Mi familia me oye hablar de Bases de datos JSON con bastante frecuencia.
Naturalmente, tuve que explicar que Jason ¡no es el propietario de mi empresa! En cambio, muchas bases de datos modernas utilizan JSON como formato de datos. Suelen abandonar la sala en este punto, cansados de complacer mi entusiasmo por la base de datos JSON de Couchbase.
¿Qué es una base de datos JSON?
A Base de datos JSON es posiblemente la categoría más popular de la familia de bases de datos NoSQL. Gestión de bases de datos NoSQL difiere de las bases de datos relacionales tradicionales, que tienen dificultades para almacenar datos fuera de columnas y filas. En cambio, se adaptan con flexibilidad a una amplia variedad de tipos de datos, a los requisitos cambiantes de las aplicaciones y a los modelos de datos. En una era en la que los límites de almacenamiento físico ya no son un cuello de botella, las bases de datos JSON ofrecen una escala y un rendimiento superiores.
Esta flexibilidad convirtió a las bases de datos JSON en la estructura de almacenamiento preeminente para los sistemas NoSQL que admiten el procesamiento multimodal o multimodelo. Su popularidad se debe principalmente a la sencillez y flexibilidad de la estructura de documentos de las bases de datos JSON.
Introducido por primera vez en 2006, JSON significa "JavaScript Object Notation" y ofrece un formato de datos menos verboso que el popular XML (eXtensible Markup Language). Hoy en día, el formato de datos JSON está impulsando sistemas empresariales en todo el mundo a pesar de sus humildes raíces en permitir la programación JavaScript y aplicaciones web sencillas. Las bases de datos JSON como Couchbase o MongoDB aprovechan la sencilla sintaxis del estándar y proporcionan estructuras de datos legibles tanto por humanos como por máquinas.
Veamos algunas de las ventajas de una base de datos que almacena datos en formato JSON. Mientras lo hacemos, considera cómo podrías aprovechar su funcionalidad en futuras aplicaciones.
Las bases de datos JSON tienen más flexibilidad de almacenamiento
NoSQL es una categoría de base de datos adaptada a casos de uso específicos que se centran en la estructura de almacenamiento, el diseño de escalado y los métodos de consulta/indexación. También se hace hincapié en la concurrencia, la alta disponibilidad y las garantías de persistencia de datos en tiempo real.
Por ejemplo, algunas bases de datos optimizan el almacenamiento de datos clave-valor para la velocidad de recuperación, con el objetivo de funcionar lo más rápido posible. Suelen ejecutarse principalmente en memoria, lo que evita la pesada carga de leer datos de discos duros giratorios.
Por supuesto, la memoria es volátil y los fallos de alimentación pueden borrar los datos almacenados en ella. Los motores de bases de datos clave-valor ofrecen un medio para escribir datos en un almacenamiento persistente con el fin de reducir la pérdida de datos. Sin embargo, los almacenes clave-valor pueden ser demasiado simplistas para algunos casos de uso.
Además, otras estructuras de datos, como las bases de datos de grafos, pueden resultar demasiado abstractas para otros casos de uso. Las estructuras de bases de datos de grafos pueden ser rápidas, ya que suelen admitir el procesamiento en memoria para acelerar la velocidad de recorrido de las relaciones. Sin embargo, para ello se requiere una arquitectura de datos construida de forma nativa con nombres de diseño extravagantes como "adyacencia sin índice". Estas estructuras asocian cada dato a un conjunto de números de identificación de relaciones almacenados físicamente en un disco.
Los modelos de datos de grafos resultaban muy útiles cuando la memoria y el espacio en disco eran escasos. Sin embargo, planteaban problemas a la hora de escalar una estructura de grafos en varios nodos de base de datos. Por ejemplo, ¿dónde se rompen lógicamente las relaciones en los datos subyacentes?
Las bases de datos NoSQL JSON manejan los documentos como objetos individuales de archivos de datos sin utilizar tablas estructuradas. El número de filas o el tamaño de la tabla no limitan el número de documentos almacenados en una base de datos JSON. En su lugar, la disponibilidad de almacenamiento es el único límite al volumen de datos. Afortunadamente, un clúster puede ampliar fácilmente el almacenamiento.
Partición de datos
Este enfoque basado en clústeres permite a la base de datos añadir más nodos para crear una plataforma de datos mayor según sea necesario. Los desarrolladores también denominan a este proceso "ampliación" del clúster. La partición de datos entre nodos permite un almacenamiento y procesamiento distribuidos en los que ningún nodo realiza todo el trabajo.
La base de datos subyacente particiona los datos para mantener este equilibrio utilizando un conjunto de servicios de almacenamiento en una arquitectura compartida-nada. El sistema equilibra y replica los datos para mantenerlos disponibles si un nodo queda inutilizable.
Tratamiento de modelos de datos
Un clúster también puede tener una mezcla de tipos de nodos -almacenamiento de datos, procesamiento y servicio de datos- utilizando diferentes modelos de acceso. Una base de datos JSON permite almacenar datos como JSON y proporcionarlos a las aplicaciones de otras formas.
Por ejemplo, las bases de datos JSON pueden funcionar como un almacén de claves y valores en memoria para aplicaciones que sólo necesitan un acceso rápido y sencillo. O bien, la indexación y la consulta pueden hacer que los datos JSON aparezcan como una tabla. Además, los desarrolladores pueden utilizar SDK de estructura de datos para servir atributos atómicos como pares clave-valor.
Las bases de datos JSON ofrecen esquemas flexibles
Las bases de datos de documentos JSON almacenan sus datos en archivos utilizando una notación específica diseñada para eliminar la rigidez de los esquemas de bases de datos relacionales. Pueden satisfacer más rápidamente los nuevos requisitos de estructura de datos derivados tras el diseño inicial del esquema de la base de datos y el lanzamiento de la aplicación.
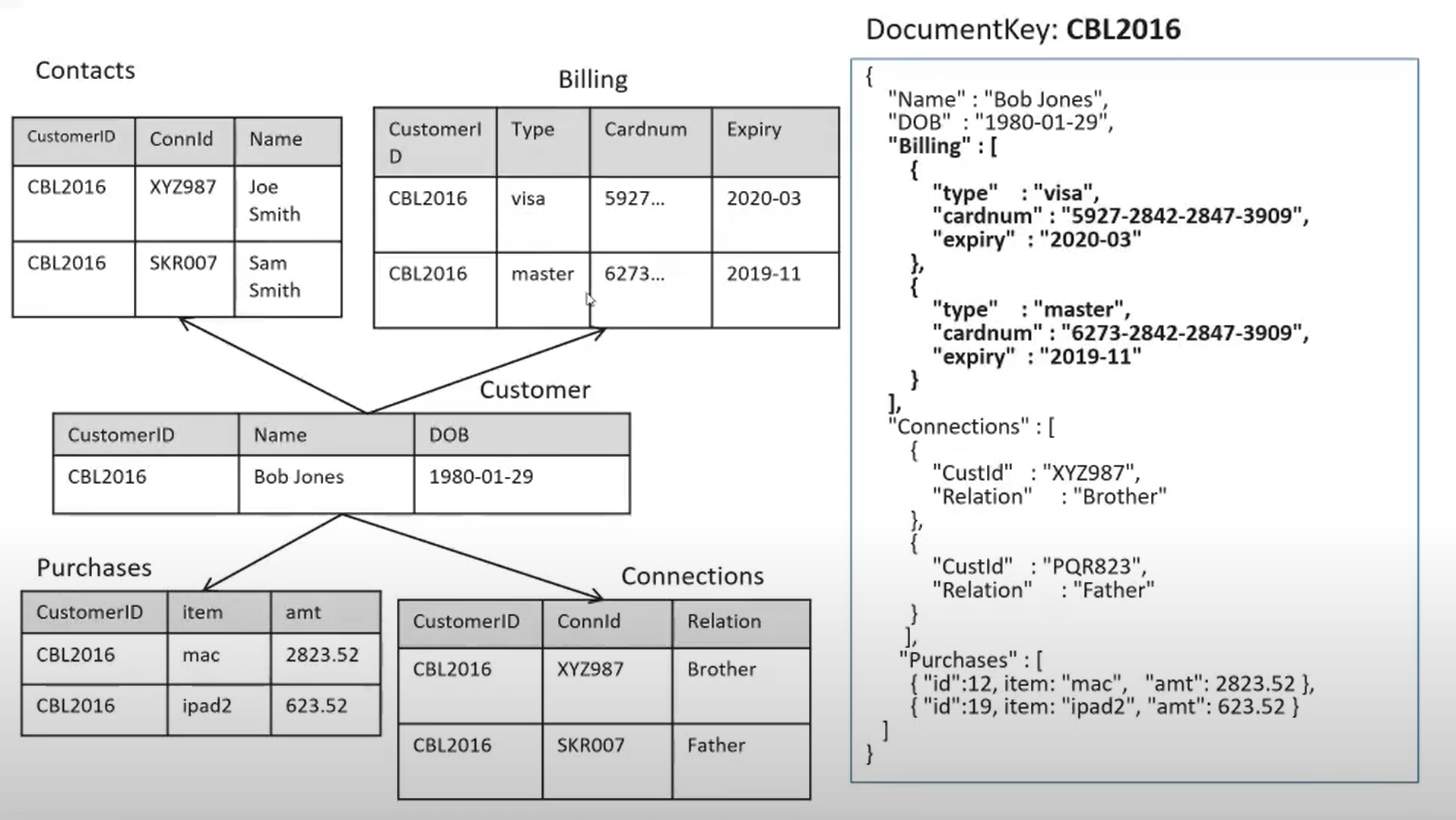
Comparación de un modelo de datos relacional de múltiples tablas con un documento JSON simplificado.
En los años 80 y 90, los ciclos de mantenimiento y entrega de aplicaciones solían durar años. Y uno de los ejercicios más lentos y temidos era introducir nuevos cambios en el esquema de la base de datos bajo una aplicación.
Ahora, los desarrolladores pueden añadir nuevos atributos a un documento, ampliando esencialmente el esquema de ese documento. Con el poder de las bases de datos JSON, los desarrolladores controlan el esquema, no el DBA.
Por ejemplo, al crear un documento que describa a una persona, el desarrollador puede añadir y modificar atributos según sea necesario. El desarrollador puede ampliar un documento que sólo almacenaba un nombre y un apellido para incluir una dirección particular. La flexibilidad de los esquemas es la razón por la que a los desarrolladores les gustan las bases de datos JSON y Encuestas a clientes de Couchbase demostrarlo.
Las bases de datos JSON tienen una ventaja moderna, ya que las infraestructuras basadas en la nube han abaratado los costes de almacenamiento físico (y de RAM en menor medida). Así que la compacidad final no es tan crítica como solía ser. Además, la organización de documentos en una base de datos JSON es mucho más intuitiva que las estructuras relacionales y de otro tipo.
Los datos JSON son fáciles de leer
Los datos de una base de datos JSON son fáciles de leer y escribir tanto para las personas como para las máquinas debido a su simplicidad.
Al igual que JavaScript, los documentos contienen conjuntos de nombres clave asociados a atributos u objetos. Utilizar espacios en blanco puede hacer que los documentos sean más legibles para los humanos.
|
1 2 3 |
<document id>: { <key>: <object>, <key>: <object>, ... } hotel_1: { "name": "Grande Hotel de Paris", "City": "Porto" } |
Existen varios tipos de datos fundamentales que se pueden mezclar y combinar: texto, numéricos, listas y mapas clave-valor. Los objetos también pueden contener otros objetos de forma jerárquica.
|
1 2 3 4 5 6 7 8 9 10 11 |
hotel_1: { "name": "Le Grande Hotel", "url": "https://www.guestreservations.com/grande-hotel-de-paris/booking", "RoomCount": 120, "Amenities": ["Pets Ok", "Pool", {"Parking": ["Valet", "Self"]}], "Address": { "Street": "Rua da Fabrica", "StreetNum": "27/29", "City": "Porto", "Country": "Portugal" } } |
Las bases de datos JSON no requieren una validación oficial del esquema. Las aplicaciones pueden utilizar/añadir/modificar los conjuntos de claves y objetos según sea necesario. Esta flexibilidad elimina la necesidad de que un DBA gestione los esquemas de las aplicaciones y acelera la "entrega continua" de microservicios.
Asignación de esquemas JSON a estructuras SQL
Aunque resaltamos la naturaleza opcional de los esquemas con la base de datos JSON, aún podemos aplicar cualquier estructura necesaria. En el contexto de una tabla relacional, los nombres de las claves del documento JSON pueden tratarse como nombres de columnas. Se vuelve un poco más complicado cuando hay objetos jerárquicos en el documento, pero las funciones pueden ayudar a aplanar los datos (más sobre esto en otra ocasión).
Al asignar los atributos JSON a nombres de columnas, se puede aplicar la sintaxis general de SQL. Las bases de datos JSON pueden automatizar esta asignación gracias a la sencilla estructura sintáctica de SQL, lo que abre un mundo de posibilidades. Los desarrolladores ya saben usar SQL y pueden utilizarlo para acelerar el desarrollo. También reduce la necesidad de que los administradores de bases de datos y los arquitectos intervengan.
Las bases de datos JSON admiten varios tipos de índices
Las bases de datos JSON también pueden generar índices de columnas que aceleran las consultas de datos SQL. Los desarrolladores identifican las columnas que utilizarán sus aplicaciones, y el sistema backend mantiene automáticamente los índices. Se puede aplicar una gran variedad de índices, incluidos índices primarios, índices secundarios globales (GSI) e incluso búsqueda de texto completo índices.
Los datos JSON son fáciles de buscar
Búsqueda de texto completo también son naturales para las bases de datos JSON y son posibles gracias a otro tipo de índice.
Los desarrolladores identifican qué atributos indexar y utilizan el SDK del lenguaje de programación para enviar una solicitud de búsqueda a la base de datos. La respuesta JSON incluye coincidencias de datos, estadísticas de coincidencias y otros metadatos que los desarrolladores utilizan para optimizar las aplicaciones cliente.
Las bases de datos JSON se cuidan solas
Ya hemos visto lo versátiles y potentes que pueden ser las bases de datos JSON. Lo más importante es recordar que el servicio de base de datos gestiona automáticamente todas las funciones configuradas de indexación, partición, replicación y acceso a datos.
Los desarrolladores de aplicaciones se benefician significativamente de esta potencia, centrándose en crear soluciones en lugar de gestionar clusters. Al añadir nuevos documentos, el sistema se da cuenta y se ajusta, actualizando los datos indexados en consecuencia sin intervención del usuario.
Los paneles de control proporcionan interfaces web para las métricas de rendimiento y ayudan a mostrar cuándo puede ser beneficioso disponer de más nodos o memoria. Los usuarios pueden añadir fácilmente nuevos nodos a un clúster, mientras que el equilibrio y la replicación de datos se realizan automáticamente entre bastidores. Una base de datos JSON puede desconectar el nodo averiado cuando se producen fallos, ajustar la distribución de datos y notificar a los administradores.
Próximos pasos
Los desarrolladores esperan que las infraestructuras de datos estén siempre ahí para sus aplicaciones. Con bases de datos JSON como Couchbasecon el que obtendrá flexibilidad y alto rendimiento desde el primer momento.
Más información sobre las bases de datos NoSQL JSON y Couchbase: