Prolog
En artículo anterior proporcionaba detalles sobre cómo migrar un conjunto de datos MongoDB a Couchbase Server. Este artículo muestra cómo usar el SDK de Couchbase para acceder a los datos a través de una aplicación de consola Java. Los fragmentos de código muestran cómo conectarse al clúster de Couchbase, realizar operaciones clave/valor y ejecutar búsquedas secundarias mediante consultas N1QL junto con el código correspondiente para hacer lo mismo con el SDK Java de Mongo.
Todo el código de este blog está disponible en el siguiente repositorio Git: mongodb-to-couchbase.
Requisitos previos
Un clúster Couchbase que contenga el conjunto de datos según los detalles del artículo anterior.
Crear un usuario de aplicación
Antes de que un cliente (aplicación) pueda conectarse al cluster del Servidor Couchbase es necesario definir un usuario de aplicación que se utiliza para la autenticación por parte del cliente. Couchbase Control de acceso basado en funciones le permite definir usuarios y asignarles las funciones adecuadas. Utilice la consola web para crear un usuario de aplicación denominado mflix_client como sigue.
Ir a la Seguridad en la consola web y haga clic en AÑADIR USUARIO:
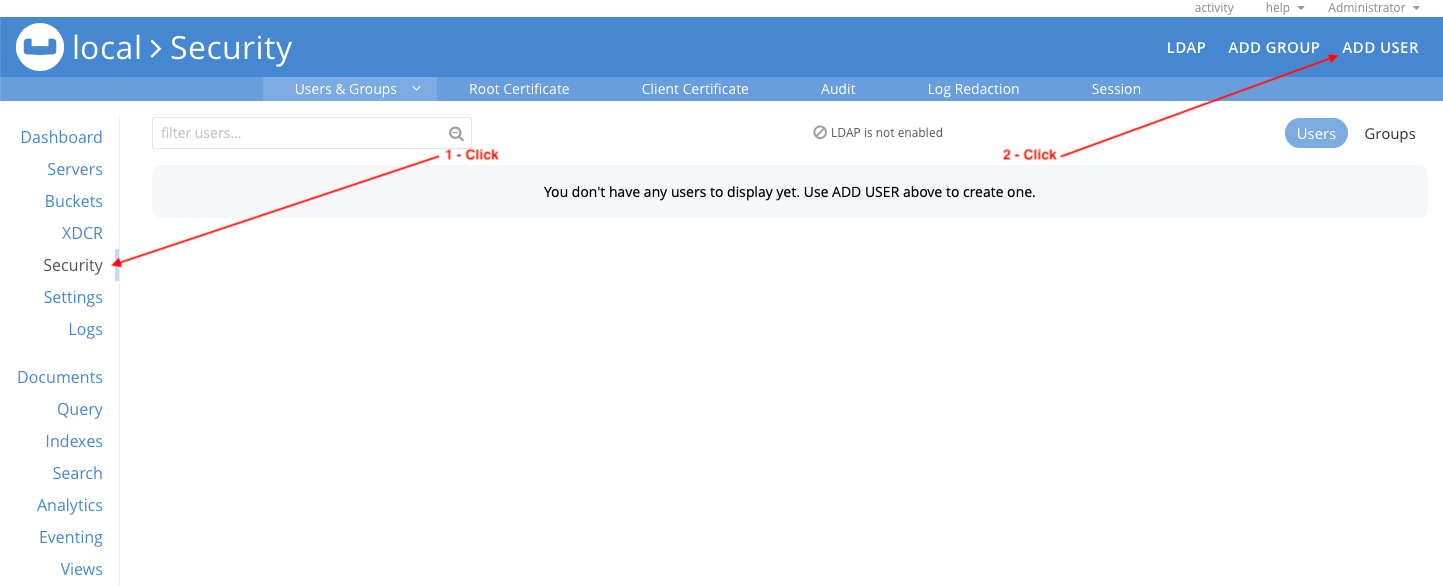
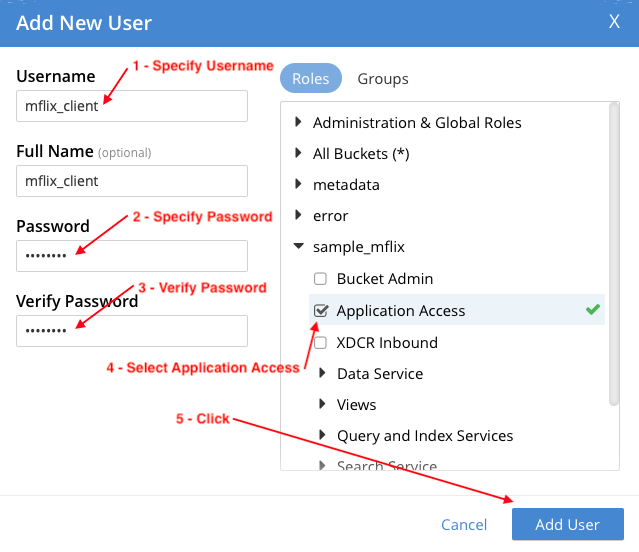
Configure el mflix_client usuario de la siguiente manera y haga clic en Añadir usuario:
- Nombre de usuario: mflix_client
- Contraseña: contraseña (o cualquier contraseña de su elección).
- Verificar contraseñaigual que Contraseña valor de arriba.
- Funciones: Ampliar la sample_mflix y seleccione Acceso a la aplicación. Los usuarios con el Función de acceso a aplicaciones tienen acceso completo de lectura y escritura a todos los datos del bucket sample_mflix. El rol no permite el acceso a la Consola Web de Couchbase: está pensado para aplicaciones, más que para usuarios.
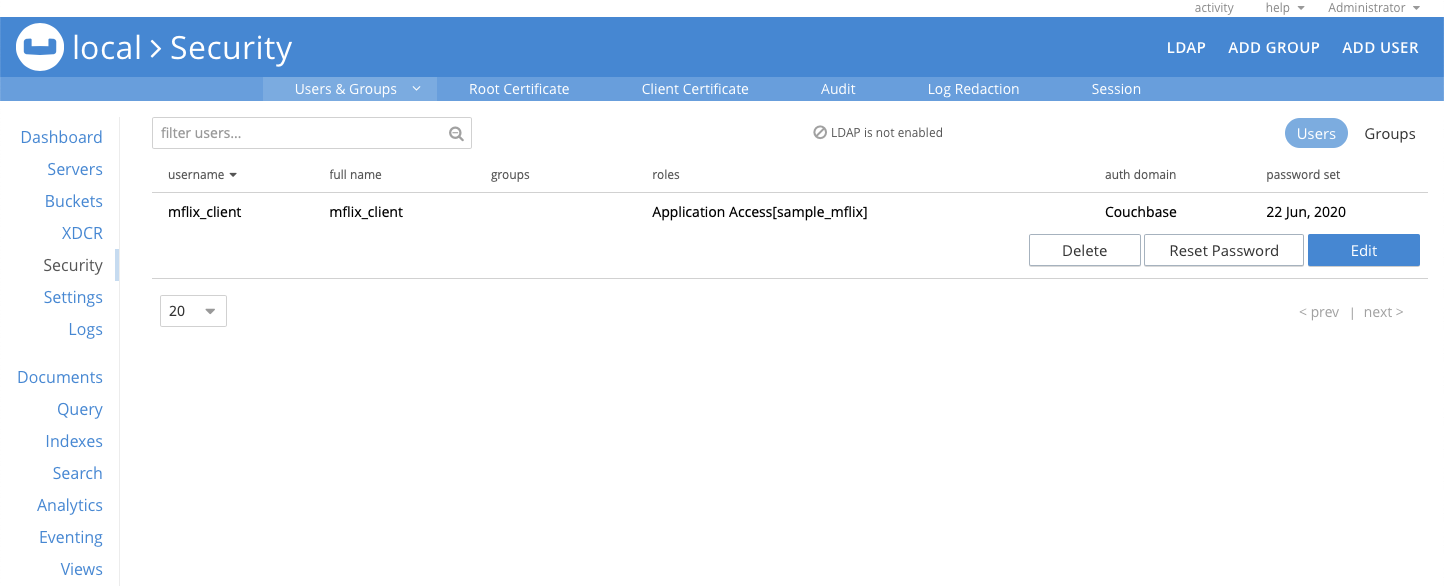
En el Seguridad verás el nuevo usuario mflix_client:
Creación de índices para consultas N1QL
Índices secundarios en Couchbase Server soportan la ejecución eficiente de consultas (o búsquedas secundarias) al igual que los índices en MongoDB. Los ejemplos de código en este artículo ejecutan Consultas N1QL que utilizan dos índices que crearás ejecutando consultas N1QL. Vaya a la página Consulta en la consola web:
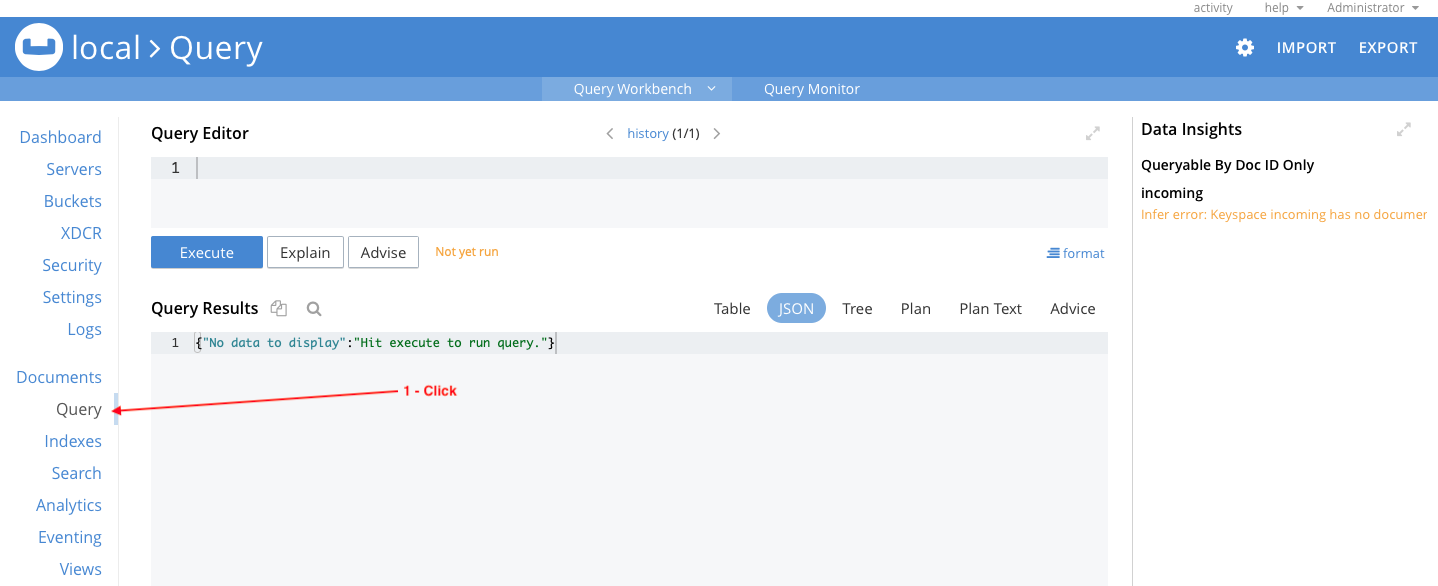
El primer índice está en el atributo name de todos los documentos de comentarios del bucket sample_mflix. Introduzca la siguiente sentencia N1QL en el archivo Editor de consultas:
|
1 |
CREATE INDEX idx1 on sample_mflix(name) WHERE type="comment" |
Haga clic en Ejecute y después de unos momentos el creación de índices está completo:
El segundo índice se basa en los atributos year, imdb.rating y title de todos los documentos de películas del bucket sample_mflix. Introduzca la siguiente sentencia N1QL en el archivo Editor de consultas:
|
1 |
CREATE INDEX idx2 on sample_mflix(year, imdb.rating, title) WHERE type="movie" |
Haga clic en Ejecute y al cabo de unos instantes se habrá completado la creación del índice:
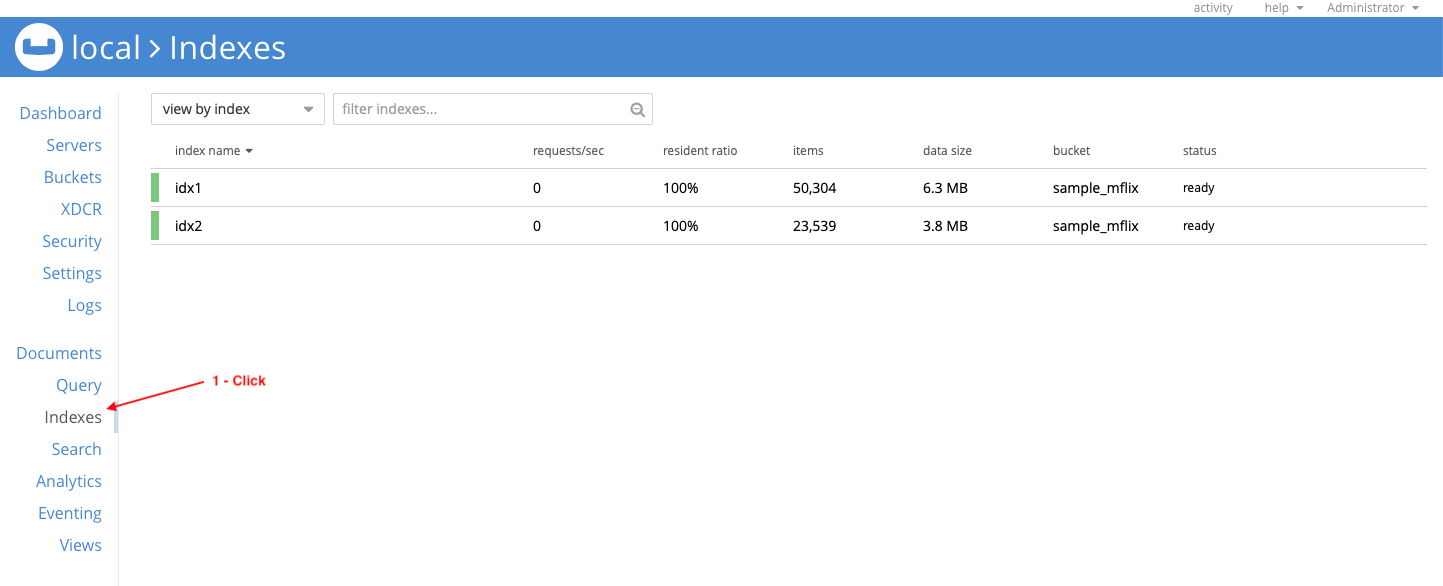
Ir a la Índices en la consola web para verificar que los índices idx1 & idx2 existe:
Convertir llamadas API de MongoDB en llamadas API de Couchbase
El código de ejemplo de este artículo utiliza los SDK Java de Couchbase y MongoDB y se proporciona sólo como ejemplo de cómo utilizar algunas de las API del SDK. Consulta los siguientes enlaces para obtener la documentación completa del SDK de Couchbase para tu idioma:
Conectarse a Couchbase Server
Para acceder a los recursos del clúster, los clientes deben autentifique pasando las credenciales apropiadas a Couchbase Server. El código de ejemplo utiliza las credenciales de usuario de la aplicación mflix_client creadas anteriormente para autenticar.
El siguiente ejemplo de código se conecta al cluster de Couchbase que se ejecuta en el nodo especificado, obtiene una referencia al bucket mflix_client, y una referencia a la colección por defecto en ese bucket.
Couchbase
|
1 2 3 |
Cluster cluster = Cluster.connect("127.0.0.1", "mflix_client", "password"); Bucket bucket = cluster.bucket("sample_mflix"); Collection collection = bucket.defaultCollection(); |
MongoDB
|
1 2 3 4 |
MongoClient mongoClient = MongoClients.create("mongodb+srv://<user>:<password>@<host>/<database> "); MongoDatabase mongoDatabase = mongoClient.getDatabase("sample_mflix"); MongoCollection<Document> comments = mongoDatabase.getCollection("comments"); MongoCollection<Document> movies = mongoDatabase.getCollection("movies"); |
Recuperar un documento por ID
Utiliza el Colección.get() para recuperar documentos completos por ID. El siguiente ejemplo de código recupera dos documentos de la colección predeterminada del bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 |
// get() will throw an exception if a document with the specified ID does not exist GetResult comment = collection.get("comment:5a9427648b0beebeb69579cc"); System.out.println(comment.contentAsObject()); GetResult movie = collection.get("movie:573a1390f29313caabcd4135"); System.out.println(movie.contentAsObject()); |
MongoDB
|
1 2 |
comments.find(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579cc"))); movies.find(Filters.eq("_id", new ObjectId("573a1390f29313caabcd4135"))); |
Insertar un nuevo documento
Utiliza el Colección.insertar() para crear un nuevo documento con el ID y el contenido especificados si aún no existe. El siguiente ejemplo de código inserta este documento en la colección predeterminada del bucket sample_mflix:
|
1 2 3 4 5 6 7 |
{ "name":"Anat Chase", "email":"anat_chase@fakegmail.com", "movie_id":"movie:573a1390f29313caabcd4135", "text":"This is Anat's review", "type":"comment" } |
Couchbase
|
1 2 3 4 5 6 7 8 9 |
JsonObject doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Anat's review") .put("type", "comment"); // insert() will throw an exception if a document with the specified ID already exists collection.insert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
Document doc = new Document("_id", new ObjectId("5a9427648b0beebeb69579c0")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Anat's review"); comments.insertOne(doc); |
Insertar varios documentos nuevos
Operaciones de dosificación le permite aprovechar mejor su red y acelerar su aplicación aumentando el rendimiento de la red y reduciendo la latencia. Las operaciones por lotes funcionan mediante pipelining a través de la red. Cuando las solicitudes se canalizan, se envían en un gran grupo al clúster. El clúster, a su vez tuberías al cliente.
El siguiente ejemplo de código utiliza este enfoque para insertar dos nuevos documentos en el bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Create two JSON documents List<Tuple2<String, JsonObject>> documents = new ArrayList<Tuple2<String, JsonObject>>(); doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd42e8") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c1", doc)); JsonObject doc2 = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4323") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c2", doc2)); // Insert the 2 documents in one batch, waiting until the last one is done. // insert() will throw an exception if a document with the specified ID already exists Flux .fromIterable(documents) .parallel().runOn(Schedulers.elastic()) .concatMap(doc3 -> reactiveCollection.insert(doc3.getT1(), doc3.getT2()) .onErrorResume(e -> Mono.error(new Exception(doc3.getT1(), e)))) .sequential().collectList().block(); |
MongoDB
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
List<Document> documents = new ArrayList<Document>(); Document doc1 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c1")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd42e8")) .append("text", "This is Anat's review"); documents.add(doc1); Document doc2 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c2")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4323")) .append("text", "This is Anat's review"); documents.add(doc2); comments.insertMany(documents); |
Actualizar un documento existente
Utiliza el Colección.reemplazar() para actualizar un documento existente con el ID especificado sólo si ya existe. Couchbase admite operaciones con subdocumentos que puede utilizarse para acceder eficazmente a piezas de documentos. Las operaciones con subdocumentos pueden ser más rápidas y eficientes en red que documento completo porque sólo transmiten por la red las secciones del documento a las que se ha accedido. Las operaciones con documentos completos y subdocumentos son atómicas, lo que permite realizar modificaciones seguras en los documentos con control de concurrencia incorporado.
El siguiente ejemplo de código utiliza operaciones de subdocumento para actualizar el atributo de texto de un documento especificado.
Couchbase
|
1 2 3 4 5 |
// Update a document using the sub-document API to modify the specific attribute(s) // replace() will throw an exception if a document with the specified ID does not exist collection.mutateIn( "comment:5a9427648b0beebeb69579c0", Arrays.asList(replace("text", "This is not Anat's review"))); |
MongoDB
|
1 2 3 |
comments.updateOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), Updates.combine(Updates.set("text", ""))); |
Actualizar varios documentos
Además del acceso primario mediante API de clave/valor, también puede ejecutar consultas N1QL a través de las API N1QL. N1QL es un lenguaje declarativo para consultar, transformar y manipular datos JSON - piensa en SQL para JSON.
El siguiente ejemplo de código ejecuta una consulta N1QL para actualizar los atributos de nombre y correo electrónico de todos los documentos de comentarios cuyo nombre sea Anat Chase. Esta consulta utiliza el atributo idx1 creado anteriormente.
Couchbase
|
1 2 3 4 5 6 |
// execute a N1QL UPDATE query via the query API String statement = "UPDATE sample_mflix " + "SET name='Anita Chase', email='anita_chase@fakegmail.com' " + "WHERE type='comment' AND name='Anat Chase'"; QueryResult updateResult = cluster.query(statement); |
MongoDB
|
1 2 3 4 5 |
comments.updateMany( Filters.eq("name", "Anat Chase"), Updates.combine( Updates.set("name", "Anita Chase"), Updates.set("email", "anita_chase@fakegmail.com"))); |
Actualizar o insertar un documento
Utiliza el Colección.upsert() para insertar el documento si no existe, o sustituirlo si existe. Si no existe un documento con el ID especificado, upsert() creará un nuevo documento. Si existe un documento con el ID especificado, upsert() actualizará el documento existente. El siguiente ejemplo de código actualiza un documento existente en el bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 7 8 9 |
doc = JsonObject.create() .put("name", "Mia Hannas") .put("email", "mia_hannas@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Mia's review") .put("type", "comment"); // upsert() will update the document if it exists or insert the document if it does not exist collection.upsert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
collection.replaceOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), new Document("name", "Mia Hannas") .append("email", "mia_hannas@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Mia's review"), new UpdateOptions().upsert(true)); |
Borrar un documento
Utiliza el Colección.eliminar() para eliminar un documento completo con el ID especificado. El siguiente ejemplo de código elimina un documento existente del bucket sample_mflix.
Couchbase
|
1 2 |
// remove() will throw an exception if the document does not exist collection.remove("comment:5a9427648b0beebeb69579c0"); |
MongoDB
|
1 |
collection.deleteOne(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0"))); |
Borrar varios documentos
También puede utilizar consultas N1QL para eliminar documentos. El siguiente ejemplo de código ejecuta una consulta N1QL para eliminar varios documentos del bucket sample_mflix. Se eliminarán todos los documentos de comentarios cuyo nombre sea Anita Chase. Esta consulta utiliza el método idx1 creado anteriormente.
Couchbase
|
1 2 3 4 5 |
// execute a N1QL DELETE query via the query API String statement = "DELETE FROM sample_mflix " + "WHERE type='comment' AND name='Anita Chase'"; QueryResult deleteResult = cluster.query(statement); |
MongoDB
|
1 |
comments.deleteMany(Filters.eq("name", "Anita Chase")); |
Acceso a datos con N1QL
N1QL también puede utilizarse para realizar búsquedas secundarias de datos más complicadas. El siguiente ejemplo de código ejecuta una consulta N1QL de bloqueo para seleccionar el título, el año y la calificación imdb de todos los documentos de películas cuyo año esté comprendido entre 1970 y 1979, ordenados por la calificación imdb. La consulta utiliza el método idx2 creado anteriormente.
Similar a operaciones reactivas clave/valor por lotes, consultas reactivas y asíncronas para un mejor rendimiento.
Couchbase
|
1 2 3 4 5 6 7 8 |
// execute a N1QL SELECT query (blocking) via the query API String selectStatement = "SELECT title, year, imdb.rating FROM sample_mflix " + "WHERE type='movie' AND year BETWEEN 1970 AND 1979 ORDER BY imdb.rating DESC"; final QueryResult selectResult = cluster.query(selectStatement); for (JsonObject row : selectResult.rowsAsObject()) { System.out.println(row.toString()); } |
MongoDB
|
1 2 3 4 5 |
movies.find(Filters.and(Filters.gte("year", 1970), Filters.lte("year", 1979))) .sort(Sorts.descending("imdb.rating")) .projection(Projections.fields( Projections.include("title", "year", "imdb.rating"), Projections.excludeId())); |
El futuro
Explore las otras capacidades del SDK de Couchbase incluyendo Analítica y Búsqueda de texto completo. Aproveche nuestra formación gratuita en línea disponible en https://learn.couchbase.com para obtener más información sobre Couchbase.
Para obtener información detallada sobre las ventajas arquitectónicas de la plataforma de datos Couchbase sobre MongoDB, consulte este documento: Couchbase: Mejor que MongoDB en todos los sentidos.
Descubra por qué otras empresas eligen Couchbase en lugar de MongoDB: