Reenvío y procesamiento de registros con Couchbase es más fácil que nunca.
Disponemos de soporte para reenvío de registros y gestión de registros de auditoría para Couchbase Autonomous Operator (es decir, Kubernetes) y para despliegues on-prem de Couchbase Server. En ambos casos, el procesamiento de los registros se realiza mediante Bits fluidos.
¿Por qué elegimos Fluent Bit? Los usuarios de Couchbase necesitan registros en un formato común con configuración dinámica, y queríamos utilizar un estándar de la industria con una sobrecarga mínima. Fluent Bit fue una elección natural.
Este artículo cubre consejos y trucos para aprovechar al máximo el uso de Fluent Bit para el reenvío de logs con Couchbase. Utilizaré el Operador autónomo de Couchbase en mis ejemplos de despliegue. (También voy a presentar una inmersión más profunda de este post en la próxima FluentCon.)
Antes de Fluent Bit, los formatos de registro de Couchbase variaban en múltiples archivos. A continuación se muestra una sola línea de cuatro archivos de registro diferentes:
|
1 2 3 4 |
2021-03-09T17:32:25.520+00:00 DEBU CBAS.util.MXHelper [main] ignoring exception calling RuntimeMXBean.getBootClassPath; returning null java.lang.UnsupportedOperationException: Boot class path mechanism is not supported at sun.management.RuntimeImpl.getBootClassPath(Unknown Source) ~[?:?] at org.apache.hyracks.util.MXHelper.getBootClassPath(MXHelper.java:111) [hyracks-util.jar:6.6.0-7909] |
|
1 2 3 |
{"bucket":"default","description":"The specified bucket was selected","id":20492,"name":"select bucket","peername":"127.0.0.1:56021","real_userid":{"domain":"local","user":"@ns_server"},"sockname":"127.0.0.1:11209","timestamp":"2021-03-09T20:12:17.445039Z"} [ns_server:warn,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:ns_crash_log<0.102.0>:ns_crash_log:read_crash_log:148]Couldn't load crash_log from /opt/couchbase/var/lib/couchbase/logs/crash_log_v2.bin (perhaps it's first startup): {error, enoent} |
|
1 2 3 |
[error_logger:info,2021-03-09T17:31:55.401Z,babysitter_of_ns_1@cb.local:error_logger<0.32.0>:ale_error_logger_handler:do_log:203] =========================PROGRESS REPORT========================= supervisor: {local,ns_babysitter_sup} |
|
1 |
127.0.0.1 - @ [09/Mar/2021:17:32:02 +0000] "RPCCONNECT /goxdcr-cbauth HTTP/1.1" 200 0 - Go-http-client/1.1 |
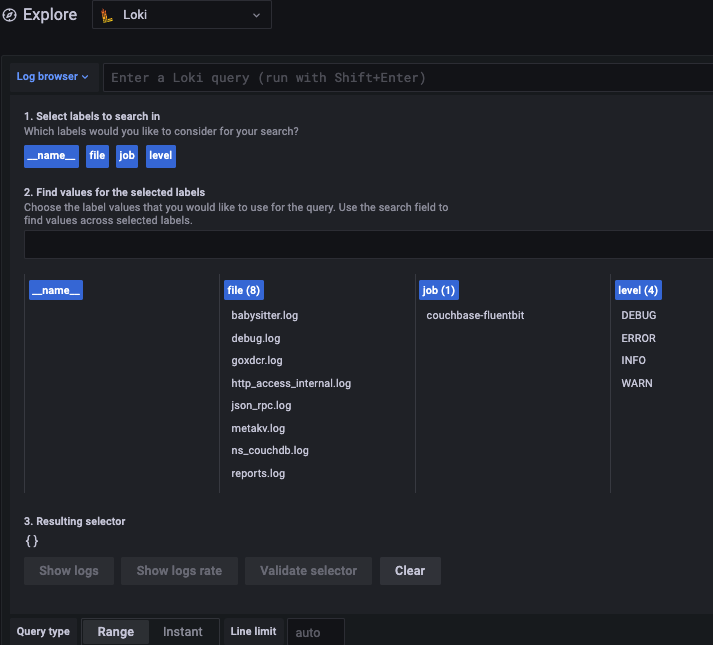
Con la actualización a Fluent Bit, ahora puede transmitir en directo las siguientes vistas de registros la arquitectura de registro estándar de Kubernetes que también significa integración sencilla con los cuadros de mando de Grafana y otras herramientas estándar del sector. A continuación se muestra una captura de pantalla tomada de la pila Loki de ejemplo que tenemos en el repositorio Fluent Bit.
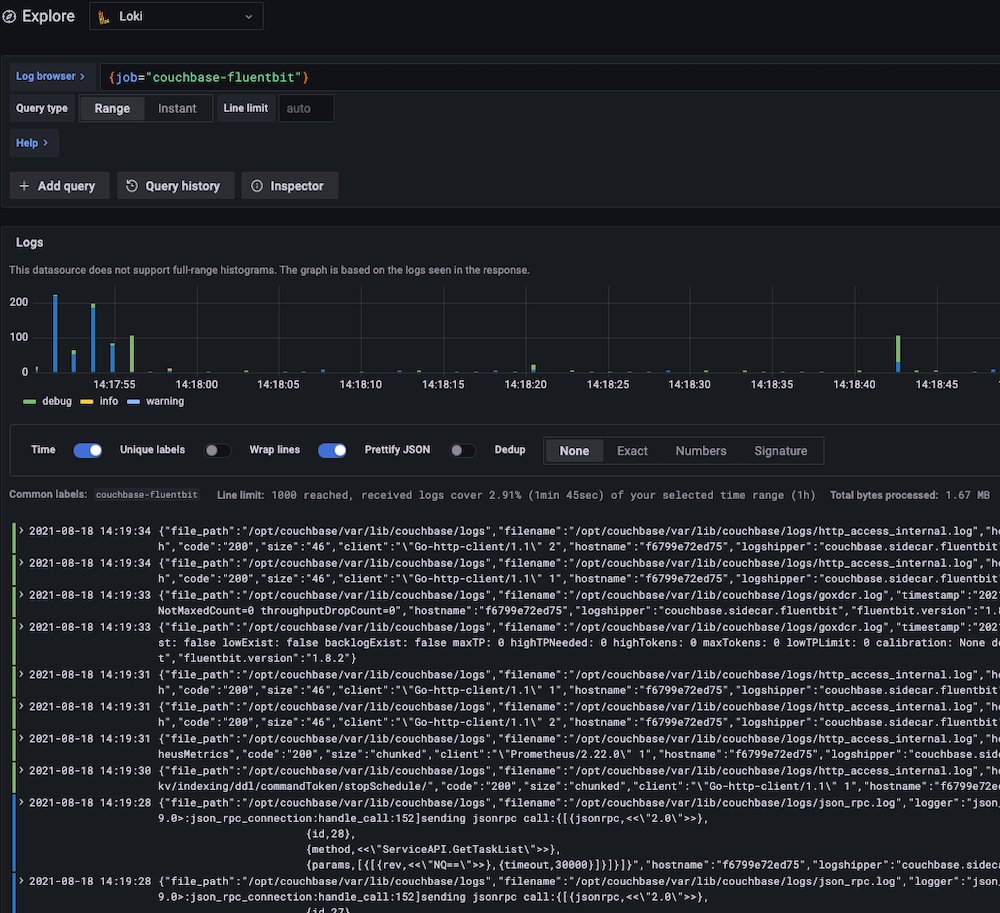
Tanto si eres nuevo en Fluent Bit como si eres un profesional experimentado, espero que este artículo te ayude a navegar por las complejidades de su uso para el procesamiento de logs con Couchbase.
¿Cuál es su principal duda o reto con Fluent Bit?
Vaya directamente a su problema o pregunta particular con Fluent Bit utilizando los enlaces de abajo o desplácese más abajo para leer todos los consejos y trucos.
¿Qué es (y por qué) Fluent Bit?
¿Cómo puedo hacer preguntas, obtener orientación o aportar sugerencias sobre Fluent Bit? Participar y contribuir a la comunidad OSS.
¿Cómo puedo averiguar qué está fallando en Fluent Bit? Utiliza el stdout y aumente el nivel de registro al depurar.
¿Cómo puedo saber si mi analizador sintáctico está fallando? Si ve la opción por defecto registro en el registro, sabrá que el análisis ha fallado..
¿Por qué no funciona mi analizador regex? Verificar y simplificar, en particular para el análisis sintáctico multilínea..
¿Cómo puedo restringir un campo (por ejemplo, el nivel de registro) a valores conocidos? Limite y normalice los valores de salida con algunos filtros sencillos.
¿Cómo añado información opcional que podría no estar presente? Utiliza el modificador_registro filtro - no el modificar filtro - si desea incluir información opcional.
¿Cómo identifico qué plugin o filtro está activando una métrica o un mensaje de registro? Utilizar alias.
¿Cómo puedo realizar un tratamiento especial o a medida (por ejemplo, una redacción parcial)? Usa el filtro Lua: ¡Puede hacerlo todo!.
¿Cómo compruebo mis cambios o verifico si una nueva versión sigue funcionando? Realización de pruebas de regresión automatizadas.
¿Cómo pruebo cada parte de mi configuración? Separe su configuración en trozos más pequeños (ventaja adicional: esto permite una reutilización personalizada más sencilla)..
¿Cómo utilizo Fluent Bit con Red Hat OpenShift?
Respondo a estas y otras muchas preguntas en el siguiente artículo. Entremos en materia.
¿Qué es (y por qué) Fluent Bit?
¿Qué es Fluent Bit? Fluent Bit es la hermana más delicada de Fluentdque son Fundación para la Computación Nativa en la Nube (CNCF) proyectos de la organización Fluent.
Fluent Bit consume esencialmente varios tipos de entrada, aplica un tubería de procesamiento a esa entrada y, a continuación, admite enrutamiento esos datos a múltiples tipos de puntos finales.
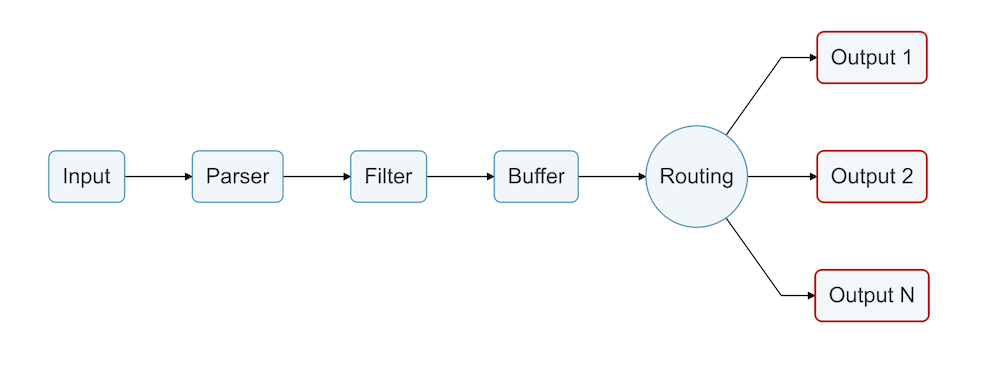
En lo que respecta a Fluentd frente a Fluent Bit, este último es una mejor opción que Fluentd para tareas más sencillas, especialmente cuando sólo necesita reenvío de registros con un procesamiento mínimo y nada más complejo.
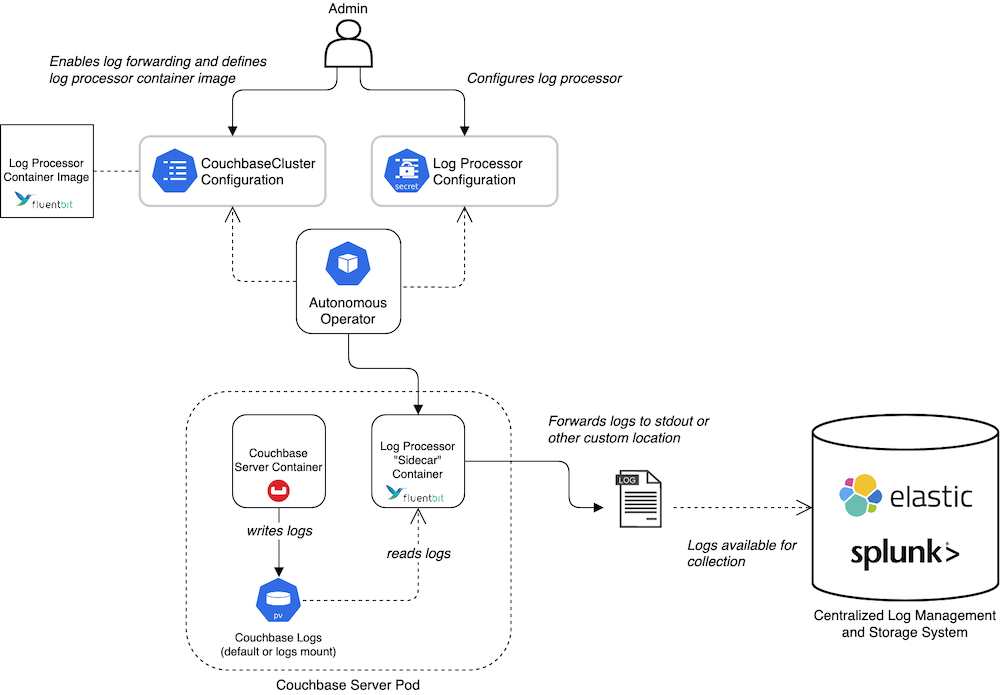
Habíamos evaluado otras opciones antes de Fluent Bit, como Logstash, Promtail y rsyslog, pero finalmente nos decidimos por Fluent Bit por varias razones. En primer lugar, es una solución OSS respaldada por el CNCF y ya se utiliza ampliamente en proveedores locales y en la nube. En segundo lugar, es ligera y también se ejecuta en OpenShift. En tercer lugar, y lo más importante, cuenta con amplias opciones de configuración para que puedas apuntar a cualquier punto final que necesites.
(Véase mi anterior artículo sobre Fluent Bit o la documentación detallada sobre el envío de registros para más información).
Consejo #1: Conectar con la comunidad OSS
Mi primera recomendación para utilizar Fluent Bit es contribuir y comprometerse con su comunidad de código abierto.
Casi todo lo que aparece en este artículo es reutilizado descaradamente de otros, ya sea de el Slack fluido, entradas de blog, Repositorios de GitHub o similares. Al mismo tiempo, he contribuido con varios analizadores sintácticos que construimos para Couchbase volver al repositorio oficialy espero haber planteado algunas cuestiones útiles.
La comunidad OSS de Fluent Bit es muy activa. Sus responsables se comunican regularmente, corrigen problemas y sugieren soluciones. Por ejemplo, FluentCon EU 2021 generó muchas sugerencias y comentarios útiles sobre nuestro uso de Fluent Bit que hemos integrado en versiones posteriores. (FluentCon suele coincidir con los eventos de la KubeCon).
Consejo #2: Depurar cuando todo está roto
En los canales de Slack de la comunidad de Fluent Bit, las preguntas más comunes son sobre cómo depurar las cosas cuando no funcionan. Mis dos recomendaciones aquí son:
- Utiliza el
stdoutplugin. - Aumente el nivel de registro para Fluent Bit.
Mi primera sugerencia sería simplificar. La mayoría de los usuarios de Fluent Bit están tratando de plomada registros en una pila más grande, por ejemplo, Elastic-Fluentd-Kibana (EFK) o... Prometheus-Loki-Grafana (PLG). Para empezar, no mires lo que te dicen Kibana o Grafana hasta que hayas eliminado todos los posibles problemas de fontanería en tu pila de elección.
Utiliza el stdout plugin para determinar qué cree Fluent Bit que es la salida. Luego, itere hasta que obtenga la salida múltiple de Fluent Bit que esperaba. Es mucho más fácil empezar aquí que lidiar con todas las partes móviles de una pila EFK o PLG.
Mi segundo consejo para depurar es subir el nivel de registro. Este paso hace obvio lo que Fluent Bit está intentando encontrar y/o analizar. En muchos casos, al aumentar el nivel de registro se ponen de manifiesto soluciones sencillas, como problemas de permisos o una ruta o comodín incorrectos.
Consideraciones para las comprobaciones de salud de Helm
Si utiliza Helm, active el servidor HTTP para las comprobaciones de estado si ha habilitado esas sondas.
Helm es buena para una instalación sencilla, pero como es una herramienta genérica, debe asegurarse de que su configuración de Helm sea aceptable. Si habilita las sondas de comprobación de estado en Kubernetes, también deberá habilitar el punto final para ellas en la configuración de Fluent Bit.
Las versiones más recientes de Fluent Bit tienen un chequeo específico (que también utilizaremos en la próxima versión del Operador Autónomo Couchbase).
Consejo #3: Convertir el agua en vino con el análisis sintáctico
Normalmente, querrás analizar tus registros después de leerlos. Yo utilizo el plugin de entrada de cola para convertir datos no estructurados en datos estructurados (por la terminología oficial).
El fracaso no es una opción
Cuando se trata de solucionar problemas de Fluent Bit, un punto clave que hay que recordar es que si falla el análisis sintáctico, obtendrá la siguiente salida. El analizador sintáctico de Fluent Bit proporciona toda la línea de registro como un único registro. Esto es una buena característica de Fluent Bit, ya que nunca se pierde información y una herramienta diferente siempre puede volver a analizarla.
Un truco útil aquí es asegurarse de que nunca tiene el valor predeterminado registro en el registro después del análisis. Si ve el icono registro sabrá que el análisis ha fallado. De lo contrario, no siempre es obvio.
Consejo #4: You Can't Handle the Truth (Multi-Line Parsing)
Análisis sintáctico multilínea es una característica clave de Fluent Bit. Algunos registros son producidos por procesos Erlang o Java que lo utilizan ampliamente.
En objetivo con análisis sintáctico multilínea es hacer un pase inicial para extraer un conjunto común de información. Para los registros de Couchbase, hemos decidido que cada entrada de registro tenga un marca de tiempo, nivel y mensaje (con mensaje siendo bastante abierto, ya que contenía todo lo que no se recogía en los dos primeros).
El nombre del archivo de registro también se utiliza como parte de la etiqueta Fluent Bit. Hemos implementado esta práctica porque es posible que desee enrutar diferentes registros a destinos separadospor ejemplo el registro de auditoría tiende a ser un requisito de seguridad:
|
1 2 3 4 5 |
@include /fluent-bit/etc/fluent-bit.conf [OUTPUT] Name s3 Match couchbase.log.audit ... |
Como se ha indicado anteriormente (y con más detalle aquí), este código sigue enviando todos los registros a la salida estándar de forma predeterminada, pero también envía los registros de auditoría a AWS S3.
Veamos otro ejemplo de análisis sintáctico multilínea con este tutorial (y en GitHub aquí):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[INPUT] Name tail Alias erlang_tail # ^See note 1 below Path ${COUCHBASE_LOGS}/babysitter.log,${COUCHBASE_LOGS}/couchdb.log,${COUCHBASE_LOGS}/debug.log,${COUCHBASE_LOGS}/json_rpc.log,${COUCHBASE_LOGS}/metakv.log,${COUCHBASE_LOGS}/ns_couchdb.log,${COUCHBASE_LOGS}/reports.log Multiline On Parser_Firstline couchbase_erlang_multiline Refresh_Interval 10 # ^See note 2 Skip_Long_Lines On # ^See note 3 Skip_Empty_Lines On # ^See note 4 Path_Key filename # ^See note 5 # We want to tag with the name of the log so we can easily send named logs to different output destinations. # This requires a bit of regex to extract the info we want. Tag couchbase.log. Tag_Regex ${COUCHBASE_LOGS}/(?[^.]+).log$ # ^See note 6 |
Notas:
[1] Especifica un alias para este plugin de entrada. Esto es muy útil si algo tiene un problema o para realizar un seguimiento de las métricas.
[2] La lista de registros se actualiza cada 10 segundos para recoger los nuevos.
[3] Si llega a una línea larga, esto la omitirá en lugar de detener cualquier otra entrada. Recuerde que Fluent Bit comenzó como una solución embebida, por lo que una gran cantidad de soporte de límites estáticos está en su lugar por defecto.
[4] Una adición reciente a la versión 1.8 fue la posibilidad de omitir las líneas vacías. Esta opción está activada para reducir el ruido y garantizar que las pruebas automatizadas sigan pasando.
[5] Asegúrese de añadir la etiqueta Fluent Bit filename en el registro. Esto es útil para filtrar.
[6] Etiqueta por nombre de fichero. En este caso usamos una regex para extraer el nombre del archivo ya que estamos trabajando con múltiples archivos.
Una recomendación obvia es asegurarse de que su regex funciona mediante pruebas. Puede utilizar una herramienta en línea como:
-
- Rubular
- RegEx101
- Calyptia (Calyptia también dispone de una herramienta de visualización, y he una secuencia de comandos para tratar los archivos incluidos para raspar todo en un solo archivo pasable.)
Es importante tener en cuenta que, como siempre, existen aspectos específicos en el motor regex utilizado por Fluent Bit, por lo que, en última instancia, también deberá realizar pruebas allí. Por ejemplo, asegúrese de que nombrar adecuadamente los grupos (sólo alfanumérico más guión bajo, sin guiones), ya que de lo contrario podría causar problemas.
Sugerencia: Si la expresión regular no funciona, a pesar de que debe - simplificar las cosas hasta que lo haga.
El ejemplo anterior de analizador sintáctico multilínea de Fluent Bit manejaba los mensajes Erlang, que tenían este aspecto:
|
1 2 |
[ns_server:info,2021-03-09T17:31:55.351Z,babysitter_of_ns_1@cb.local:<0.92.0>:ns_babysitter:init_logging:136]Brought up babysitter logging [ns_server:debug,2021-03-09T17:31:55.373Z,babysitter_of_ns_1@cb.local:<0.92.0>:dist_manager:configure_net_kernel:293]Set net_kernel vebosity to 10 -> 0 |
Este fragmento sólo muestra mensajes de una línea por motivos de brevedad, pero también hay mensajes de ejemplos grandes de varias líneas en las pruebas. Recuerde que el analizador sintáctico busca los corchetes para indicar el inicio de cada mensaje de registro, posiblemente de varias líneas:
|
1 2 3 4 5 6 7 |
[PARSER] Name couchbase_erlang_multiline Format regex Regex \[(?\w+):(?\w+),(?\d+-\d+-\d+T\d+:\d+:\d+.\d+Z),(?.*)$ Time_Key timestamp Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On |
Complicaciones y consideraciones sobre el análisis de marcas de tiempo
Desafortunadamente, no se puede tener una regex completa para la directiva marca de tiempo campo. Si tiene varios formatos de fecha y hora, le resultará difícil. Por ejemplo, puede encontrar los siguientes formatos de fecha y hora dentro del mismo archivo de registro:
|
1 2 |
2021-03-09T17:32:15.545+00:00 [INFO] Using ... 2021/03/09 17:32:15 audit: ... |
En el momento del lanzamiento de la versión 1.7, no había una buena manera de analizar los formatos de fecha y hora en una sola pasada. Así que para los registros de Couchbase, diseñamos Fluent Bit para ignorar cualquier fallo al analizar la marca de tiempo del registro y sólo usamos la hora de análisis como valor para Fluent Bit. La hora real no es vital, y debería ser lo suficientemente cercana.
El análisis multiformato en la serie Fluent Bit 1.8 debería ser capaz de soportar un mejor análisis de marcas de tiempo. Pero en el momento de escribir esto, Couchbase aún no utiliza esta funcionalidad. El siguiente fragmento muestra un ejemplo de análisis multiformato:
|
1 2 3 4 5 6 7 8 9 10 |
# Cope with two different log formats, e.g.: # 2021/03/09 17:32:15 cbauth: ... # 2021-03-09T17:32:15.303+00:00 [INFO] ... # https://rubular.com/r/XUt7xQqEJnrF2M [PARSER] Name couchbase_simple_log_mixed Format regex Regex ^(?\d+(-|/)\d+(-|/)\d+(T|\s+)\d+:\d+:\d+(\.\d+(\+|-)\d+:\d+|))\s+((\[)?(?\w+)(\]|:))(?.*)$ Time_Key timestamp Time_Keep On |
Otra cosa que hay que tener en cuenta es que las pruebas de regresión automatizadas son imprescindibles.
Tip #5: Bateo de Oro con Filtración
Soy un gran fan de la pila Loki/Grafanapor lo que lo utilicé ampliamente cuando probaba el reenvío de registros con Couchbase.
Un problema con la versión original del contenedor Couchbase era que los niveles de registro no estaban estandarizados: podías obtener cosas como INFO, Información, información con diferentes casos o DEBU, depurar, etc. con diferentes cadenas reales para el mismo nivel. Esta falta de estandarización dificultaba la visualización y el filtrado en Grafana (o la herramienta que elijas) sin un procesamiento adicional.
Basado en una sugerencia de un usuario de Slack, He añadido algunos filtros que restringen efectivamente todos los diversos niveles en un nivel utilizando la siguiente enumeración: DESCONOCIDO, DEBUG, INFO, AVISO, ERROR. Estos filtros de Fluent Bit parten primero de los distintos casos de esquina y se aplican después para que todos los niveles sean coherentes.
Funciona de la siguiente manera: Cada vez que un campo fijo a un valor conocido, se añade una clave temporal adicional a la misma. Esta clave temporal la excluye de cualquier otra coincidencia en este conjunto de filtros. La dirección se retira la llave temporal al final. Vea a continuación un ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[FILTER] Name modify Alias handle_levels_uppercase_error_modify Match couchbase.log.* Condition Key_value_matches level (?i:ERRO\w*) Set level ERROR # Make sure we don't re-match it Condition Key_value_does_not_equal __temp_level_fixed Y Set __temp_level_fixed Y … # Remove all "temp" vars here [FILTER] Name modify Alias handle_levels_remove_temp_vars_modify Match couchbase.log.* Remove_regex __temp_.+ |
Al final, el conjunto restringido de salida es mucho más fácil de usar.
Consejo #6: Cómo añadir información opcional
Una cosa que probablemente querrás incluir en tus logs de Couchbase son datos extra si están disponibles.
Para mis propios proyectos, utilicé inicialmente el bit de fluidez modificar filtro para añadir claves adicionales al registro. Sin embargo, si no se definen determinadas variables, la función modificar el filtro saldría.
Más tarde descubrí que utilizar el modificador_registro filtro en su lugar. Este filtro le avisa si una variable no está definida, por lo que puede utilizarlo con un superconjunto de la información que desea incluir.
En resumen: Si desea añadir información opcional al reenvío de registros, utilice modificador_registro en lugar de modificar.
He incluido un ejemplo de modificador_registro abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[FILTER] Name record_modifier Alias common_info_modifier Match couchbase.log.* Record hostname ${HOSTNAME} Record logshipper couchbase.sidecar.fluentbit # These should be built into the container Record couchbase.logging.version ${COUCHBASE_FLUENTBIT_VERSION} Record fluentbit.version ${FLUENTBIT_VERSION} # The following are set by the operator from the pod meta-data, they may not exist on normal containers Record pod.namespace ${POD_NAMESPACE} Record pod.name ${POD_NAME} Record pod.uid ${POD_UID} # The following come from kubernetes annotations and labels set as env vars so also may not exist Record couchbase.cluster ${couchbase_cluster} Record couchbase.operator.version ${operator.couchbase.com/version} Record couchbase.server.version ${server.couchbase.com/version} Record couchbase.node ${couchbase_node} Record couchbase.node-config ${couchbase_node_conf} Record couchbase.server ${couchbase_server} # These are config dependent so will trigger a failure if missing but this can be ignored Record couchbase.analytics ${couchbase_service_analytics} Record couchbase.data ${couchbase_service_data} Record couchbase.eventing ${couchbase_service_eventing} Record couchbase.index ${couchbase_service_index} Record couchbase.query ${couchbase_service_query} Record couchbase.search ${couchbase_service_search} |
También utilizo el filtro Nest para consolidar todos los couchbase.* y vaina.* en estructuras JSON anidadas para su salida. Usando el filtro Nest, todas las operaciones posteriores se simplifican porque la información específica de Couchbase está en una única estructura anidada, en lugar de tener que analizar todo el registro de logs. Esto es similar para la información de pods, que puede faltar para la información on-premise.
Consejo #7: Utilice alias
Otro consejo valioso que ya habrás notado en los ejemplos hasta ahora: utilizar alias.
Cuando utiliza un alias para un filtro específico (o entrada/salida), tiene un nombre legible en sus registros y métricas de Fluent Bit en lugar de un número que es difícil de descifrar. Le recomiendo que cree un proceso de nomenclatura de alias según la ubicación y la función del archivo.
La documentación de Fluent Bit le muestra cómo acceder a las métricas en formato Prometheus con varios ejemplos.
Ejecutar con la imagen Couchbase Fluent Bit muestra la siguiente salida en lugar de sólo cola.0, cola.1 o similar con los filtros:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# HELP fluentbit_filter_drop_records_total Fluentbit metrics. # TYPE fluentbit_filter_drop_records_total counter fluentbit_filter_drop_records_total{name="common_info_modifier"} 0 1629194033696 fluentbit_filter_drop_records_total{name="couchbase_common_info_nest"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_filenames_add_missing_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_info_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_add_unknown_missing_level_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_check_for_incorrect_level"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_remove_temp_vars_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_debug_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_error_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_info_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_levels_uppercase_warn_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_filename_in_log_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_message_unknown_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_msg_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_tail_filename_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="handle_logfmt_ts_modify"} 0 1629194033696 fluentbit_filter_drop_records_total{name="parser.16"} 0 1629194033696 fluentbit_filter_drop_records_total{name="pod_common_info_nest"} 0 1629194033696 # HELP fluentbit_input_bytes_total Number of input bytes. # TYPE fluentbit_input_bytes_total counter fluentbit_input_bytes_total{name="audit_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="erlang_tail"} 691360 1629194033696 fluentbit_input_bytes_total{name="http_tail"} 4302 1629194033696 fluentbit_input_bytes_total{name="java_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="memcached_tail"} 10623 1629194033696 fluentbit_input_bytes_total{name="prometheus_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="rebalance_process_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_mixed_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="simple_tail"} 0 1629194033696 fluentbit_input_bytes_total{name="xdcr_tail"} 26544 1629194033696 |
Y si algo va mal en los registros, no tienes que perder tiempo averiguando qué plugin puede haber causado un problema basándote en su ID numérico.
Otra consideración con los alias
Si usas Loki, como yo, puede que te encuentres con otro problema con los alias.
En mi caso, estaba filtrando el archivo de registro utilizando el nombre del archivo. Mientras que el plugin tail rellena automáticamente el nombre de archivo, desafortunadamente incluye el campo ruta completa del nombre del archivo. Pero Grafana muestra sólo la primera parte de la cadena de nombre de archivo hasta que se recorta, lo que es particularmente poco útil ya que todos los registros están en la misma ubicación de todos modos.
El resultado final es una experiencia frustrante, como puedes ver a continuación.
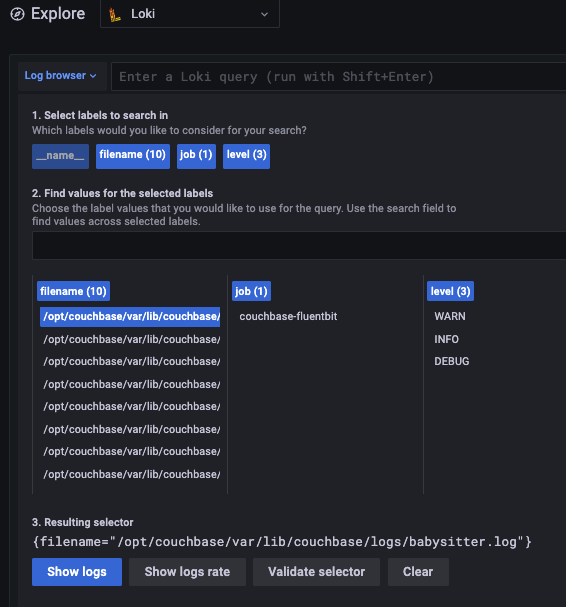
Para resolver este problema, He añadido un filtro adicional que proporciona un nombre de archivo abreviado y mantiene el original también. Este filtro requiere un analizador sintáctico sencillo, que he incluido a continuación:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[PARSER] Name couchbase_filename_shortener Format regex Regex ^(?.*)/(?.*)$ [FILTER] Name parser Match couchbase.log.* Key_Name filename Parser couchbase_filename_shortener # Do not overwrite original field Preserve_Key On # Keep everything else Reserve_Data On |
Con este analizador en su lugar, se obtiene un filtro simple con entradas como registro.auditoría, niñera.logetc. en lugar de prefijos de ruta completa como /opt/couchbase/var/lib/couchbase/logs/.
Consejo #8: Filtro Lua: Todo tu (sofá)base nos pertenece
El bit de fluidez Filtro Lua puede resolver prácticamente todos los problemas. Pero la cuestión es, ¿Debería?
La imagen de Couchbase Fluent Bit incluye un poco de código Lua para soporte de redacción mediante hashing para campos específicos en los registros de Couchbase. El objetivo de esta redacción es reemplazar datos identificables con un hash que pueda ser correlacionado a través de los registros para propósitos de depuración sin filtrar la información original. Usando un filtro Lua, Couchbase redacta los registros en vuelo mediante un hash SHA-1 del contenido de todo lo que esté rodeado de etiquetas .. en el mensaje de registro.
En la FluentCon EU de este año, Mike Marshall presentó algunas sugerencias para utilizar filtros Lua con Fluent Bit. incluyendo un Lua especial te filtro que te permite pinchar en varios puntos de tu pipeline para ver qué está pasando. Se trata de un filtro genérico que vuelca todos los pares clave-valor en ese punto del proceso, lo que resulta útil para crear una vista del antes y el después de un campo concreto.
Consejo #9: Probar, probar y volver a probar
Dadas todas estas capacidades, la configuración de Couchbase Fluent Bit es muy amplia. Echa un vistazo a la siguiente imagen que muestra la configuración de la versión 1.1.0 utilizando el visualizador de Calyptia.
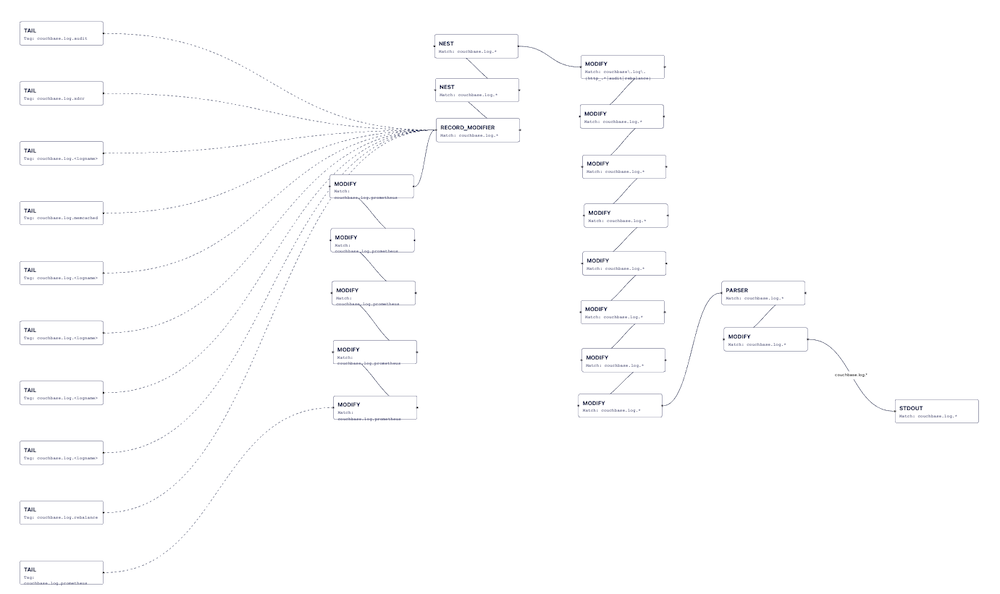
Dado el tamaño de esta configuración, el equipo de Couchbase ha hecho muchas pruebas para asegurarse de que todo se comporta como se espera. De todas esas pruebas, he creado conjuntos de ejemplos de mensajes problemáticos y los distintos formatos de cada archivo de registro para usar como un conjunto de pruebas automatizadas con los resultados esperados. También construí un contenedor de pruebas que ejecuta todas estas pruebas; es un contenedor de producción con scripts y datos de prueba superpuestos. A medida que el equipo encuentre nuevos problemas, ampliaré los casos de prueba.
Estas herramientas también le ayudan a realizar pruebas para mejorar el rendimiento. Por ejemplo, si está acortar el nombre del archivopuede utilizar estas herramientas para verlo directamente y confirmar que funciona correctamente.
Consejo #10: Separe sus áreas de preocupación
Cada parte de la configuración de Couchbase Fluent Bit se divide en un archivo separado. Hay un archivo por cada plugin de cola, un archivo para cada conjunto de filtros comunes, y uno para cada plugin de salida. Lo he diseñado de esta manera por dos razones principales:
- Reutilización sencilla de distintas configuraciones
- Pruebas
Couchbase proporciona una configuración por defecto, pero es probable que desee ajustar lo que los registros que desea analizar y cómo. Puedes usar @incluir la parte específica de la configuración que deseaPor ejemplo, si sólo desea el análisis y la salida de los registros de auditoría, puede incluir sólo eso. No hay necesidad de escribir la configuración directamente, lo que le ahorra esfuerzo en el aprendizaje de todas las opciones y reduce los errores.
Esta configuración dividida también simplifica las pruebas automatizadas. Por ejemplo, puede incluya la configuración de cola y, a continuación, añada un leer_desde_cabeza para que lea todas las entradas. He mostrado esto a continuación
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
cat > "$testConfig" << __FB_EOF @include /fluent-bit/test/conf/test-service.conf # Now we include the configuration we want to test which should cover the logfile as well. # We cannot exit when done as this then pauses the rest of the pipeline so leads to a race getting chunks out. # https://github.com/fluent/fluent-bit/issues/3274 # Instead we rely on a timeout ending the test case. @include $i Read_from_head On @include /fluent-bit/test/conf/test-filters.conf @include /fluent-bit/test/conf/test-output.conf __FB_EOF |
Una advertencia: asegúrese de probar también la configuración global. Hace poco me encontré con un problema por un error tipográfico en el nombre del include cuando se utiliza en la configuración general. Añadir una llamada a -- recogió esto en las pruebas automatizadas, como se muestra a continuación:
|
1 |
if "${COUCHBASE_LOGS_BINARY}" --dry-run --config="$i"; then |
Esto valida que la configuración es lo suficientemente correcta como para pasar las comprobaciones estáticas. Tenga en cuenta que aún puede haber fallos durante el tiempo de ejecución cuando se cargan determinados plugins con esa configuración. En esos casos, aumentar el nivel de registro normalmente ayuda (ver Consejo #2 más arriba).
Esperar lo inesperado durante las pruebas
Al realizar pruebas o solucionar problemas en Fluent Bit, es importante recordar que cada mensaje de registro debe contener ciertos campos (como mensaje, nively marca de tiempo) y no otros (como registro).
Esta distinción es especialmente útil cuando se quiere probar con una nueva entrada de registro pero no se dispone de una salida dorada con la que comparar. Por ejemplo, si está probando una nueva versión de Couchbase Server y está produciendo registros ligeramente diferentes. Mi recomendación es utilizar el Espere plugin para salir cuando se encuentra una condición de fallo y desencadenar un fallo de la prueba de esa manera.
Lamentablemente Fluent Bit actualmente sale con un código 0 incluso en caso de fallo, por lo que es necesario analizar la salida para comprobar por qué ha salido. También debe ejecutar con un tiempo de espera en este caso en lugar de un exit_when_done. De lo contrario provocar una salida en cuanto el fichero de entrada llegue al final que podría ser antes de que haya vaciado toda la salida a diff contra:
|
1 2 3 4 |
timeout -s 9 "${EXPECT_TEST_TIMEOUT}" "${COUCHBASE_LOGS_BINARY}" --config "$testConfig" > "$testLog" 2>&1 # Currently it always exits with 0 so we have to check for a specific error message. # https://github.com/fluent/fluent-bit/issues/3268 if grep -iq -e "exception on rule" -e "invalid config" "$testLog" ; then |
También tengo que mantener el script de prueba funcional tanto para Busybox (el contenedor oficial de depuración) y UBI (el contenedor de Red Hat) que a veces limita las capacidades de Bash o los binarios extra utilizados.
Sugerencia #11: Cómo utilizar Fluent Bit con Red Hat OpenShift
Hay un Operador Autónomo Couchbase para Red Hat OpenShift que exige que todos los contenedores pasen varias comprobaciones para su certificación. Una de estas comprobaciones es que la imagen base sea UBI o RHEL.
El equipo de Couchbase utiliza la imagen oficial de Fluent Bit para todo excepto OpenShift, y nosotros construirlo desde el código fuente en una imagen base UBI para el catálogo de contenedores de Red Hat. Lo construimos desde el código fuente para que se especifique el número de versión, ya que actualmente el repositorio Yum sólo proporciona la versión más reciente. Además, es un objetivo CentOS 7 RPM que infla la imagen si se despliega con todos los RPM de soporte adicionales para ejecutarse en UBI 8.
Hay un ejemplo en el repositorio que le muestra cómo utilizar directamente los RPM también.
Conclusión
Espero que estos consejos y trucos te hayan ayudado a utilizar mejor Fluent Bit para el reenvío de logs y la gestión de logs de auditoría con Couchbase.
Elegimos Fluent Bit para que sus registros de Couchbase tuvieran un formato común con configuración dinámica. También queríamos utilizar un estándar del sector con una sobrecarga mínima para facilitar las cosas a usuarios como tú.
Si te interesa saber más, presentaré este mismo contenido en mayor profundidad en la próxima FluentCon. Espero verle allí.
Descargue Couchbase Server 7 hoy mismo
