Las compilaciones y actualizaciones de índices acaban de recibir una gran mejora de rendimiento con la introducción de Scopes y Collections en Couchbase 7.
La versión 7.0 de Couchbase Server introduce la separación de los datos de Bucket en Ámbitos lógicos y colecciones sobre la base de datos de documentos JSON. Esta separación le permite organizar sus datos en diferentes esquemas y tablas, conceptos con los que la mayoría de los usuarios de RDBMS ya están familiarizados. Además, Los ámbitos y las colecciones permiten un control de acceso más preciso basado en funciones a los datos que ha almacenado en Couchbase.
Nota: La introducción de Ámbitos y Colecciones no significa que los datos de un determinado tipo debe separarse y almacenarse en su propia colección. En realidad es lo contrario: una Colección es ante todo una colección de documentos JSONy, como tal, conserva toda la flexibilidad de una base de datos sin esquema. O mejor dicho, usted crear el esquema que exige su aplicación.
Con estas optimizaciones de Index Service, puede que decida migrar del modelo Bucket al nuevo modelo Collections - o puede que ya tenga un modelo bien configurado Couchbase cluster. En este artículo, te mostraré algunas formas en las que se ha optimizado Index Service para ayudarte a decidir qué es lo mejor para tu despliegue. Empecemos.
Canalización de índices para el modelo de cubos
El siguiente diagrama muestra el proceso de creación de índices bajo el modelo Couchbase Bucket.
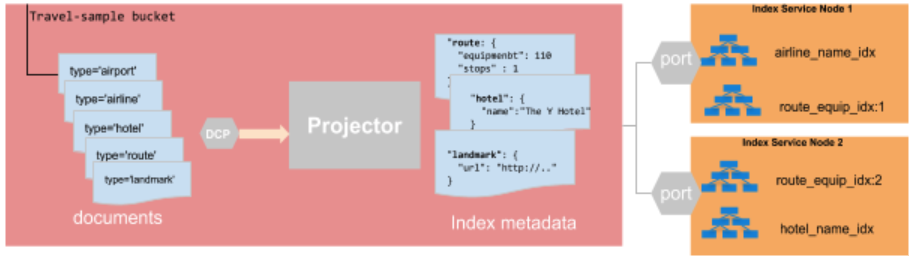
- El proceso del proyector en el Servicio de Datos es el único responsable de transmitir los datos del Cubo al Servicio de Indexación.
- El proyector utiliza un único flujo de Protocolo de Cambio de Base de Datos (DCP) para evaluar todas las mutaciones y determinar si un documento debe transmitirse al Servicio de Índices, basándose en los metadatos del índice.
- El proyector transmite sólo las columnas específicas que el Servicio de Índices mantiene para sus índices.
Por si no ha quedado claro en el diagrama anterior, el proyector debe tener en cuenta todos Mutaciones del cubo para todos de los índices del cluster.
La cadena de índices para el modelo de recogida
En el nuevo modelo de Colección de Couchbase 7.0, el streaming DCP entre el Servicio de Datos y el Servicio de Índices es a nivel de Colección. Aunque este cambio implica más flujos DCP, en realidad beneficia al procesamiento posterior cuando el proyector decide a qué Index Service enviará las mutaciones.
Hay una pequeña diferencia en cómo funciona esto para la construcción del índice inicial frente a las actualizaciones del índice. En primer lugar, veamos el proceso de creación del índice inicial con el nuevo modelo de colecciones.
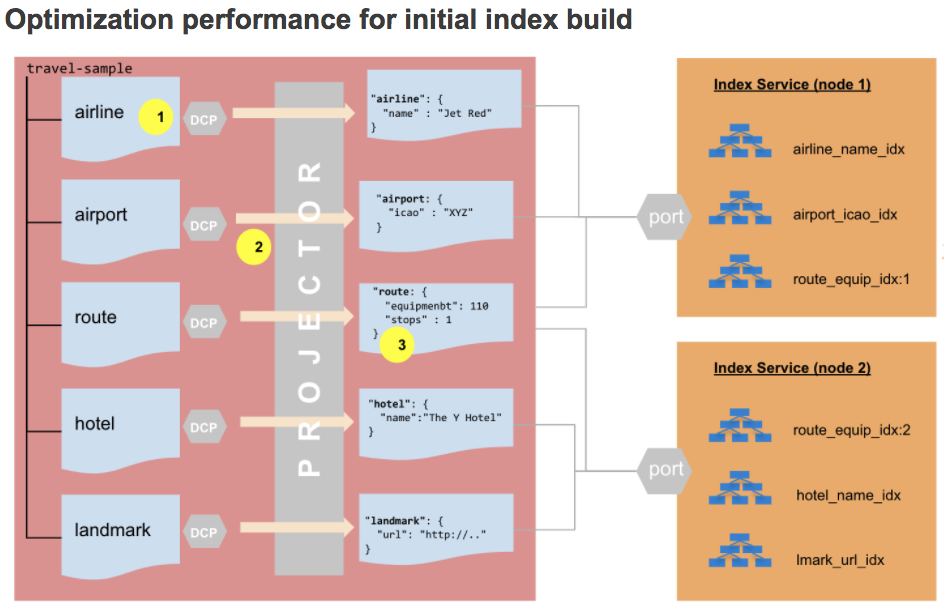
- Los índices se crean por colección.
- Se crea un flujo DCP para cada colección durante la creación del índice inicial, lo que reduce la carga de trabajo del proyector.
- El proyector ya no necesita evaluar el índice
DONDEpara determinar si una mutación es apta para el índice.
Ahora echemos un vistazo al nuevo proceso de actualización de índices en Couchbase 7.0:
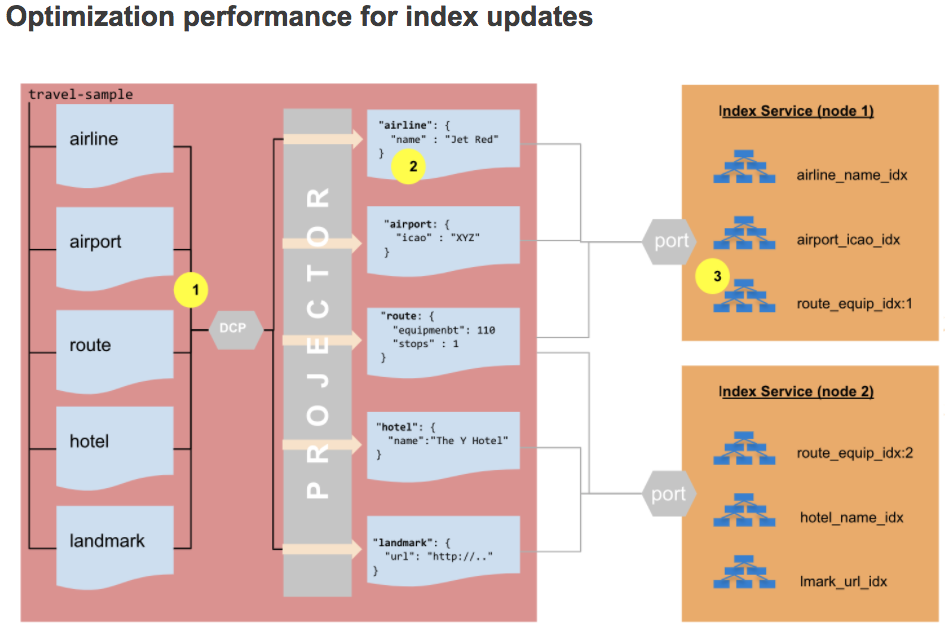
- Los datos del flujo DCP llevan ahora el prefijo
identificador de colecciónpara que el proyector sepa a qué índice debe enviar el cambio. - El proyector ya no necesita evaluar el índice
DONDEcláusula. - La comprobación de la ingestión de índices se limita a los índices definidos en la colección del documento actualizado, en lugar de a todos los índices del cubo. Esta limitación supone un ahorro significativo en términos de CPU y E/S de disco.
Conclusión
Desde el punto de vista de la configuración, la introducción de Couchbase Collections no requiere que cambies nada en el Servicio de Índices. Sin embargo, sí es necesario especificar el nombre de la colección (en lugar de solo el nombre del bucket) al crear índices en una colección específica.
La versión 7.0 implementó estos cambios para ofrecerle la ventaja de trabajar con conjuntos de datos más pequeños en lugar de gestionar las mutaciones en todo un Bucket. Esta ventaja de los datos pequeños se extiende a todas las etapas del servicio de índices, desde el proyector hasta la capa de almacenamiento, pasando por el indexador.
Si desea obtener más información sobre la versión 7.0 de Couchbase Server, Novedades y/o las notas de la versión 7.0.
Pruebe Couchbase 7.0 hoy mismo
Muy buena entrada en el blog, ¡me encanta!