específica restringiendo el espacio de búsqueda a las propiedades elegibles mediante consultas geoespaciales y numéricas. Sobre este subconjunto limitado se realizará una búsqueda de similitud vectorial de propiedades "frente a la playa", "junto a la playa", "frente al mar".
El filtrado previo permitirá a los usuarios especificar consultas de filtrado como parte del atributo kNN en la consulta, cuyos resultados sólo se considerarán aptos para ser devueltos por la consulta kNN. En pocas palabras, el usuario puede utilizar la conocida sintaxis de consulta FTS para restringir los documentos sobre los que se realizará una búsqueda kNN.
¿Cuándo aplicar el prefiltrado?
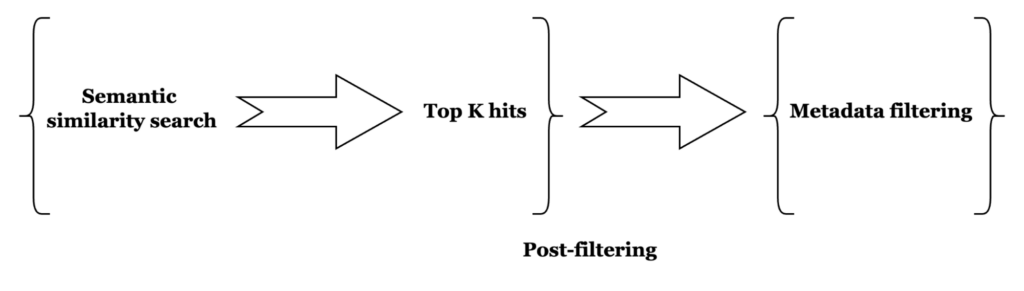
Como su nombre indica, las incrustaciones son metadatos filtrados antes de la búsqueda de similitudes. Es diferente del postfiltrado, en el que la búsqueda kNN va seguida de un filtrado de metadatos. El prefiltrado ofrece muchas más posibilidades de obtener k resultados positivos, siempre que al menos esos documentos superen la fase de filtrado.

Cómo funciona
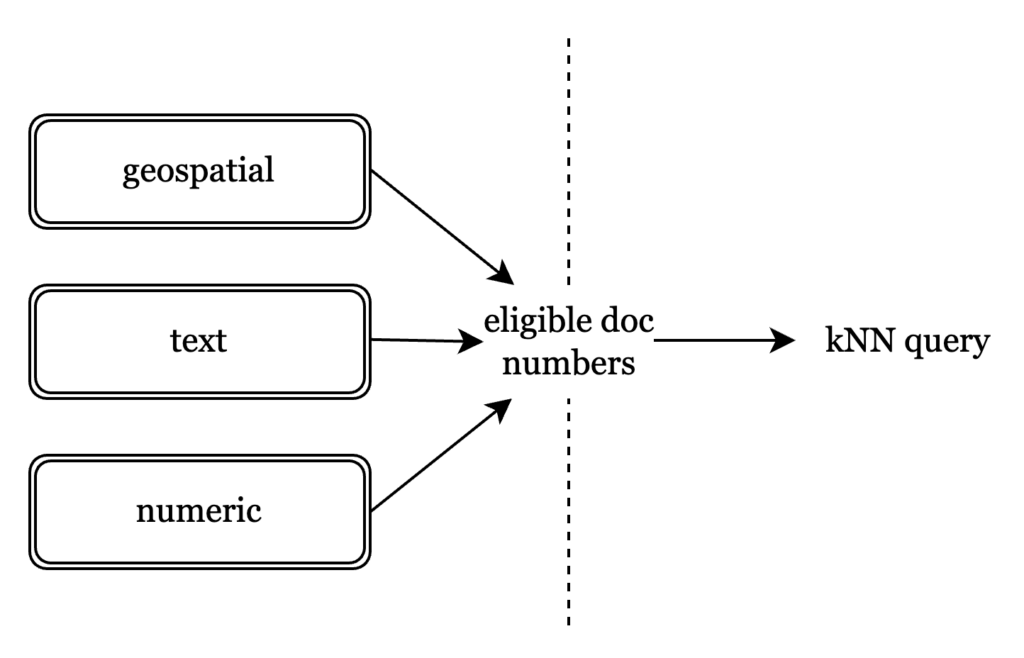
Antes de adentrarnos en las tripas del prefiltrado con kNN, vamos a entender cómo un vector y un índice de texto completo se ubican conjuntamente en el índice del servicio de Búsqueda. Cada índice de búsqueda tiene una o más particiones, cada una de las cuales tiene uno o más segmentos. Cada uno de estos segmentos es un fichero, y el fichero se divide en secciones separadas, una por cada tipo de índice. La visualización de un segmento como una unidad autónoma con contenido tanto textual como vectorial de un lote de documentos indexado será útil para comprender cómo funciona el prefiltrado a nivel de segmento.
 Una consideración clave a la hora de construirlo fue que debía ser agnóstico de predicción en el momento de la búsqueda. Esencialmente, esto significa que el filtrado en el índice vectorial debería funcionar de la misma manera, independientemente del predicado de texto completo. Un predicado de texto sobre un campo de texto no debería ser diferente de un predicado numérico sobre otro.
Una consideración clave a la hora de construirlo fue que debía ser agnóstico de predicción en el momento de la búsqueda. Esencialmente, esto significa que el filtrado en el índice vectorial debería funcionar de la misma manera, independientemente del predicado de texto completo. Un predicado de texto sobre un campo de texto no debería ser diferente de un predicado numérico sobre otro.
Para ello, se utilizan números de documento, identificadores exclusivos de un documento, para delimitar qué documentos son aptos para la consulta kNN. Toda consulta FTS, ya sea textual, numérica o geoespacial, se reduce a identificar los resultados por su número de documento. Utilizar números de documento significa que no tenemos que cambiar nuestra estrategia de indexación de vectores, y limitarla a un cambio en el tiempo de búsqueda.
Fase 1: Filtrado de metadatos
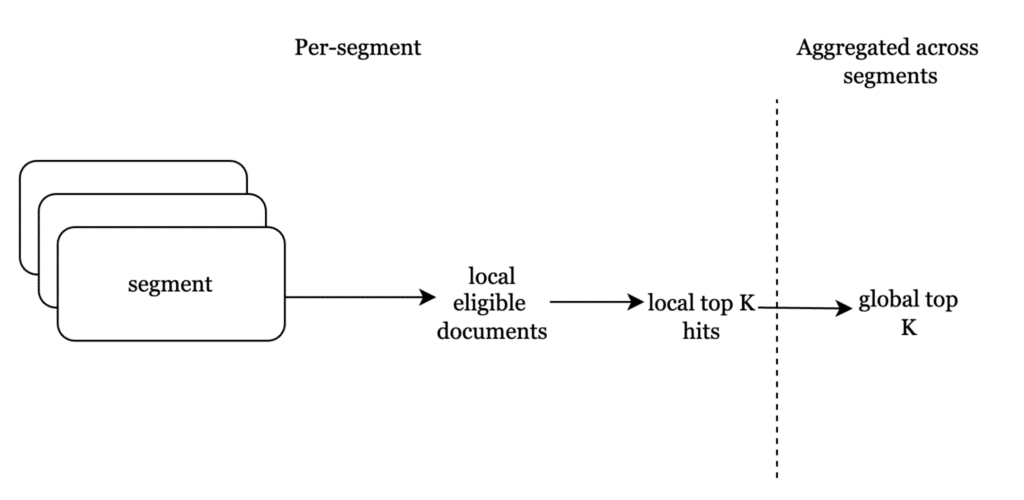
Dado que un segmento es esencialmente un lote inmutable de documentos, con su contenido textual y vectorial indexado, la consulta de metadatos de texto completo devuelve todos los documentos elegibles. a nivel de segmento. A continuación, sus números de documento se pasan al índice de vectores para recuperar los vectores elegibles más cercanos.
Fase 2: búsqueda kNN

Un grupo más cerca al vector de consulta podría tener muchas menos coincidencias elegibles que uno mucho más alejado.
Tener en cuenta la distribución de los aciertos de filtro y mantener al mismo tiempo una alta recuperación significa que no podemos escanear los conglomerados basándonos únicamente en la densidad de aciertos de filtro. Lo que sí significa es que intentamos minimizar los cálculos de distancia para los vectores no elegibles, incluso cuando escaneamos tantos conglomerados como sea necesario para devolver el k vecinos más cercanos.
Antes, nprobe se definió como el límite absoluto al número de clusters escaneados. Ahora, se trata más bien de un número mínimo de clusters a escanear suponiendo que menos clusters tengan suficientes vectores elegibles. En los casos de distribución dispersa de aciertos de filtro, en los que cada conglomerado tiene relativamente pocos vectores elegibles, nuestra búsqueda de k vecinos más cercanos puede llevarnos a escanear mucho más que nprobe clusters. Tanto el kNN filtrado como el no filtrado escanean los clusters en orden creciente de distancia al vector de consulta, con la diferencia de que escanean un subconjunto de vectores a través de un número potencialmente mayor de clusters.
|
1 2 3 4 5 6 7 8 9 10 11 |
eligible_clusters: clusters with at least 1 filtered hit if eligible_clusters < nprobe : scan all clusters else: total_hits(1,n): Cumulative count of eligible hits in closest 'n' eligible clusters if total_hits(1,nprobe) >= k: scan nprobe eligible clusters else: while total_hits(1,n) < k: n++ scan n eligible clusters |
Una vez que el índice vectorial devuelve los vectores más similares a nivel de segmento, éstos se agregan a nivel de índice global de forma similar a como se hace para kNN sin filtrado.
Cómo utilizarlo
Cojamos un cubo, hitos. Este es un documento de muestra:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "title": "Los Angeles/Northwest", "name": "El Cid Theatre", "alt": null, "address": "4212 W Sunset Blvd", "directions": null, "phone": null, "tollfree": null, "email": null, "url": null, "hours": null, "image": null, "price": null, "content": "Built around turn of the century and, after several reincarnations, offers one of the only dinner theater options left in Los Angeles. The menu is heavily Spanish and the shows differ depending on the night and range from flamenco performances to tongue-in-cheek burlesque.", "geo": { "accuracy": "ROOFTOP", "lat": 34.0939, "lon": -118.2822 }, "activity": "do", "type": "landmark", "id": 35034, "country": "United States", "city": "Los Angeles", "state": "California", "embedding_crc": "fa6edfd97ffa665b", "embedding": [-0.003134159604087472, -0.020280055701732635,.... -0.014541691169142723] } |
Crea un índice, prueba, que indexa el incrustación, id y ciudad campos.
Mi primera consulta es una incrustación del Museo de Ingenieros Reales de Gillingham:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "knn": [ { "k": 10, "field": "embedding", "vector": [ 0.0022478399332612753, .... ] } ], "explain": true, "size": 10, "from": 0 } |
Los más cercanos son el Museo de la Brigada de Bomberos de Londres, el Museo Verulamium de St Albans y el Museo de la RAF de Londres.
Ahora queremos buscar museos similares en Glasgow, es decir, el campo ciudad debe tener un valor Glasgow.
Este es el aspecto de la consulta filtrada, con la opción filtro cláusula añadida:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "knn": [ { "k": 10, "field": "embedding", "vector": [ 0.0022478399332612753, .... ], "filter": { "match": "Glasgow", "field": "city" } } ], "explain": true, "size": 10, "from": 0 } |
Como era de esperar, los resultados se limitan ahora a los de Glasgow: los más cercanos son la Galería de Arte y Museo Kelvingrove y el Museo Riverside.
Como se ve en este ejemplo, una consulta kNN filtrada ofrece la ventaja de seleccionar los documentos para una búsqueda por similitud utilizando las buenas y viejas consultas FTS.
Seguir aprendiendo
-
- Lea el blog para saber más sobre FAISS y la indexación vectorial, Rendimiento de la búsqueda vectorial: El aumento de la recuperación
- Cree aplicaciones LLM más rápidas y baratas con Couchbase
- ¿Qué es la búsqueda semántica?
- Empieza a usar Couchbase Capella hoy mismo, gratis
