Los modelos de lenguaje grandes han cambiado la forma en que interactuamos con la información, pero tienen una limitación fundamental: su conocimiento está congelado en el tiempo. No pueden acceder a datos en tiempo real ni a información de documentos privados y confidenciales, ya que solo conocen lo que se les ha enseñado. Aquí es donde entra en juego RAG. Al conectar los LLM con fuentes de conocimiento externas, RAG los hace más inteligentes, precisos y útiles.
¿Qué es el GAR?
RAG es una técnica de inteligencia artificial que mejora grandes modelos lingüísticos permitiéndoles recuperar información externa relevante antes de generar una respuesta. En lugar de basarse únicamente en conocimientos previamente entrenados, RAG busca fuentes de datos conectadas, como documentos o bases de datos, para proporcionar respuestas más precisas, actualizadas y sensibles al contexto.
Piensa en ello como un examen a libro abierto. Un LLM por sí solo es como un estudiante que intenta responder preguntas de memoria. Un LLM con tecnología RAG es como ese mismo estudiante que tiene un conjunto seleccionado de libros de texto y notas para consultar antes de escribir su respuesta. Este proceso mejora la precisión y la relevancia de los resultados del LLM, reduce el riesgo de generar información incorrecta o inventada (lo que se conoce como “alucinaciones”) y le permite responder preguntas sobre datos con los que no ha sido entrenado.
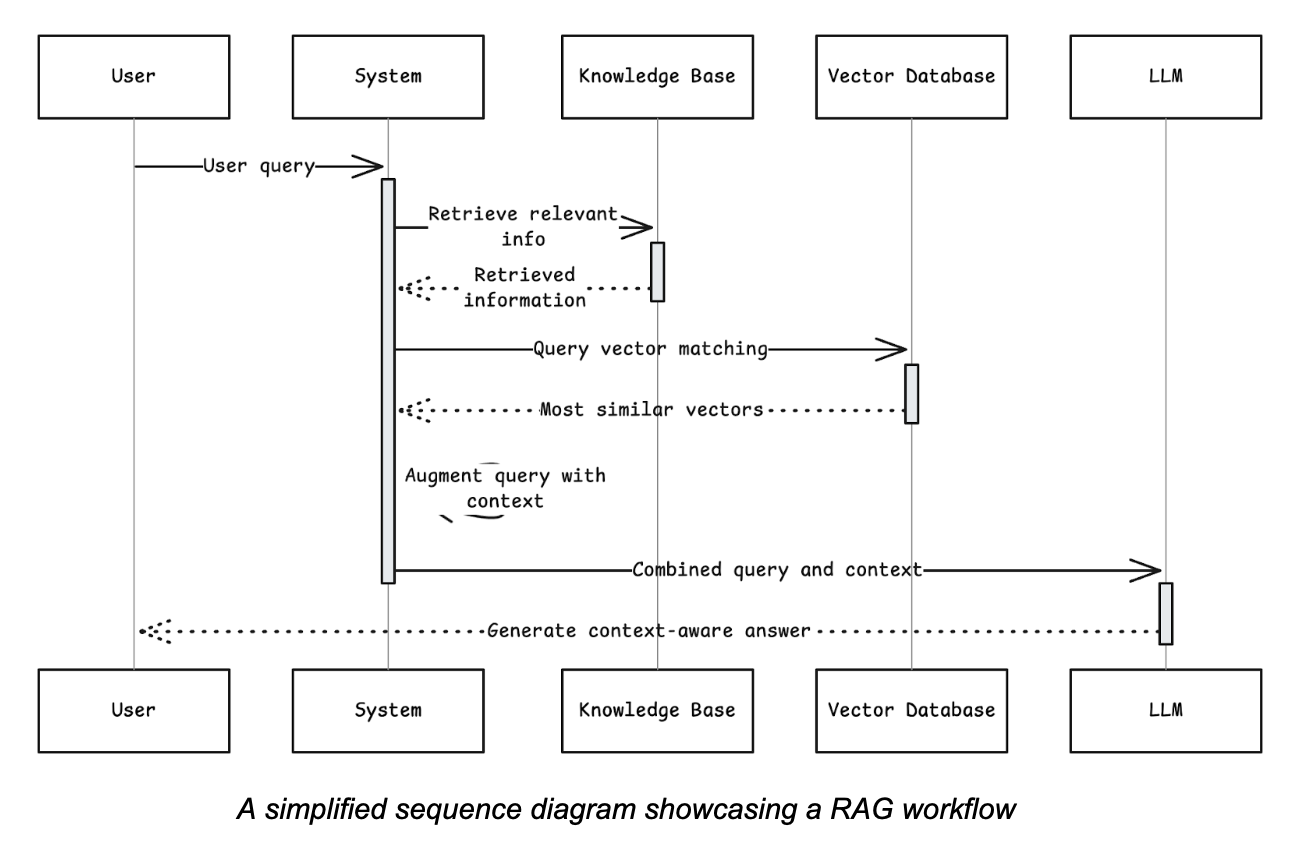
El proceso RAG suele seguir estos pasos:
- Consulta del usuario: Un usuario hace una pregunta.
- Recuperación: El sistema busca en una base de conocimientos externa (por ejemplo, una colección de documentos, una base de datos o un sitio web) información relevante para la consulta.
- Aumento: La información recuperada se añade a la consulta original del usuario como contexto.
- Generación: La solicitud combinada (consulta original más contexto recuperado) se envía al LLM, que luego genera una respuesta completa y contextualizada.
¿Qué es el RAG gráfico?
Graph RAG es un enfoque más sofisticado que utiliza un gráfico de conocimiento como fuente de datos externa. A gráfico de conocimiento organiza la información como una red de entidades (nodos) y sus relaciones (aristas). Por ejemplo, un nodo podría ser una persona, una empresa o un producto, mientras que una arista podría representar una relación como “trabaja para”, “adquirido” o “es un componente de”.”
En lugar de limitarse a buscar fragmentos de texto que sean semánticamente similares a una consulta, Graph RAG recorre la red de relaciones para encontrar información altamente contextual e interconectada. No solo entiende qué las cosas son, pero también cómo se relacionan entre sí. Esto le permite responder preguntas complejas que requieren comprender las relaciones, los patrones y las jerarquías dentro de los datos.
Beneficios
- Relaciones explícitas: Los gráficos son excelentes para representar conexiones explícitas entre puntos de datos, proporcionando un contexto profundo y estructurado que las búsquedas vectoriales podrían pasar por alto.
- Manejo de consultas complejas: Graph RAG puede responder preguntas de múltiples saltos que requieren reunir información de diferentes partes de la base de conocimientos (por ejemplo, “¿Qué clientes en Alemania utilizan un producto fabricado por una empresa que adquirimos el año pasado?”).
- Reducción de las alucinaciones: Al basar el LLM en un gráfico estructurado y factual, se reduce significativamente el riesgo de generar información inexacta. El contexto se basa en relaciones definidas, no solo en similitudes semánticas.
- Explicabilidad: Se puede rastrear el camino recorrido a través del gráfico para encontrar una respuesta, lo que hace que el proceso de razonamiento del LLM sea más transparente y explicable.
Desafíos
- Modelado de datos complejos: Crear y mantener un grafo de conocimiento requiere un esfuerzo inicial significativo en el modelado y la extracción de datos, la transformación y la procesos de carga (ETL).
- Escalabilidad: Aunque las bases de datos gráficas modernas son muy escalables, la gestión de gráficos masivos y altamente interconectados puede plantear retos de rendimiento.
- Experiencia especializada: La implementación de RAG en grafos requiere conocimientos especializados en bases de datos de grafos, lenguajes de consulta como Cifrado y SPARQL, y ciencia de datos gráficos.
Casos prácticos
- Detección de fraudes: Identificar relaciones complejas y ocultas entre cuentas, transacciones y personas para descubrir redes fraudulentas.
- Gestión de la cadena de suministro: Responder preguntas sobre las dependencias de los proveedores, los riesgos logísticos y el impacto de una interrupción en una parte de la cadena en toda la red.
- Descubrimiento de fármacos: Explorar las relaciones entre genes, proteínas y enfermedades para identificar posibles objetivos para nuevas terapias.
- Motores de recomendación avanzados: Sugerir productos o contenido basándose en comportamientos complejos de los usuarios y relaciones entre artículos, no solo en lo que es popular.
¿Qué es el vector RAG?
Vector RAG es actualmente la implementación más común del marco RAG. Utiliza una base de datos vectorial para almacenar y recuperar información. En este enfoque, los datos de texto (por ejemplo, documentos, artículos, páginas web) se dividen en fragmentos más pequeños, y cada fragmento se convierte en una representación numérica denominada incrustación vectorial. utilizando un modelo de incrustación.
Cuando un usuario envía una consulta, la propia consulta también se convierte en un vector. A continuación, el sistema realiza una búsqueda por similitud dentro de la base de datos vectorial para encontrar los fragmentos de texto cuyos vectores son más cercanos al vector de la consulta. Estos fragmentos semánticamente similares se pasan al LLM como contexto.
Beneficios
- Simplicidad y rapidez: Configurar un proceso RAG vectorial es relativamente sencillo. El proceso de incrustación y búsqueda es computacionalmente eficiente y rápido, incluso con grandes conjuntos de datos.
- Maneja datos no estructurados: Funciona excepcionalmente bien con grandes volúmenes de texto no estructurado, como PDF, artículos y tickets de soporte, sin necesidad de un esquema predefinido.
- Amplia aplicabilidad: Al centrarse en el significado semántico, es una solución versátil para una amplia gama de tareas generales de preguntas y respuestas y resumen.
- Ecosistema maduro: Existe un ecosistema sólido y en crecimiento de bases de datos vectoriales, modelos de incrustación y marcos (como Cadena LangChain y LlamaIndex) que simplifican el desarrollo.
Desafíos
- Falta de relaciones contextuales: La búsqueda vectorial puede pasar por alto las relaciones sutiles entre los distintos datos. Puede recuperar datos que son semánticamente similares, pero que no están directamente relacionados, lo que da lugar a respuestas menos precisas.
- “El problema de ”perderse en medio»: Cuando se recuperan demasiados documentos, el LLM puede tener dificultades para identificar la información más importante, especialmente si está oculta en medio del contexto proporcionado.
- Dificultad con los datos granulares: En el caso de datos muy estructurados o tabulares, convertir todo en fragmentos de texto puede provocar una pérdida de precisión y la imposibilidad de responder a preguntas que dependen de puntos de datos específicos.
Casos prácticos
- Chatbots de atención al cliente: Encontrar rápidamente respuestas a las preguntas de los usuarios a partir de una base de conocimientos con artículos de ayuda, preguntas frecuentes y manuales de productos.
- Preguntas y respuestas sobre el documento: Permitir a los usuarios “chatear” con sus documentos, haciendo preguntas específicas sobre un trabajo de investigación, un contrato legal o un informe financiero.
- Descubrimiento de contenido: Recomendar artículos, videos o productos basándose en el significado semántico de la búsqueda de un usuario.
- Búsqueda empresarial: Mejorar los motores de búsqueda internos para ofrecer resultados más relevantes a partir de los documentos y recursos de toda la empresa.
Diferencias clave entre RAG gráfico y RAG vectorial
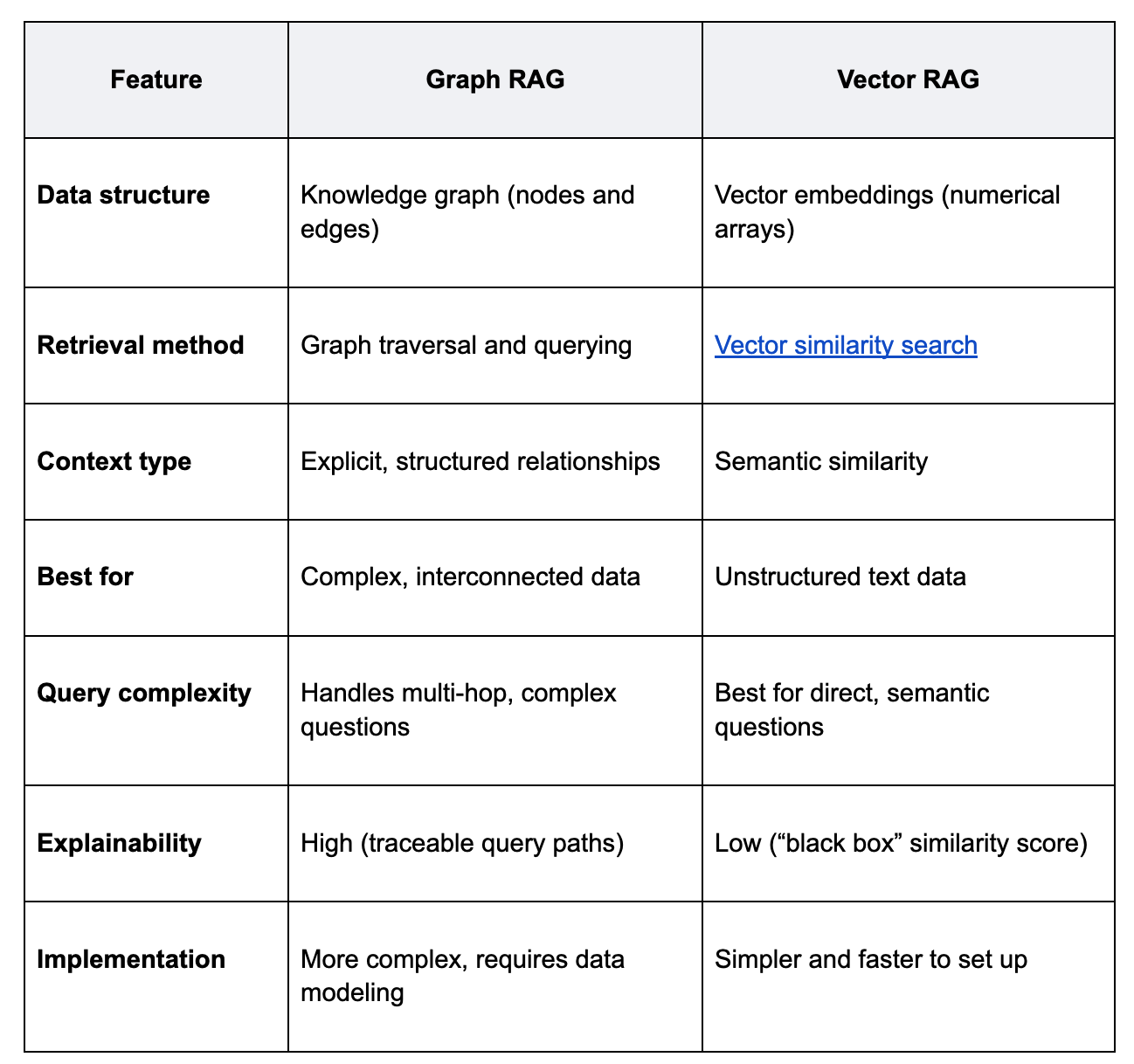
Cuándo utilizar RAG gráfico frente a RAG vectorial
La elección entre RAG gráfico y RAG vectorial depende totalmente de tus datos y del tipo de preguntas que necesites responder.
Utilice el gráfico RAG cuando:
- Las relaciones son fundamentales: Sus datos están muy conectados, y el valor reside en comprender esas conexiones (por ejemplo, redes sociales, cadenas de suministro, sistemas financieros).
- Debes responder preguntas complejas y con múltiples saltos: Los usuarios deben formular preguntas que requieran sintetizar información procedente de múltiples puntos de datos relacionados entre sí.
- La explicabilidad es fundamental: Es necesario poder mostrar exactamente cómo el sistema ha llegado a una respuesta, lo cual es crucial en sectores altamente regulados como el financiero y el sanitario.
Utilice el RAG vectorial cuando:
- Sus datos son en su mayoría texto no estructurado: Tienes un gran corpus de documentos, artículos u otra información basada en texto.
- Necesitas una solución rápida: Desea crear una prueba de concepto o un sistema de producción sin realizar una gran inversión en modelado de datos.
- El objetivo principal es la búsqueda semántica y la síntesis: Sus usuarios necesitan encontrar pasajes relevantes en los documentos y obtener respuestas resumidas.
El futuro de los sistemas RAG
El debate no se centra en qué método RAG “ganará”. El futuro de RAG es híbrido. Los sistemas de IA más potentes combinarán las fortalezas tanto de RAG gráfico como de RAG vectorial.
Imaginemos un sistema que realiza una búsqueda vectorial para identificar rápidamente un conjunto relevante de documentos. A continuación, utiliza un grafo de conocimiento construido a partir de esos documentos para explorar las relaciones específicas entre las entidades mencionadas. Este enfoque multicapa proporciona tanto la velocidad y la escala de la búsqueda vectorial como la profundidad y la precisión del recorrido del grafo. Este modelo híbrido permite a un LLM responder a una gama más amplia de preguntas con mayor precisión y contexto que cualquiera de los dos sistemas por separado.
Principales conclusiones y recursos adicionales
- RAG mejora los LLM al conectarlos con conocimientos externos, lo que aumenta la precisión y reduce las alucinaciones.
- Vector RAG es ideal para buscar grandes volúmenes de texto no estructurado basándose en el significado semántico. Es rápido, escalable y relativamente fácil de implementar.
- Graph RAG destaca en la navegación por datos altamente conectados para responder a preguntas complejas que dependen de la comprensión de las relaciones. Ofrece mayor precisión y explicabilidad.
- La elección correcta depende de la estructura de sus datos y de los requisitos de su aplicación.
- Los sistemas híbridos que combinan ambos enfoques representan el futuro de la creación de aplicaciones de IA sofisticadas y sensibles al contexto.
Para seguir aprendiendo sobre la generación aumentada por recuperación, puede consultar los siguientes recursos:
- Base de datos vectorial frente a base de datos gráfica: diferencias y similitudes – Blog
- Del concepto al código: LLM + RAG con Couchbase – Blog
- Ampliación de las capacidades de RAG a Excel con Couchbase, LLamaIndex y Amazon Bedrock – Blog
- Guía paso a paso para preparar datos para la generación aumentada por recuperación (RAG) – Blog
- Cómo creé una aplicación RAG para plantas con Couchbase Vector Search en iOS – Blog
PREGUNTAS FRECUENTES
¿Cuáles son las principales ventajas del RAG gráfico sobre el RAG vectorial? Las principales ventajas son su capacidad para comprender y utilizar relaciones explícitas dentro de los datos, responder preguntas complejas de múltiples saltos y proporcionar una mayor explicabilidad de sus respuestas mediante el seguimiento de la ruta de la consulta a través del gráfico.
¿Se pueden combinar el RAG gráfico y el RAG vectorial en un solo sistema? Sí, y esto se está convirtiendo en un patrón muy potente. Un enfoque híbrido puede utilizar la búsqueda vectorial para una recuperación inicial amplia y, a continuación, utilizar un gráfico de conocimiento para refinar el contexto y explorar relaciones específicas, aprovechando las ventajas de ambos métodos.
¿Qué es mejor para los datos empresariales a gran escala, el RAG gráfico o el RAG vectorial? Depende del tipo de datos. Si los datos de la empresa son una recopilación masiva de documentos no estructurados (informes, correos electrónicos, etc.), el RAG vectorial es un excelente punto de partida. Si los datos implican relaciones complejas (por ejemplo, organigramas, historiales de interacción con los clientes, dependencias de productos), el RAG gráfico aportará más valor y conocimientos más profundos.
¿En qué se diferencian las bases de datos gráficas de las bases de datos vectoriales en las aplicaciones RAG? Las bases de datos gráficas almacenan datos como nodos y aristas, optimizadas para consultar relaciones. Las bases de datos vectoriales almacenan datos como vectores de alta dimensión y están optimizadas para encontrar los vecinos más cercanos de un vector de consulta utilizando una métrica de distancia. Una almacena conexiones explícitas, mientras que la otra almacena similitudes semánticas.
¿El RAG gráfico requiere más recursos computacionales que el RAG vectorial? Los recursos iniciales necesarios para el RAG gráfico pueden ser mayores, especialmente en la fase de modelado e ingestión de datos. Sin embargo, para ciertas consultas complejas, recorrer un gráfico bien estructurado puede ser más eficiente que examinar miles de fragmentos de texto semánticamente similares, pero potencialmente irrelevantes, recuperados mediante una búsqueda vectorial. El rendimiento de las consultas depende en gran medida del caso de uso específico y de la optimización de la base de datos.