Las nuevas funciones de consulta ocupan un lugar destacado en la última versión de Couchbase Server 5.5. Echa un vistazo a el anuncio y descárguese la versión gratuita ahora mismo.
En esta entrada, quiero destacar algunas de las nuevas funciones y mostrarte cómo empezar a utilizarlas:
- ANSI JOINs - N1QL en Couchbase ya tiene JOIN, pero ahora JOIN es más compatible con los estándares y más flexible.
- Uniones HASH: el rendimiento de determinados tipos de uniones puede mejorarse con una unión HASH (sólo en Enterprise Edition).
- Agregación pushdowns - GROUP BY puede ser empujado hacia el indexador, mejorando el rendimiento de la agregación (sólo en Enterprise Edition)
Todos los ejemplos de este post utilizan el bucket "travel-sample" que viene con Couchbase.
UNIONES ANSI
Hasta Couchbase Server 5.5, los JOINs eran posibles, con dos advertencias:
- Un lado del JOIN tiene que ser clave(s) de documento
- Debe utilizar el
EN TECLASsintaxis
En Couchbase Server 5.5, ya no es necesario utilizar EN TECLASpor lo que escribir joins resulta mucho más natural y más acorde con otros dialectos de SQL.
Sintaxis JOIN anterior
Por ejemplo, aquí está la sintaxis antigua:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON KEYS r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
Esto obtendrá 10 rutas que comienzan en el aeropuerto CMH, unidas con sus correspondientes documentos de aerolíneas. Los resultados están abajo (los estoy mostrando en vista de tabla, pero sigue siendo JSON):
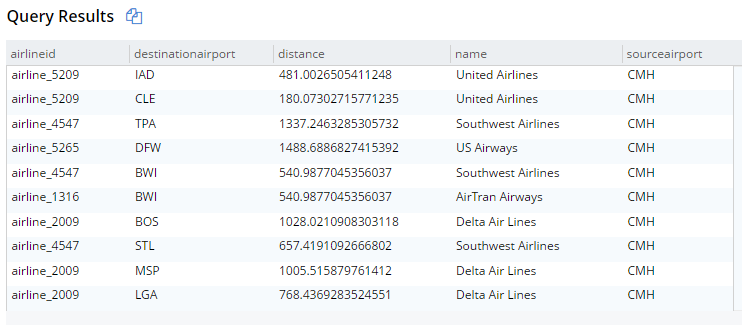
Nueva sintaxis JOIN
Y aquí está la nueva sintaxis haciendo lo mismo:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON META(a).id = r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
La única diferencia es el EN. En lugar de EN TECLASAhora es ON =. Es más natural para los que proceden de un entorno relacional (como yo).
Pero eso no es todo. Ahora ya no estás limitado a unirte sólo a claves de documentos. He aquí un ejemplo de ÚNASE A en un campo de la ciudad.
|
1 2 3 4 5 6 |
SELECT a.airportname, a.city AS airportCity, h.name AS hotelName, h.city AS hotelCity, h.address AS hotelAddress FROM `travel-sample` a INNER JOIN `travel-sample` h ON h.city = a.city WHERE a.type = 'airport' AND h.type = 'hotel' LIMIT 10; |
Esta consulta mostrará los hoteles que coincidan con los aeropuertos en función de su ciudad.
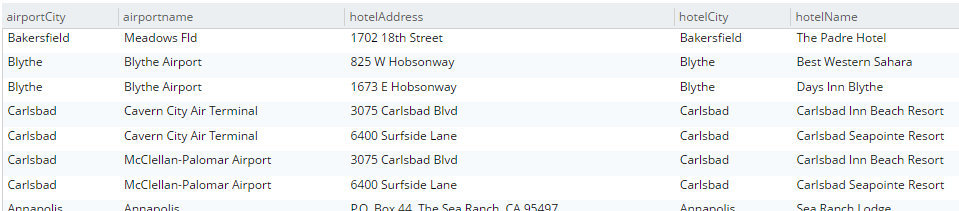
Tenga en cuenta que para que esto funcione, debe tener un índice creado en el campo que está en el lado interno del JOIN. El bucket "muestra-viaje" ya contiene un índice predefinido en el campo ciudad. Si lo intentara con otros campos, obtendría un mensaje de error como "No index available for ANSI join term...".
Para más información sobre ANSI JOIN, consulte la página documentación completa de N1QL JOIN.
Nota: La antigua sintaxis JOIN, ON KEYS seguirá funcionando, así que no se preocupe por tener que actualizar su antiguo código.
Uniones Hash
Debajo de las cubiertas, hay diferentes formas en las que se pueden llevar a cabo los joins. Si ejecutas la consulta anterior, Couchbase utilizará un Bucle anidado (NL) para ejecutar la unión. Sin embargo, también puedes instruir a Couchbase para que use un método unión hash en su lugar. A veces, un hash join puede ser más eficaz que un bucle anidado. Además, una unión hash no depende de un índice. Sin embargo, sí depende de que la unión sea sólo de igualdad.
Por ejemplo, en "travel-sample", podría unir puntos de referencia con hoteles en sus campos de correo electrónico. Puede que no sea la mejor forma de averiguar si un hotel es un punto de referencia, pero como el correo electrónico no se indexa por defecto, es ilustrativo.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
La consulta anterior tardará mucho tiempo en ejecutarse y probablemente se agote.
Sintaxis
A continuación probaré con un hash join, que debe invocarse explícitamente con una directiva USAR HASH insinuar.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h USE HASH(BUILD) ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
Un hash join tiene dos lados: un CONSTRUIR y un SONDA. En CONSTRUIR de la unión se utilizará para crear una tabla hash en memoria. La dirección SONDA utilizará esa tabla para encontrar coincidencias y realizar la unión. Normalmente, esto significa que desea que la tabla CONSTRUIR que se utilizará en el menor de los dos conjuntos. Sin embargo, sólo se puede proporcionar una sugerencia de hash, y sólo para el lado derecho de la unión. Por tanto, si especifica CONSTRUIR en el lado derecho, entonces está utilizando implícitamente SONDA en el lado izquierdo (y viceversa).
CONSTRUIR y SONDEAR
Entonces, ¿por qué utilicé HASH(CONSTRUIR)?
Lo sé por usar INFER y/o Ideas para cubos que los puntos de referencia representan aproximadamente 10% de los datos, y los hoteles alrededor de 3%. Además, sé por haberlo probado que HASH(CONSTRUIR) era ligeramente más lento. Pero en cualquier caso, el tiempo de ejecución de la consulta era de milisegundos. Resulta que hay dos pares hotel-landmark con la misma dirección de correo electrónico.
USAR HASH le dirá a Couchbase que intente un hash join. Si no puede hacerlo (o si estás usando Couchbase Server Community Edition), volverá a un nested-loop. (Por cierto, puedes especificar explícitamente nested-loop con la opción USO NL pero actualmente no hay ninguna razón para hacerlo).
Para más información, consulte Unión HASH áreas de la documentación.
Flexiones agregadas
Las agregaciones en el pasado han sido complicadas cuando se trata de rendimiento. Con Couchbase Server 5.5, flexiones agregadas son ahora compatibles con SUM, COUNT, MIN, MAX y AVG.
En versiones anteriores de Couchbase, la indexación no se utilizaba para sentencias que implicaban GRUPO POR. Esto podría afectar gravemente al rendimiento, porque hay un paso extra de "agrupación" que tiene que tener lugar. En Couchbase Server 5.5, el servicio de índices puede hacer la agrupación/agregación.
Ejemplo
He aquí un ejemplo de consulta que busca el número total de hoteles y los agrupa por país, estado y ciudad.
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
La consulta se ejecutará y devolverá como resultado:
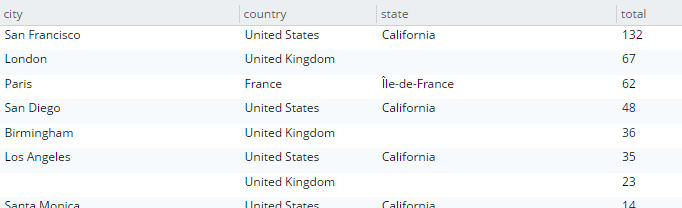
Echemos un vistazo al plan de consulta visual (sólo disponible en la edición Enterprise, pero puede ver el texto sin procesar del plan en la edición Community).

Tenga en cuenta que el único índice que se utiliza es para el tipo campo. El paso de agrupación realiza el trabajo de agregación. Con el conjunto de datos de muestras de viajes relativamente pequeño, esta consulta tarda unos 90 ms en mi escritorio de nodo único. Pero veamos qué ocurre si añado un índice a los campos por los que estoy agrupando:
Indexación
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
Ahora, ejecute lo anterior SELECCIONE de nuevo. Debería devolver los mismos resultados. Pero..:
- Ahora tarda ~7ms en mi escritorio de nodo único. Nosotros tardamos ms, pero con un conjunto de datos grande y más realista, es una diferencia de magnitud enorme.
- El plan de consulta es diferente.

Nótese que esta vez no hay paso de "grupo". Todo el trabajo se transfiere al servicio de índices, que puede utilizar la función ix_hotelregiones índice. Puede utilizar este índice porque mi consulta coincide exactamente con los campos del índice.
El "push down" del índice no siempre se produce: su consulta tiene que cumplir unas condiciones específicas. Para más información, consulte la página Rendimiento de GROUP BY y agregado áreas de la documentación.
Resumen
Con Servidor Couchbase 5.5N1QL incluye aún más sintaxis conforme a los estándares y es más eficaz que nunca.
Prueba N1QL hoy mismo. Usted puede instalar Enterprise Edition o prueba N1QL directamente en tu navegador.
¿Tiene alguna pregunta? Estoy en Twitter @mgroves. También puede consultar @N1QL en Twitter. En Foro N1QL es un buen lugar al que acudir si tiene preguntas en profundidad sobre N1QL.
Gracias por este artículo.
Le agradecería que me ayudara a entender un par de puntos:
1. Es decir, ¿el optimizador nunca elegirá una combinación HASH por su cuenta? ¿Es porque el optimizador está basado en reglas? En caso afirmativo, ¿el próximo optimizador basado en costes elige una unión HASH en lugar de una unión NL si considera que el coste es menor?
2. Una unión HASH necesitará memoria para mantener la tabla hash en memoria. ¿Qué nodo utilizará esa memoria: el nodo que ejecuta el servicio de datos, el servicio de índices o el servicio de consultas?
Hola Purav,
Puede plantear estas preguntas en https://www.couchbase.com/forums/c/sql/16 - 1) Sí, necesita instrucciones. No conozco muchos detalles sobre el optimizador y las uniones HASH/NL. 2) No estoy seguro de si es el índice o la consulta, pero no será el servicio de datos.
Gracias Matthew. Agradezco la pronta respuesta. Lo haré.