"Nada es seguro, salvo la muerte y los impuestos".
No se trata de un conjunto de datos hecho con un lecho de rosas o césped verde cuidado. Un poco más serio. Veamos si podemos aprender algo rápidamente aquí. El conjunto de datos es el siguiente.
"name" : "NCHS - Principales causas de muerte: Estados Unidos",
"atribución" : "Centro Nacional de Estadísticas Sanitarias",
El público dataset está disponible en https://data.cdc.gov/api/views/bi63-dtpu/rows.json?accessType=DOWNLOAD
Primer paso: Descargue el archivo en un archivo local (por ejemplo, health.json). Suba este archivo a uno de los nodos del clúster de Couchbase.
Paso 2importar los datos a un bucket llamado causa. Después de crear el bucket, crea el índice primario. Lo necesitarás para realizar consultas.
/opt/couchbase/bin/cbimport json -c couchbase://127.0.0.1 -u Administrador -p contraseña -b causa -d fichero://salud.json -g causa:0 -f muestra
> CREAR ÍNDICE PRIMARIO EN causa;
Paso 3. Inspecciona la estructura de los datos.
Todos los datos se proporcionan en un ÚNICO documento JSON. Debido a esto, INFER no ayuda. Tendrás que inspeccionar y comprender la estructura manualmente. Estos datos son los típicos conjuntos de datos gubernamentales con muchos datos en matrices simples con el significado de cada entidad en los metadatos.
Matriz simple:
|
1 |
<strong>select data from cause ;</strong> |
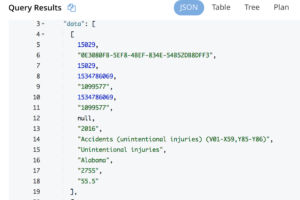
Simplemente contiene una matriz de datos sin el esquema. Para los conjuntos de datos públicos, el esquema se encuentra en el campo meta.
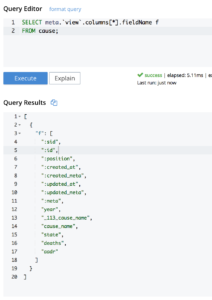
Vamos a transformar la estructura en simples pares clave-valor JSON para que podamos manejar estos bits de manera más eficaz. Usted puede aprender más acerca de cómo se produjo esta magia en este artículo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END; |
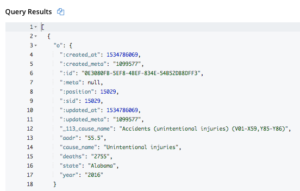
Tarea1: Averiguar la causa de la mayoría de las muertes en un estado, por año.
La expresión de tabla común (CTE) en la cláusula WITH (csdata) transforma los datos json complejos en JSON plano. Puedes hacer esto dinámicamente o hacerlo una vez e INSERTAR de nuevo en un bucket, como he comentado en el artículo sobre Nombres de bebé en Nueva York. En este artículo, utilizo CTEs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ) SELECT c.o.state, c.o.year, c.o.cause_name, COUNT(c.o.cause_name), SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" GROUP BY c.o.state, c.o.year, c.o.cause_name ORDER BY totdeaths DESC, c.o.state, c.o.year |
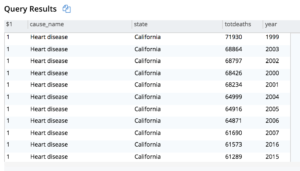
En este caso, todas las muertes de California se sitúan en cabeza, debido principalmente a su población.
Tarea 2. Averigua las principales causas de muerte en cada estado para el año 2016.
Consulta 2: Utilice el conjunto de resultados de la consulta anterior y, a continuación, utilice la función de ventana FIRST_VALUE() para determinar la causa principal. La partición por estado (en la cláusula OVER BY) le dará las particiones por estado y ORDER BY dx.totdeaths dentro de la cláusula OVER BY le dará la causa principal en cada estado.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( SELECT c.o.state, c.o.year, c.o.cause_name, SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" and c.o.year = "2016" GROUP BY c.o.state, c.o.year, c.o.cause_name), d3 as ( SELECT dx.state, dx.cause_name, dx.totdeaths, FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topreason, FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topcount FROM d2 dx) SELECT d3 FROM d3 WHERE d3.topcount = d3.totdeaths order by d3.state |
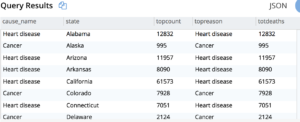
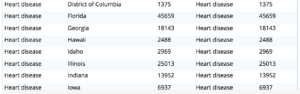
Tarea 3. Descubre cómo ha cambiado el motivo principal por año, de 1999 a 2016 por estado.
Consulta 3: Simplemente genere el informe para todos los años (199-2016) y luego determine la razón principal y finalmente obtenga la razón más alta agrupando por estado, año y obteniendo MAX(topcount) para la causa topreason.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
WITH csdata as ( WITH cs AS ( SELECT meta.`view`.columns [*].fieldName f, data FROM cause ) SELECT o FROM cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END ), d2 as( SELECT c.o.state, c.o.year, c.o.cause_name, SUM(TONUMBER(c.o.deaths)) totdeaths FROM csdata as c WHERE c.o.state <> "United States" and c.o.cause_name <> "All causes" GROUP BY c.o.state, c.o.year, c.o.cause_name), d3 as ( SELECT dx.state, dx.year, FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC ) topreason, FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC) topcount FROM d2 dx) SELECT d3.state , d3.year , d3.topreason, max(d3.topcount) topcount FROM d3 GROUP BY d3.state, d3.year, d3.topreason order by d3.state, d3.year |
Este es el resultado parcial.
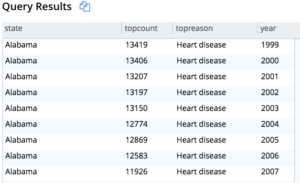
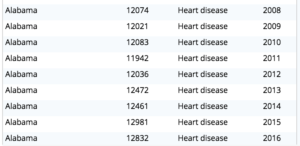
Visualizando esto obtenemos el siguiente histograma.
