Bienvenidos de nuevo, este será el último post de esta serie sobre el tallaje. En las entradas anteriores he proporcionado una visión general de las consideraciones a tener en cuenta a la hora de dimensionar un cluster de Couchbase Server, a un análisis más profundo de cómo afectan las distintas características/versiones a este dimensionamiento y proporcionó algunos consideraciones y recomendaciones específicas sobre el hardware.
En este último post, voy a discutir las diversas métricas que se deben utilizar para entender las necesidades de dimensionamiento de un clúster de Couchbase Server en ejecución. También intentaré orientar sobre umbrales y alertas cuando sea apropiado. Tómate un café, que esto va para largo...
Después de que hayas usado los tres primeros posts para entender cuál debería ser tu tamaño inicial y hayas pasado a producción, es muy importante que continúes monitorizando tu cluster y haciendo cualquier cambio de tamaño relacionado con esa monitorización. Uno de los beneficios ampliamente aceptados de Couchbase Server es la capacidad de actualizar y ampliar sin ninguna interrupción en tu aplicación y esto se utiliza mucho en toda nuestra base de clientes.
A modo de resumen rápido, los 5 factores principales que utilizamos para el dimensionamiento en primer lugar son los mismos 5 que vamos a controlar:
- RAM
- Disco (IO y espacio)
- CPU
- Red
- Distribución de datos
Muchas métricas vendrán directamente del propio Couchbase y están relacionadas sólo con nuestro software. Sin embargo, también es importante tener una monitorización extensiva del sistema desde una perspectiva externa a Couchbase (para los 4 primeros). También hay que tener en cuenta que mientras que muchas métricas se agregan a través de todo el clúster (por cubo) y que suele ser la forma más fácil para un ser humano para consumirlos, todo lo que está sucediendo en una base por nodo / por cubo y por lo que es importante para controlar la granularidad de un solo nodo. El mejor enfoque sería unir todo esto en un sistema de monitorización centralizado.
Seguimiento y umbrales
Cada aplicación va a ser un poco diferente, por lo que los valores y comportamientos de estas estadísticas variarán. Depende del administrador entender cuáles son importantes para su aplicación y en qué niveles debe preocuparse.
También debería esperar que cada nodo tenga básicamente los mismos valores (+/-) en todas estas métricas y posiblemente crear alguna alerta si algún nodo diverge demasiado.
Aunque un umbral fijo para la mayoría de estos parámetros es sin duda valioso, en muchos casos tiene más sentido realizar un seguimiento de estas métricas a lo largo del tiempo para poder estar preparado con cambios de tamaño antes de llegar a un punto crítico. De este modo, también podrá obtener datos de referencia precisos sobre lo que debería esperar.
Para cada estadística he intentado dar una idea de qué niveles y/o umbrales serían apropiados para diferentes clases de aplicaciones. Por favor, no dude en aprovechar los cientos de años de experiencia acumulada en Couchbase, Inc. para responder a cualquier pregunta específica de su aplicación.
Reaccionar ante los cambios
A continuación verás que no propongo una acción específica para cada área. Considero que es más importante entender lo que significa cada valor y luego utilizar la combinación de todo para decidir si es necesario un cambio. Si alguno de los valores siguientes no está dentro de los límites aceptables para su aplicación, es importante volver a los cálculos de tamaño y ajustar en consecuencia. En casi todas las situaciones en las que se necesitan más recursos, la respuesta será añadir uno o más nodos.
Resumen
En primer lugar, echemos un vistazo a la sección "Resumen" de los gráficos de monitorización de Couchbase:
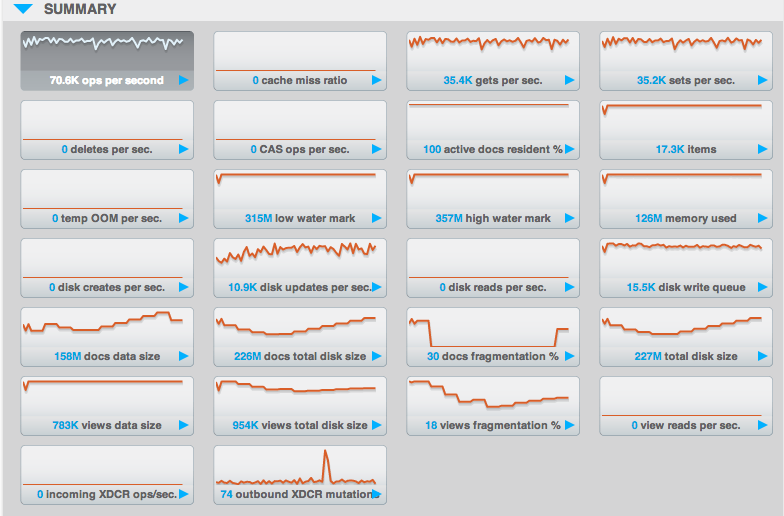
Este conjunto de estadísticas debería ser tu primer punto de referencia para monitorizar Couchbase en general, así como para dimensionar. Está diseñado para darte una visión de alto nivel a través de muchas áreas y estaremos usando muchas de estas métricas más adelante en la discusión. Verás que traigo algunas estadísticas que no están cubiertas directamente aquí, pero este es un gran lugar para empezar, si estás buscando un punto de partida para importar métricas a sus propios sistemas.
Verás una relación proporcional entre la importancia de cada factor de dimensionamiento y el número de métricas que tenemos para controlarlo.
RAM
Como sin duda habrás reconocido a estas alturas, la RAM suele ser uno de los factores más importantes relacionados con el dimensionamiento para Couchbase y es también el que puede cambiar más drásticamente en función de la carga de trabajo, el tamaño del conjunto de datos u otros factores.
Hay varias maneras de ver el uso de memoria en Couchbase y muchas están interrelacionadas:
- "artículos"es el número de documentos activos en un bucket concreto (excluidas las réplicas). Es una indicación indirecta de cuánta memoria se está utilizando, y es también uno de los valores principales que utilizamos para nuestros cálculos de tamaño. Sin embargo, no siempre es el más útil para monitorizar de forma continua.
- "memoria utilizada": Esto es el métrica de uso de memoria para Couchbase y describe cuánta memoria cree el software que está utilizando. Este es el valor que se utilizará para controlar las expulsiones y los mensajes OOM. (A veces oirás a nuestros ingenieros referirse a esto como "mem_utilizado"...es lo mismo)
- "marca de pleamar" está muy relacionado con "memoria utilizada"y es posible que desee seguirlos juntos en un gráfico. Este valor le indica en qué momento el nodo comenzará a expulsar datos.
- Siempre quieres "memoria utilizada" por debajo del "marca de pleamar". Algunas aplicaciones pueden esperar que se sobrepase ligeramente pero que luego vuelva a bajar a medida que se expulsan los datos, mientras que otras pueden esperar que nunca llegue al "marca de pleamar".
- También puede ser importante controlar este valor en comparación con la cantidad real de RAM que utiliza el proceso "memcached" dentro del sistema operativo. Hay algunos casos en los que estos dos valores divergen y es importante vigilarlos. Cualquier divergencia por encima de 10% justificaría alguna investigación, aunque algunos sistemas pueden querer permitir porcentajes más altos antes de tomar cualquier acción.
- Conjunto de trabajo:
- "ratio de fallos de caché": Se trata de un porcentaje del número de lecturas que se están sirviendo desde el disco frente a las que se están sirviendo desde la RAM. Un valor de 0 significa que todas las lecturas proceden de la RAM, mientras que un valor superior indica que algunas lecturas proceden del disco.
- Para aplicaciones que esperan que todo sea servido desde la RAM, esto debería ser siempre 0.
- Para las aplicaciones que esperan que no sea 0, lo ideal es que sea lo más bajo posible; la mayoría de las implantaciones están por debajo de 1%, pero algunas aceptan más de 10%. Los SSD frente a los discos giratorios tienen un gran efecto en lo que es un valor razonable.
- "docs activos residentes %": Este es el porcentaje de elementos actualmente almacenados en caché en la RAM. 100% significa que todos los elementos están almacenados en la memoria RAM, mientras que cualquier valor inferior indica que algunos elementos han sido expulsados.
- Algunas aplicaciones esperan que este valor sea siempre 100% y alertan si es inferior.
- Otras aplicaciones esperan que sea algo inferior a 100%, pero el valor real depende de ti. En general, yo recomendaría no bajar de 30% a menos que tu aplicación se sienta cómoda con ello.
- "ratio de fallos de caché": Se trata de un porcentaje del número de lecturas que se están sirviendo desde el disco frente a las que se están sirviendo desde la RAM. Un valor de 0 significa que todas las lecturas proceden de la RAM, mientras que un valor superior indica que algunas lecturas proceden del disco.
- Tenga en cuenta que aunque "docs activos residentes %" puede ser significativamente inferior a 100%, el "ratio de fallos de caché" puede estar dentro de un rango aceptable dependiendo del conjunto de trabajo de su aplicación.
- "temp OOM por seg."es una medida de cuántas operaciones de escritura están fallando debido a una situación de "falta de memoria" en el nodo/cubo. Solo se producirá si la "memoria utilizada" alcanza 90% de la cuota total del bucket.
- A menos que se espere explícitamente, todo lo que no sea 0 aquí debe considerarse muy malo. Sin embargo, esta situación puede evitarse controlando adecuadamente "memoria utilizada"como se ha indicado anteriormente.
Además de las métricas específicas de Couchbase, también querrás monitorizar:
- El total de RAM libre disponible en el nodo. Ten en cuenta que Linux tiene algunas formas extrañas de expresar lo que realmente es "libre".
- Alerta si baja de 1-2GB.
- Uso de swap. Aunque se espera que Linux utilice un poco de swap en condiciones normales, cualquier cantidad excesiva de uso de swap o swap excesivo (mire la salida de 'vmstat') se consideraría motivo de preocupación
- El uso de memoria del proceso beam.smp (erl.exe en Windows). Las versiones anteriores tenían algunos posibles crecimientos excesivos en este proceso. Esos problemas se han solucionado a partir de la versión 2.5, pero sigue siendo una buena idea vigilarlo.
- Más de 4,5 GB sería inapropiado en este caso.
Disco
Dividido en IO frente a espacio, el dimensionamiento global de los recursos de disco también es de vital importancia. Dependiendo de la naturaleza de la carga de trabajo, a veces puede ser más importante que la RAM.
Tomando IO en primer lugar, tenemos unas cuantas métricas dignas de seguimiento:
- "cola de escritura en disco": Esto es el para saber si hay suficiente IO de disco en un nodo. Aunque hay muchos procesos que compiten por la IO de disco (escritura de datos, compactación, vistas, XDCR, copias de seguridad locales, etc.), utilizamos la métrica "cola de escritura en disco" como medidor general, ya que una IO insuficiente hará que los elementos se escriban en el disco más lentamente (independientemente de la causa) y debería resolverse.
- Todo lo que se acerque a 1M de elementos por contenedor por nodo debería ser motivo de preocupación, aunque muchas aplicaciones esperan que sea mucho menor para su carga de trabajo. Es de esperar que sea mayor durante un reequilibrio.
- Esta métrica también es importante desde el punto de vista de las tendencias, ya que subirá y bajará en la mayoría de los casos. Muchas aplicaciones aceptan picos durante sus picos de carga de trabajo (aún así debería ser <1M) pero es importante que baje durante periodos de menor carga. Una cola en constante aumento a lo largo del tiempo indica que no hay suficiente IO de disco en general.
- "creaciones de disco por segundo", "actualizaciones de disco por segundo", "lecturas de disco por segundo": Todas estas son indicaciones de la tasa de lectura/escritura y pueden utilizarse en futuros cálculos de dimensionamiento
Por el espacio:
- "docs tamaño total del disco" y "vistas tamaño total del disco": Estos miden la cantidad de espacio en disco en uso bajo el directorio de datos y el directorio de vistas (según las mejores prácticas, estos deben estar en particiones separadas). Esto es diferente de "tamaño de los datos del disco" o "vistas tamaño de los datos", que miden la cantidad de datos Couchbase activos dentro de esos archivos. La diferencia entre estas dos causas "docs fragmentación %" y "vistas fragmentación %", lo que podría desencadenar la compactación.
- Es muy importante asegurarse de que hay suficiente espacio disponible en el disco no sólo para almacenar datos, sino también para la naturaleza de sólo apéndice del formato de archivo, realizar la compactación, hacer copias de seguridad, etc. Un nivel de alerta apropiado sería alrededor de 75% de uso de disco con una alerta crítica a 90%.
Fuera de Couchbase, el sistema operativo monitorizará no sólo el espacio en disco (piensa en 'df') sino también la utilización del disco (piensa en 'iostat').
CPU
Como has visto en posts anteriores, la CPU es raramente un área importante en el dimensionamiento de Couchbase. Dicho esto, es importante monitorizar el uso total de CPU de un nodo y el uso de CPU de los nodos. memcached y beam.smp/erl.exe procesos.
Otro aspecto importante del uso de la CPU es la distribución entre varios núcleos. Aunque no está necesariamente relacionado con el dimensionamiento, un desequilibrio en el uso de la CPU puede requerir cierta investigación.
Red
Aunque el ancho de banda y la latencia de la red tienen un gran efecto en el rendimiento general del sistema, es muy raro que se desvíen de los niveles esperados y causen problemas.
El principal valor que usamos dentro de Couchbase para asegurar una red saludable está relacionado con la cola de replicación entre nodos. Aunque no está presente en el "Resumen" anterior, se conoce casualmente como la "cola TAP" y está representada por "artículos"dentro de la sección "TAP QUEUES" de la interfaz de usuario:
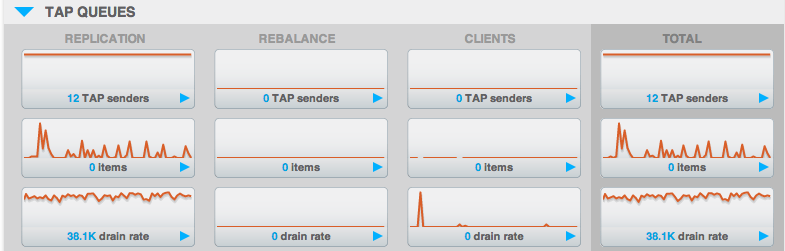
Este valor casi siempre será 0 e incluso unos pocos por encima de 0 no son motivo de preocupación. Si este valor se eleva a más de 200 por nodo, y especialmente si sigue aumentando, puede indicar un problema de red o algo más dentro del clúster que ralentiza la replicación.
Fuera de Couchbase, también querrás mantener un ojo general en el uso del ancho de banda de la red entre los nodos de Couchbase y entre esos nodos y tus servidores de aplicaciones. También es potencialmente importante el número de conexiones TCP a los distintos nodos de Couchbase. puertos de red, sobre todo desde la perspectiva de la comunicación cliente-servidor.
Distribución de datos
Al final de la lista por una buena razón, realmente no hay mucho que supervisar aquí en relación con el tamaño. También es el único factor que realmente tiene sentido para mirar a través de todo el clúster en lugar de nodos individuales.
Si nos fijamos en la sección "recursos vbucket" de la interfaz de usuario:
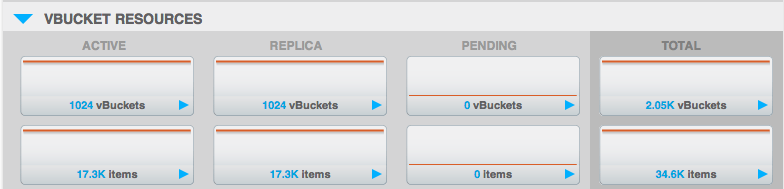
Podemos ver cuántos "vBuckets" activos y cuántas réplicas hay para este bucket. "Activo vBuckets" debe ser siempre 1024 y "Réplica de vBuckets"debería ser siempre 1024*(número de réplicas). Si no lo son, significa que hay algunos datos no disponibles o no replicados y se requiere una acción inmediata. Esto suele ocurrir después de un fallo/failover y requerirá un reequilibrio para volver a la normalidad.
La recomendación general de tener siempre al menos 3 nodos en el clúster también es válida.
XDCR
Si utiliza XDCR con Couchbase, la métrica más importante que debe vigilar es la cola de mutación XDCR - "mutaciones XDCR salientes". Esta es una indicación de cuántos elementos están esperando ser replicados a los cubos que actúan como destinos de éste. Al igual que la cola de escritura en disco, se espera que crezca y disminuya bajo carga, pero es importante asegurarse de que con el tiempo se acerque a cero y no crezca continuamente.
Virtualización/Nube
Sin excepciones, el análisis anterior se aplica por igual a todos los entornos de hardware físico, máquinas virtuales y despliegues en la nube. Los valores reales pueden variar y, sin duda, sus umbrales y líneas de base esperadas también serán diferentes.
La principal adición a este rompecabezas para entornos virtualizados y en la nube es el impacto de los sistemas e hipervisores subyacentes. He proporcionado algunas directrices específicas de despliegue en el post anterior de esta serie, así que no voy a recapitular aquí. En términos de monitoreo, todos los mismos "fuera de Couchbase" se aplican al sistema subyacente.
Una intersección interesante entre ambas se refiere a "tiempo robado".
Conclusión
Para reunir todo esto en un solo lugar, he reunido todas estas métricas en un solo lugar. Puede que no todas sean aplicables a tu entorno, pero todas "podrían" serlo y deberían entenderse para tu aplicación:
| Métricas en Couchbase: | Externo a Couchbase | |
|---|---|---|
| RAM: |
|
|
| IO de disco: |
|
|
| Espacio en disco: |
|
|
| CPU: |
|
|
| Red: |
|
|
| Distribución de datos: |
|
|
| XDCR: |
|
Gracias por acompañarme en este viaje, espero que haya sido útil. Por favor, no dudes en ponerte en contacto conmigo directamente o con el equipo de Couchbase si tienes alguna pregunta o duda o si te gustaría recibir atención específica en tu entorno.
Hola, gracias por estos artículos. Tengo una pregunta que no puedo averiguar si es posible.
Dados los Servidores 1, 2 y 3, ¿puedo tener instancias Couchbase A1, B1, C1 en
Servidor 1; A2, B2, C2 en el Servidor 2 y A3, B3 y C3 en el Servidor 3, de modo que
¿A1, A2, A3 forman un grupo, B1, B2 y B3 forman un grupo, etc.?
Esto sería necesario a efectos de producción.
Gracias.
Hola Renault, disculpa el retraso en responderte. No hay ninguna razón técnica por la que esto sería un problema, pero iría en contra de nuestras mejores prácticas generales de mantener estas cargas de trabajo aisladas. También crearía una tarea de administración para que usted recuerde que hay 3 nodos en cada servidor físico que forman parte de 3 clusters diferentes y necesitan ser gestionados / equilibrados por separado.
[...] la tercera entrada de esta serie trata sobre las diferentes opciones de hardware e infraestructura. Por último, la cuarta entrada examina las métricas que puede supervisar tanto dentro como fuera de Cocuhbase para comprender [...]