¿Se ha preguntado alguna vez qué es la concordancia difusa? La concordancia difusa permite identificar coincidencias no exactas del elemento buscado. Es la piedra angular de muchos motores de búsqueda y una de las principales razones por las que puede obtener resultados de búsqueda relevantes incluso si tiene un error tipográfico en su consulta o un tiempo verbal diferente.
Como cabría esperar, existen muchos algoritmos de búsqueda difusa que pueden utilizarse para el texto, pero prácticamente todos los marcos de los motores de búsqueda (incluido bleve) utilizan principalmente la distancia Levenshtein para la coincidencia difusa de cadenas:
Distancia Levenshtein
También conocido como Editar Distanciaes el número de transformaciones (supresiones, inserciones o sustituciones) necesarias para transformar una cadena de origen en la de destino. Para un ejemplo de búsqueda difusa, si el término de destino es "libro" y el de origen es "espalda", será necesario cambiar la primera "o" por "a" y la segunda "o" por "c", lo que nos dará una Distancia de Levenshtein de 2.Editar Distancia es muy fácil de implementar, y es un reto popular durante las entrevistas de código (Puedes encontrar implementaciones de Levenshtein en JavaScript, Kotlin, Java y muchos otros aquí).
Además, algunos marcos también admiten la distancia Damerau-Levenshtein:
Distancia Damerau-Levenshtein
Es una extensión de la distancia Levenshtein, que permite una operación extra: Transposición de dos caracteres adyacentes:
Ex: De TSAR a STAR
Distancia Damerau-Levenshtein = 1 (La conmutación de las posiciones S y T sólo cuesta una operación)
Distancia Levenshtein = 2 (Sustituir S por T y T por S)
Correspondencia difusa y relevancia
La concordancia difusa tiene un gran efecto secundario: estropea la relevancia. Aunque Damerau-Levenshtein es un algoritmo de concordancia difusa que tiene en cuenta la mayoría de los errores ortográficos comunes de los usuarios, también puede incluir un número significativo de falsos positivossobre todo cuando utilizamos una lengua con un media de sólo 5 letras por palabracomo el inglés. Por eso, la mayoría de los motores de búsqueda prefieren utilizar la distancia Levenshtein. Veamos un ejemplo real de concordancia difusa:
En primer lugar, vamos a utilizar este conjunto de datos de catálogos de películas. Lo recomiendo encarecidamente si quieres jugar con la búsqueda de texto completo. A continuación, busquemos películas con "Libro"en el título. Un código sencillo sería el siguiente:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book").field("title"); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
El código anterior dará los siguientes resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) The Book Thief score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 2) The Book of Eli score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 3) The Book of Life score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 4) Black Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- 5) The Jungle Book score: 4.826942606027416 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 6) The Jungle Book 2 score: 3.9411821308689627 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- |
Por defecto, los resultados no distinguen entre mayúsculas y minúsculas, pero puede cambiar fácilmente este comportamiento creando nuevos índices con diferentes analizadores.
Ahora, añadamos una capacidad de coincidencia difusa a nuestra consulta estableciendo la difusidad en 1 (distancia Levenshtein 1), lo que significa que "Libro" y "mira" tendrá la misma relevancia.
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book").field("title").fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(6)); printResults(movies); |
Y aquí está el resultado de la búsqueda difusa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Hook score: 1.1012248063242538 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 2) Here Comes the Boom score: 0.7786835148361213 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 3) Look Who's Talking Too score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 4) Look Who's Talking score: 0.7047266634351538 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- 5) The Book Thief score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 6) The Book of Eli score: 0.5228811753737184 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- |
Ahora, la película llamada "Gancho" es el primer resultado de la búsqueda, que puede no ser exactamente lo que el usuario espera en una búsqueda de "Reserve".
Cómo minimizar los falsos positivos en las búsquedas difusas
En un mundo ideal, los usuarios nunca cometerían errores tipográficos mientras buscan algo. Sin embargo, ese no es el mundo en el que vivimos, y si quieres que tus usuarios tengan una experiencia agradable, tienes que manejar al menos una distancia de edición de 1. Por lo tanto, la verdadera pregunta es: ¿Cómo podemos hacer coincidir cadenas difusas minimizando la pérdida de relevancia?
Podemos aprovechar una característica de la mayoría de los marcos de los motores de búsqueda: Una coincidencia con una distancia de edición menor suele tener una puntuación más alta. Esa característica nos permite combinar en una sola esas dos consultas con distintos niveles de imprecisión:
|
1 2 3 4 5 6 7 8 |
String indexName = "movies_index"; String word = "Book"; MatchQuery titleFuzzy = SearchQuery.match(word).fuzziness(1).field("title"); MatchQuery titleSimple = SearchQuery.match(word).field("title"); DisjunctionQuery ftsQuery = SearchQuery.disjuncts(titleSimple, titleFuzzy); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, ftsQuery).highlight().limit(20)); printResults(result); |
He aquí el resultado de la consulta difusa anterior:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
1) The Book Thief score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 2) The Book of Eli score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 3) The Book of Life score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 4) Black Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- field:title term:book fragment:[Black <mark>Book</mark>] ----------------------------- 5) The Jungle Book score: 2.398890092610849 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 6) The Jungle Book 2 score: 1.958685557004688 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- field:title term:book fragment:[The Jungle <mark>Book</mark> 2] ----------------------------- 7) National Treasure: Book of Secrets score: 1.6962714808368062 Hit Locations: field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ----------------------------- field:title term:book fragment:[National Treasure: <mark>Book</mark> of Secrets] ----------------------------- 8) American Pie Presents: The Book of Love score: 1.517191317611584 Hit Locations: field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ----------------------------- field:title term:book fragment:[American Pie Presents: The <mark>Book</mark> of Love] ----------------------------- 9) Hook score: 0.5052232518679681 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 10) Here Comes the Boom score: 0.357246781294941 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 11) Look Who's Talking Too score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 12) Look Who's Talking score: 0.32331663301992025 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- |
Como puede ver, este resultado se acerca mucho más a lo que el usuario podría esperar. Tenga en cuenta que ahora estamos utilizando una clase llamada DisjunctionQuery, las disyunciones son un equivalente a la clase "O"en SQL.
¿Qué más podríamos mejorar para reducir el efecto secundario negativo de un algoritmo de emparejamiento difuso? Analicemos de nuevo nuestro problema para saber si necesita más mejoras:
Ya sabemos que las búsquedas difusas pueden producir algunos resultados inesperados (por ejemplo, Book -> Look, Hook). Sin embargo, una búsqueda de un solo término suele ser una consulta terrible, ya que apenas nos da una pista de lo que el usuario intenta conseguir exactamente.
Ni siquiera Google, que cuenta con uno de los algoritmos de búsqueda difusa más desarrollados que existen, sabe exactamente lo que busco cuando busco "tabla":
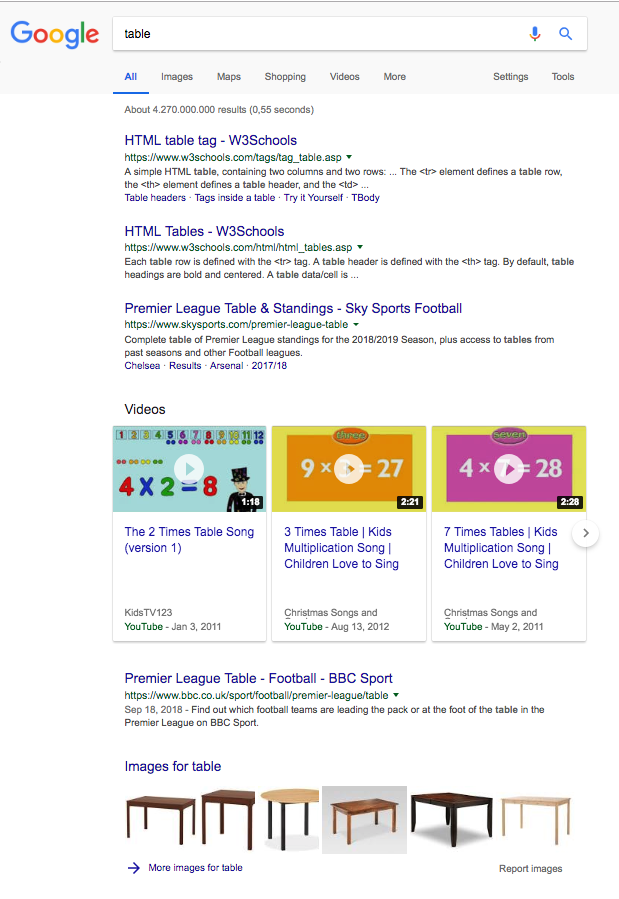
Entonces, ¿cuál es la longitud media de las palabras clave en una consulta de búsqueda? Para responder a esta pregunta, mostraré un gráfico de Presentación de Rand Fishkin en 2016. (Es uno de los gurús más famosos del mundo SEO)
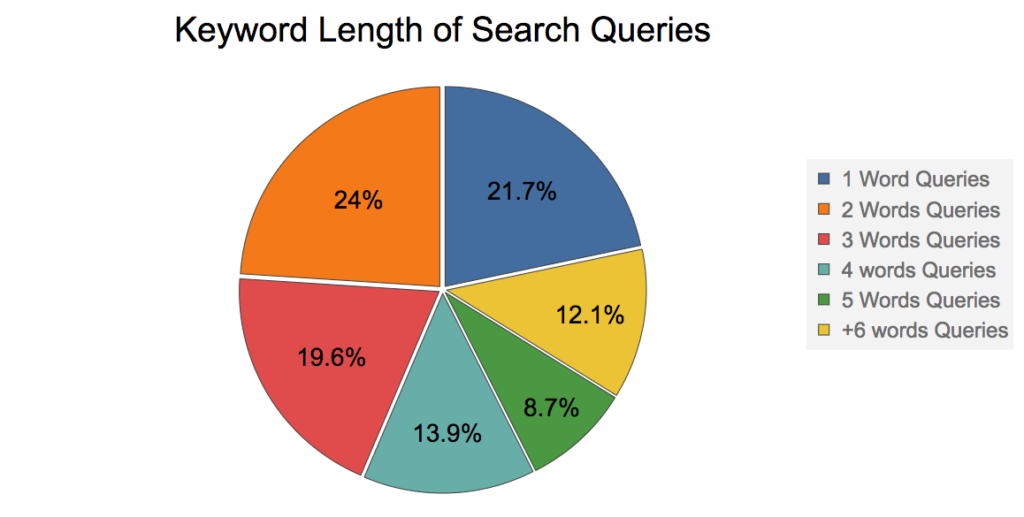
Según el gráfico anterior, ~80% de las consultas de búsqueda tienen 2 o más palabras clave, así que vamos a intentar buscar la película "Black Book" utilizando fuzziness 1:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("Black Book").field("title").fuzziness(1); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
Resultado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
1) Black Book score: 0.6946442424065404 Hit Locations: field:title term:book fragment:[<mark>Black</mark> <mark>Book</mark>] ----------------------------- field:title term:black fragment:[<mark>Black</mark> <mark>Book</mark>] ----------------------------- 2) Hook score: 0.40139742528039857 Hit Locations: field:title term:hook fragment:[<mark>Hook</mark>] ----------------------------- 3) Attack the Block score: 0.2838308365090324 Hit Locations: field:title term:block fragment:[Attack the <mark>Block</mark>] ----------------------------- 4) Here Comes the Boom score: 0.2838308365090324 Hit Locations: field:title term:boom fragment:[Here Comes the <mark>Boom</mark>] ----------------------------- 5) Look Who's Talking Too score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking Too] ----------------------------- 6) Look Who's Talking score: 0.25687349813115684 Hit Locations: field:title term:look fragment:[<mark>Look</mark> Who's Talking] ----------------------------- 7) Grosse Pointe Blank score: 0.2317469073782136 Hit Locations: field:title term:blank fragment:[Grosse Pointe <mark>Blank</mark>] ----------------------------- 8) The Book Thief score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> Thief] ----------------------------- 9) The Book of Eli score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Eli] ----------------------------- 10) The Book of Life score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The <mark>Book</mark> of Life] ----------------------------- 11) The Jungle Book score: 0.19059065534780495 Hit Locations: field:title term:book fragment:[The Jungle <mark>Book</mark>] ----------------------------- 12) Back to the Future score: 0.17061000968368 Hit Locations: field:title term:back fragment:[<mark>Back</mark> to the Future] ----------------------------- |
No está mal. Obtuvimos la película que buscábamos como primer resultado. Sin embargo, una consulta disyuntiva nos daría un conjunto de resultados mejor.
Pero aún así, parece que tenemos una nueva propiedad agradable aquí; el efecto secundario de la concordancia difusa disminuye ligeramente a medida que aumenta el número de palabras clave. Una búsqueda de "Libro negro" con desenfoque 1 todavía puede traer resultados como la mirada hacia atrás o la falta de cocinero (algunas combinaciones con la distancia de edición 1), pero estos son poco probable que sean títulos de películas reales.
Una búsqueda de "libro eli" con borrosidad 2 aún lo traería como tercer resultado:
|
1 2 3 4 5 6 |
String indexName = "movies_index"; MatchQuery query = SearchQuery.match("book eli").field("title").fuzziness(2); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(12)); printResults(movies); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
1) Ed Wood score: 0.030723793900031805 Hit Locations: field:title term:wood fragment:[<mark>Ed</mark> <mark>Wood</mark>] ----------------------------- field:title term:ed fragment:[<mark>Ed</mark> <mark>Wood</mark>] ----------------------------- 2) Man of Tai Chi score: 0.0271042761982626 Hit Locations: field:title term:chi fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- field:title term:tai fragment:[Man of <mark>Tai</mark> <mark>Chi</mark>] ----------------------------- 3) The Book of Eli score: 0.02608335441670756 Hit Locations: field:title term:eli fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ----------------------------- field:title term:book fragment:[The <mark>Book</mark> of <mark>Eli</mark>] ----------------------------- 4) The Good Lie score: 0.02439822770591834 Hit Locations: field:title term:lie fragment:[The <mark>Good</mark> <mark>Lie</mark>] ----------------------------- field:title term:good fragment:[The <mark>Good</mark> <mark>Lie</mark>] ----------------------------- |
Sin embargo, como la palabra inglesa media tiene 5 letras, me gustaría NO recomiendan utilizar una distancia de edición superior a 2 a menos que el usuario busque palabras largas y fáciles de escribir mal, como "Schwarzenegger" por ejemplo (al menos para los no alemanes o no austriacos).
Conclusión
En este artículo, hablamos de la concordancia difusa y de cómo superar su principal efecto secundario sin estropear su relevancia. Sin embargo, la concordancia difusa es sólo una de las muchas características que debe aprovechar al implementar una búsqueda relevante y fácil de usar. En esta serie hablaremos de algunas de ellas: N-Gramas, Stopwords, Steeming, Shingle, Elisión. Etc.
Consulte también el Parte 1 y Parte 2 de esta serie.
Mientras tanto, si tienes alguna pregunta, envíame un tweet a @deniswsrosa.
¿Cómo se relaciona la puntuación obtenida del índice con un porcentaje de coincidencia? ¿Cómo construir una consulta para la que la puntuación de relevancia de los resultados represente una relevancia > 50%, por ejemplo?
Si quieres saber más sobre cómo se puntúan los documentos, tanto lucene como bleve tienen el método "explain". En couchbase puede establecer explain(true) para ver exactamente cómo se calcula la puntuación.Los resultados se ordenan por defecto por puntuación, por lo que los más relevantes deberían ser los primeros de la lista. ¿Qué quieres conseguir exactamente?