Estoy empezando a utilizar NiFi, una herramienta para automatizar el flujo de datos. Es una herramienta para la migración, sincronización y otros tipos de procesamiento de datos. Me la presentó uno de los clientes más recientes de Couchbase: los Cincinnati Reds.
En este post, describiré para qué usan NiFi los Reds y te mostraré cómo poner en marcha un flujo de datos muy básico desde SQL Server a Couchbase Server.
NiFi y los Rojos
Los Reds quieren crear algunas visualizaciones de las entradas escaneadas el día del partido en el Great American Ball Park.
El equipo de datos tiene acceso a una base de datos SQL Server que se utiliza para almacenar datos en directo sobre un partido. Cada vez que se escanea una entrada en la puerta, los datos se introducen en esta base de datos. (Esta base de datos también registra las concesiones y otros datos).
Los Reds podrían consultar los datos directamente desde el servidor SQL, pero una visualización en tiempo real durante el tiempo de juego resultaría en una visualización lenta o demasiada carga para la base de datos, o ambas cosas. En su lugar, les gustaría copiar esos datos en un clúster Couchbase, y utilizar el clúster como backend para la visualización.
Hay varias formas de mover datos de a Couchbase, pero los Reds ya están usando Apache NiFi de código abierto con SQL Server, y sería ideal que pudieran usar esa misma combinación para este proyecto. Afortunadamente, NiFi ya es compatible con Couchbase, así que es bastante fácil de hacer.
Primeros pasos con NiFi y Couchbase
Para empezar a experimentar con NiFi localmente, decidí utilizar Docker. Dentro del host de Docker, puedo girar fácilmente una instancia cada uno de:
- Servidor Couchbase (por supuesto)
- Apache Nifi (Enlace al hub Docker)
- Microsoft SQL Server (para Linux; no creo que los rojos utilicen SQL para Linux, pero se parece bastante)
No es necesario utilizar Docker, pero a mí me facilitó mucho la puesta en marcha y la productividad de inmediato.
Estos son los comandos que utilicé para ejecutar las imágenes Docker:
|
1 2 3 4 5 |
docker run -d --name db55beta -p 8091-8094:8091-8094 -p 11210:11210 couchbase:5.5.0-beta docker run -d --name NiFi -p 8080:8080 apache/nifi:latest docker run -d -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=<use a strong password here>' -p 1433:1433 microsoft/mssql-server-linux:2017-latest |
Tenga en cuenta que la contraseña que proporcione a SA_PASSWORD debe cumplir los requisitos de contraseña segura de SQL Server. De lo contrario, no podrá utilizar SQL Server y se sentirá un poco frustrado y confundido durante unos 20 minutos.
Empezar con SQL Server
Utilicé SQL Server Management Studio para conectarme a la instancia de SQL Server en Docker (localhost, puerto 1433). No tengo (todavía) acceso al servidor real de Reds, así que me inventé mi propio esquema para aproximar:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE [dbo].[TicketCheck]( [Id] [uniqueidentifier] NOT NULL, [FullName] [varchar](100) NOT NULL, [Section] [varchar](10) NOT NULL, [Row] [varchar](10) NOT NULL, [Seat] [varchar](10) NOT NULL, [GameDay] [datetime] NOT NULL, CONSTRAINT [PK_TicketCheck] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[TicketCheck] ADD CONSTRAINT [DF_TicketCheck_Id] DEFAULT (newid()) FOR [Id] GO |
Más tarde, lo poblaré con un INSERTAR declaración así:
|
1 2 3 4 5 6 7 |
INSERT INTO TicketCheck (FullName, Section, [Row], Seat, GameDay) VALUES ( 'Joey Votto', '429', 'C', '11', GETDATE() ) |
Configuración de Couchbase
Una vez que inicié sesión en Couchbase por primera vez (localhost:8091) y creé un clúster, hice dos cosas:
- He creado un bucket llamado "tickets". Aquí es donde quiero que vayan los datos de SQL Server.
- He creado un usuario también llamado "tickets", con el permiso adecuado para el cubo. Es importante que el usuario tenga el mismo nombre que el cubo.
La razón por la que necesitas crear un usuario con el mismo nombre es porque el procesador NiFi Couchbase está un poco desactualizado, así que esto es una solución provisional. NiFi no ha sido actualizado para manejar las nuevas capacidades RBAC de Couchbase, todavía. Ver Apache Nifi número 5054 para más información.
Configurar NiFi
NiFi es una herramienta visual de flujo de datos basada en la web. Soy desarrollador, estoy acostumbrado al código y a las líneas de comandos, pero sin duda aprecio una interfaz visual agradable cuando es aplicable.
Si ha utilizado Docker, visite localhost:8080/NiFi. Verás lo que parece una gran hoja de papel cuadriculado con algunas barras de herramientas/ventanas en la parte superior.
Voy a saltar un poco la cabeza y mostrar el flujo de datos completo que he construido:
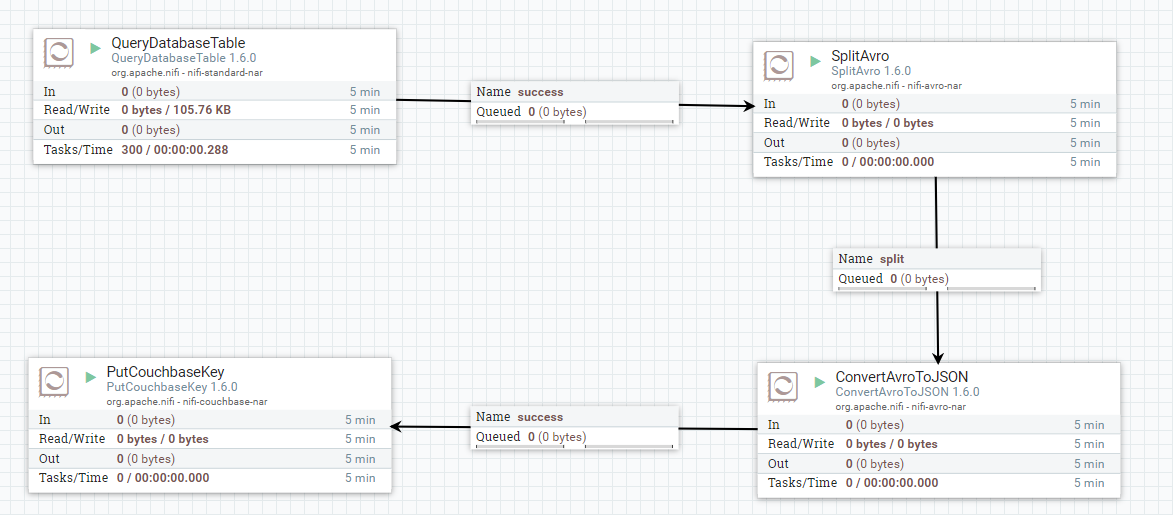
Iré paso a paso, pero ten en cuenta que no soy un experto en NiFi.
A un alto nivel, cada una de estas cajas son "procesadores". Cada una de ellas recibe datos de algún lugar, los procesa de alguna manera y los escribe en otro lugar. Este "flujo" de datos puede proceder de una fuente externa, de una cola NiFi o escribirse en una fuente externa. Cada procesador puede ser "Iniciado" y "Detenido".
Servicio de agrupación de conexiones de bases de datos
Antes de crear un procesador, vamos a informar a NiFi sobre las bases de datos que vamos a utilizar.
Hay una ventana "Operar" que flota sobre el papel cuadriculado. Haga clic en el icono de configuración para abrir la ventana de configuración de NiFi Flow.
Mira la pestaña de Servicios del Controlador. Pienso en esto como una colección de fuentes de datos externas a las que los procesadores pueden conectarse. Vamos a añadir dos servicios de controlador: uno para SQL Server y otro para Couchbase.
DBCPConnectionPool
Haz clic en el botón "+" para añadir. Empecemos con SQL Server: busque DBCPConnectionPool y haga clic en "Añadir". Debería aparecer en la lista. Haga clic en el icono de engranaje y vaya a la pestaña de propiedades:
- URL de conexión a la base de datos - Introduzca un valor como
jdbc:sqlserver://172.17.0.4. - Nombre de clase del controlador de base de datos - Si utiliza SQL Server, es
com.microsoft.sqlserver.jdbc.SQLServerDriver - Ubicación(es) del controlador de base de datos - Entrar
file:///usr/share/java/mssql-jdbc-6.4.0.jre8.jar. Tenga en cuenta que NiFi no viene con este controlador fuera de la caja (al menos no la imagen Docker). Descargue este controlador de Microsoft y colóquelo en la carpeta /usr/share/java de su servidor NiFi (puede utilizardocker cpsi usas Docker como yo). - Usuario de la base de datos y Contraseña - Las credenciales de SQL Server que necesita para conectarse.
Una vez que lo hayas añadido, tendrás que "activarlo" (haz clic en el icono del rayo) para poder utilizarlo. Si necesitas hacer cambios en el futuro, tendrás que desactivarlo primero.
CouchbaseClusterService
A continuación, vamos a informar a NiFi sobre Couchbase. De nuevo, haz clic en el botón "más" para añadir. Busca CouchbaseClusterService. De nuevo, ve a la pestaña de propiedades. Debería haber una propiedad llamada Cadena de conexión. Introduzca algo como couchbase://172.17.0.3. A continuación, haga clic en el botón "más" de esta pestaña y cree una nueva propiedad llamada "Contraseña de cubo para tickets". Tenga en cuenta que el nombre de la propiedad debe ser de la forma "Contraseña de cubo para ". El valor de esta propiedad debe ser la contraseña del usuario de Couchbase que creó anteriormente.
Ahora, NiFi conoce SQL Server y Couchbase. Pongámoslo en práctica.
QueryDatabaseTable
Empezaré por la fuente de los datos: un servidor SQL Server. Más concretamente, una tabla en SQL Server. Y aún más específicamente, sólo nuevas filas de datos en esa tabla (más sobre cómo definir esto más adelante).
En primer lugar, arrastra el icono "procesador" de la parte superior izquierda al papel cuadriculado. A continuación, busque el procesador QueryDatabaseTable y pulse "añadir". En este punto, tendrás un procesador en el tablero con un icono de advertencia que indica que necesitas hacer alguna configuración.
Puede hacer doble clic en este procesador para que aparezcan sus detalles. Me interesa sobre todo la pestaña "Propiedades". En esta pestaña, voy a indicar a este procesador a qué base de datos debe conectarse y cómo debe consultar los datos de la misma:
Las propiedades de interés:
- Servicio de agrupación de conexiones de bases de datos - Seleccione el DBCPConnectionPool creado anteriormente.
- Tipo de base de datos - Seleccioné MS SQL 2008, que parece funcionar bien con MS SQL para Linux, pero también hay opciones para MS SQL 2012+ y "Genérico".
- Nombre de la tabla - Introduzca el nombre de la tabla a consultar.
TicketCheckes el que he utilizado. - Columnas de valor máximo - He entrado
GameDay. Esta es la columna que NiFi comprobará para encontrar datos nuevos/actualizados en la tabla. Puede utilizar un campo autoincrementado, una marca de tiempo o cualquier otra combinación. El procesador NiFi almacenará el último valor en su "estado" a medida que avanza.
PutCouchbaseKey
Avancemos un poco y creemos otro procesador. Esta vez será un procesador PutCouchbaseKey. Todo lo que hace este procesador es tomar una pieza de datos que fluye hacia él y crear/actualizar un documento Couchbase con esos datos.
Para configurarlo, establezca estas propiedades:
- Servicio de controlador de clúster de Couchbase - seleccione el CouchbaseClusterService creado anteriormente.
- Nombre del cubo - entradas
Ir del punto A al punto B
En este punto, NiFi es capaz de extraer datos de SQL Server y poner documentos en Couchbase. Para terminar, es necesario conectarlos. Pero aún queda un poco de trabajo por hacer. El procesador QueryDatabaseTable produce datos "Avro", que está diseñado para Hadoop, pero también es utilizado por Spark y, por supuesto, Nifi. Podríamos alimentar esto directamente en Couchbase, pero sería almacenado como datos binarios, y no JSON. Por lo tanto, hay un par de pasos intermedios para conseguir que en forma JSON puro.
He añadido un procesador SplitAvro y un procesador ConvertAvroToJSON al papel cuadriculado.
El procesador SplitAvro dividirá el archivo de datos Avro (potencialmente grande) en archivos más pequeños. Puede que esto no sea estrictamente necesario, pero es una buena precaución, y ayuda a dividir los datos para facilitar su visualización y depuración. Las propiedades por defecto de este procesador están bien.
El procesador ConvertAvroToJSON hace exactamente lo que dice. Esto preparará los datos Avro para Couchbase. He cambiado el Opciones del contenedor JSON propiedad de matriz a ninguno. Sólo quiero un documento JSON plano, y no un array que contenga un único documento.
Conectarlo todo
Ahora que tienes estas cuatro piezas en su sitio, tienes que conectarlas.
En primer lugar, pase el ratón por encima de la QueryDatabaseTable hasta que aparezca el icono de una flecha. Haga clic en esta flecha y arrástrela hasta el procesador SplitAvro. Aparecerá una cola entre ambos llamada "success".
Repita esta operación con los demás procesadores. Un procesador puede tener varios puntos de terminación que definen la relación. Por ejemplo, cuando arrastre una conexión entre SplitAvro y ConvertAvroToJSON, se le presentarán tres opciones: fallo, original y división. Esto variará de un procesador a otro, pero ésta es la idea:
- fallo - SplitAvro falló en la conversión, entonces enviará los datos a "fallo"
- original - SplitAvro puede canalizar los datos originales de esta manera
- dividir - Los datos reales de la división van así. Esto es lo que debe introducir en ConvertAvroToJSON.
Con las otras conexiones, podrías canalizar los datos de vuelta al proceso para reintentarlo, o quizás canalizarlos a algún procesador de notificación o depuración.
Activar el flujo NiFi
Para iniciar un procesador, haz clic en él y, a continuación, en el botón "start" de la ventana Operate (se parece al botón de reproducción de un vídeo). Puede que le interese experimentar con un solo procesador cada vez y ver cómo se acumulan los datos en las colas. Al final, cuando empieces a insertar filas en la tabla de SQL Server, deberían acabar como nuevos documentos en Couchbase Server.
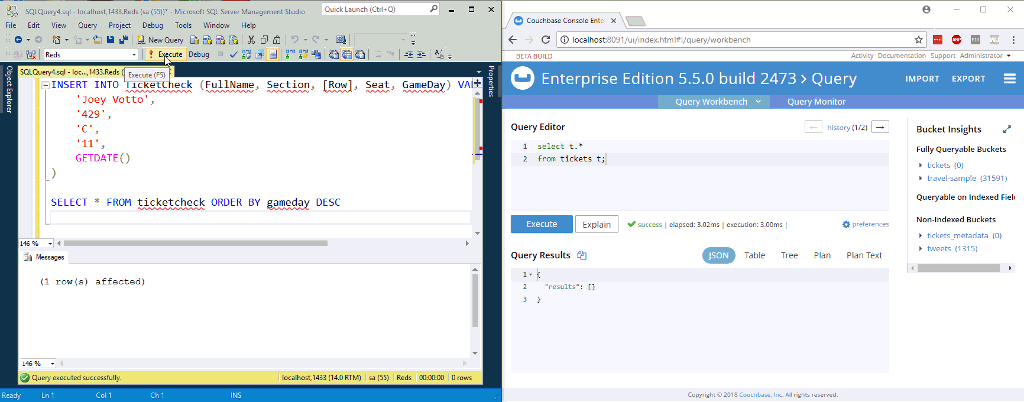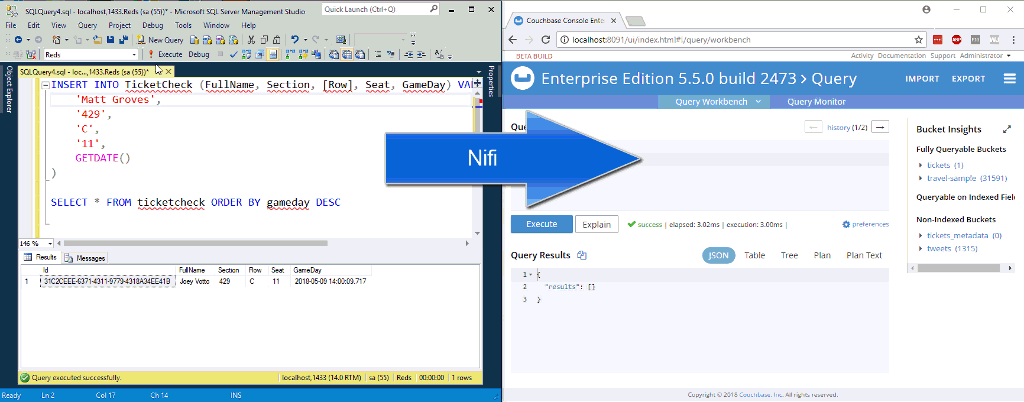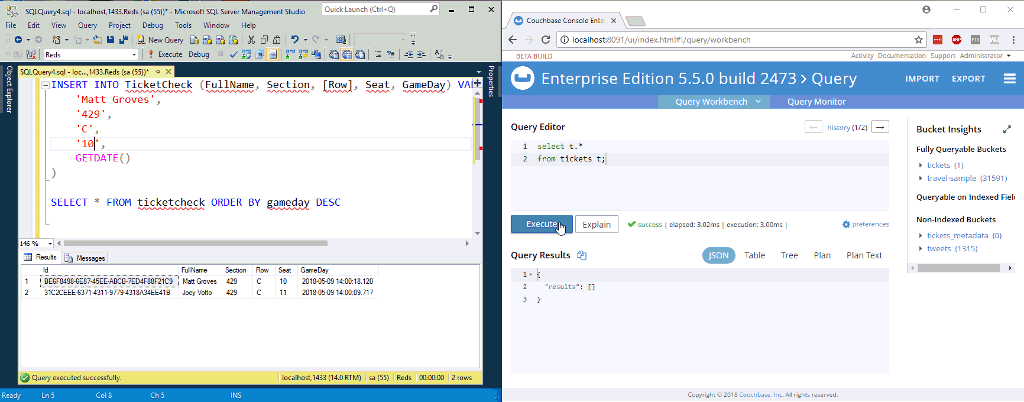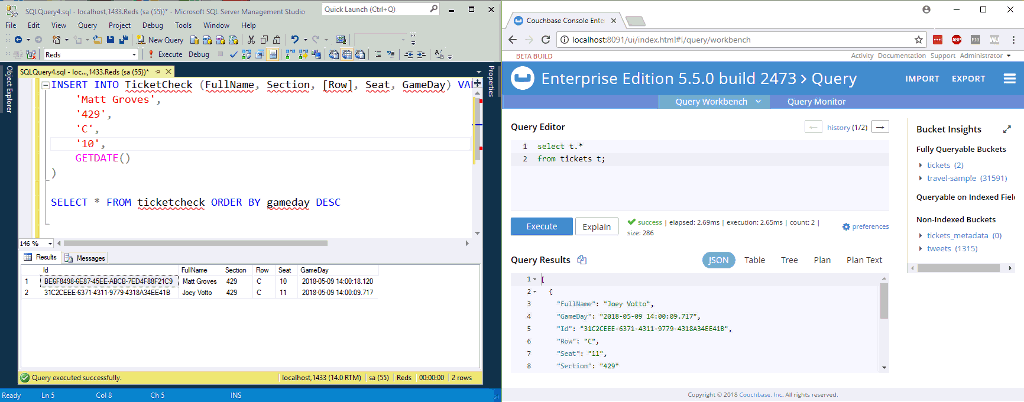
En la animación de arriba, estoy insertando dos nuevas filas en una tabla de SQL Server. NiFi (que no aparece en la imagen) las procesa y las introduce en Couchbase.
Resumen
Esta entrada del blog explica cómo empezar a utilizar NiFi. Hay muchas cosas que puede hacer. Si estás en una empresa con una variedad de fuentes de datos, NiFi es una gran herramienta para orquestar todos esos flujos de datos. Couchbase Server es un gran ajuste también:
- La flexibilidad de JSON permite introducir datos de casi cualquier fuente.
- La arquitectura memory-first ayuda a maximizar el rendimiento de su flujo de datos
- Las capacidades de escalado de Couchbase le permiten aumentar su capacidad sin tener que desconectar su flujo.
Estoy aprendiendo NiFi por primera vez, y ya estoy amando la interfaz gráfica y la simplicidad de empezar. Todavía tengo mucho que aprender, pero espero que este post te ayude con el uso del procesador Couchbase en NiFi.
Si utilizas NiFi y Couchbase, quiero saber de ti. El conector Couchbase podría utilizar actualizado (véase el número 5054), y cuantos más seáis, más fácil me resultará justificar el tiempo que le dedique.
Si tiene alguna pregunta sobre Couchbase, consulte la página Foros de Couchbase Server. Si tiene alguna pregunta sobre NiFi, consulte el Apache Nifi sitio web del proyecto.
También estoy encantada de hablar contigo sobre todo lo anterior. Puedes dejarme un comentario más abajo, o encontrarme en Twitter @mgroves.