En esta entrada de blog, la primera de una serie, vamos a mostrarte cómo configurar un servidor Prometheus y conectarlo a tu base de datos Couchbase Capella para recopilar métricas.
¿Qué es Prometeo?
Prometeo es un conjunto de herramientas de supervisión y alerta de sistemas de código abierto muy popular, con una comunidad de desarrolladores y usuarios muy activa. Se creó originalmente en SoundCloudpero ahora es un proyecto independiente de código abierto, mantenido con independencia de cualquier empresa, y se unió a la iniciativa Fundación para la Computación Nativa en la Nube en 2016 como segundo proyecto acogido, tras Kubernetes.
¿Qué es Couchbase Capella?
Couchbase Capella es nuestra oferta de base de datos como servicio (DBaaS) totalmente gestionada, la forma más fácil y rápida de empezar con Couchbase y eliminar los esfuerzos continuos de gestión de bases de datos. Su base de datos Capella contiene un objetivo de raspado Prometheus nativo, lo que le permite conectar sus sistemas de monitoreo Prometheus (o compatibles con Prometheus) para recopilar métricas.
Requisitos previos
Para seguir los pasos de esta guía, necesitará una instalación Docker en funcionamiento (que utilizaremos para desplegar Prometheus), una base de datos Capella y algunas utilidades shell comunes.
Nota: Queda fuera del alcance de este post mostrar cómo instalar y configurar Docker. Existen muchos tutoriales, incluido el propio de Docker Introducción a Docker. En este punto, supondremos que lo ha instalado y probado correctamente (por ejemplo, con Hola, mundo.).
En el momento de escribir esto, la última versión de Prometheus era la 2.46. Los pasos aquí se llevaron a cabo utilizando Rancher Desktop 1.9.1, con el motor de contenedores establecido en dockerd (moby) y utilizando la CLI de docker proporcionada. La expectativa es que los pasos deberían funcionar tal cual en cualquier instalación actual de Docker, o una pila equivalente como containerd con la CLI nerdctl.
Por último, los comandos compartidos aquí son adecuados para entornos de desarrollo autónomos de corta duración; por supuesto, debes seguir tus mejores prácticas locales de red y seguridad cuando proceda.
Ejecutar un servidor Prometheus en Docker
Vamos a ejecutar el último contenedor Prometheus (prom/prometheus) con su configuración por defecto.
En docker run tiene muchas opciones, pero para este ejemplo sólo usaremos una -p / -publicar para exponer el puerto Prometheus (que por defecto es 9090) para que podamos acceder a él desde nuestro navegador local, y un -rm para asegurarse de que el contenedor se limpia al salir.
Por defecto, el contenedor en ejecución permanecerá "conectado", transmitiendo los registros a la salida estándar (en este caso, su terminal). Vamos a hacer eso para la primera ejecución para que podamos asegurarnos de que se inicia correctamente:
|
1 |
docker run --rm --publish 9090:9090 prom/prometheus |
A menos que vea algún error en la salida de la consola, ahora debería tener un servidor Prometheus ejecutándose en https://localhost:9090/. Ábrelo en una ventana del navegador y verás algo parecido a esto:
Ahora vuelve a tu ventana de terminal y pulsa Ctrl+C para matar el contenedor en ejecución, luego lo iniciaremos de nuevo, pero esta vez utilizando un -d / -detach para ponerlo en segundo plano y liberar nuestro terminal:
|
1 |
docker run --detach --rm --publish 9090:9090 prom/prometheus |
En caso de éxito, Docker imprimirá el ID del contenedor, y también se puede encontrar con docker ps. Como de todas formas lo necesitarás para algunos de los pasos posteriores, vamos a filtrar (con -f / -filtro) la salida de docker ps para mostrar sólo el ID de contenedor que queremos, basándonos en los puertos de red que estamos utilizando (en este caso estamos publicando el puerto 9090):
|
1 |
docker ps --filter publish=9090 |
Podemos añadir un -q / -silencio a sólo obtenga el ID del contenedor y utilice el resultado en otro comando. Por ejemplo, para ver los registros del contenedor Prometheus que acaba de iniciar:
|
1 |
docker logs $(docker ps --quiet --filter publish=9090) |
Ese comando mostrará algo similar a cuando arrancó el servidor Prometheus la primera vez, cuando el contenedor aún estaba conectado al terminal. Puede utilizar la misma técnica con (por ejemplo) docker exec (si desea iniciar un shell en un contenedor en ejecución), o bien docker kill (para enviar una señal al contenedor).
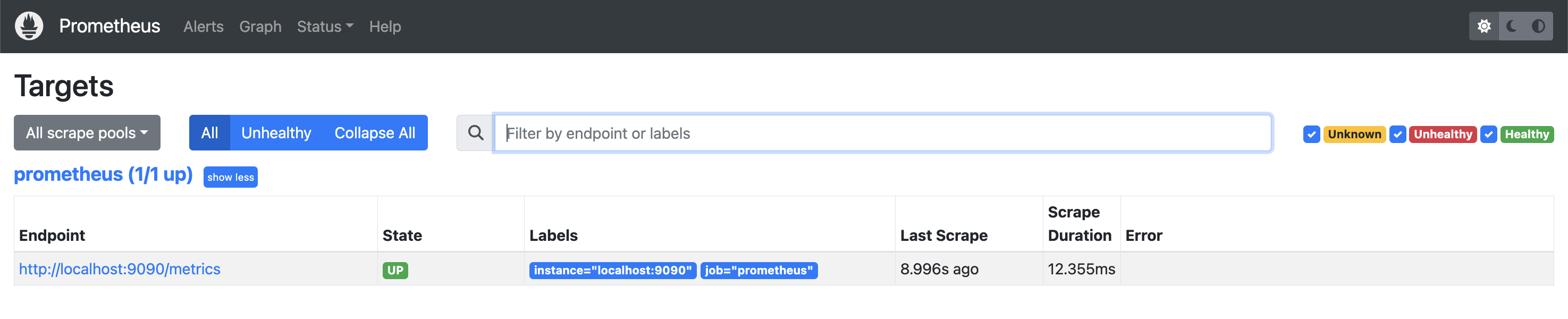
Echemos un vistazo más profundo al servidor Prometheus en el que se está ejecutando https://localhost:9090/. Si navega a Estado -> Objetivospuede ver que ya hay un trabajo en ejecución:
Este servidor Prometheus ha sido configurado para raspar sí mismo como objetivo, lo que puede confirmar viendo su configuración (Estado -> Configuración):
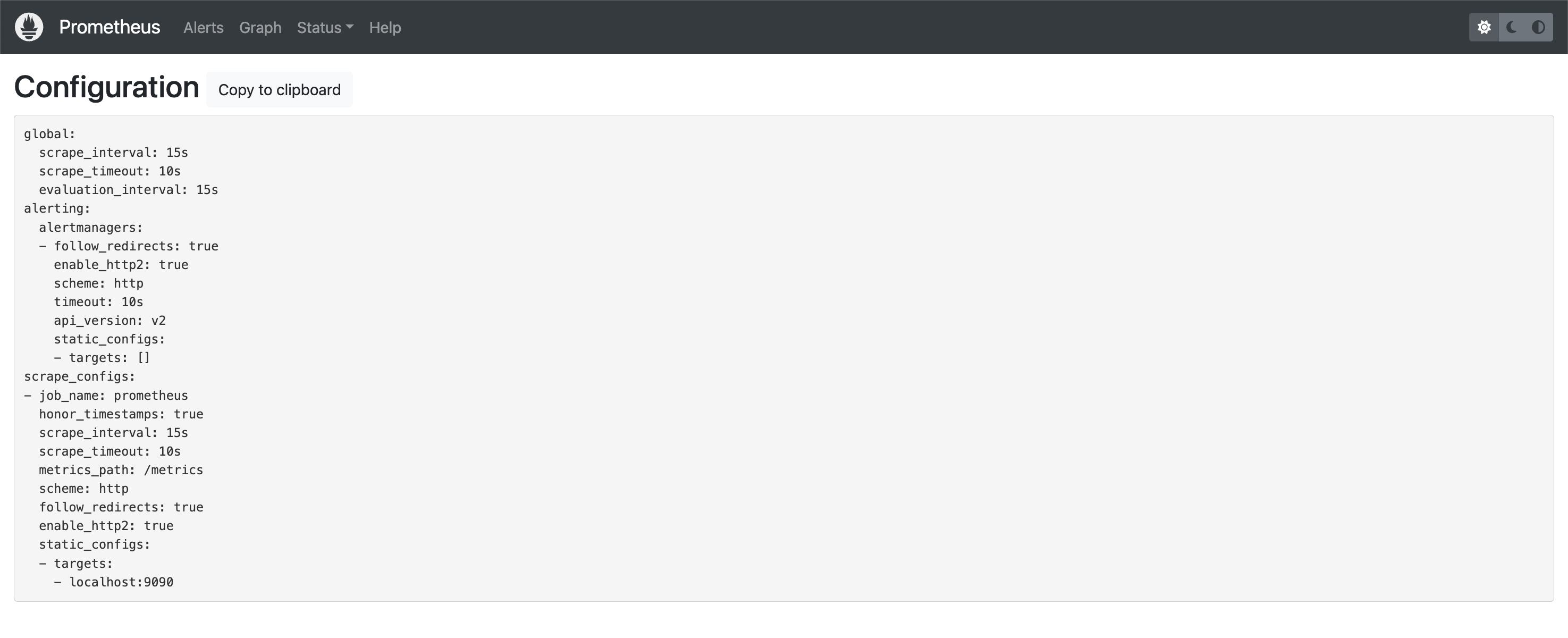
Puede ver en la imagen de arriba que hay un trabajo llamado prometheuscuyo objetivo es localhost:9090/métricas (targets + metrics_path). Véase Configurar Prometheus para que se supervise a sí mismo para ver un ejemplo de configuración.
Antes de volver a nuestro terminal, echemos un vistazo rápido a las métricas que se están raspando en el trabajo anterior. Si hace clic en Gráfico, encontrará el icono Navegador de expresionesque permite introducir expresiones PromQL (véase Consulta a Prometheus para obtener una visión general), y ver los resultados.
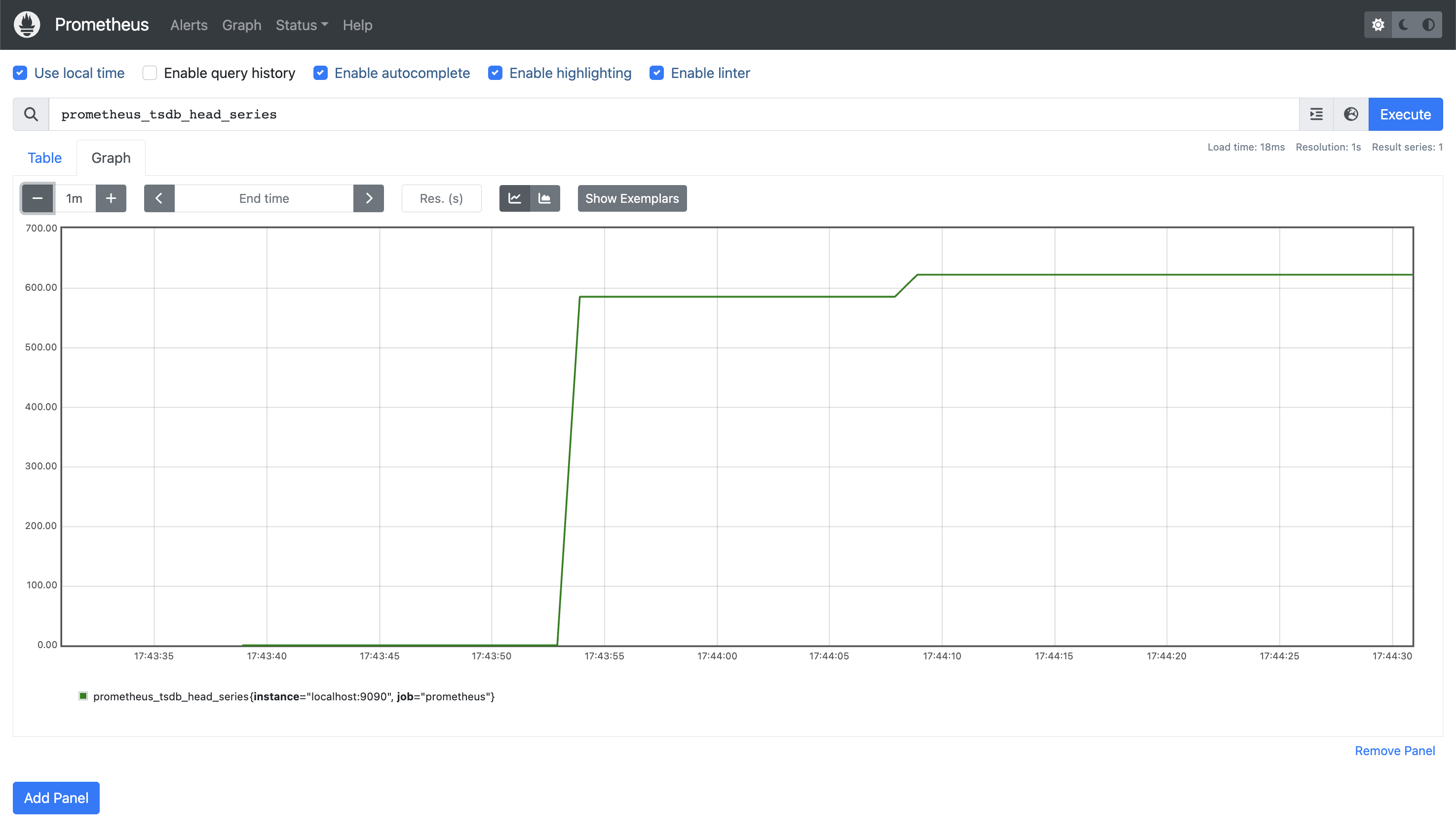
Tenga en cuenta la Navegador de expresiones es sólo para uso ad hoc - la recomendación es utilizar Grafana como una solución de gráficos completa, y lo veremos en un próximo post. Mientras tanto, como ejemplo rápido, este es el número de series temporales almacenadas actualmente en su propia base de datos (prometheus_tsdb_head_series):
Si queremos añadir nuestra base de datos Capella como un Scrape Job en nuestro servidor Prometheus, esto significa que tenemos que hacer cambios en la configuración que vimos anteriormente, pero la configuración se hornea en nuestra imagen de contenedor. Una vez que tengamos una configuración final podemos reconstruir la imagen, pero por ahora sería mucho más conveniente si pudiéramos aplicar nuevas opciones de configuración y probar sin tener que hacer tanto esfuerzo.
Hagamos uso de Docker's -v / -volumen que permite montar un archivo o directorio local en el contenedor. El archivo de configuración de Prometheus en el contenedor es /etc/prometheus/prometheus.yml - Si ese fuera el único archivo que necesitamos, podríamos montarlo directamente, pero necesitaremos algunos más, así que montaremos un directorio en su lugar.
En su directorio de trabajo, cree un subdirectorio que utilizaremos para guardar nuestra configuración (prometheus.yml) y otros archivos asociados.
|
1 |
mkdir prometheus |
Ahora necesitamos una copia del archivo de configuración con la que podamos trabajar. Como siempre, hay más de una manera de hacer esto, pero con mucho, la más sencilla es utilizar el comando docker cp para copiar /etc/prometheus/prometheus.yml de su contenedor en ejecución, a un archivo local:
|
1 |
docker cp $(docker ps --quiet --filter publish=9090):/etc/prometheus/prometheus.yml prometheus/ |
Ahora mata tu contenedor en ejecución:
|
1 |
docker kill $(docker ps --quiet --filter publish=9090) |
A continuación, inicie un nuevo contenedor, esta vez montando su local prometheus directorio como /etc/prometheus/ en el contenedor:
|
1 |
docker run --detach --rm --publish 9090:9090 --volume $(pwd)/prometheus/:/etc/prometheus/ prom/prometheus |
Si, como el autor, se pregunta cómo saber si el servidor Prometheus está utilizando realmente su copia de prometheus.yml o no, puede comprobar los montajes dentro del contenedor para asegurarse de que /etc/prometheus/ se monta específicamente con:
|
1 |
docker exec $(docker ps --quiet --filter publish=9090) mount | grep '/etc/prometheus' |
También puede hacer un pequeño cambio en la configuración (por ejemplo, el nombre del trabajo de raspado existente), y esto debería reflejarse en la consola (en https://localhost:9090/config).
Por último para esta sección, como vamos a hacer algunos cambios en nuestro archivo de configuración, sería bueno si no tuviéramos que volver a crear el contenedor para aplicar los cambios. Prometheus tiene un método integrado en la API para esto, discutido en Configuraciónpero el -web.enable-lifecycle no está activada por defecto en el contenedor oficial. Afortunadamente (al menos para los usuarios de MacOS y Linux), existe la opción de enviar un SIGHUP con docker kill (aparece el mensaje "Cargando archivo de configuración" en los registros):
|
1 |
docker kill --signal SIGHUP $(docker ps --quiet --filter publish=9090) |
En resumen, ahora tenemos un servidor Prometheus en funcionamiento, sabemos cómo comprobar sus registros, explorar las métricas que está explorando y cómo actualizar y recargar su configuración, lo que nos facilita la tarea de añadir nuestra base de datos Capella como objetivo de exploración.
Añadir una base de datos Capella a su servidor Prometheus
Ahora que tenemos un servidor Prometheus, vamos a echar un vistazo a la adición de una base de datos Couchbase Capella.
Requisitos previos
Para cada base de datos de la que quieras recoger métricas, vas a necesitar:
-
- El nombre de host de conexión
- Credenciales de usuario con el acceso adecuado a la base de datos
- Un certificado de seguridad
- Una o más direcciones IP permitidas
Conexión Nombre de host
Este es el nombre de host de su cadena de conexión. Vaya al campo Conectar en su base de datos en la interfaz de usuario de Capella y copie todo lo que hay después de la pestaña couchbases:// prefijo de esquema. El que utilizamos en nuestros ejemplos es: cb.plmvshfqolmyxvpt.cloud.couchbase.com.
Credenciales de usuario
Un conjunto de credenciales (nombre de usuario/contraseña) que tiene Leer Acceso a Todos los cubos y Todos los ámbitos en su base de datos (como nota, la lector_estadisticas_externo sólo se concede cuando un La credencial de la base de datos tiene acceso de lectura a todos Cubos en una base de datos). Si no tiene uno, puede crearlo desde Configuración -> Acceso a la base de datos -> Crear acceso a la base de datos (véase Configurar las credenciales de la base de datos). En nuestros ejemplos, utilizaremos metrics_user / metrics_Passw0rd.
Certificado de seguridad
El certificado de seguridad para su base de datos. Desde su base de datos, vaya a Configuración -> Certificado de seguridady haga clic en Descargar. Obtendrá un archivo de texto con formato PEM con el nombre de su clúster (en nuestro caso bravetimbernerslee-root-certificate.txt). En realidad, se utiliza el mismo certificado de firma para todas las bases de datos de Capella, por lo que sólo tendrá que descargarlo una vez y podrá utilizar el mismo certificado raíz para verificar todas sus bases de datos de Capella. Para ello, hemos cambiado el nombre de nuestro archivo de certificado local a couchbase-cloud-root-certificate.pem para mayor claridad, y copiado en nuestro prometheus (en un subdirectorio denominado certificados) para que Prometheus pueda acceder a él más tarde.
Direcciones IP permitidas
Antes de que cualquier cliente pueda conectarse a una base de datos Capella, la dirección IP del cliente debe añadirse a la base de datos. Lista de IP permitidas. Para seguir los pasos aquí descritos, lo más probable es que desee añadir su dirección IP actual, en cuyo caso puede utilizar la opción Añadir mi IP botón. Para un despliegue de producción necesitará la dirección IP pública de su(s) servidor(es) Prometheus.
Definición de una nueva Scrape Config
Empecemos por echar un vistazo al trabajo existente, que le dice a Prometheus que se raspe a sí mismo.
Si ignoramos los ajustes globales y por defecto, se convierte en lo siguiente:
|
1 2 3 4 5 |
scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] |
Si consulta la documentación de scrape_config puedes ver que esta es esencialmente la definición más pequeña posible de un trabajo. No hay TLS, no hay autenticación, sólo un nombre y un único objetivo (que con los valores por defecto añadidos se convierte en https://localhost:9090/metrics).
Por otra parte, si te interesa, puedes probarlo cargando esa URL en tu navegador o utilizando rizo en la CLI. La salida resultante está en Prometheus basado en texto Formato de la exposición.
Nuestro nuevo trabajo necesitará un nombre, que deberá ser único para todas las definiciones de raspado, lo que conviene tener en cuenta si se está planeando añadir varias bases de datos de Capella. Para nuestro ejemplo utilizaremos el componente único de nuestro nombre de host de conexión para diferenciar, dándonos:
|
1 |
- job_name: "capella-plmvshfqolmyxvpt" |
Sabemos que tendremos que autenticarnos para acceder al endpoint de métricas, utilizando las credenciales anteriores:
|
1 2 3 |
basic_auth: username: "metrics_user" password: "metrics_Passw0rd" |
Todas las comunicaciones de Capella están encriptadas con TLS, por lo que tendremos que añadir un icono tls_config utilizando el certificado que descargamos anteriormente:
|
1 2 |
tls_config: ca_file: "certs/couchbase-cloud-root-certificate.pem" |
Y en relación, esquema por defecto http...así que necesitaremos..:
|
1 |
scheme: https |
Lo último que tenemos que hacer es decirle a Prometheus el(los) nombre(s)/dirección(es) de host que debe utilizar para conectarse a su Base de Datos, también conocido como objetivos.
En el prometheus anterior, se proporciona un único nombre de host utilizando el campo configuración_estática parámetro. Como su nombre indica, se trata de una forma de definir estáticamente uno o varios objetivosy no se actualizarán a menos que se reinicie el servidor Prometheus o se recargue su archivo de configuración.
Esto está bien en este caso, ya que el nombre de host (localhost) nunca va a cambiar. También podría ser manejable si tiene nombres de host que cambian ocasionalmente, y sólo se actualizan bajo circunstancias controladas (por ejemplo, un período de mantenimiento programado en el que puede actualizar su configuración de Prometheus al mismo tiempo).
Pero, ¿y si sus nombres de host cambian con frecuencia y el momento de esos cambios está fuera de su control? Si la aplicación que estás monitorizando está alojada en cualquier tipo de entorno en la nube, donde hay escalado bajo demanda, sustitución de servidores en caso de fallo, actualizaciones automatizadas, entonces necesitarás un método mucho más flexible para especificar tus nombres de host. objetivos.
Aquí es donde entra en juego el descubrimiento de servicios.
Descubrimiento de servicios
Prometheus Service Discovery (SD) es un mecanismo que permite a su servidor Prometheus descubrir dinámicamente (y actualizar) la lista de objetivos a monitorizar para una aplicación o servicio en particular. En el momento de redactar este documento existen 28 mecanismos diferentes, entre los que se incluyen opciones genéricas como Archivo- y Basado en HTTP Service Discovery, así como implementaciones específicas para un gran número de plataformas y aplicaciones en la nube (véase el sitio web de Prometheus documentación de configuración para consultar la lista completa).
Veamos esas dos opciones genéricas en relación con su base de datos Couchbase Capella.
Descubrimiento de servicios basado en archivos (archivo_sd_configs) es donde uno o más nombres de archivo se proporcionan a Prometheus, cada archivo contiene cero o más configuración_estática entradas. Prometheus aplicará cualquier formato objetivos que encuentre en esos archivos, y cargará automáticamente cualquier cambio cuando se actualicen los archivos.
Este mecanismo es útil en el sentido de que puedes usarlo para conectarte a cualquier sistema arbitrario, siempre y cuando puedas obtener los detalles del host en un archivo con el formato correcto (ya sea manualmente o mediante cualquier automatización apropiada). Sin embargo, es necesario asegurarse de que la automatización para actualizar el archivo(s) es fiable.
Descubrimiento de servicios basado en HTTP (http_sd_configs) es similar a File-based, en el sentido de que proporciona una interfaz genérica, con una carga útil que contiene cero o más ficheros configuración_estática pero utiliza una conexión HTTP para obtener la carga útil en lugar de leer un archivo local. Esto elimina la dependencia de cualquier automatización o intervención humana y, siempre que la aplicación de destino proporcione la API pertinente, sería preferible a la opción basada en archivos.
En el momento de escribir estas líneas, estamos actualizando el estado de Capella de Couchbase Server 7.1 a 7.2 (véase Actualizar una base de datos para más detalles). Server 7.1 sólo proporciona una API básica de descubrimiento de servicios basada en archivos, pero en Server 7.2 hemos añadido SD basada en HTTP, así como SD mejorada basada en archivos.
Veremos primero el método de Descubrimiento de Servicios basado en Archivos en Server 7.1. No dude en saltarse una sección si ya está ejecutando Server 7.2.
Descubrimiento de servicios basado en archivos en Couchbase Server 7.1
El punto final es prometheus_sd_config.yamltendrá que autenticarse con las mismas credenciales que antes y proporcionar el certificado raíz de Capella que descargamos anteriormente.
En primer lugar, utilizaremos rizo y transmitir el resultado a nuestro terminal:
|
1 |
curl --cacert /path/to/couchbase-cloud-root-certificate.pem -u 'metrics_user:metrics_password' https://cb.plmvshfqolmyxvpt.cloud.couchbase.com:18091/prometheus_sd_config.yaml |
Para nuestro cluster esto da:
|
1 2 3 4 5 6 |
- targets: - 'svc-d-node-001.plmvshfqolmyxvpt.cloud.couchbase.com:8091' - 'svc-d-node-002.plmvshfqolmyxvpt.cloud.couchbase.com:8091' - 'svc-d-node-003.plmvshfqolmyxvpt.cloud.couchbase.com:8091' - 'svc-qi-node-004.plmvshfqolmyxvpt.cloud.couchbase.com:8091' - 'svc-qi-node-005.plmvshfqolmyxvpt.cloud.couchbase.com:8091' |
Aquí podemos ver la limitación de la actual API de Service Discovery - siempre devolverá el puerto inseguro (8091), que no nos sirve en Capella ya que toda la comunicación se realiza a través del puerto seguro (18091). Este problema se solucionará con las mejoras del Servidor 7.2, pero hasta que estén disponibles tendremos que añadir un paso extra para actualizar esos números de puerto.
Por el bien de esta demostración sólo vamos a canalizar a través de sedpero puede hacer lo que sea más apropiado para su entorno:
|
1 |
curl --cacert /path/to/couchbase-cloud-root-certificate.pem -u 'metrics_user:metrics_password' https://cb.plmvshfqolmyxvpt.cloud.couchbase.com:18091/prometheus_sd_config.yaml | sed 's/:8091/:18091/' |
Para nuestro cluster esto da ahora:
|
1 2 3 4 5 6 |
- targets: - 'svc-d-node-001.plmvshfqolmyxvpt.cloud.couchbase.com:18091' - 'svc-d-node-002.plmvshfqolmyxvpt.cloud.couchbase.com:18091' - 'svc-d-node-003.plmvshfqolmyxvpt.cloud.couchbase.com:18091' - 'svc-qi-node-004.plmvshfqolmyxvpt.cloud.couchbase.com:18091' - 'svc-qi-node-005.plmvshfqolmyxvpt.cloud.couchbase.com:18091' |
Ahora que tenemos la salida correcta, podemos redirigirla a un archivo para utilizarla más tarde en la definición de nuestro trabajo.
En nuestro directorio de trabajo, utilizaremos un subdirectorio para mantener nuestros objetivos juntos, nombrando los archivos después del nombre del trabajo (en nuestro caso capella-plmvshfqolmyxvpt):
|
1 |
curl --cacert /path/to/couchbase-cloud-root-certificate.pem -u 'metrics_user:metrics_password' https://cb.plmvshfqolmyxvpt.cloud.couchbase.com:18091/prometheus_sd_config.yaml | sed 's/:8091/:18091/' > $(pwd)/prometheus/targets/capella-plmvshfqolmyxvpt.yml |
Esto está bien para nuestra demostración, pero obviamente querrás asegurarte de que es robusto y adecuado para tu propio entorno, añadiendo gestión de errores según corresponda. Y, lo que es más importante, tendrás que programarlo para que se ejecute con regularidad para asegurarte de que la lista de objetivos se actualiza con cualquier cambio de topología que se produzca (se ejecuta una vez por minuto a través de cron por ejemplo, sería suficiente).
Ahora podemos tomar todo lo que tenemos arriba, añadir en nuestro archivo_sd_configsy nuestro nuevo trabajo se parece a esto:
|
1 2 3 4 5 6 7 8 9 10 |
- job_name: "capella-plmvshfqolmyxvpt" basic_auth: username: "metrics_user" password: "metrics_Passw0rd" tls_config: ca_file: "certs/couchbase-cloud-root-certificate.pem" scheme: https file_sd_configs: - files: - "targets/capella-plmvshfqolmyxvpt.yml" |
Descubrimiento de servicios basado en HTTP en Couchbase Server 7.2
En Server 7.2 hemos añadido un nuevo punto final (prometheus_sd_config) y, al igual que en el caso anterior, tendrá que autenticarse con las credenciales que creó y proporcionar el certificado raíz de Capella que descargó anteriormente.
En primer lugar, utilizaremos rizo y enviamos el resultado a nuestro terminal. En la nueva API la salida por defecto es JSON, por lo que estamos canalizando a jq para mayor claridad:
|
1 |
curl --cacert /path/to/couchbase-cloud-root-certificate.pem -u 'metrics_user:metrics_password' https://cb.plmvshfqolmyxvpt.cloud.couchbase.com:18091/prometheus_sd_config | jq |
Para nuestro clúster actualizado (donde los nombres de host han cambiado durante el proceso de actualización), esto da:
|
1 2 3 4 5 6 7 8 9 10 11 |
[ { "targets": [ "svc-d-node-006.plmvshfqolmyxvpt.cloud.couchbase.com:18091", "svc-d-node-007.plmvshfqolmyxvpt.cloud.couchbase.com:18091", "svc-d-node-008.plmvshfqolmyxvpt.cloud.couchbase.com:18091", "svc-qi-node-009.plmvshfqolmyxvpt.cloud.couchbase.com:18091", "svc-qi-node-010.plmvshfqolmyxvpt.cloud.couchbase.com:18091" ] } ] |
Esta salida es exactamente lo que espera Prometheus, así que podemos tomar los argumentos que utilizamos en el comando rizo y utilizarlos en un http_sd_configs en nuestro nuevo trabajo Prometheus:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
- job_name: "capella-plmvshfqolmyxvpt" basic_auth: username: "metrics_user" password: "metrics_Passw0rd" tls_config: ca_file: "certs/couchbase-cloud-root-certificate.pem" scheme: https http_sd_configs: - url: https://cb.plmvshfqolmyxvpt.cloud.couchbase.com:18091/prometheus_sd_config basic_auth: username: "metrics_user" password: "metrics_Passw0rd" tls_config: ca_file: "certs/couchbase-cloud-root-certificate.pem" |
Dirigir su nuevo puesto de trabajo
En este punto deberías tener todo lo que necesitas para añadir el nuevo trabajo de scrape a tu servidor Prometheus. Si todavía está utilizando Couchbase Server 7.1 entonces será el archivo_sd_configs (con los pasos necesarios para crear el objetivos ), y si está ejecutando Server 7.2, el archivo http_sd_configs basada en la versión.
Añade el nuevo trabajo a tu prometheus.ymly, a continuación, vuelva a cargar la configuración con matar que hemos utilizado antes:
|
1 |
docker kill --signal SIGHUP $(docker ps --quiet --filter publish=9090) |
A continuación, puede comprobar los registros para asegurarse de que la configuración se ha cargado correctamente:
|
1 |
docker logs $(docker ps --quiet --filter publish=9090) |
Recuerde que está buscando un Carga del archivo de configuración y, si la configuración es válida, debería aparecer un mensaje de registro Finalizada la carga del archivo de configuración inmediatamente después. Si no se recarga correctamente, hay que solucionar los problemas e intentarlo de nuevo. Una vez que lo haga, vamos a volver a ver la consola de Prometheus en https://localhost:9090/.
Veamos primero nuestra nueva configuración (Estado -> Configuración), que debería mostrar el trabajo extra que acabamos de añadir.
Esta es la configuración completa utilizando File-based Service Discovery:
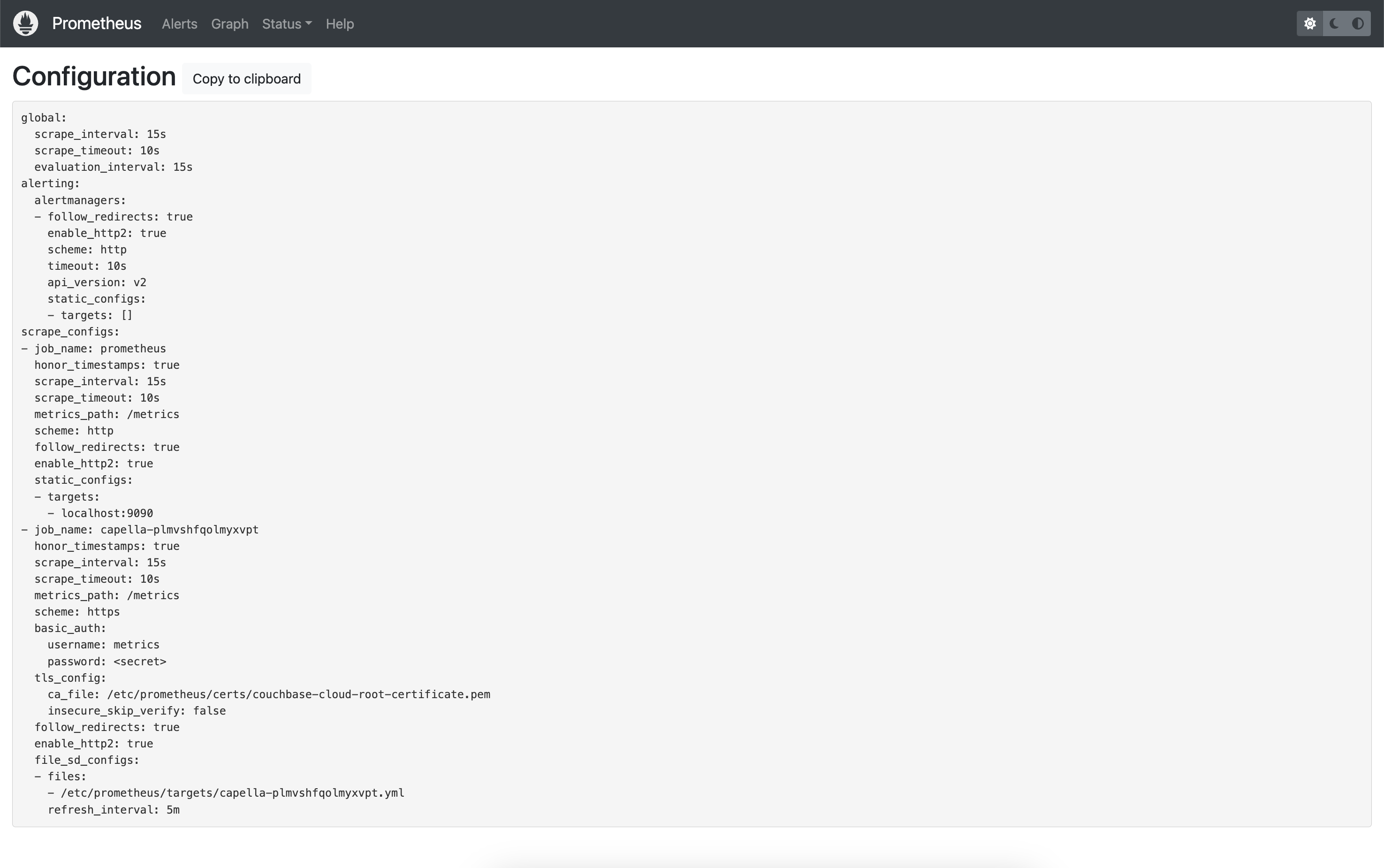
Y aquí hay un fragmento que muestra el scrape basado en HTTP en su lugar:

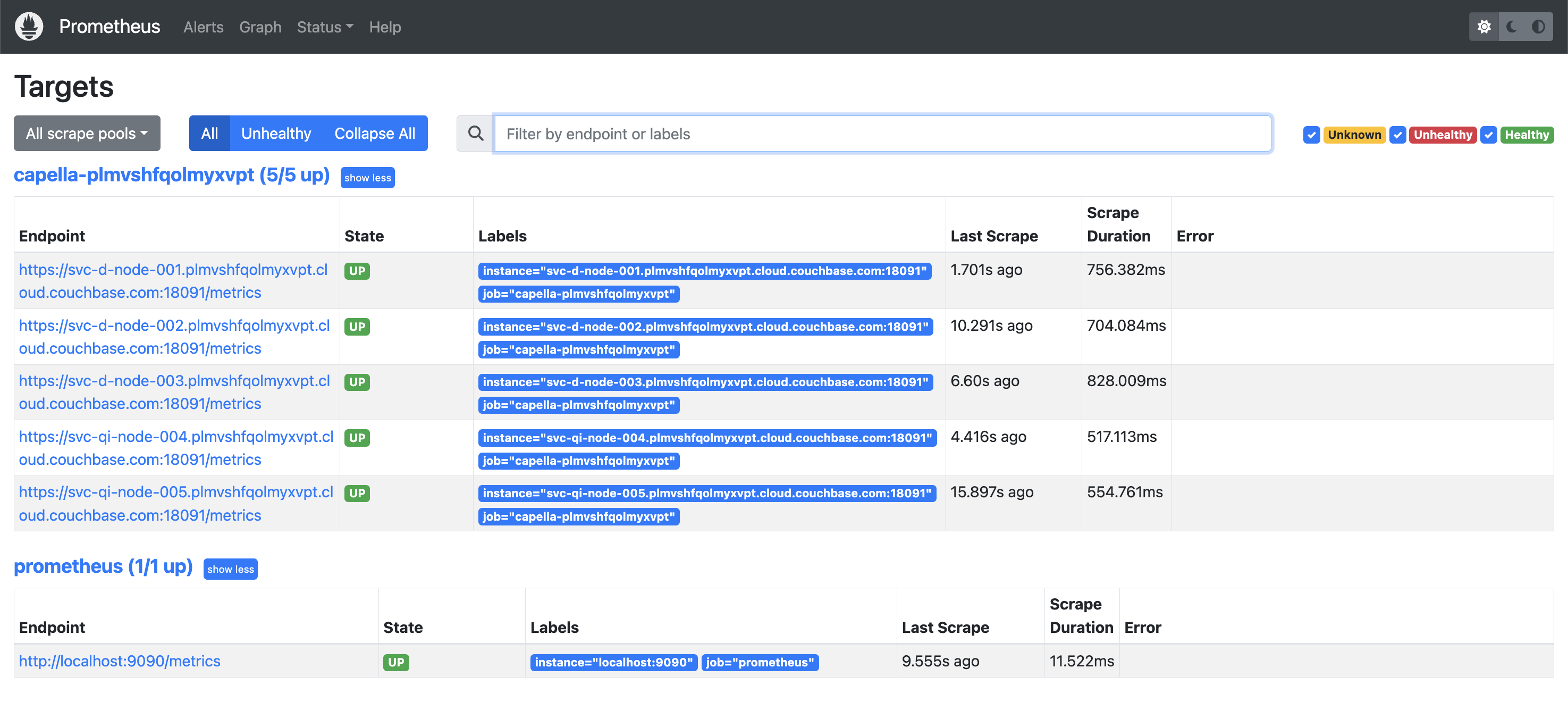
Ahora, si nos fijamos en Estado -> Objetivosdebería mostrar todos los nodos de su base de datos Capella. Por ejemplo, este es nuestro cluster antes de la actualización a Server 7.2:
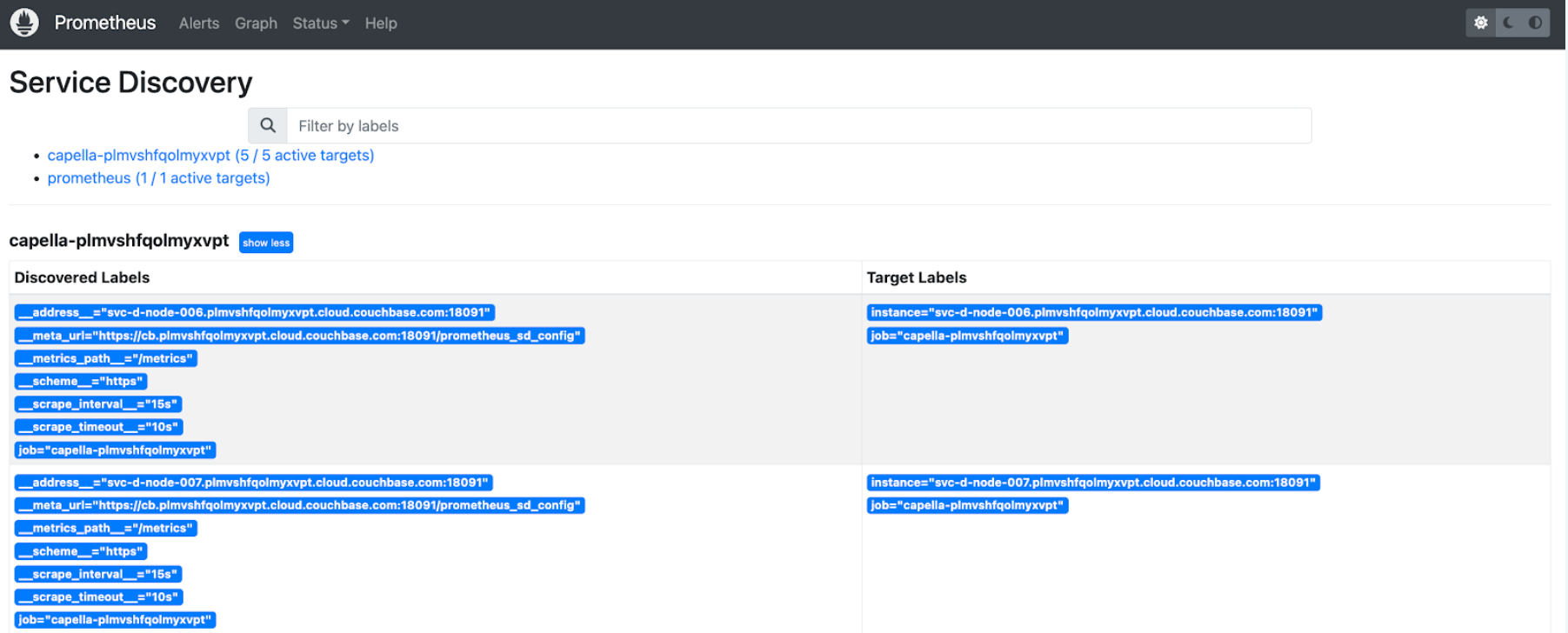
En relación con esto, si los Objetivos no son lo que usted esperaba, Estado -> Descubrimiento de servicios le mostrará de dónde viene cada endpoint. Aquí está el estado de Service Discovery para nuestro clúster actualizado, donde estamos usando HTTP SD (recortado para mostrar sólo los primeros nodos):
Ahora que hemos añadido nuestra base de datos Capella, ¿cómo comprobamos que realmente estamos obteniendo algo útil?
En primer lugar, si volvemos al gráfico anterior, veremos que el número de series temporales almacenadas (prometheus_tsdb_head_series) ha crecido considerablemente:
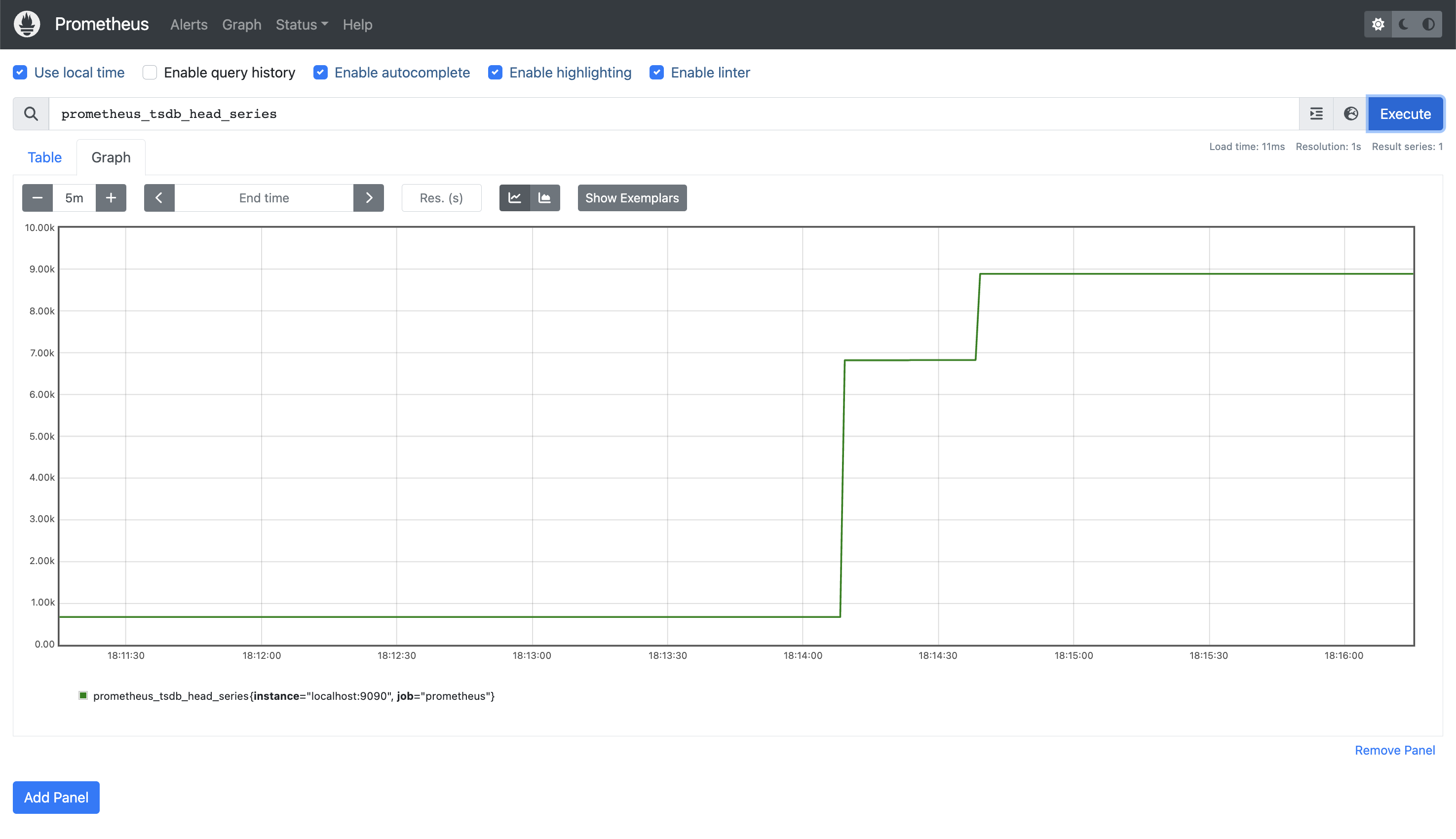
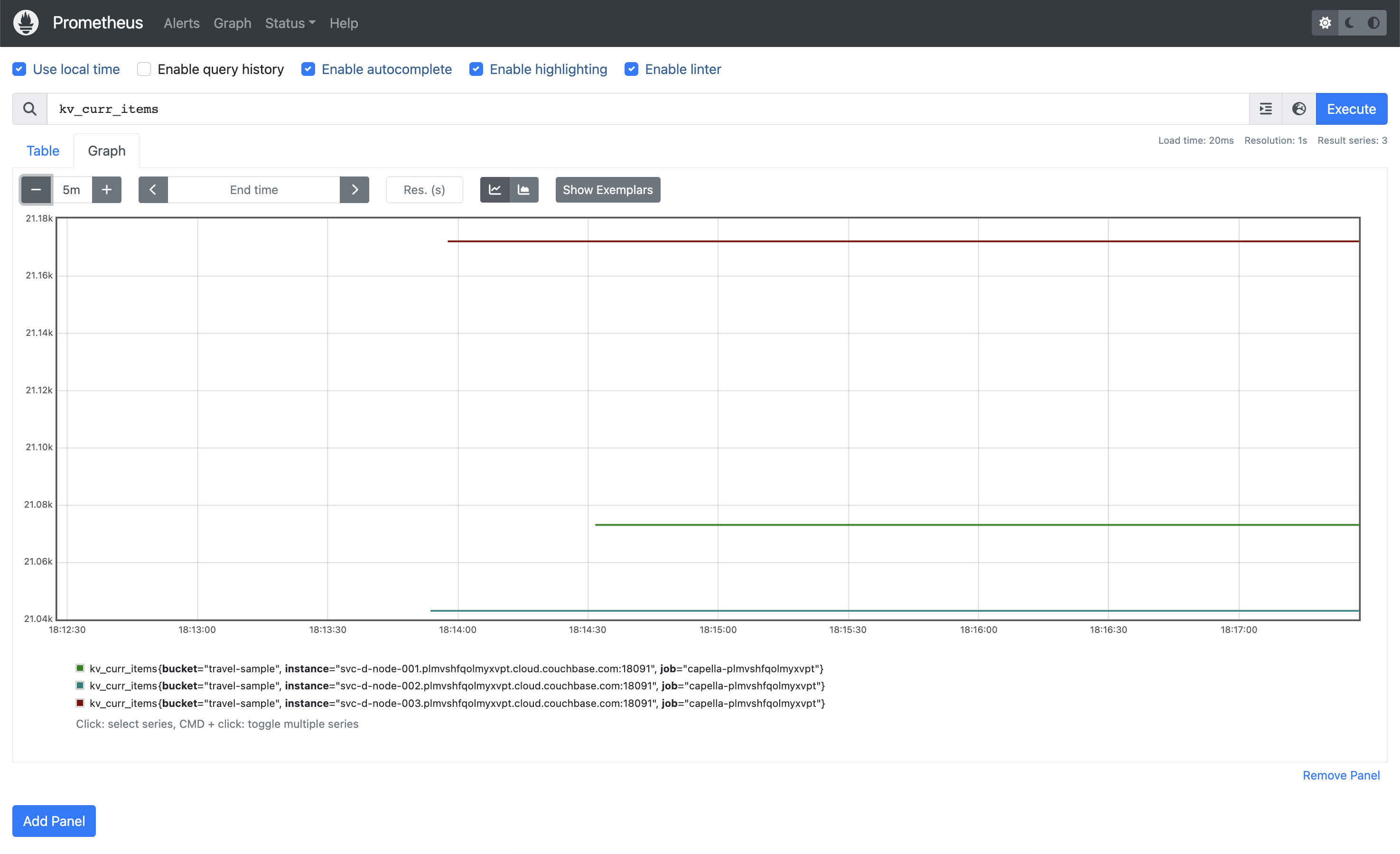
Entonces podemos confirmar que efectivamente tenemos algunas métricas de Couchbase Server capturadas. Tenemos las métricas viaje-muestra cargado en nuestra base de datos, que contiene algo más de 63.000 elementos. Si consultamos kv_curr_items podemos ver que cada uno de nuestros tres nodos de Servicio de Datos tiene ~21.000 elementos cada uno:
Conclusión
En este artículo te hemos mostrado cómo ejecutar un servidor Prometheus sencillo en tu entorno de desarrollo local, y cómo puedes añadir tu base de datos Couchbase Capella Database para que puedas empezar a monitorizarla. En los siguientes posts de esta serie, te mostraremos qué puedes hacer con esas métricas ahora que las tienes.
Como siempre, agradecemos todos y cada uno de los comentarios, por favor, no dude en ponerse en contacto con nosotros dejando un comentario aquí, o puede encontrarnos en nuestro Foroso nuestro Discordia.
cb.plmvshfqolmyxvpt.cloud.couchbase.com no es accesible cuando utilizamos VPC peering con Capella.
¿Cómo descubrir servicios en la VPC?
El host mencionado en la página de conexión no es accesible cuando utilizamos Capella con VPC peering.
¿De qué manera se puede realizar el descubrimiento de servicios con capella en VPC?