With the OpenAI’s landmark releases of DALL·E 2, and ChatGPT last year, people have been interacting with artificial intelligence and seeing first hand (a tiny bit of) its potential.
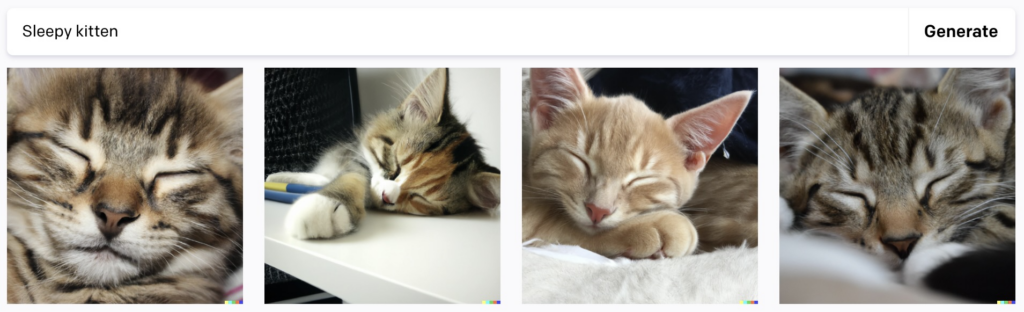
These tools can feel like magic. Each takes a textual prompt and then gives you back a response. DALL·E turns your text into an image and ChatGPT will have an entire conversation with you. For example, ask for a sleepy kitten from DALL·E and you’ll get a selection of stunning incarnations. Ask ChatGPT to write an essay about the American Revolution and you’ll get a strong thesis.
Yet, these tools (and similar ones) are absolutely not magic, and they certainly aren’t infallible. Look too closely and you’ll start to see issues. Did you ask DALL·E for something with hands or text? You’ll probably be disappointed by the “hands” and nonsensical arrangement of letters. That thesis on the American Revolution you requested? Well, it might have some factual inaccuracies or strange wording.

Note the odd hand in this ‘realistic man waving’ or the repetitive paragraphs in the American Revolution essay
The virality of these two tools has led us to grapple with the complex social and legal ramifications of the democratization of AI tools. For example, how will AI affect copyright laws? Is a picture produced by AI as valuable as one made by a human? What is the future for artist careers and the creator economy? Should you hand in that American Revolution essay to your college professor? Probably not.
Those questions are not the scope of this article, rather we will be asking: Why hasn’t Google implemented something like ChatGPT as a search product?
Can AI be trusted?
Some of the initial reactions to the release of ChatGPT were that Google is in trouble. Why search Google and click through links looking for the answer to your question, when you could ask ChatGPT? Where is Google’s response to this? Surely Google, with their significant investments in AI could have produced this already?
It probably did. In fact, it has publicly shown demos of its natural language engine called LaMDA AI where the user can talk to the planet Pluto and ask it any questions they want. Google has never publicly released this though. Why not?
In a company all hands meeting recently, Google CEO Sundar Pichai answered this question by citing the reputational risk of such a product. He noted that customers inherently trust Google’s search results and that “you can imagine for search-like applications, the factuality issues are really important and for other applications, bias and toxicity and safety issues are also paramount.”
Yes, inaccurate search results would hurt Google’s image, but the second part of that response reveals the real risk. If you phrase the question in a specific way, you can get ChatGPT to tell you some horrifically false or highly offensive things. For example, Steven Piantadosi of the University of California revealed that ChatGPT ranked the value of a human brain according to race and gender.
While Google is slowly and methodically charting its AI future, others are seizing the opportunity to disrupt the status quo. With the recent announcement of Microsoft’s intention to integrate some of its core products (Office and Bing) with OpenAI’s technology, we must look closer to understand why AI engines have the potential to be derogatory. Unfortunately, it’s not the AI’s fault. To understand why, we need to peek behind the curtain.
Inside the AI Brain
DALL·E and ChatGPT are both machine learning models. They use well researched modeling techniques to create predictive systems that take an input and return an output. DALL·E was fed billions of picture and caption pairs from the internet and learned how they relate, so that when given a new caption it can generate a matching image. ChatGPT is based on the GPT3 language model which ingested text from the internet so that when given a prompt it can predict what word should come next. This was then implemented in a conversational framework to produce ChatGPT.
The reason that models like ChatGPT can produce offensive, racist or sexist results, is because it was trained on a dataset that contained millions of examples of highly offensive content. The internet is filled with people saying unfiltered, terrible things, thus using it as the source of data to train a model will undoubtedly teach it to say those same things. Imagine teaching a baby to talk by only telling it swear words — you can imagine what the baby’s first word might be.
This explains why companies like Google fear releasing these massive complex AI models. Once all the complicated training of the model is said and done, you are left with a probabilistic black box. You cannot be sure that given a particular input, the black box won’t output something particularly obscene.
The problem is not new. It is referred to as AI bias, which occurs when an AI model reflects the inherent biases of its human author that are implied through the dataset. Garbage in, garbage out.
So how can companies that are using AI in their product suite reduce AI bias and their risk of putting a harmful, offensive, unsafe AI model into production? What can Microsoft, Google and others do to reduce the risk to their customers and brands?
Shift Right: The ChatGPT Approach
OpenAI was acutely aware of this problem well before it released ChatGPT, so much so that guardrails were built against it. The approach was simple. Don’t let ChatGPT respond to questions that might prompt inappropriate responses. ChatGPT has a list of prohibited keywords and phrases that it will either not respond to, or has been taught how to respond to specifically.
This means that in most cases, OpenAI has stopped ChatGPT from saying something bigoted. However, the fact that users can manipulate ChatGPT to say bigoted things means that the underlying AI model is suffering from AI bias and has learned the inherent harmful language from its dataset. Yes, OpenAI will continue to build more filters and strategies to avoid those inherent biases from creeping out, but the biases are still there.
This is a shift right strategy – putting a gate at the end of the process to try and stop the risk from getting through. It clearly isn’t foolproof.
Shift Left: The Reputationally Safe Approach
A more long-term strategy is to look at the beginning of the process. If you remove the bias from the dataset before the model has a chance to learn it, you have effectively nullified the possibility of building a biased AI.
While OpenAI did attempt to limit GPT3 and DALL·E’s exposure to vulgar text and images, it was not 100% effective. When looking at a dataset the size of the internet, such a solution is prohibitively expensive and complicated for a research group such as OpenAI. Forgetting the sheer scope of the internet, the nuance of racism and sexism online is very hard to identify and remove even manually.
This is not the case for all AI projects, especially when targeting a smaller use case. Most businesses are not trying to build a general-purpose AI product, and this strategy is the more scalable approach.
Let’s take the example of a fictional company “SalaryAdvise.” It is trying to build an AI model that takes a given employee’s details and suggests a fair salary. SalaryAdvise has painstakingly acquired a dataset of hundreds of thousands of people, with their personal details, work history and current salary. Here’s a theoretical example of what a single data point might look like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "uuid": "d7c0d1eb-6946-44eb-a7e4-a9487136a468", "gender": "female", "name": "Ignacia Wong", "age": 63, "blood_type": "AB-", "height": "1.54", "nationality": "Ecuadorian", "address": { "street": "1229 Caw Glen", "city": "Coralville", "postal_code": "7013", "country": "Australia" }, "professional_details": { "degree": "Graduate Certificate", "university": "University of New South Wales", "profession": "Textile Worker", "professional_experience": 41, "company": "ZAMANCO MINERALS LIMITED", "salary": "$1240318" } } |
Note: all data used throughout this example is entirely fictional and created randomly using mimesis
While this dataset is comprehensive, using it to train a model would produce a model that considers gender, age, blood type and nationality as input for calculating salary. These are protected pieces of information and in no way should those be a consideration ethically or legally. There are also some irrelevant pieces of information for determining salary such as name and height. So, to fix that, we can remove those data points:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "uuid": "d7c0d1eb-6946-44eb-a7e4-a9487136a468", "address": { "street": "1229 Caw Glen", "city": "Coralville", "postal_code": "7013", "country": "Australia" }, "professional_details": { "degree": "Graduate Certificate", "university": "University of New South Wales", "profession": "Textile Worker", "professional_experience": 41, "company": "ZAMANCO MINERALS LIMITED", "salary": "$1240318" } } |
When looking for bias in datasets, we need to also consider proxies — data points that may undermine the exclusion of protected values. The address information is useful as geographic information may inform salary, but specific population groups may live in similar areas, so using the full address (and postcode) may imply other demographic information. Therefore, we should remove it.
We are now left with a dataset that does not contain any protected values or information that may cause an AI model to be biased. SalaryAdvise should now feel comfortable to use this dataset to train the model, knowing that the AI cannot be biased and the company has protected its reputation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "uuid": "d7c0d1eb-6946-44eb-a7e4-a9487136a468", "address": { "city": "Coralville", "country": "Australia" }, "professional_details": { "degree": "Graduate Certificate", "university": "University of New South Wales", "profession": "Textile Worker", "professional_experience": 41, "company": "ZAMANCO MINERALS LIMITED", "salary": "$1240318" } } |
Automatic Bias Removal: The Couchbase Approach
As a custodian of data and in accordance with our company values, Couchbase seeks to empower users to build unbiased AI models. That’s why we have created the Couchbase Eventing service for our cloud database platform, empowering researchers to automatically remove protected information from an AI dataset.
With Eventing, you can trigger a Javascript function to run on any update to a document in your dataset (and all existing data), so whenever a new document is added, you automatically remove the protected information. The above example could be achieved with the following simple function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
function OnUpdate(doc, meta) { log('document', doc); //remove any fields that may lead to a biased model //ie remove anything that should not be a factor for salary delete doc.gender; delete doc.nationality; delete doc.name; delete doc.blood_type; delete doc.age; delete doc.address.street; delete doc.address.postal_code; log('document', doc); bias[meta.id]=doc; } |
By using Couchbase, you also get access to its memory-first architecture, giving you unparalleled performance and the ability to use SQL++ to query your dataset.
Unleash the potential of this NoSQL document database in your next AI project.
Start a free trial today.
