Ajustar el rendimiento de las consultas de búsqueda es un aspecto muy importante del Búsqueda de texto completo ya que ayuda a las aplicaciones críticas para el negocio a cumplir los requisitos SLA de latencia y rendimiento. Sin mucho preámbulo, permítanme compartir algunas recomendaciones útiles para la solución de problemas de rendimiento de búsqueda. Todas estas sugerencias son independientes de cualquier configuración de hardware y topología de clúster, y son aplicables a la mayoría de los casos de uso de búsqueda genéricos.
Buscar en el menor número de campos posible
Esto es especialmente aplicable a determinados tipos de consultas compuestas donde el usuario intenta buscar un texto de consulta de búsqueda común en varios campos indexados.
Veamos un ejemplo de consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
"consulta": { "Conjuntos": [ { "campo": "NombreUsuario", "match": "searchText", "confusión": 1 }, { "campo": "Departamento.Nombre", "match": "searchText", "confusión": 1 }, { "campo": "SegundoNombre", "match": "searchText", "confusión": 1 }, { "campo": "NombreConsumidor", "match": "searchText" "confusión": 1 } ]} |
Si nos fijamos, en la consulta compuesta conjunct hay 4 cláusulas de búsqueda coincidentes, todas ellas con el mismo texto de búsqueda. Esto es muy ineficaz, ya que en segundo plano el sistema de búsqueda tiene que examinar un montón de datos indexados a través de diferentes campos para el mismo texto de búsqueda. Esta sobrecarga se ve agravada por la multitud de estructuras de consulta en tiempo de ejecución creadas y recogidas a través de los campos.
FTS dispone de una función que permite hacer esto de forma muy eficaz. Permite a los usuarios indexar múltiples campos del documento fuente contra un campo genérico configurable. Una vez que el usuario hace esto durante la definición del índice, puede ejecutar búsquedas en ese único campo común.
Para utilizar esta función, el usuario debe activar el Todos contra todos esos campos múltiples en la asignación de campos durante la indexación.
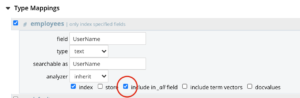
De este modo, todos los contenidos de estos campos también se indexarán en el campo por defecto Todos en el índice. Esto tiene un aspecto de almacenamiento adicional para el tamaño del índice.
Ahora el usuario debería poder realizar consultas sin especificar explícitamente el campo de destino. Y siempre que no se especifiquen campos de destino en la consulta, Full-Text Search la buscará en el campo común por defecto Todos.
Así que con la optimización anterior, la consulta anterior se convertiría en una más simple como la siguiente,
|
1 2 3 4 5 6 7 8 |
"consulta": { "Conjuntos": [ { "match": "searchText" "desenfoque" : 1, } ] } |
El rendimiento de esta consulta de búsqueda debería ser mucho más ligero y rápido en comparación con la consulta original.
Nota: Esto es aplicable si no hay aumento de la puntuación utilizado en la consulta original para las cláusulas subordinadas.
Especifique longitud_prefijo Para consultas de coincidencia difusa
Los usuarios eligen difuso consultas de coincidencia para evitar posibles errores ortográficos en los textos de búsqueda. Con el factor de difuminación, seguirían obteniendo los resultados deseados del sistema de búsqueda. Pero los usuarios difusos deben tener en cuenta que las consultas difusas consumen muchos recursos.
Cómo - En un índice FTS suficientemente grande, habrá muchos tokens candidatos que se encuentren a una determinada distancia de borrosidad/edición del texto de la consulta. Por lo tanto, una consulta difusa se convertirá en una consulta disyuntiva/OR para todos los tokens candidatos presentes en el índice. Esto da lugar a un gran despliegue interno de las operaciones de búsqueda rudimentaria, lo que resulta engorroso desde el punto de vista de los recursos.
Veamos aquí un ejemplo más sencillo para el abanico de consultas.
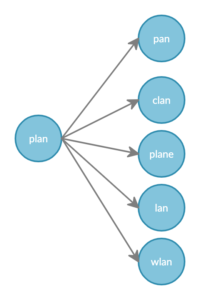
Una consulta difusa con un grado de difuminación de 1 para el texto de consulta "plan" daría como resultado un total de 6 términos buscados por debajo, como en este ejemplo. (dado que en el contenido indexado sólo están presentes los 5 términos que se encuentran a la distancia de edición o fuzziness de 1)
Una idea de optimización importante para evitar posibles errores ortográficos es que la mayoría de las faltas de ortografía se producen al final del texto, no al principio. Los usuarios pueden aprovechar este hecho y utilizar la función longitud_prefijo en las consultas difusas. Una vez que la longitud_prefijo la imprecisión sólo se tendrá en cuenta para el texto que se encuentre después del punto longitud_prefijo.
Por lo general, un longitud_prefijo de 2 ó 3 debería estar bien. Pero, ciertamente, se trata de una aplicación o caso de uso específico.
Por ejemplo:
|
1 2 3 4 5 6 7 |
{ "match": "hermosa", => "autiful" es sólo considerado para desenfoque "campo": "reviews.content", "analizador": "estándar", "confusión": 1, "longitud_prefijo": 2 } |
Esto reduce drásticamente el alcance/número de los tokens buscados en el índice para una consulta difusa determinada. Y el rendimiento de la consulta de búsqueda puede mejorarse significativamente especificando un longitud_prefijo por la confusión.
Saltar la puntuación cuando la relevancia del texto no importa
Muchas veces se observa que los usuarios utilizan la búsqueda de texto completo para las consultas de coincidencia exacta con un poco de confusión u otras funciones específicas de búsqueda como geo. La puntuación de relevancia del texto no importa cuando el usuario realiza búsquedas exactas o más específicas con muchos predicados.
En situaciones similares en las que el usuario no está interesado en la opción por defecto tf-idf pueden optimizar el rendimiento de la consulta omitiendo la puntuación. Los usuarios pueden omitir la puntuación introduciendo la opción "puntuación": "none" en la solicitud de búsqueda.
Por ejemplo:
|
1 2 3 4 5 6 |
{ "consulta": {}, "puntuación": "ninguno", "tamaño": 10, "de": 0 } |
Esto mejora significativamente el rendimiento de la consulta de búsqueda en muchos casos, especialmente para consultas compuestas con muchas cláusulas de búsqueda hijas.
Esta función está disponible desde la versión 6.6.1 del servidor Couchbase.
Paginación por teclas para búsquedas más profundas en las páginas
Como ya sabrá, la paginación de los resultados de búsqueda puede realizarse mediante la función de y talla en la petición de búsqueda. Sin embargo, a medida que la búsqueda se adentra en páginas más profundas, se vuelve más costosa. La razón principal es que los resultados de la búsqueda están ordenados por defecto por su tf-idf y la búsqueda de texto completo tiene unos requisitos de memoria de montón proporcionales al desplazamiento y al tamaño de la página solicitada. es decir de+tamaño por mantener esta clasificación.
Para protegernos contra cualquier requisito arbitrario de memoria superior, tenemos un límite configurable bleveMaxResultWindow (10000 por defecto) en el desvío de página máximo permitido. Pero elevar este límite a niveles superiores no es una solución escalable.
Para evitar este problema, hemos introducido el concepto de paginación de conjuntos de claves en FTS.
En lugar de proporcionar de como un número de resultados de búsqueda a omitir, el usuario proporcionará el valor de ordenación de un resultado de búsqueda visto anteriormente (normalmente, el último resultado mostrado en la página actual). La idea es que para mostrar la siguiente página de resultados, sólo queremos los N primeros resultados de esa ordenación después del último resultado de la página anterior.
Esta solución requiere que se cumplan algunas condiciones previas:
- La solicitud de búsqueda debe especificar un orden de clasificación.
- El orden de clasificación debe imponer un orden total a los resultados. Sin esto, cualquier resultado que comparta el mismo valor de ordenación podría quedar fuera al manejar los límites de navegación de la página. Una solución habitual es incluir siempre el ID del documento como criterio de ordenación final. Por ejemplo, si desea ordenar por ["nombre", "-edad"], en lugar de ordenar por ["nombre", "-edad", "_id"].
Por ejemplo:
El usuario busca descripción:luz y ordena por ["nombre", "_id"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "consulta": { "consulta": "descripción:luz" }, "clasificar": [ "nombre", "_id" ], "buscar_después": [ "Cerveza de verano Anchor", "anchor_brewing-anchor_summer_beer" ] } |
Existe un parámetro similar denominado buscar_antes para navegar a la página anterior de resultados. En lugar de proporcionar el valor de ordenación del último resultado, la aplicación proporciona el valor de ordenación del primer resultado de la página actual. Por lo demás, el comportamiento es el mismo.
Con las paginaciones search_after/search_before, el requisito de memoria de montón de las búsquedas de páginas más profundas se hace proporcional al tamaño de la página solicitada. De este modo, se reduce significativamente el requisito de memoria de montón de las búsquedas en páginas más profundas con respecto a los valores offset+from.
Esta función está disponible desde la versión 6.6.1 del servidor Couchbase.
Evitar cláusulas de búsqueda duplicadas en las consultas compuestas
Sabemos que parece una sugerencia ingenua. Pero a veces se observa que las aplicaciones de los clientes, al convertir las consultas de búsqueda del usuario final en una solicitud de búsqueda del backend FTS, acaban teniendo muchas cláusulas de búsqueda secundaria duplicadas en sus consultas compuestas.
Por ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
"disyuntos": [ { "campo": "merchantID", "match": "9447611071-0" }, { "campo": "merchantID", "match": "9447611071-0" }, { "campo": "merchantID", "match": "9447611071-0" }, { "campo": "merchantID", "match": "9447611071-0" } ] |
Esto daría lugar a una gran cantidad de trabajo redundante en el servidor de búsqueda de texto completo debido a la duplicación del contenido de las consultas.
Los usuarios deben ser conscientes de que el servicio de búsqueda no realizará ninguna deduplicación de las consultas dadas. Respeta y ejecuta la solicitud de consulta completa en el backend. Por lo tanto, los usuarios deben asegurarse de que las consultas se formulan de forma óptima antes de enviarlas al servicio de búsqueda.
Esté atento a este espacio para obtener más consejos sobre el ajuste del rendimiento de las consultas de búsqueda y la gestión de índices para el servicio Full-Text Search.
Otra lectura interesante sobre el análisis de textos para los novatos en FTS aquí
Análisis de textos en un motor de búsqueda de texto completo