La realidad es que las bases de datos están convergiendo y, en los últimos años, se está haciendo aún más difícil señalar cuáles son los mejores escenarios para cada almacén de datos sin un conocimiento profundo de cómo funcionan las cosas bajo el capó.
Postgres ha sido mi RDBMS favorito durante años, y estoy encantado con la creciente popularidad de su soporte JSONB. En mi opinión personal, ayudará a que los desarrolladores estén más familiarizados con todas las ventajas de almacenar datos como JSON en lugar de como simples tablas.
Sin embargo, he visto a mucha gente presentando inadvertidamente Postgres 11 como "El Nuevo NoSQL" o que no necesitan ningún Base de datos NoSQL puesto que ya utilizan Postgres. En este artículo, me gustaría abordar las principales diferencias y casos de uso.
Si no tiene tiempo de leer todo el artículo, resumiré los resultados más importantes en la conclusión.
Modelización de datos: RDBMS y bases de datos de documentos
Todos estamos familiarizados con el coste de una operación JOIN en un RDBMS a escala: Si tienes 1 Millón de usuarios con 10 preferencias cada uno, entonces para traer a este usuario a la memoria, suponiendo que estás usando un framework ORM (Mapeo Objeto-Relacional) tendrá que hacer un join con una tabla de USER_PREFERENCES con 10 millones de filas.
En el mundo real, los usuarios también suelen estar asociados a muchas otras entidades, lo que empeorará aún más la situación y obligará a los desarrolladores a decidir qué relaciones deben ser perezosas o ansiosas. Hoy en día, todos los RDBMS disponen de muchas optimizaciones para el escenario anterior, pero modelar los datos de la forma en que lo hemos venido haciendo durante los últimos 30 años es definitivamente subóptima.
Una de las razones por las que RDBMS se hizo tan bueno en el manejo de transacciones es exactamente por la limitación de su modelo de datos: ¿Tiene sentido almacenar un pedido si no hay artículos en él? Aún así, me veo obligado a crear una transacción para guardar esta "unidad única" repartida entre al menos dos tablas: PEDIR y ÍTEM_ORDEN.
Veamos un escenario aún más común: cómo se puede almacenar un usuario en una base de datos de documentos frente a un RDBMS:
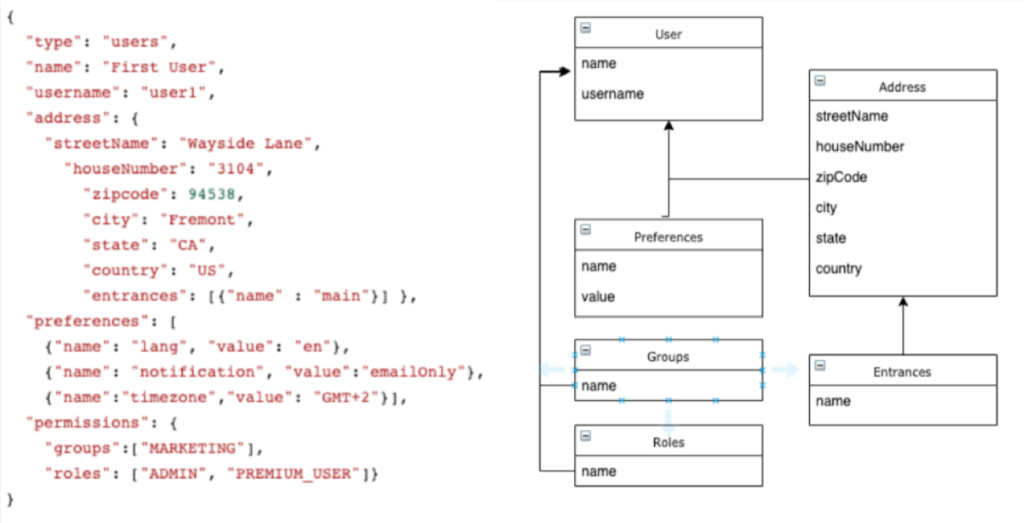
En una base de datos de documentos, las entidades con fuertes relaciones suelen almacenarse en una única estructura. En este enfoque, casi no hay coste adicional para cargar cosas como preferencias y permisos, mientras que en un modelo relacional requeriría al menos 2 uniones.
Ahora, ampliemos este ejemplo a un caso sencillo de comercio electrónico:

En el ejemplo anterior, una base de datos de documentos no necesitaría ningún JOIN para listar usuarios y productos. Para los pedidos, sin embargo, podría necesitar una o dos, lo que es totalmente aceptable. El mismo modelo en un RDBMS requeriría al menos ~12 tablas:
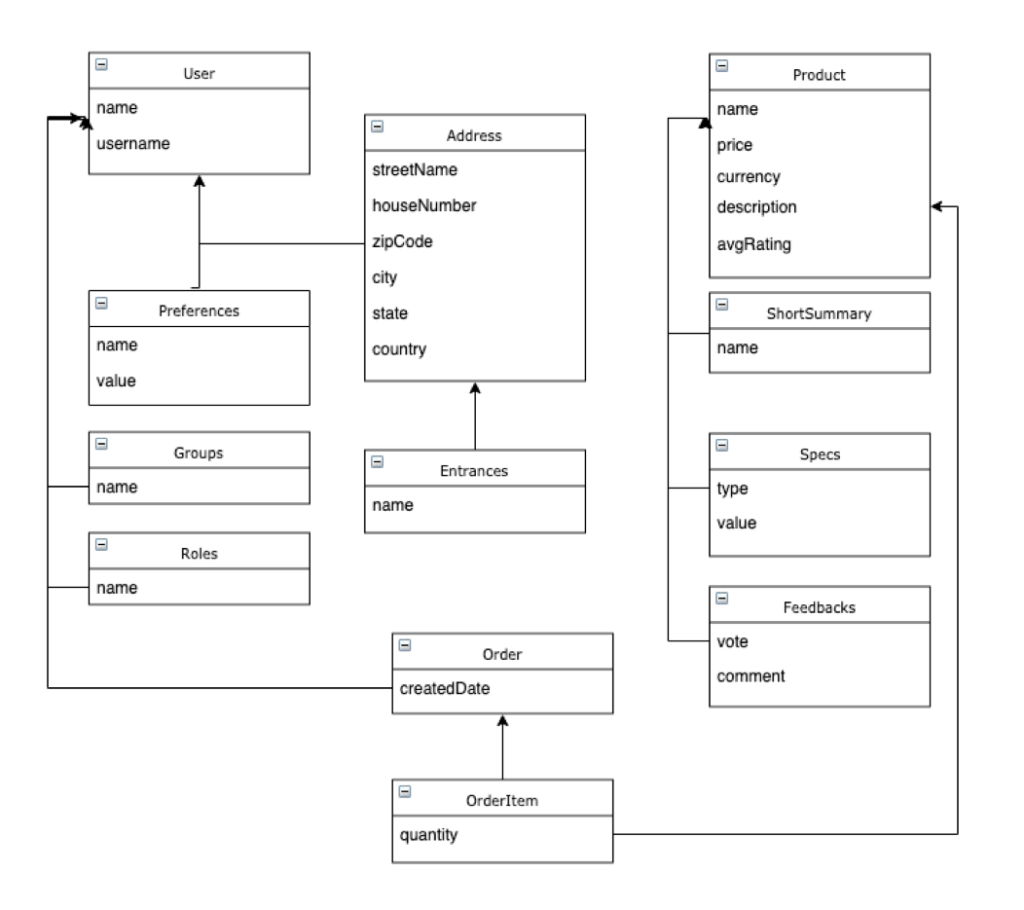
Utilizando nuestro ejemplo anterior, puede observar que los JOIN son esenciales para un RDBMS, mientras que en una base de datos de documentos se utilizan con menos frecuencia. Lo mismo ocurre con las transacciones o las operaciones en cascada, ya que la mayoría de las entidades relacionadas se almacenan en un único documento.
Algunas de las bases de datos NoSQL más famosas todavía no soportan JOINs correctamente. Afortunadamente, este no es el caso aquí. Couchbase incluso soporta UNIONES ANSI:
|
1 2 3 4 5 6 |
SELECT DISTINCT route.destinationairportFROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
Sé que es posible que haya visto esta explicación sobre el modelado de datos para RDBMS vs modelado de datos para NoSQL antes, pero tengo que hacer hincapié en que a medida que cada base de datos está optimizado para un modelo de datos específico, y que jugará un papel importante durante las pruebas de rendimiento.
El mito del silo
Como el usuario y el nombre del producto raramente cambiarán, podría simplemente almacenarlos ambos en la entidad Pedidos para evitar unos cuantos JOINS, esta es una estrategia común en Bases de datos NoSQLpero no se aplica estrictamente:

El almacenamiento en caché de datos en otras entidades puede mejorar significativamente el rendimiento de tus consultas a escala, pero hay algunas contrapartidas: Si tienes que almacenar en caché estos datos en múltiples partes de tu sistema, cada vez que estos datos cambien tendrás que ejecutar unas cuantas actualizaciones para "mantener los datos sincronizados".
He visto a muchos desarrolladores experimentados utilizar esto como un inconveniente de las bases de datos de documentos, y siempre tengo que recordarles que se podría tener exactamente el mismo problema en un RDBMS.
Postgres JSONB Tipo de columna
En Postgres, JSONB es un tipo especial de columna que puede almacenar JSON en un formato optimizado para lecturas:
|
1 |
CREATE TABLE my_table ( id integer NOT NULL, data jsonb); |
Como se indica en este vídeoSi bien es cierto que el almacenamiento de datos en una columna JSONB tiene algunas penalizaciones de rendimiento, la base de datos tiene que analizar el JSON para almacenarlo en un formato optimizado para la lectura, lo que parece una compensación justa.
NOTA: Ignoremos la columna JSON de Postgres por ahora, ya que incluso la documentación de Postgres indica que, en general, deberías elegir JSONB en lugar del tipo de columna JSON.
En teoría, incluso se puede emular una base de datos de documentos en Postgres utilizando una columna JSONB para todas las entidades anidadas:
|
1 2 3 4 5 6 7 |
CREATE TABLE users ( id integer NOT NULL, name varchar, username varchar, address jsonb, preferences jsonb, permissions jsonb ); |
Manipulación de datos
Aquí es donde las cosas empiezan a ponerse realmente interesantes: En primer lugar, Postgres no sigue exactamente la Normas SQL:2016 (ISO/IEC 9075:2016). Esto no es necesariamente algo malo, ya que las consultas en esta especificación pueden ser fácilmente bastante grandes, pero sigue siendo algo a tener en cuenta.
Siempre me gusta destacar los estándares porque las bases de datos NoSQL ya han recorrido este camino antes, y hoy en día tenemos docenas de lenguajes diferentes y una importante inversión en refactorización si quieres migrar de una NoSQL a otra.
Ojalá, SQL vino al rescate, el padre del propio SQL, Don Chamberlin, escribió un libro sobre ello el año pasado. En esta sesión, compararé las funciones y operadores JSON de Postgress con una implementación de SQL++ llamada N1QL, que es el lenguaje de consulta que utilizamos en Couchbase.
Insertos
Las inserciones son lo que cabría esperar, la principal diferencia entre la sintaxis de Postgres y N1QL es que en la primera, sólo unas pocas columnas de una fila contendrán una cadena codificada en JSON, mientras que en la segunda, todo el documento es un JSON:
Postgres:
|
1 2 3 4 |
INSERT INTO users VALUES (1, 'First User', 'user1', '{"streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": "94538", "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }', '[{"name": "lang", "value": "en"},{"name": "notification", "value":"emailOnly"}, {{"name":"timezone","value": "GMT+2"}]', '{"groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]}'); |
Couchbase:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
INSERT INTO `test` ( KEY, VALUE ) VALUES ( "1", { "type": "users", "name": "First User", "username": "user1", "address": { "streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": 94538, "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }, "preferences": [ {"name": "lang", "value": "en"}, {"name": "notification", "value":"emailOnly"}, {"name":"timezone","value": "GMT+2"}], "permissions": { "groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]} }); |
Actualizaciones
Empecemos con una actualización muy sencilla
Postgres:
|
1 |
update users set address = jsonb_set(address, '{state}', '"California"') WHERE address->'state' = '"CA"'; |
En la sintaxis de Postgres, las cadenas deben especificarse entre comillas dobles y simples ('"CA"'), mientras que los literales deben ir entre comillas simples ('false' o '123').
Couchbase:
|
1 |
update `test` set address.state = 'California' where address.state = 'CA' and type = 'users' |
En Couchbase no existe un concepto similar al de tabla, por lo que diferenciamos los documentos según un "tipo", que en este caso debe ser igual a "usuarios". El resto de la consulta es similar al SQL estándar, o si vienes del mundo Java, es casi la misma sintaxis que JPA JPQL.
Intentemos un ejemplo más complejo en el que añadimos una nueva entrada a la casa, actualizamos el código postal y eliminamos el rol ADMIN del usuario de destino:
Postgres:
|
1 2 3 4 5 6 7 |
UPDATE users SET address = jsonb_set( jsonb_set( address::jsonb, array['entrances'], (address->'entrances')::jsonb || '{"name": "backyard"}'::jsonb), '{zipcode}', '94537'), permissions = jsonb_set(permissions, '{roles}', (permissions->'roles') - 'ADMIN') |
Las consultas Postgres pueden volverse fácilmente demasiado complejas si necesitas manipular el JSON. En algunos casos, incluso tienen que crear funciones sólo para ejecutar algunas actualizaciones básicas. Para mí, esto es señal de que aún necesitamos algunas mejoras en el lenguaje de consulta.
Couchbase:
|
1 2 3 |
update `test` set address.zipcode = 94537, address.entrances = ARRAY_APPEND(address.entrances, {"name": "backyard"}), permissions.roles = ARRAY_REMOVE(permissions.roles, "ADMIN") |
Incluso si usted no está familiarizado con N1QL puede entender claramente lo que está pasando en la consulta anterior, N1QL tiene docenas de funciones sólo para tratar matrices.
SELECCIONE
Como la selección de datos es un tema extenso, vamos a dividirlo en sesiones más pequeñas:
Consulta de datos sencillos
Postgres:
|
1 2 |
select address->'city' from users where address @> '{"zipcode": "94537"}' select * from users where address @> '{"entrances":[{"name": "backyard"}]}' |
La magia @> te permite emparejar fácilmente un par clave-valor o un objeto dentro de tu JSON. De hecho, hace que sea más fácil hacer coincidir cosas en JSON, aunque hay algunas cosas que debes tener en cuenta:
- El operador @> sólo admite comparaciones de igualdad
- En la segunda consulta, hacemos coincidir patio trasero en la matriz de entradas, pero la matriz real es en realidad la siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ ... "entrances": [ { "name": "main" }, { "name": "backyard" } ], ... } |
Así, cuando buscamos un atributo ("código postal", en este primer caso), el atributo @> se comportó como es igual apero si utilizamos el mismo operador para buscar en un array, se comporta como "contiene".
Couchbase:
|
1 2 3 |
Select address.city from `test` where address.zipcode = ‘94537’; select * from `test` where ANY entrance IN address.entrances SATISFIES entrance.name = "main" END; select * from `test` as t where "main" within t; //search for the occurence of “main” inside the JSON |
No existe una correlación directa entre los valores de @> y una palabra clave en N1QL. En las consultas anteriores utilizamos diferentes estrategias para lograr las mismas cosas. La sintaxis de Postgres es más corta para consultas muy simples, pero si filtramos por dos o tres atributos las consultas en N1QL tendrán aproximadamente el mismo tamaño. En este caso también se puede utilizar cualquier tipo de operadores de comparación.
Una cosa que me parece un plus es que las consultas que utilizan la sintaxis SQL++ "parecerse más a SQL". que el SQL del propio Postgres.
Navegar por los objetos
Postgres:
|
1 |
select * from users where (address->>'houseNumber')::int > 5 |
Postgres utiliza la función ->> para navegar por las entidades y el operador -> para convertir un atributo en texto. Pero si tu atributo es un entero tienes que convertir id de nuevo a int.
Couchbase:
|
1 |
Select * from `test` where address.houseNumber > 5 |
En el caso anterior puede simplemente navegar a través de las entidades utilizando el botón "." y se deduce automáticamente el tipo adecuado.
Tratamiento de atributos ausentes/existentes
Postgres:
|
1 |
select * from users where (preferences->'randomAttributeName’') is null |
Postgres considera los valores perdidos como NULL, lo que es semánticamente incorrecto:
- JSON con null "randomAttributeName'' :
|
1 2 3 4 5 6 7 8 9 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly", “randomAttributeName’': null } ] |
- JSON al que le falta "randomAttributeName'' :
|
1 2 3 4 5 6 7 8 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly" } ] |
Puede que no sea un gran problema para ti ahora mismo, pero esta diferenciación ayuda a solucionar posibles problemas en tu esquema o cuando necesitas actualizar las estructuras del propio JSON.
En ? puede comprobar si un atributo existe, pero sólo puede utilizarse con claves de nivel superior según la directiva docs.
Couchbase:
En N1QL ya existe una sintaxis adecuada para este escenario:
|
1 |
Select * from `test` where randomAttributeName is missing |
Además, también hay una sintaxis-azúcar para comprobar si el atributo existe (igual que "is not missing"):
|
1 |
Select * from `test` where randomAttributeName exists |
Índices
Las bases de datos que permiten almacenar datos como JSON no suelen imponer ningún tipo de esquema, pero existe un problema inherente cuando se añade soporte flexible de esquemas: Por defecto, no sabes de antemano qué documentos tienen los atributos que estás consultando.
Este problema se puede solucionar rápidamente con la creación de índices adecuados, ya que se puede reducir significativamente el número de documentos escaneados y ordenarlos de alguna manera para que sea más fácil encontrar el valor de destino. Sin embargo, al tratarse de JSON, los índices también tienen que lidiar con entidades anidadas y matrices, lo que añade un importante nivel extra de complejidad.
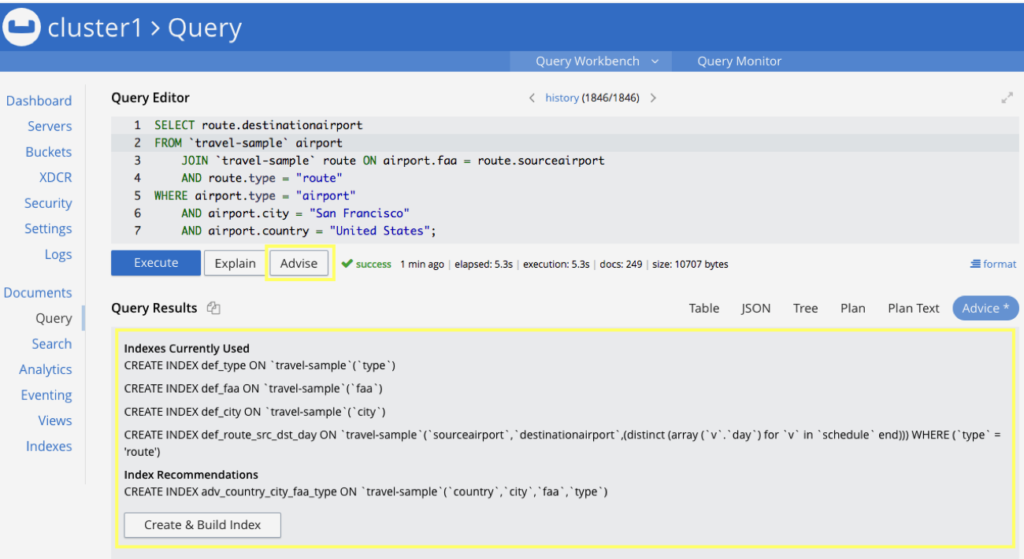
Naturalmente, crear el índice adecuado para una consulta también es una tarea que requiere cierta reflexión. De hecho, ~15% de las preguntas en los foros de Couchbase son exactamente sobre esto. Couchbase 6.5 vendrá incluso con un Recomendador de Indexadores que sugerirá un índice de acuerdo a una consulta dada:
Postgres:
Los índices para datos JSONB son una de las nuevas características de Postgres, los desarrolladores están realmente entusiasmados con ella ya que el rendimiento de las consultas aumentará significativamente en comparación con las versiones anteriores. Según la documentación principal, Postgres soporta dos tipos de índices: el índice por defecto y el índice por defecto. jsonb_path_ops:
Por defecto
|
1 |
CREATE INDEX idxusersall ON users USING GIN (address); |
Este índice permite utilizar consultas con los operadores de nivel superior de existencia de clave ?, ?& y ?| y el operador de existencia de ruta/valor @> . Además, también puede indexar un campo específico:
|
1 |
CREATE INDEX idxusers ON users USING GIN ((address -> 'entrances')); |
Para el índice GIN, sólo puede especificar un único campo.
jsonb_path_ops
|
1 |
CREATE INDEX idxginp ON api USING GIN (jdoc jsonb_path_ops); |
La clase de operador GIN no predeterminada jsonb_path_ops sólo admite la indexación del operador @>. Normalmente resultará en un índice más rápido y más pequeño. Puede más información aquí.
Actualización del artículo:
Mark (que comentó aquí en este artículo) y @postgresmen en twitter destacaron que se pueden crear índices con múltiples campos utilizando BTrees o GIST:
|
1 2 3 |
// for a JSONB collumn called "data" with the following content: // {"a": %s, "b":2, "c":1, "d":3} create index t1_l2 on users using btree((address->>'a'), (address->>'b'), (address->>'c')); |
A continuación, puede utilizar el índice anterior con la siguiente consulta:
|
1 |
select from t1 where address->>'a' = 1::text |
También puede utilizar índices parciales con la sintaxis anterior:
|
1 2 |
create index t1_l3 on users using btree((address->>'a'), (address->>'b'), (address->>'c')) where address->'state' = '"CA"'; |
En la documentación oficial sólo tiene 2 páginas sobre cómo indexar campos JSONB, Sólo después de que Mark/@postgresmen me informara pude averiguar cómo crear ciertos tipos de índices. Indexación JSONB debe recibir actualizaciones interesantes en las próximas versiones de Postgres.
Couchbase:
Los índices son en realidad el núcleo de Couchbase, actualmente soportamos 7 tipos diferentes:
- Principal – Indexa todo el bucket en la clave del documento
- Secundaria – Indexa un escalar, objeto o matriz utilizando una clave-valor
- Compuesto/Cubierto – Múltiples campos almacenados en un índice
- Funcional – Índice secundario que permite expresiones funcionales en lugar de una simple clave-valor
- Matriz – Un índice de elementos de matriz que van desde valores escalares simples hasta matrices complejas u objetos JSON anidados a mayor profundidad en la matriz.
- Adaptativo – Índice de matriz secundario para todos o algunos campos de un documento sin tener que definirlos de antemano.
- Índice parcial - Permite indexar sólo un subconjunto de datos
Como puedes ver, los índices son algo bastante maduro en Couchbase y mucho más flexibles que los soportados por Postgres JSONB. No voy a profundizar en ello porque este artículo ya es bastante largo, sólo me gustaría destacar dos cosas que personalmente creo que son realmente geniales: Índices Parciales Cubiertos y Pushdowns Agregados.
Índices parciales cubiertos
Con una combinación de Covered y Partial puedes crear índices sólo para el subconjunto de datos que te interesa.
EX: Digamos que tienes un juego online y necesitas mostrar una tabla de clasificación por país, también ignoras a los usuarios inactivos o con menos de 10 puntos. El rendimiento de tu tabla de clasificación está bien para todos los países excepto para China, que tiene 10 veces más jugadores. En este caso, podrías crear un índice específico para mejorar la velocidad de tu consulta:
|
1 2 3 4 5 6 |
CREATE INDEX `china_leader_board` ON `user_profiles`( username, points DESC) WHERE active = true and countryCode = "CN" and points > 10 |
Tenga en cuenta que ya mantenemos los puntos ordenados, por lo que una consulta como la siguiente debería ser rapidísima:
|
1 |
Select username, points from user_profiles where active = true and countryCode = "CN" order by points DESC limit 20 |
Flexiones agregadas
La agregación es siempre una tarea difícil para almacenamientos no columnares, en Couchbase te permitimos crear índices para hacer tu agregación más rápida. Pongamos el siguiente ejemplo:
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
Esta consulta tardó ~90ms en ejecutarse, aquí está el plan de consulta:

Ahora, vamos a crear el siguiente índice:
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
Si volvemos a ejecutar la misma consulta, debería ejecutarse en ~7ms, nótese que en el nuevo plan de consulta no hay ningún paso de "grupo":

Puede más información sobre los índices de Couchbase
Notatravel-sample es una de las bases de datos de demostración que puede cargar al instalar Couchbase
Rendimiento
Aunque ambas bases de datos se consideran CP (Consistent/Partition Tolerant), Postgres es un RDBMS Maestro/Esclavo tradicional, mientras que Couchbase está optimizado para lecturas/escrituras rápidas a escala y soporte adicional para Vistas atómicas monótonas
Desafortunadamente, sólo hay unos pocos benchmarks de JSONB publicados en línea, y en los más recientes Postgres ha sido más rápido que Mongo para una instancia de nodo único (aquí también). Los resultados son bastante impresionantes, pero vale la pena destacar que la mayoría de esas comparaciones se hicieron contra sólo uno o dos nodos, que es un escenario que favorece a RDBMS en general.
No quiero hacer hincapié en la arquitectura de Couchbase aquí, pero como una base de datos de memoria primero, su aplicación recibe el acuse de recibo de una escritura exitosa tan pronto como la base de datos recibe la solicitud, y luego su documento se replica de forma asíncrona y se escribe en el disco (sí, también puede cambiar cuando desea recibir el acuse de recibo).
Si además añadimos que Couchbase tiene una arquitectura sin maestros (tu aplicación envía las escrituras/lecturas directamente al servidor adecuado), un soporte de indexación mucho mejor, y la alta escalabilidad (hay clientes que ejecutan clusters CB individuales en producción con +100 nodos), para mí está claro cuál tendrá un mejor rendimiento a escala, la cuestión es sólo "cuánto".
Todavía no hay un benchmark Postgres vs Couchbase, si quieres ver uno, envíame un tweet a @deniswsrosa. Mientras tanto, puede comparar indirectamente el rendimiento de ambos utilizando este método Punto de referencia de Couchbase/Mongo/Cassandra
Conclusión
Estoy realmente entusiasmado con el creciente soporte de JSON en Postgres, definitivamente hará que los desarrolladores se familiaricen más con los beneficios de almacenar datos como JSON y, en consecuencia, hará que las Bases de Datos de Documentos también sean más populares.
Muchas herramientas y marcos de trabajo del mercado ya ofrecen compatibilidad con datos JSON y, a medida que aumente la adopción de Postgres JSONB, debería convertirse en una característica estándar, lo que, una vez más, es positivo para todos los usuarios. Base de datos NoSQL.
Sin embargo, hay que tener en cuenta algunas cosas antes de lanzarse al JSONB de Postgres:
- Lenguaje de consulta complejo: el lenguaje de consulta actual para JSONB no es intuitivo, incluso después de leer los documentos sigue siendo un poco complejo entender lo que está pasando en la consulta. PG 12 podría resolver algunos de esos problemas con el Lenguaje JSON Pathpero seguirá pareciendo una mezcla de otro lenguaje con SQL. Preferiría que Postgres añadiera soporte para SQL++.
- Lenguaje de consulta limitado: Además de ser complejo, el lenguaje de consulta aún no está disponible. Faltan funciones para manipular datos JSON, por ejemplo, tienes que utilizar algunas soluciones para hacer algunas manipulaciones básicas de matrices. Si tienes un JSON muy dinámico y necesitas consultarlo de múltiples maneras, las cosas pueden ponerse realmente difíciles. Parece que el enfoque principal hasta ahora era construir el puente entre el JSON y los datos relacionales.
- Indexación: Con el nuevo tipo de índice, las consultas se ejecutarán mucho más rápido que antes. Además, puede utilizar BTree y Gist para cubrir casos no admitidos por GIN.
- Documentación superficial: Sólo hay ~6 páginas de documentación que hablan de JSONB. La mayoría de las cosas que aprendí mientras escribía este artículo se basaron en prueba y error, preguntas de StackOverflow, entradas de blog y presentaciones de youtube y
- Herramientas: No he mencionado esto durante el artículo, pero como es una característica bastante nueva, naturalmente algunos frameworks/SDKs no han añadido soporte completo para todavía. Tomemos SpringData como un ejemplo, hay algunos esfuerzos comunitarios pero no es una experiencia totalmente fluida. Cabe esperar algunos contratiempos por el camino.
Algunos de los problemas anteriores son conocidos, incluso se mencionan en algunas charlas/artículos enlazados en este artículo. Los más críticos ya están en la hoja de ruta de las próximas versiones de Postgres.
Contrariamente a la mayoría de las presentaciones populares que he visto, no creo que sea una buena opción para modelos muy dinámicos, sobre todo porque la consulta y manipulación de datos no es tan fácil como podría ser.
¿Dónde encaja Postgres JSONB?
Aunque he señalado algunos problemas desde mi punto de vista, creo que es una función valiosa y que deberías plantearte utilizarla. He aquí algunos escenarios en los que creo que es una buena opción:
- CQRS/Contratación de eventos sistemas que deben ser altamente transaccionales
- Metadatos
- Evitar uniones innecesarias almacenando algunas entidades relacionadas como JSONBs en su lugar.
- Siempre que tengas que almacenar cadenas codificadas en JSON pero no necesites manipular o consultar los datos con demasiada frecuencia.
En los casos anteriores, Postgres debería funcionar bien, incluso para grandes despliegues. Los índices pueden ser un poco grandes con GIN, pero aún manejables.
¿Dónde encaja bien Couchbase?
Llevo más de 4 años trabajando con éxito con bases de datos documentales y, a estas alturas, puede que sea un poco parcial, pero creo que los escenarios en los que se puede utilizar como sustituto de un RDBMS son mucho más amplios de lo que cabría esperar. Algunos de los casos de uso más conocidos son:
- Almacenes de perfiles de usuario;
- Catálogos de productos/Carros de la compra;
- Historial médico (para HealthCare);
- Contratos, pólizas de seguros;
- Medios de comunicación social;
- Juegos de azar;
- Caché;
- …
De hecho, la mayoría de los sistemas que no requieren transacciones serializables fuertes entre múltiples documentos debería ser un buen ajuste, eso no significa que las transacciones no estén soportadas en absoluto, es sólo una versión más relajada que no comprometerá la escalabilidad de la base de datos, ¡especialmente con Couchbase 6.5!
Couchbase CE y EE realmente brillan cuando necesitas rendimiento a escala. Puedes crear fácilmente clusters con 3,5,10,50,100 nodos y aún así mantener un buen rendimiento y una fuerte consistencia, por eso es actualmente una de las principales opciones para aplicaciones de misión crítica. Si tienes tiempo echa un vistazo a algunas de las casos de uso público.
Todos esos casos de uso críticos a lo largo de los años hicieron que N1QL y la indexación fueran muy sólidos, rápidos y flexibles. Es por eso que incluso lo considero una comparación injusta dado el estado actual de Postgres JSONB, aunque es válido para mostrar a los desarrolladores las brechas entre una implementación temprana frente al mejor soporte de JSON hasta el momento.
Si tiene alguna pregunta, comentario o está totalmente en desacuerdo conmigo, no dude en tuitearme en @deniswsrosa
Puedes utilizar índices funcionales btree normales en alguna función que extraiga datos de una columna JSONB.
Esto es muy útil, por ejemplo, si tiene un valor dentro de un objeto json que desea indexar para operaciones de coincidencia exacta, u otras cosas que funcionan con btree.
También es posible utilizar un índice parcial simultáneamente.
Gracias por el consejo, Mark. Actualizaré el post del artículo.
Hola Mark, he actualizado el contenido con tus recomendaciones. Muchas gracias por el aviso.
buena explicación. Gracias
Estoy intentando copiar el archivo .json (generado usando cbexport) pero obtengo errores. Hay algún enlace que tiene una buena explicación sobre cómo copiar cubo couchbase a postgres tabla JSON por favor envíeme.
[...] Otras consultas [...]