Couchbase se complace en anunciar el lanzamiento de una nueva función de series temporales como parte de Couchbase 7.2. Esta función se basa en la robusta arquitectura de base de datos distribuida de Couchbase, que está diseñada para escalar horizontalmente a medida que crecen los datos, a la vez que proporciona redundancia y alta disponibilidad integradas. Esto significa que a medida que su negocio crece y sus necesidades de datos de series temporales aumentan, Couchbase puede expandirse sin esfuerzo para satisfacer esas necesidades, por lo que es una solución ideal para empresas de todos los tamaños.
Esta nueva e innovadora técnica para gestionar datos de series temporales abre todo un nuevo mundo de posibilidades para los usuarios de Couchbase. Con la capacidad de almacenar y analizar grandes cantidades de datos de series temporales utilizando Couchbase SQL++ y SDKs. Esto permite a los usuarios aprovechar sus conocimientos e infraestructura existentes, facilitando la configuración y desbloqueando poderosas perspectivas para explorar las tendencias de los datos con facilidad.
Principales ventajas de las series temporales
Los datos de series temporales se almacenan en documentos JSON en la base de datos Couchbase Multi Model. Proporciona el mismo alto rendimiento, almacenamiento en caché avanzado para una rápida recuperación de datos y baja latencia. Couchbase Query SQL++ y el servicio Index mejoran las capacidades de recuperación de datos para permitir casos de uso de consultas analíticas complejas.
El soporte de datos de series temporales en Couchbase proporciona estas ventajas adicionales:
-
- Almacenamiento eficiente de grandes volúmenes de datos de series temporales
- Almacenamiento optimizado de la estructura de datos para puntos de datos con marca de tiempo
- Nuevas funciones avanzadas de consulta de series temporales
- Baja necesidad de almacenamiento de índices
Ejemplos de casos de uso de series temporales
Comercio financiero - Las operaciones financieras se basan en el análisis de grandes cantidades de datos en tiempo real, como las cotizaciones bursátiles, los tipos de cambio y los precios de las materias primas. El análisis de series temporales puede ayudar a los operadores a identificar tendencias y tomar decisiones de compra y venta con conocimiento de causa.
Supervisión del Internet de las cosas (IoT) - Los dispositivos IoT generan una gran cantidad de datos de series temporales, como lecturas de temperatura, consumo de energía y datos de sensores. Estos datos pueden analizarse en tiempo real para detectar anomalías y predecir fallos en los equipos antes de que se produzcan.
Mantenimiento predictivo - Muchas industrias dependen de equipos y maquinaria caros, y el tiempo de inactividad puede ser costoso. Analizando series temporales de datos procedentes de sensores y otras fuentes, las organizaciones pueden predecir cuándo es probable que fallen los equipos y programar el mantenimiento de forma proactiva para minimizar el tiempo de inactividad y maximizar la eficiencia.
Principales características de Couchbase Time Series
Puedes almacenar datos de series temporales en Couchbase, usando nuestro SDK/SQL++ para cargar, y la capacidad de consulta analítica avanzada con Índice Secundario Global para consultar/analizar los datos de la misma manera que con documentos JSON normales.
Eficacia del almacenamiento
Los conjuntos de datos de series temporales suelen ser muy extensos, y cada punto de datos consta de atributos, como la marca de tiempo, el valor o valores, la granularidad y otra información relacionada. Un almacenamiento eficiente es fundamental, ya que puede determinar la rapidez con la que se pueden consultar los datos para su análisis.
Las series temporales de Couchbase utilizan dos especificaciones para mejorar la eficiencia del almacenamiento.
El uso de matrices para los puntos de datos - Por su propia naturaleza, los datos de series temporales son una serie de puntos de datos. Estos puntos de datos comparten una estructura común, por ejemplo, el tiempo y los valores, o cualquier otro atributo que esté asociado al momento en que se recogió el punto de datos.
Utilizar una matriz para almacenar un conjunto de puntos de datos de un intervalo determinado puede reducir en gran medida el coste de almacenamiento, en comparación con tener que almacenar cada punto de datos individual como un documento independiente en la base de datos.
El uso de la posición del array - Observe también que los elementos de la matriz de puntos de datos no tienen un nombre de campo asociado, sino que se basa en la posición del elemento en la matriz. En este ejemplo, los tres elementos de la matriz son: la fecha de observación, el valor de apertura y el valor de cierre de la acción.
|
1 2 3 4 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] } |
Utilizar el tiempo EPOCH - Época en lugar de la cadena de fecha ISO para reducir el tamaño de cada punto de datos y mejorar el tiempo de procesamiento.
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart y dend denotan el */ "ts_end": 1672617599999,/* intervalo de tiempo de todos los puntos de datos en ts_data */ "teletipo": "XYZ" } |
Consulta optimizada con una nueva función _timeseries
La función Couchbase Time Series incluye un nuevo _timeseries función. Esta función tiene varias finalidades:
-
- Genera dinámicamente los objetos de las series temporales a partir del ts_datos matriz de matrices
- Transmite eficientemente los resultados cuando se utiliza con UNNEST, optimiza el tiempo de respuesta y el uso de memoria.
- Puede generar automáticamente la marca de tiempo para cada punto de datos cuando se utiliza el parámetro ts_interval
- Admite casos de uso de series temporales más avanzados para intervalos irregulares de puntos de datos de series temporales, como en lugar de un conjunto múltiple de puntos de datos por marca de tiempo.
Consulte el Documentación sobre series temporales de Couchbase para más detalles.
Almacenamiento optimizado de índices
Debido a la forma en que Couchbase almacena los datos de series temporales, con cada punto de datos almacenado como un elemento en un array dentro de un documento JSON, podemos optimizar nuestra estrategia de indexación de la base de datos. Específicamente, dado que cada documento contiene tanto la hora de inicio como la hora final de todos los puntos de datos del array, podemos crear una única definición de índice para cada documento. Esto significa que incluso para grandes conjuntos de datos de series temporales con millones de puntos de datos, podemos almacenar los datos en sólo unos pocos documentos en lugar de un documento por punto de datos.
Por ejemplo, un conjunto de datos de series temporales con 1 millón de puntos de datos puede almacenarse en sólo 1.000 documentos, suponiendo que cada ts_datos array puede almacenar hasta 1.000 elementos de datos y el tamaño del documento se mantiene por debajo del límite de documentos JSON de Couchbase de 20 MB. Esto no sólo reduce el número de documentos necesarios para almacenar los datos, sino que también conduce a tamaños de índice más pequeños, mejorando el rendimiento de la base de datos y reduciendo los requisitos de espacio en disco.
En resumen, aprovechando la capacidad de Couchbase para almacenar datos de series temporales como matrices dentro de documentos JSON, podemos optimizar nuestra estrategia de indexación para reducir significativamente el número de documentos necesarios y reducir el tamaño del índice, lo que resulta en un rendimiento de consulta más rápido y un uso más eficiente de los recursos de almacenamiento.
|
1 |
CREAR ÍNDICE ix1 EN docs(ticker, ts_end, ts_start); |
Conservación de datos
Los documentos de series temporales se almacenan como documentos JSON estándar en Couchbase. Así, durante el proceso de carga de datos se puede establecer el mismo Time-To-Live (TTL).
|
1 2 3 4 5 |
/* El documento se eliminará automáticamente en 30 días */ INSERTAR EN coll1 (CLAVE, VALOR) VALORES ("stock:XYZ:d1", {"teletipo":"XYZ",..}, {"caducidad":60*60*24*30}); |
Ejemplo de recorrido
Así que vamos a recorrer el proceso de carga de un conjunto de datos de precios de acciones reales en Couchbase utilizando el modelo de datos de series temporales definido por la función.
Como he descrito anteriormente, la función de series temporales de Couchbase requiere el documento JSON en este formato específico:
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart y dend denotan el */ "ts_end": 1672617599999,/* intervalo de tiempo de todos los puntos de datos en ts_data */ "teletipo": "XYZ" } |
Siga los pasos que se indican a continuación si necesita convertir sus propios datos de series temporales al formato anterior.
El conjunto de datos utilizado aquí es para el precio de las acciones de XYZ Inc para 2013-2015.
Datos_XYZ.csv
|
1 2 3 4 |
fecha,abra,alta,bajo,cerrar,volumen,Nombre 2013-02-08,27.285,27.595,27.24,27.295,5100734,XYZ 2013-02-11,27.64,27.95,27.365,27.61,8916290,XYZ 2013-02-12,27.45,27.605,27.395,27.545,3866508,XYZ |
Migrar datos a la estructura de datos de series temporales de Couchbase
- Cargar el archivo CSV en una colección Couchbase:
|
1 |
cbimport csv --infiera-tipos -c http://:8091 -u -p -d 'file://XYZ_data.csv' -b 'ts' --scope-collection-exp "s1.c1" -g "#UUID#" |
La importación creará un documento JSON en la colección c1 para cada punto de datos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "c1": { "Nombre": "XYZ", "cerrar": 55.99, "fecha": "2016-05-25T00:00:00.000Z", "alto": 56.69, "bajo": 55.7699, "abierto": 56.47, "volumen": 9921707 } }, { "c1": { "Nombre": "XYZ", "cerrar": 31.075, "fecha": "2013-06-11T00:00:00.000Z", "alto": 31.47, "bajo": 30.985, "abierto": 31.15, "volumen": 5540312 } }, ... |
2. Utilizar SQL++ para transformar la colección c1 en la estructura de datos de series temporales y, a continuación, insertar en la colección c3:
|
1 2 3 4 5 6 7 8 9 |
INSERTAR EN ts.s1.c3 (CLAVE _k, VALOR _v) SELECCIONE "stock:XYZ:2013" _k, {"teletipo": a.Nombre , "ts_start" : MIN(STR_TO_MILLIS(a.fecha)), "ts_end" : MAX(STR_TO_MILLIS(a.fecha)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.fecha), a.cerrar]) } _v DESDE ts.s1.c1 a DONDE a.fecha ENTRE "2013-01-01" Y "2013-12-31" GRUPO POR a.Nombre; |
El SQL++ realiza una INSERTAR SELECCIONAR y crea un único documento con la estructura requerida para el procesamiento de series temporales de Couchbase. Tenga en cuenta que el ts_datos contiene todos los puntos de datos de precios de cierre diarios de 2013.
3. Repita la operación INSERT/SELECT para 2014 y 2015.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[ { "id": "stock:XYZ:2013", "teletipo": "XYZ", "ts_start": 1387497600000, "ts_end": 1365465600000, "ts_data": [ [ 1387497600000, 38.67 ], [ 1380585600000, 36.21 ], ...] }, { "id": "stock:XYZ:2014", "teletipo": "XYZ", "ts_start": 1413331200000, "ts_end": 1402444800000, "ts_data": [ [ 1413331200000, 42.59 ], [ 1399507200000, 36.525], ...] }, { "id": "stock:XYZ:2015", "teletipo": "XYZ", "ts_start": 1444780800000, "ts_end": 1436313600000, "ts_data": [ [ 1444780800000, 62.92 ], [ 1421280000000, 46.405], ...] } ] |
Estrategias de ingestión de datos
Hay varios escenarios que puede tener para la carga incremental de sus documentos JSON de Series Temporales.
-
- Añadir un rango de puntos de datos como un nuevo documento JSON - Para este escenario se puede utilizar el anterior SQL++ INSERT. Sólo tiene que asegurarse de que los rangos de puntos de datos no se superpongan a los documentos existentes.
- Añadir un rango de puntos de datos a un documento JSON existente - Aquí tienes dos opciones:
- Reemplazar todo el documento utilizando UPSERT/SELECT como en el INSERT/SELECT
- Utilizar Couchbase SDK para añadir sólo los nuevos puntos de datos de elementos
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Inicializar el cluster Couchbase y los objetos bucket Grupo grupo = CouchbaseCluster.crear(""); Cubo cubo = grupo.openBucket(""); // Especifique el ID del documento y la ruta del subdocumento a actualizar Cadena docId = ""; // eg. "stock:XYZ:2015" Cadena ruta = "a.ts_data[-1]"; // -1 especifica el último elemento de la matriz // Crear un objeto JSON que represente el nuevo elemento del array a añadir JsonObject nuevoElemento = JsonObject.crear() .poner("0", "2015-12-31") .poner("1", 300); // Utiliza la API de subdocumentos para actualizar la matriz JsonDocument doc = cubo.consiga(docId); si (doc != null) { cubo.mutateIn(docId) .arrayAppend(ruta, nuevoElemento) .ejecutar(); } |
Consulta de los datos de las series temporales
Antes de consultar los datos, debe crear un índice. Aunque esto no es absolutamente necesario, ya que sólo tenemos unos pocos documentos, aunque cada documento consta de todo el año de la cotización diaria de las acciones.
|
1 |
CREAR ÍNDICE ix1 EN c3(ticker, ts_end, ts_start); |
A continuación definimos el rango de datos sobre el que queremos que se ejecute la consulta. Aquí definimos un array con dos elementos, la hora de inicio y fin de 2013-01-01 y 2015-12-31.
|
1 |
\configure -$ts_gamas [1682947800000,1685563200000]; |
Ver los puntos de datos de las series temporales
Utiliza el _timeseries como se ha descrito anteriormente:
|
1 2 3 |
SELECCIONE t.* DESDE c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_rangos}) AS t DONDE d.ticker = XYZ Y (d.ts_start <= $ts_rangos[1] Y d.ts_end >= $ts_rangos[0]); |
Resultados:
|
1 2 3 4 5 6 |
[ { "_t": 1413331200000, "_v0": 42.59 }, { "_t": 1399507200000, "_v0": 36.525}, { "_t": 1392854400000, "_v0": 37.79 }, { "_t": 1395100800000, "_v0": 39.82 }, { "_t": 1410307200000, "_v0": 41.235}, ... ] |
Visualizar los datos de las series temporales con la función Ventana de SQL
Ahora que podemos acceder a todo el conjunto de datos, podemos utilizar la función de ventanas SQL++ de Couchbase para ejecutar algunas funciones avanzadas de agregación. Esta consulta devuelve la media diaria de la acción, así como una media móvil de 7 días.
|
Resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
[ { "día": "2014-01-02T00:00:00Z", "dayavg": 39.12, "sevendaymovavg": 39.12 }, { "día": "2014-01-03T00:00:00Z", "dayavg": 39.015, "sevendaymovavg": 39.067499999999995 }, { "día": "2014-01-06T00:00:00Z", "dayavg": 38.715, "sevendaymovavg": 38.949999999999996 }, { "día": "2014-01-07T00:00:00Z", "dayavg": 38.745, "sevendaymovavg": 38.89875 }, { "día": "2014-01-08T00:00:00Z", "dayavg": 38.545, "sevendaymovavg": 38.827999999999996 }, .. ] |
Utilizar gráficos SQL++ en datos de series temporales
En este ejemplo, utilizamos la función de Series Temporales de Couchbase y su capacidad de Gráficos para seguir una estrategia de trading popular mediante el seguimiento de medias móviles rápidas (5 días) frente a medias móviles lentas (30 días).
|
1 2 3 4 5 6 7 8 9 |
SELECCIONE MILLIS_TO_TZ(día*86400000,"UTC") AS día, dayavg , AVG(dayavg) EN (PEDIR POR día FILAS 5 PRECEDENTES) AS fma, AVG(dayavg) EN (PEDIR POR día FILAS 30 PRECEDENTES) AS sma DESDE ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_rangos}) AS t DONDE d.ticker = XYZ <span estilo="font-weight: 400"> Y (d.ts_start <= $ts_rangos[</span><span estilo="font-weight: 400">1</span><span estilo="font-weight: 400">] Y d.ts_end >= $ts_rangos[</span><span estilo="font-weight: 400">0</span><span estilo="font-weight: 400">])</span> GRUPO POR IDIV(t._t,86400000) AS día ALQUILER dayavg = AVG(t._v0); |
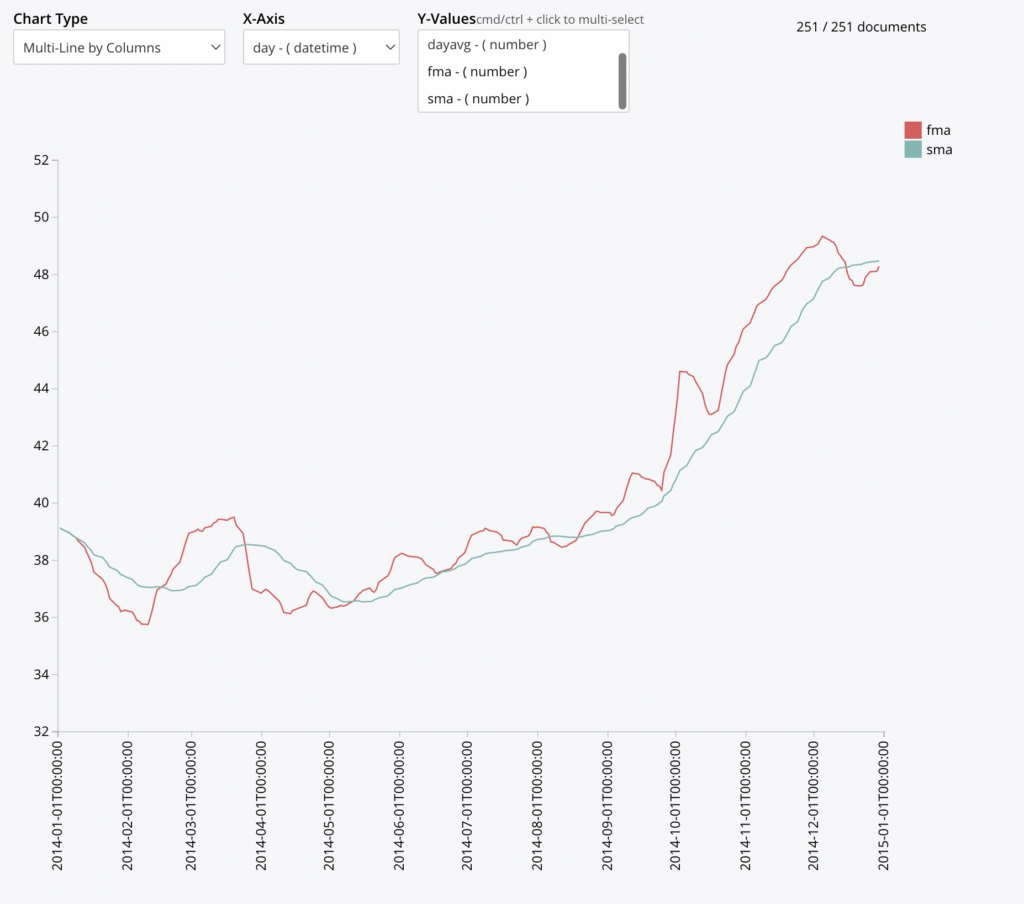
La idea detrás de esta estrategia es identificar cuándo la tendencia a corto plazo (FMA) cruza por encima o por debajo de la tendencia a largo plazo (SMA). Cuando la FMA cruza la SMA, se considera una señal de compra, y a la inversa, una señal de venta cuando la FMA cruza por debajo de la SMA.
Utilizar la Expresión de Tabla Común de SQL++ con datos de series temporales
Este análisis calcula el Índice de Fuerza Relativa, es decir, la velocidad y el cambio de los movimientos del precio de las acciones para identificar cuándo una acción está sobrecomprada o vendida. Un valor de RSI > 70 puede indicar que la acción está sobrecomprada y que debe corregirse. Por el contrario, cuando el RSI es inferior a 30, puede indicar que la acción está sobrevendida y se espera un rebote.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
CON cambio_precio AS ( SELECCIONE t._t como fecha, t._v0 AS precio, LAG(t._v0, 1) EN (PEDIR POR t._t) AS precio_anterior, NÚMERO DE FILA() EN (PEDIR POR t._t) AS rn DESDE ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_rangos}) AS t DONDE d.ticker = XYZ Y ( $ts_rangos[0] ENTRE d.ts_start Y d.ts_fin O (d.ts_start ENTRE $ts_rangos[0] Y $ts_rangos[1] Y d.ts_end ENTRE $ts_rangos[0] Y $ts_rangos[1] ) O $ts_rangos[1] ENTRE d.ts_start Y d.ts_fin ) ), ganancia_pérdida AS ( SELECCIONE pc.fecha, pc.precio, pc.precio_anterior, CASO CUANDO pc.precio > pc.precio_anterior ENTONCES pc.precio - pc.precio_anterior ELSE 0 FIN AS ganar, CASO CUANDO pc.precio < pc.precio_anterior ENTONCES pc.precio_anterior - pc.precio ELSE 0 FIN AS pérdida, pc.rn DESDE cambio_precio pc ), ganancia_pérdida_avg AS ( SELECCIONE gl.fecha, AVG(gl.ganar) EN (PEDIR POR gl.rn FILAS ENTRE 13 PRECEDENTES Y ACTUAL FILA) AS gan_avg, AVG(gl.pérdida) EN (PEDIR POR gl.rn FILAS ENTRE 13 PRECEDENTES Y ACTUAL FILA) AS pérdida_avg, gl.rn DESDE ganancia_pérdida gl ), rsi AS ( SELECCIONE agl.fecha, 100 - (100 / (1 + (agl.gan_avg / agl.pérdida_avg))) AS rsi_val DESDE ganancia_pérdida_avg agl DONDE agl.rn >= 14 ), señales_compra_venta AS ( SELECCIONE rsi.fecha, rsi.rsi_val, CASO CUANDO rsi.rsi_val < 30 ENTONCES comprar CUANDO rsi.rsi_val > 70 ENTONCES vender FIN AS señal DESDE rsi ) SELECCIONAR * DESDE señales_compra_venta bss DONDE bss.señal IS NO NULL; |
Resultados:
|
||
Principales conclusiones
Almacenamiento de datos - El almacenamiento total de datos para las series temporales de Couchbase dependerá de cuántos puntos de datos elijas empaquetar en el array. Si el análisis es por hora, día, mes, entonces empaquete los puntos de datos según el periodo. Tenga en cuenta que el almacenamiento también se puede reducir aún más si se utiliza una serie de tiempo regular donde el elemento de tiempo en la serie de tiempo se puede derivar, y por lo tanto no requiere el almacenamiento del elemento de tiempo de época.
Elemento de datos y retención de datos con TTL - El tamaño máximo del documento JSON en Couchbase es de 20MB. Aunque esto podría significar que puedes empaquetar un gran número de puntos de datos en el array de series temporales, también debes tener en cuenta que la configuración de Time To Live es a nivel de documento, y no a nivel de elemento del array.
Ingesta de datos - La aplicación es responsable de la estrategia de ingestión de datos. Cómo empaquetar los puntos de datos de series temporales en las matrices, y el tamaño de las matrices. Lo que significa que tiene que decidir si anexar a un documento existente, o iniciar uno nuevo.
Para más información, consulte el Documentación sobre series temporales de Couchbase.