En esta serie de entradas de blog, voy a exponer las consideraciones a tener en cuenta al pasar a una base de datos de documentos cuando se tiene una experiencia relacional. En concreto, Microsoft SQL Server en comparación con Servidor Couchbase.
En tres partes, voy a cubrir:
- Modelado de datos (esta entrada del blog)
- Los propios datos
- Aplicaciones que utilizan los datos
El objetivo es establecer algunas directrices generales que pueda aplicar a la planificación y el diseño de su aplicación.
Si quieres seguirme, he creado una aplicación que demuestra Couchbase y SQL Server lado a lado. Obtenga el código fuente en GitHuby asegúrese de descargar una versión preliminar para desarrolladores de Couchbase Server.
¿Por qué iba a hacerlo?
Antes de empezar, quiero dedicar un poco de tiempo a la motivación. Hay 3 razones principales por las que uno podría considerar el uso de un almacén de datos de documentos en lugar de (o además de) una base de datos relacional. Tu motivación puede ser una o las tres:
- Velocidad: Couchbase Server utiliza un arquitectura memory-first que puede proporcionar un gran aumento de velocidad en comparación con las bases de datos relacionales.
- Escalabilidad: Couchbase Server es un base de datos distribuidaque le permite ampliar (y reducir) la capacidad simplemente acumulando hardware básico. Las funciones integradas de Couchbase, como la autodistribución, la replicación y el equilibrio de carga, hacen que el escalado sea mucho más fácil y fluido que el de las bases de datos relacionales.
- Flexibilidad: Algunos datos encajan perfectamente en un modelo relacional, pero otros pueden beneficiarse de la flexibilidad del uso de JSON. A diferencia de SQL Server, el mantenimiento del esquema ya no es un problema. Con JSON: el esquema se dobla según tus necesidades.
Por estas y otras razones, Gannett cambia SQL Server por Couchbase Server. Si lo está considerando, definitivamente consulte la presentación completa de Gannett.
[youtube https://www.youtube.com/watch?v=mor2p0UqZ14&w=560&h=315]
Cabe señalar que las bases de datos documentales y las bases de datos relacionales pueden ser complementarias. Tu aplicación puede ser mejor servida por una, la otra, o una combinación de ambas. En muchos casos, simplemente no es posible eliminar completamente las bases de datos relacionales de tu diseño, pero una base de datos de documentos como Couchbase Server todavía puede aportar los beneficios anteriores a tu software. El resto de esta serie de blogs asumirá que tienes experiencia con SQL Server y que estás reemplazando, complementando o empezando un nuevo proyecto usando Couchbase.
La facilidad o dificultad de la transición de una aplicación existente varía mucho en función de una serie de factores. En algunos casos puede ser extremadamente fácil; en otros llevará mucho tiempo y será difícil; en algunos casos (cada vez menos) puede que ni siquiera sea una buena idea.
Comprender las diferencias
El primer paso consiste en comprender cómo se modelan los datos en una base de datos documental. En una base de datos relacional, los datos suelen almacenarse en una tabla y se estructuran con claves primarias y externas. Como ejemplo sencillo, consideremos una base de datos relacional para un sitio web que tiene un carrito de la compra, así como características de medios sociales. (En este ejemplo, esas funciones no están relacionadas para simplificar las cosas).
En una base de datos de documentos, los datos se almacenan como claves y valores. Un bucket de Couchbase contiene documentos; cada documento tiene una clave única y un valor JSON. No hay claves externas (o, más exactamente, no hay restricciones de clave externa).
He aquí una comparación de alto nivel de las características/nomenclatura de SQL Server en comparación con Couchbase:
| Servidor SQL | Servidor Couchbase |
|---|---|
|
Servidor |
Grupo |
|
Base de datos |
Cubo |
|
Fila(s) de tabla(s) |
Documento |
|
Columna |
Clave/valor JSON |
|
Clave principal |
Clave del documento |
Estas comparaciones son un punto de partida metafórico. Mirando esa tabla, puede ser tentador adoptar un enfoque simplista. "Tengo 5 tablas, por lo tanto me limitaré a crear 5 tipos diferentes de documentos, con un documento por fila". Esto equivale a traducir literalmente una lengua escrita. Este enfoque puede funcionar a veces, pero no tiene en cuenta toda la potencia de una base de datos de documentos que utiliza JSON. Al igual que una traducción literal de una lengua escrita no tiene en cuenta el contexto cultural, los modismos y el contexto histórico.
Debido a la flexibilidad de JSON, los datos de una base de datos de documentos se pueden estructurar más como un objeto de dominio en su aplicación. Por lo tanto, no tienes un desajuste de impedancia que a menudo se aborda con herramientas OR/M como Entity Framework y NHibernate.
Hay dos enfoques principales que puedes utilizar al modelar datos en Couchbase que examinaremos más adelante:
- Desnormalización - En lugar de dividir los datos entre tablas utilizando claves externas, agrupe los conceptos en un único documento.
- Referencial - Los conceptos tienen sus propios documentos, pero hacen referencia a otros documentos utilizando la clave de documento.
Ejemplo de desnormalización
Consideremos la entidad "carrito de la compra".
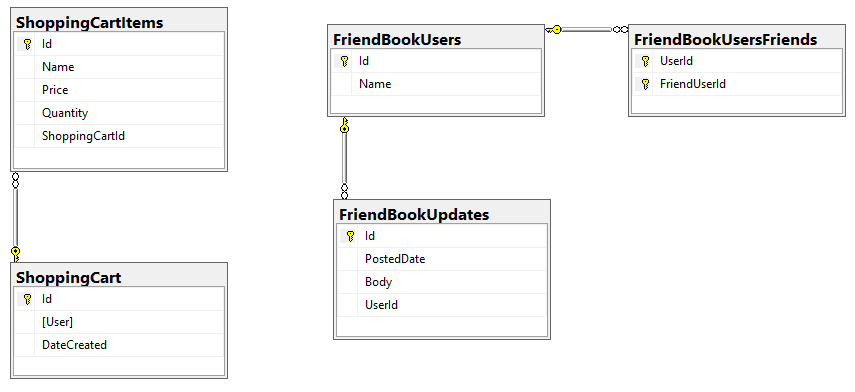
Para representar esto en una base de datos relacional probablemente se necesitarían dos tablas: una tabla ShoppingCart y una tabla ShoppingCartItem con una clave externa a una fila en ShoppingCart.
Al crear el modelo para una base de datos de documentos, hay que decidir si se sigue modelando como dos entidades separadas (por ejemplo, un documento ShoppingCart y los correspondientes documentos ShoppingCartItem) o si se "desnormaliza" y se combinan una fila de ShoppingCart y fila(s) de ShoppingCartItem en un único documento para representar un carrito de la compra.
En Couchbase, utilizando una estrategia de desnormalización, un carrito de la compra y los artículos que contiene estarían representados por un único documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "usuario": "mgroves", "fechaCreado": "2017-02-02T15:28:11.0208157-05:00", "artículos": [ { "nombre": "BB-8 Sphero", "precio": 80.18, "cantidad": 1 }, { "nombre": "Shopkins Temporada 5", "precio": 59.99, "cantidad": 2 } ], "tipo": "Carro de la compra" } |
Observe que la relación entre los artículos y el carro de la compra está ahora implícita al estar contenidos en el mismo documento. Ya no es necesario un ID en los artículos para representar una relación.
En C#, es probable que defina Carrito de la compra y Artículo para modelar estos datos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
público clase Carrito de la compra { público Guía Id { consiga; configure; } público cadena Usuario { consiga; configure; } público FechaHora FechaCreación { consiga; configure; } público Lista Artículos { consiga; configure; } } público clase Artículo { público Guía Id { consiga; configure; } // necesario para SQL Server, no para Couchbase público cadena Nombre { consiga; configure; } público decimal Precio { consiga; configure; } público int Cantidad { consiga; configure; } } |
Estas clases seguirían teniendo sentido con Couchbase, así que puedes reutilizarlas o diseñarlas de esta forma. Pero con una base de datos relacional, este diseño no coincide de forma directa.
De ahí la necesidad de OR/Ms como NHibernate o Entity Framework. La forma en que el modelo anterior se puede asignar a una base de datos relacional se representa en Entity Framework* de la siguiente manera:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
público clase ShoppingCartMap : EntityTypeConfiguration { público ShoppingCartMap() { este.HasKey(m => m.Id); este.ToTable("Carro de la compra"); este.Propiedad(m => m.Usuario); este.Propiedad(m => m.FechaCreación); este.HasMany(m => m.Artículos) .Conopcional() .HasForeignKey(m => m.ShoppingCartId); } } público clase ShoppingCartItemMap : EntityTypeConfiguration { público ShoppingCartItemMap() { este.HasKey(m => m.Id); este.ToTable("ShoppingCartItems"); este.Propiedad(m => m.Nombre); este.Propiedad(m => m.Precio); este.Propiedad(m => m.Cantidad); } } |
*Otros OR/M tendrán asignaciones similares
Basándome en estos mapeos y en un análisis de los casos de uso, pude decidir que se modelaría como un único documento en Couchbase. ShoppingCartItemMap sólo existe para que el OR/M sepa cómo rellenar el Artículos propiedad en Carrito de la compra. Además, es poco probable que la aplicación haga lecturas del carrito de la compra sin también necesidad de leer los artículos.
En un post posterior se hablará más de las OR/M, pero por ahora puedo decir que las ShoppingCartMap y ShoppingCartItemMap no son necesarias cuando se utiliza Couchbase, y las clases Id campo de Artículo no es necesario. De hecho, el SDK .NET de Couchbase puede rellenar directamente un Carrito de la compra sin OR/M en una sola línea de código:
|
1 2 3 4 |
público Carrito de la compra GetCartById(Guía id) { devolver _bucket.Visite(id.ToString()).Valor; } |
Esto no quiere decir que usar Couchbase siempre resulte en un código más corto y fácil de leer. Pero para ciertos casos de uso, definitivamente puede tener un impacto.
Ejemplo referencial
No siempre es posible u óptimo desnormalizar relaciones como la Carrito de la compra ejemplo. En muchos casos, un documento necesitará hacer referencia a otro documento. Dependiendo de cómo su aplicación espera hacer lecturas y escrituras, es posible que desee mantener su modelo en documentos separados mediante el uso de referencias.
Veamos un ejemplo en el que referenciar podría ser el mejor enfoque. Supongamos que tu aplicación tiene algunos elementos de redes sociales. Los usuarios pueden tener amigos, y los usuarios pueden publicar actualizaciones de texto.
Una forma de modelar esto:
- Usuarios como documentos individuales
- Actualizaciones como documentos individuales que hacen referencia a un usuario
- Friends como matriz de claves dentro de un documento de usuario
Con dos usuarios, dos actualizaciones, tendríamos 4 documentos en Couchbase con este aspecto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
[ // Clave: "7fc5503f-2092-4bac-8c33-65ef5b388f4b" { "amigos": [ "c5f05561-9fbf-4ab0-b68f-e392267c0703" ], "nombre": "Matt Groves", "tipo": "Usuario" }, // Clave: "c5f05561-9fbf-4ab0-b68f-e392267c0703" { "amigos": [ ], "nombre": "Nic Raboy", "tipo": "Usuario" }, // Clave: "5262cf62-eb10-4fdd-87ca-716321405663" { "cuerpo": "Nostrum eligendi aspernatur enim repellat culpa"., "postedDate": "2017-02-02T16:19:45.2792288-05:00", "tipo": "Actualizar", "usuario": "7fc5503f-2092-4bac-8c33-65ef5b388f4b" }, // Clave: "8d710b83-a830-4267-991e-4654671eb14f" { "cuerpo": "Autem occaecati quam vel. In aspernatur dolorum"., "postedDate": "2017-02-02T16:19:48.7812386-05:00", "tipo": "Actualizar", "usuario": "c5f05561-9fbf-4ab0-b68f-e392267c0703" } ] |
Decidí modelar los "amigos" como una relación unidireccional (como Twitter) para este ejemplo, por lo que Matt Groves tiene a Nic Raboy como amigo, pero no viceversa. (No le des demasiada importancia, Nic :).
La forma de modelar esto en C# podría ser:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
público clase FriendbookUsuario { público Guía Id { consiga; configure; } público cadena Nombre { consiga; configure; } público virtual Lista Amigos { consiga; configure; } } público clase Actualización { público Guía Id { consiga; configure; } público FechaHora Fecha de publicación { consiga; configure; } público cadena Cuerpo { consiga; configure; } público virtual FriendbookUsuario Usuario { consiga; configure; } público Guía UserId { consiga; configure; } } |
En Actualización a FriendbookUsuario puede modelarse como una Guía o como otro FriendbookUsuario objeto. Se trata de un detalle de implementación. Usted puede preferir uno, el otro, o ambos, dependiendo de sus necesidades de aplicación y / o cómo su OR / M funciona. En cualquier caso, el modelo subyacente es el mismo.
Aquí está el mapeo que utilicé para estas clases en Entity Framework. Su kilometraje puede variar, dependiendo de cómo utilice EF u otras herramientas OR/M. Concéntrate en el modelo subyacente y no en los detalles de la herramienta de mapeo OR/M.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
público clase ActualizarMapa : EntityTypeConfiguration { público ActualizarMapa() { este.HasKey(m => m.Id); este.ToTable("FriendBookUpdates"); este.Propiedad(m => m.Cuerpo); este.Propiedad(m => m.Fecha de publicación); este.HasRequired(m => m.Usuario) .ConMuchos() .HasForeignKey(m => m.UserId); } } público clase FriendbookUserMap : EntityTypeConfiguration { público FriendbookUserMap() { este.HasKey(m => m.Id); este.ToTable("FriendBookUsers"); este.Propiedad(m => m.Nombre); este.HasMany(t => t.Amigos) .ConMuchos() .Mapa(m => { m.MapLeftKey("UserId"); m.MapRightKey("FriendUserId"); m.ToTable("FriendBookUsersFriends"); }); } } |
Si, en lugar de almacenar estas entidades como documentos separados, aplicáramos la misma desnormalización que en el ejemplo de la cesta de la compra e intentáramos almacenar un usuario y las actualizaciones en un solo documento, acabaríamos teniendo algunos problemas.
- Duplicación de amigosCada usuario almacenaría los datos de sus amigos. Esto no es sostenible, porque ahora la información de un usuario estaría almacenada en múltiples lugares en lugar de tener una única fuente de verdad (a diferencia del carrito de la compra, donde tener el mismo artículo en más de un carrito probablemente no tiene ningún sentido de dominio). Esto podría estar bien cuando se utiliza Couchbase como una caché, pero no como un almacén de datos primario.
- Tamaño de las actualizaciones: Durante un periodo de uso regular, un usuario individual podría publicar cientos o miles de actualizaciones. Esto podría dar lugar a un documento muy grande que podría ralentizar las operaciones de E/S. Esto se puede mitigar con la herramienta de Couchbase subdocumento APIpero ten en cuenta que Couchbase tiene un límite de 20 MB por documento.
Nota: Aquí también hay un problema de N+1 (amigos de amigos, etc.), pero no voy a dedicar tiempo a resolverlo. Es un problema que no es exclusivo de ninguna de las dos bases de datos.
Además, puede que cuando la aplicación lea o escriba un usuario no necesite leer o escribir amigos y actualizaciones. Y, al escribir una actualización, no es probable que la aplicación necesite actualizar un usuario. Dado que estas entidades a menudo pueden ser leídas/escritas por sí solas, eso indica que necesitan ser modeladas como documentos separados.
Observe la matriz en el Amigos del documento de usuario y el valor del campo Usuario del documento de actualización. Estos valores se pueden utilizar para recuperar los documentos asociados. Más adelante en este post, voy a discutir cómo hacerlo con operaciones clave/valor y cómo hacerlo con N1QL.
En resumen, hay dos formas de modelar datos en una base de datos de documentos. En el ejemplo de la cesta de la compra se utilizó objetos anidadosmientras que el ejemplo de las redes sociales documentos separados. En esos ejemplos, la elección era relativamente sencilla. Cuando tomes tus propias decisiones de modelado, aquí tienes una práctica hoja de trucos:
| Si... | Entonces considera... |
|---|---|
|
La relación es de 1 a 1 o de 1 a muchos |
Objetos anidados |
|
La relación es muchos-a-1 o muchos-a-muchos |
Documentos separados |
|
Los datos leídos son en su mayoría campos padre |
Documento aparte |
|
Los datos leídos son en su mayoría campos padre + hijo |
Objetos anidados |
|
Las lecturas de datos son en su mayoría parentales o niño (no ambos) |
Documentos separados |
|
Las escrituras de datos son en su mayoría de los padres y niño (ambos) |
Objetos anidados |
Operaciones clave/valor
Para obtener documento(s) en Couchbase, la forma más sencilla y rápida es pedirlos por clave. Una vez que tenga uno de los FriendbookUsuario documentos anteriores, puede ejecutar otra operación para obtener los documentos asociados. Por ejemplo, podría pedirle a Couchbase que me diera los documentos de las claves 2, 3 y 1031 (como una operación por lotes). Esto me daría los documentos de cada amigo. Luego puedo repetir eso para Actualizacionesetc.
El beneficio de esto es la velocidad: las operaciones clave/valor son muy rápidas en Couchbase, y probablemente estarás obteniendo valores directamente de la RAM.
El inconveniente es que implica al menos dos operaciones (obtener el documento FriendbookUser y, a continuación, obtener las actualizaciones). Así que esto puede implicar un poco de codificación adicional. También puede requerir que pienses más detenidamente en cómo construyes las claves de los documentos (más sobre esto más adelante).
N1QL
En Couchbase, tienes la posibilidad de escribir consultas usando N1QL, que es SQL para JSON. Esto incluye el ÚNASE A palabra clave. Esto me permite, por ejemplo, escribir una consulta para obtener las 10 últimas actualizaciones y los usuarios que les corresponden.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
público Lista GetTenLatestUpdates() { var n1ql = @"SELECT up.body, up.postedDate, { 'id': META(u).id, u.name} AS `user`. FROM `sqltocb` up JOIN `sqltocb` u ON KEYS up.`user` WHERE up.type = 'Actualizar' ORDER BY STR_TO_MILLIS(up.postedDate) DESC LIMIT 10;"; var consulta = Solicitud de consulta.Cree(n1ql); consulta.Consistencia de escaneado(Consistencia de escaneado.SolicitarPlus); var resultado = _bucket.Consulta(consulta); devolver resultado.Filas; } |
El resultado de esta consulta sería:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[ { "cuerpo": "Autem occaecati quam vel. In aspernatur dolorum"., "postedDate": "2017-02-02T16:19:48.7812386-05:00", "usuario": { "id": "c5f05561-9fbf-4ab0-b68f-e392267c0703", "nombre": "Bob Johnson" } }, { "cuerpo": "Nostrum eligendi aspernatur enim repellat culpa eligendi maiores et"., "postedDate": "2017-02-02T16:19:45.2792288-05:00", "usuario": { "id": "7fc5503f-2092-4bac-8c33-65ef5b388f4b", "nombre": "Steve Oberbrunner" } }, // ... etc ... ] |
N1QL le permite tener una gran flexibilidad en la recuperación de datos. No tengo que estar restringido al uso de claves. También es fácil de aprender, ya que es un superconjunto de SQL con el que los usuarios de SQL Server se sentirán cómodos rápidamente. Sin embargo, la contrapartida es que la indexación es importante. Incluso más que la indexación de SQL Server. Si escribiera una consulta en la base de datos Nombre por ejemplo, debería tener un índice como
|
1 |
CREAR ÍNDICE IX_Nombre EN `Medios sociales` (Nombre) USO DE GSI; |
De lo contrario, la consulta no se ejecutará (si no tiene indexación) o no tendrá rendimiento (si sólo tiene un índice primario creado).
Hay pros y contras en la decisión de utilizar o no la referenciación. Los valores en amigos y usuario son similares a las claves foráneas, en el sentido de que hacen referencia a otro documento. Pero no hay imposición de valores por parte de Couchbase. La gestión de estas claves debe ser manejada adecuadamente por la aplicación. Además, mientras Couchbase provee transacciones ACID para operaciones de un solo documento, no hay transacciones ACID multi-documento disponibles.
Hay formas de abordar estas advertencias en la capa de aplicación que se tratarán con más detalle en posteriores entradas de esta serie, así que permanezca atento.
Diseño clave y diferenciación de documentos
En las bases de datos relacionales, las filas de datos (normalmente, no siempre) corresponden a una clave primaria, que suele ser un número entero o un Guid, y a veces una clave compuesta. Estas claves no tienen necesariamente ningún significado: sólo sirven para identificar una fila dentro de una tabla. Por ejemplo, dos filas de datos en dos tablas diferentes pueden tener la misma clave (un valor entero de 123, por ejemplo), pero eso no significa necesariamente que los datos estén relacionados. Esto se debe a que el esquema aplicado por las bases de datos relacionales a menudo transmite un significado por sí mismo (por ejemplo, el nombre de una tabla).
En bases de datos de documentos como Couchbase, no hay nada equivalente a una tabla, per se. Cada documento en un bucket debe tener una clave única. Pero un bucket puede tener una variedad de documentos en él. Por lo tanto, a menudo es conveniente encontrar una manera de diferenciar los documentos dentro de un cubo.
Claves significativas
Por ejemplo, es perfectamente posible tener un FriendbookUsuario con una clave de 123y un Actualización con una clave de 456. Sin embargo, sería conveniente añadir más información semántica a la clave. En lugar de 123utilice una clave de AmigoUsuario::123. Entre las ventajas de incluir información semántica en su clave figuran las siguientes:
- Legibilidad: De un vistazo se puede saber para qué sirve un documento.
- Referenciabilidad: Si tiene un
AmigoUsuario::123documento, entonces podría tener otro documento con una claveFriendbookUser::123::Actualizacionesque tiene una asociación implícita.
Si piensas utilizar N1QL, puede que no necesites que las claves tengan tanto significado semántico. En términos de rendimiento, cuanto más corta es la clave, más de ellas pueden almacenarse en RAM. Así que sólo utilice este patrón si planea hacer un uso intensivo de operaciones clave/valor en lugar de consultas N1QL.
Campos discriminadores
Cuando se utiliza N1QL, otra táctica que se puede utilizar además o en lugar de claves significativas es añadir campo(s) a un documento que se utilizan para diferenciar el documento. Esto suele implementarse como tipo dentro de un documento.
|
1 2 3 4 5 6 |
{ "dirección" : "1800 Brown Rd", "ciudad" : "Groveport", "estado" : "OH", "tipo" : "dirección" } |
No hay nada mágico en el tipo campo. No es una palabra reservada dentro de un documento y no es tratada especialmente por Couchbase Server. Podría llamarse tipo de documento, elTipoetc. Pero puede ser útil dentro de su aplicación cuando se utiliza N1QL para consultar documentos de un determinado tipo.
|
1 2 3 |
SELECCIONE d.* DESDE `por defecto` d DONDE d.tipo = dirección |
Incluso puedes ir un paso más allá y añadir un objeto incrustado a tus documentos para que actúe como una especie de "metadatos" de imitación:
|
1 2 3 4 5 6 7 8 9 10 |
{ "dirección" : "1800 Brown Rd", "ciudad" : "Groveport", "estado" : "OH", "documentInfo" : { "tipo" : "dirección", "lastUpdated" : "1/29/2017 1:31:10 PM", "lastUpdatedBy" : "mgroves" } } |
Esto puede ser excesivo para algunas aplicaciones. Es similar a un patrón que he visto en bases de datos relacionales: una tabla "raíz" para simular la herencia dentro de una base de datos relacional, o quizás los mismos campos añadidos a cada tabla.
Conclusión de la 1ª parte
En esta entrada del blog se trató el modelado de datos mediante desnormalización, el modelado de datos mediante referenciación, el diseño de claves y la discriminación de campos. El modelado de datos en una base de datos de documentos es un proceso de pensamiento, algo así como una forma de arte, y no un proceso mecánico. No existe una receta sobre cómo modelar los datos en una base de datos de documentos: depende en gran medida de cómo interactúe la aplicación con los datos.
Puede obtener el código fuente de toda la serie de blogs en GitHub ahorapartes del cual se presentaron en esta entrada del blog. Si tienes preguntas sobre diversas partes de ese código, no dudes en dejar un comentario a continuación o abrir una incidencia en GitHub.
Permanezca atento al próximo blog de la serie, en el que se hablará de datos y migración de datos.
Si tiene alguna pregunta, deje un comentario a continuación, póngase en contacto conmigo en Twittero utilice el botón Foros de Couchbase.
[...] Modelización de datos [...]
[...] volviendo a la primera entrada del blog sobre modelado de datos, la necesidad de transacciones multidocumento suele reducirse o eliminarse, en comparación con un modelo relacional [...]
[...] de SQL Server a Couchbase - Parte 1 (modelado de datos), Parte 2 (migración de datos), Parte 3 [...]
[...] al modelado de datos JSON es algo que toqué en la primera parte de mi serie "Pasar de SQL Server a Couchbase". Desde esa entrada de blog, me han llamado la atención algunas herramientas nuevas de Hackolade, que [...]