Una construcción de datos que aparece a menudo en las aplicaciones empresariales es la estructura jerárquica de datos. La jerarquía captura la relación padre-hijo que a menudo existe entre el mismo objeto. Por ejemplo, la estructura de una empresa refleja la línea jerárquica entre los empleados. La organización empresarial captura la relación entre empresas matrices y filiales. Jerarquías territoriales en Ventas. Libro de cuentas en aplicaciones financieras.
Debido a la naturaleza de auto-referencia de la jerarquía, la consulta de la estructura de manera eficiente junto con sus datos asociados puede ser un reto para RDBMS, en particular desde una perspectiva de rendimiento. En este artículo, hablaré de cómo los SGBDR tradicionales gestionan las consultas jerárquicas. Los retos con los que tiene que lidiar, y cómo este problema puede ser abordado de manera similar con Couchbase N1QL y Couchbase GSI.
Estructura jerárquica en las aplicaciones
La principal razón para reunir la información en una estructura jerárquica es mejorar la comprensión de la información. La estructura jerárquica de la empresa está diseñada no sólo para ayudar a gestionar la organización, sino también para proporcionar una estructura que permita medir y optimizar la eficacia de cada grupo. En una gran organización, el rendimiento de las ventas suele evaluarse, no sólo a nivel individual, sino a nivel de equipo de ventas. En resumen, las empresas organizan la información en una estructura jerárquica para poder comprender mejor el rendimiento comercial. Para lograr ese objetivo, las empresas necesitan un medio eficaz para consultar los datos jerárquicos.
Representación de la jerarquía de la empresa
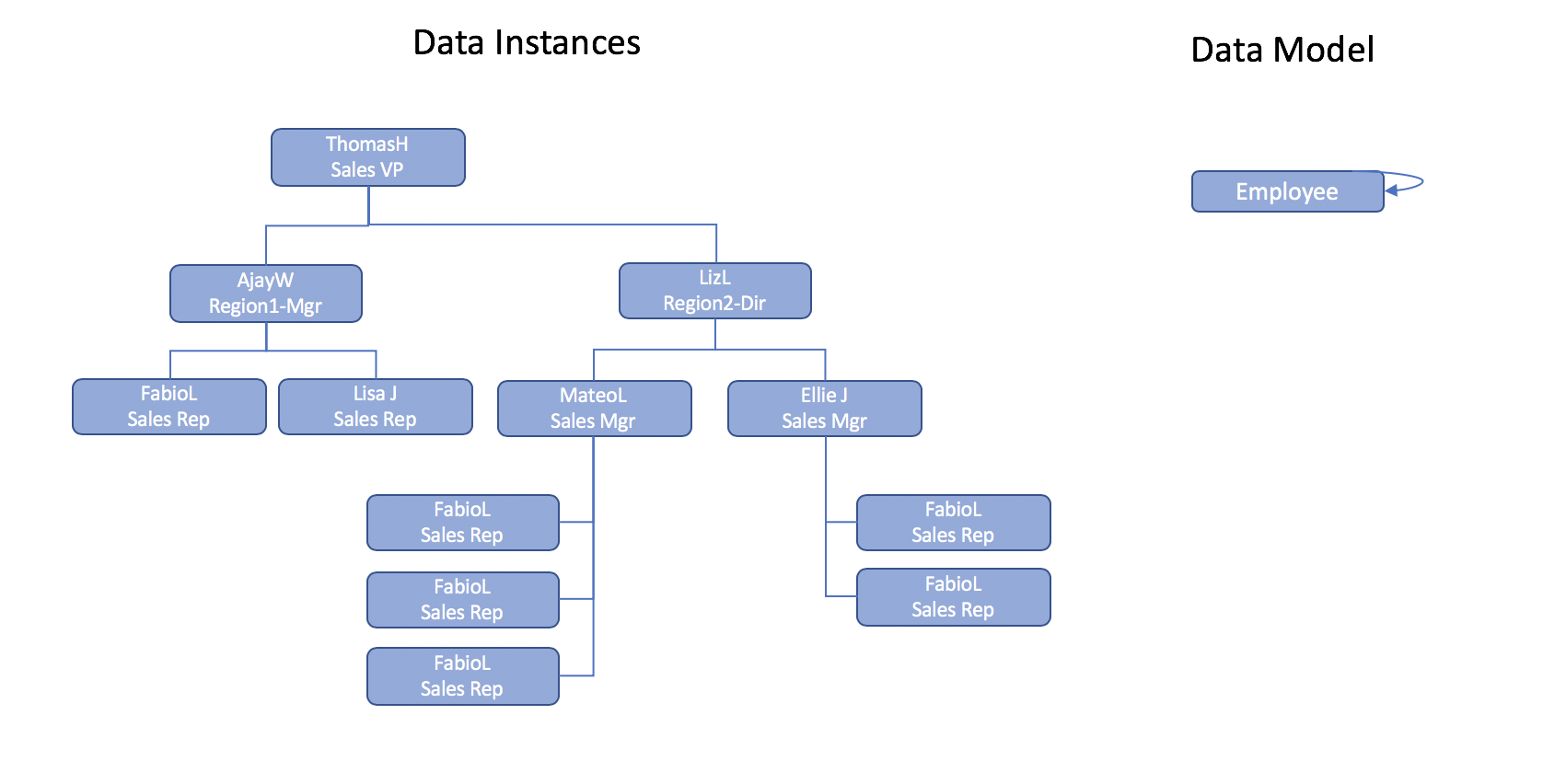
Aunque el modelo de datos de la base de datos es capaz de capturar eficazmente la estructura jerárquica, la dificultad surge cuando es necesario consultar los datos jerárquicos y la información relacionada.
Considere este requisito: Obtenga el valor total de los pedidos de venta de todos los representantes de ventas que dependen de ThomasH-Vicepresidente de Ventas.
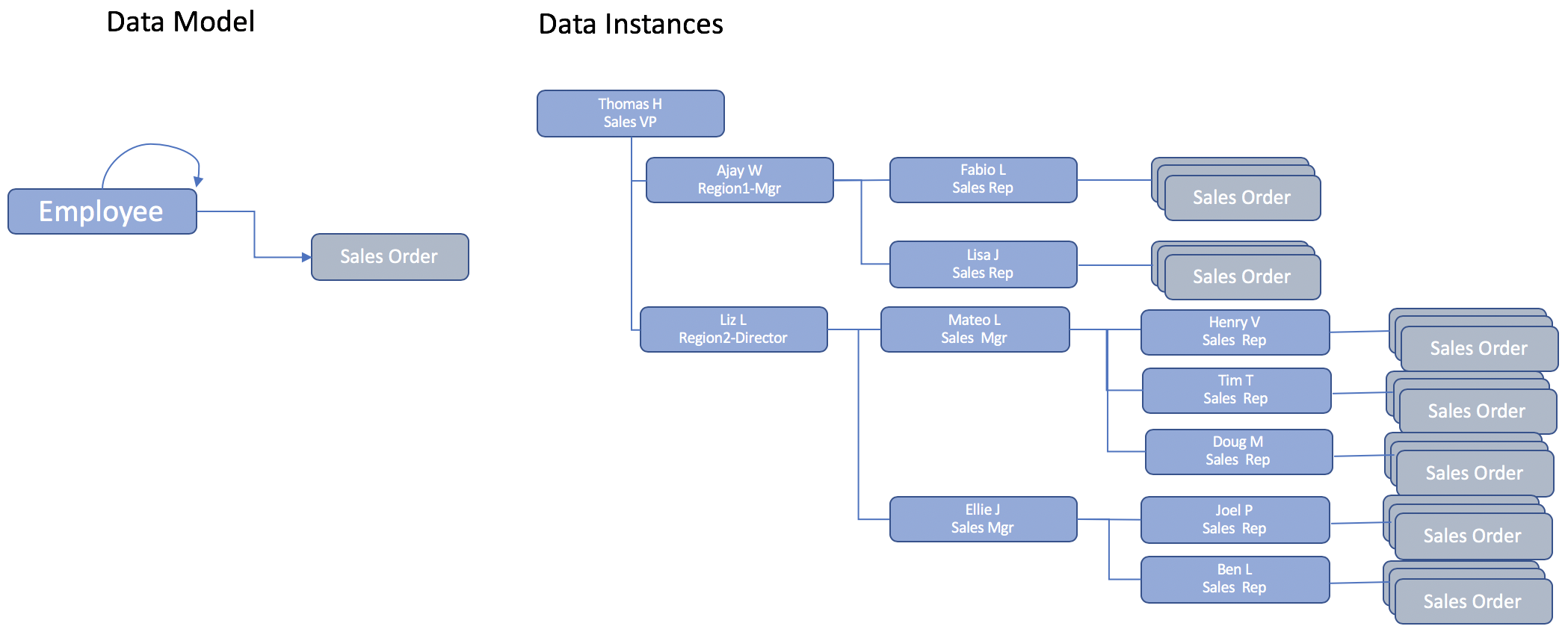
Aunque el modelo de datos es relativamente sencillo. La naturaleza jerárquica de la organización de ventas sugiere una estructura dinámica inherente en la jerarquía de informes. AjayW, que dirige el territorio de la Región1, también gestiona directamente a los miembros del equipo de ventas. Mientras que, en la Región2, Liz L dirige a dos Gerentes, que a su vez dirigen al equipo de ventas. Esto es típico en la mayoría de las jerarquías de datos de aplicación.
Enfoque RDMBS
Para consultar datos jerárquicos, los RDBMS más consolidados como Oracle y SQLSever proporcionan la construcción CONNECT BY / START WITH para permitir que una sola consulta recorra recursivamente la estructura de empleados de la jerarquía.
|
1 2 3 4 5 6 7 8 |
Consulta: Ventas pedidos generado por miembros que informe arriba a ThomasH-Ventas VP</fuerte></span> SELECCIONE e.EmpID, e.Nombre, e.ManagerID, suma(o.orderVal) DESDE empleado e INTERIOR ÚNASE A pedido_venta o EN o.EmpID = o.EmpId INICIO CON EmpID = 101 CONECTAR POR ANTERIOR EmpID = ManagerID GRUPO POR e.EmpID, e.Nombre, e.ManagerID; |
Aunque la consulta anterior puede parecer sencilla, el rendimiento de la consulta es difícil de mejorar con índices debido a la naturaleza recursiva de la implementación de CONNECT BY. Por este motivo, esta técnica no es popular en el desarrollo de aplicaciones para sistemas con un gran volumen de datos. En su lugar, las aplicaciones empresariales confían en una estructura de objetos previamente aplanada para obtener un rendimiento de consulta más predecible. La técnica de jerarquía aplanada se describe en la sección de Couchbase N1QL más abajo.
Couchbase N1QL
Para obtener el mejor rendimiento de consulta, las aplicaciones N1QL deben utilizar la estructura jerárquica aplanada. El enfoque proporciona un rendimiento más predecible, así como un mejor aprovechamiento de Couchbase GSI. El diagrama de abajo muestra un ejemplo de la transformación flattening de una estructura jerárquica autorreferenciada, como el objeto empleado. También incluyo un fragmento de código python que puedes usar para aplanar la estructura jerárquica. El aplanar_jerarquía toma un objeto JSON jerárquico auto-referenciado y genera dos nuevos objetos en el mismo espacio de claves pero con diferentes valores de tipo
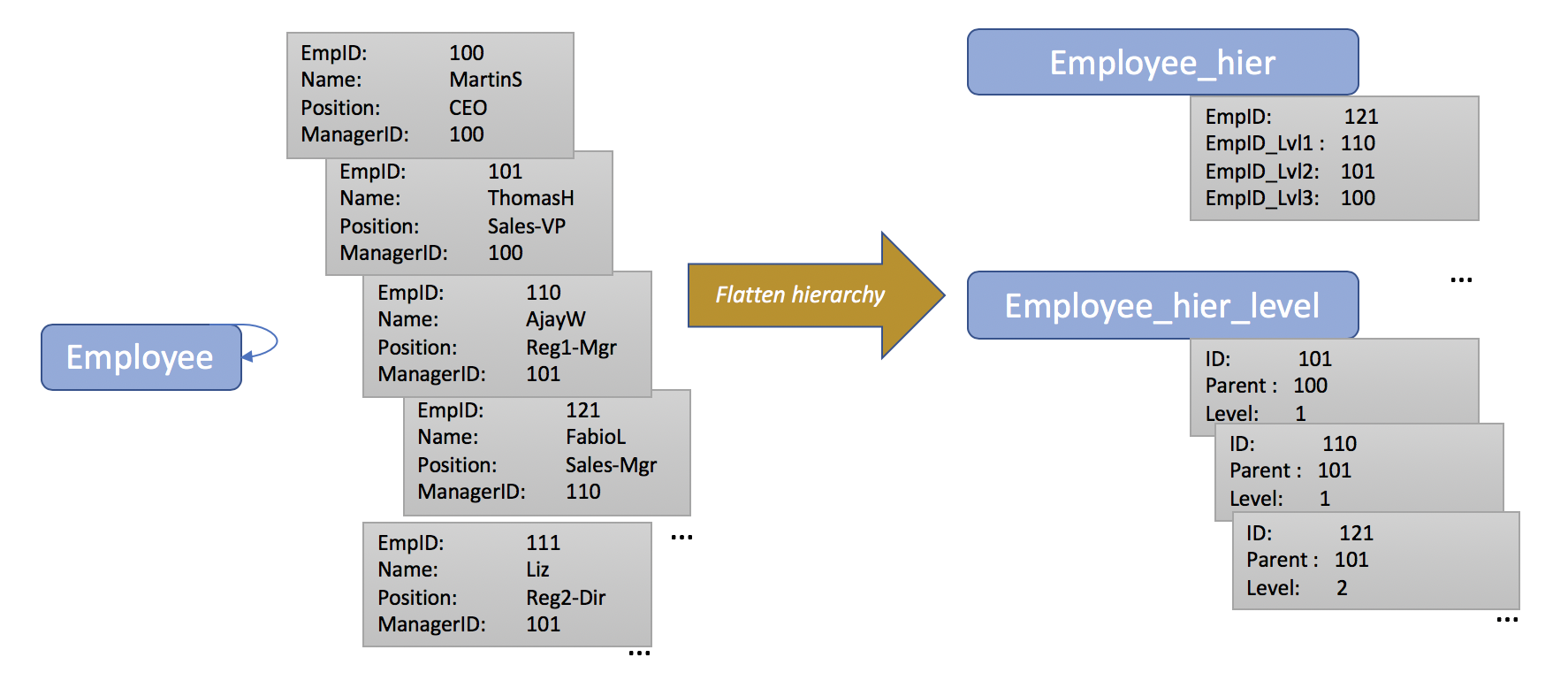
- En objeto_hier funciona con consultas BI agregadas, en las que los resultados de la consulta se pueden acumular para cada nivel.
- En objeto_nivel_superior proporciona el mismo resultado que la cláusula CONNECT BY/START WITH, que devuelve todos los objetos hijo de un nodo determinado. Este es el objeto que utilizaremos en nuestra consulta N1QL para proporcionar la solución de consulta.
|
1 2 3 4 5 6 7 8 9 10 |
N1QL Consulta: Ventas pedidos generado por miembros que informe arriba a ThomasH-Ventas VP SELECCIONE e.id,suma(a.valor) DESDE crm a INTERIOR ÚNASE A ( SELECCIONE uhl.id DESDE crm uhl DONDE uhl.tipo ='_nivel_empleado_superior' Y uhl.padre='101') e UTILICE HASH(sonda) EN a.propietario = e.id DONDE a.tipo='pedido_venta' GRUPO POR e.id |
Índice GS recomendado:
|
1 |
CREAR ÍNDICE `crm_employee_hier_level` EN `crm`(`padre`) DONDE (`tipo` = "_nivel_empleado_superior") |
Notas:
- La consulta principal recupera todos los pedidos de cliente de la base de datos
crmcubo con tipo valor = 'pedido' - La consulta realiza un HASH JOIN con otra consulta (función de N1QL 6.5) que recupera todos los ID de los empleados que dependen del usuario101, es decir, ThomasH-SalesVP
- Los índices de cobertura adicionales también pueden mejorar el rendimiento de las consultas
- La consulta utiliza N1QL 6.5 ANSI JOIN Soporte para Expresión y Subconsulta Término
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# Código Python para aplanar un documento JSON en un bucket Couchbase de couchbase.grupo importar Grupo de couchbase.grupo importar PasswordAuthenticator de couchbase.excepciones importar NotFoundError de couchbase.cubo importar Cubo de couchbase.n1ql importar N1QLQuery def aplanar_jerarquía(cb,bucketname,src_doc_type,num_hier_level,nodo_id_col, parent_id_col): # Ejemplo: flatten_hierarchy(cb,args.bucket,'user',4,'id','managerid') # cb - asa de cubo couchbase # bucketname - nombre del bucket para los documentos de origen y destino # src_doc_type - el valor del tipo del documento fuente # num_hier_level - especifica el número de niveles que se necesitan. Debe ser la profundidad máxima de la jerarquía # node_id - el nombre del campo en el documento para el id del nodo clave # parent_node_id - el campo padre # gen_doc_type = '_'+src_doc_type+'_hier' si (num_hier_level > 1): qstr_ins = INSERTAR en '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "tipo":"'+gen_doc_type+'"' para i en gama(1,num_hier_level+1): qstr_sel += id+str(i)+'":l'+str(i)+'.'+nodo_id_col qstr_sel += "} ndoc qstr_sel_one = SELECCIONAR+nodo_id_col+','+parent_id_col+FROM+bucketname+' WHERE type="'+src_doc_type+'"' para i en gama(1,num_hier_level+1): si (i==1): qstr_sel += FROM ('+qstr_sel_one+') l'+str(i) si no: qstr_sel += LEFT OUTER JOIN ('+qstr_sel_one qstr_sel += ') l'+str(i)+' ON l'+str(i-1)+'.'+parent_id_col+' = l'+str(i)+'.'+nodo_id_col pruebe: #q = N1QLQuery(qstring) filas = cb.n1ql_query(qstr_ins+qstr_sel).ejecutar() excepto Excepción como e: imprimir("error de consulta",e) # generar conectar por si (num_hier_level > 1): qstr_ins = INSERTAR en '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "id":ll.child, "parent":ll.parent, "level":ll.level , "type":"'+gen_doc_type+'_level" } ndoc FROM (' para i en gama(1,num_hier_level): si (i>1): qstr_sel += UNION ALL qstr_sel += SELECT id+str(i+1)+' padre, id1 hijo,'+str(i)+Nivel FROM+bucketname+' WHERE type="'+gen_doc_type+'" y id'+str(i+1)+' NO ES NULO ' qstr_sel += ') ll' pruebe: filas = cb.n1ql_query(qstr_ins+qstr_sel).ejecutar() excepto Excepción como e: imprimir("error de consulta",e) devolver |
Recursos
- Descargar: Descargar Couchbase Server 6.5
- Documentación: Novedades de Couchbase Server 6.5
- Todos los blogs de 6.5
Nos encantaría que nos dijera qué le han parecido las funciones de la versión 6.5 y en qué beneficiarán a su empresa en el futuro. Por favor, comparta su opinión a través de los comentarios o en el foro.
La consulta N1QL con INNER JOIN ya no funciona en CB6 tal y como está escrita.
[
{
"código": 3000,
"msg": "ANSI JOIN debe realizarse en un espacio de claves. - at where \n Error al analizar: error de ejecución: dirección de memoria no válida o desviación de puntero nulo - at where",
"query_from_user": "SELECT uhl.id FROM test uhl \r\nINNER JOIN (SELECT e.id,sum(a.
valor)\r\nFROM test a\r\n WHERE a.type='sales_order' ) e ON a.owner = e.id\r\nwhere uhl.type ='_employee_hier_level'\r\n AND uhl.parent='101'\r\nGROUP BY e.id"}
]
También la palabra clave
valornecesita sercitadoo error de sintaxis. Algo comoSELECT e.id,suma(a.
valor), (SELECT uhl.id FROM test uhl WHERE uhl.type ='_employee_hier_level')AND uhl.parent='101′) e
FROM prueba a
WHERE a.type='pedido_venta' and a.owner = e.id
GROUP BY e.id
funciona pero no estoy seguro del USE HASH...
La consulta utiliza una nueva característica de N1QL 6.5 - Soporte ANSI JOIN para Término de Expresión y Término de Subconsulta. La versión beta de 6.5 está prevista para finales de mayo. Por favor, hágamelo saber si usted está interesado en una versión temprana para probar esto. También estoy buscando una manera de hacer que el conjunto de datos esté disponible.
Gracias,
-binh
Sugerir algunos datos JSON de muestra también estaría bien
Bueno, tanto Oracle ATP - como MS SQL Server ofrecen una función de jerarquía y un tipo de datos de jerarquía especial, también. ¿Podría aclarar las diferencias con CouchBase? ¿Añade ANSI SQL y/o CouchBase estas palabras clave de SQL: ¿"CONNECT BY" y "LEVEL"? TIA.
Hola CM27,
Couchbase query no soporta la palabra clave "CONNECT BY". La capacidad de atravesar relaciones está en nuestro plan. En esa misma nota, CONNECT BY es una característica específica de Oracle, mientras que Recursive CTE es el enfoque ANSI para la consulta de relaciones.
-binh