Nueva caché estándar, semántica y conversacional con integración de LangChain
En el panorama en rápida evolución del desarrollo de aplicaciones de IA, la integración de grandes modelos lingüísticos (LLM) con fuentes de datos empresariales se ha convertido en un aspecto fundamental. La capacidad de aprovechar la potencia de los LLM para generar respuestas de alta calidad y contextualmente relevantes está transformando diversos sectores. Sin embargo, los equipos se enfrentan a importantes retos a la hora de ofrecer respuestas fiables a gran velocidad y reducir costes, especialmente a medida que aumenta el volumen de peticiones de los usuarios. Además, como la mayoría de los LLM tienen una memoria limitada, existe la oportunidad de almacenar las conversaciones de los LLM durante un periodo de tiempo prolongado y evitar que los usuarios tengan que volver a empezar desde cero cuando se agote la memoria de un LLM.
Couchbase, líder en almacenamiento en caché altamente escalable y de baja latencia (Lea el artículo de LinkedIn), aborda estos retos con soluciones innovadoras. Las nuevas mejoras de nuestra oferta de búsqueda vectorial y almacenamiento en caché, así como un paquete LangChain dedicado para desarrolladores, facilitan la elevación del rendimiento y la fiabilidad de las aplicaciones de IA generativa.
Búsqueda vectorial en Couchbase y generación mejorada de recuperación (RAG)
La búsqueda vectorial de Couchbase permite a los usuarios encontrar objetos similares sin necesidad de tener una coincidencia exacta. Se trata de una función avanzada que permite buscar y recuperar datos de forma eficiente basándose en incrustaciones vectoriales, que son representaciones matemáticas de objetos en un gran número de dimensiones. Por ejemplo, buscar en un catálogo de productos zapatos "marrones" y "de cuero" devolvería esos resultados, así como zapatos "de ante", con colores como "caoba, castaño, café, bronce, castaño rojizo y cacao".
Retrieval-augmented generation (RAG) combina la búsqueda vectorial, recuperando información de la base de datos Couchbase relacionada con la petición del usuario, y ofrece tanto la petición como la información relevante relacionada. a un modelo generativo para producir respuestas LLM más informadas y adecuadas al contexto. Esto suele ser más rápido y menos costoso que entrenar un modelo personalizado. Couchbase arquitectura en memoria altamente escalable proporciona un acceso rápido y eficiente a la búsqueda de datos de incrustación vectorial relevantes. Para aumentar el rendimiento y la eficiencia de una aplicación RAG, los desarrolladores pueden utilizar funciones de caché semántica y conversacional.
Caché semántico
La caché semántica es una sofisticada técnica de caché que utiliza incrustaciones vectoriales para comprender el contexto y la intención de las consultas. A diferencia de los métodos de caché tradicionales, que se basan en coincidencias exactas, el caché semántico aprovecha el significado y la relevancia de los datos. Esto significa que preguntas similares, que de otro modo obtendrían la misma respuesta de un LLM, no necesitan hacer peticiones adicionales al LLM. Siguiendo con el ejemplo anterior, un usuario que buscara "Busco zapatos de piel marrón de la talla 10" obtendría los mismos resultados que otro usuario que solicitara "Quiero comprar zapatos de piel de la talla 10 de color marrón".

Entre las ventajas de la caché semántica, especialmente en volúmenes más elevados, se incluyen:
- Mayor eficacia - Tiempos de recuperación más rápidos gracias a la comprensión del contexto de la consulta
- Costes más bajos - La reducción de llamadas al LLM ahorra tiempo y dinero
Caché conversacional
Mientras que la caché semántica reduce el número de llamadas a un LLM a través de una amplia variedad de usuarios, una caché conversacional mejora la experiencia general del usuario ampliando el conocimiento conversacional de por vida de las interacciones entre el usuario y el LLM. Al aprovechar el historial de preguntas y respuestas, el LLM puede proporcionar un mejor contexto a medida que se envían nuevas solicitudes.
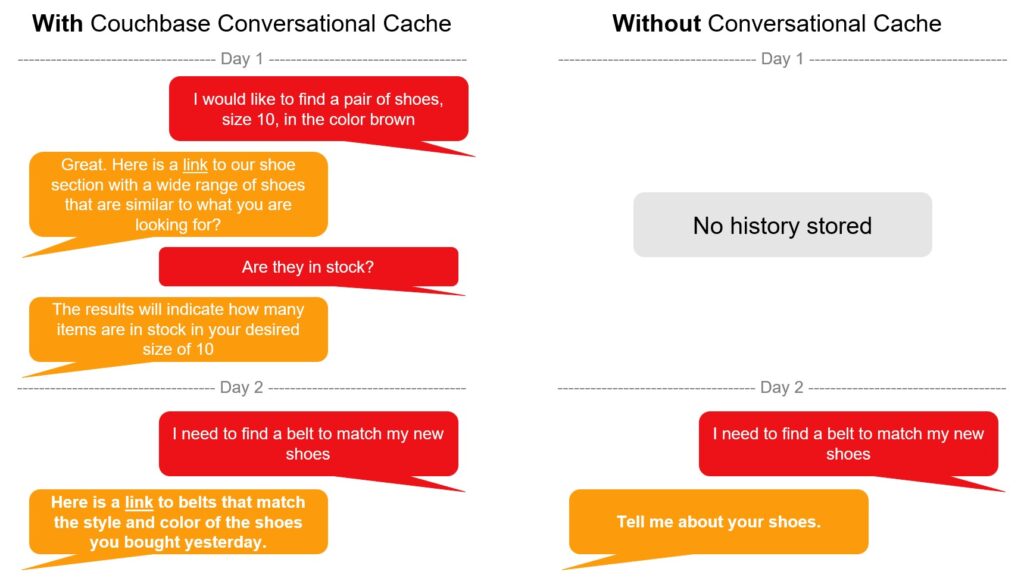
Además, la caché conversacional puede utilizarse para ayudar a aplicar el razonamiento a los flujos de trabajo de los agentes de IA. Un usuario puede preguntar: "¿Qué tal funcionará este artículo con los productos que he comprado anteriormente?". En primer lugar, esto requiere la resolución de la referencia "este artículo" seguida de un razonamiento sobre cómo determinar lo bien que funcionará con compras anteriores."
Paquetes LangChain-Couchbase dedicados
Couchbase ha introducido recientemente módulos LangChain diseñados para desarrolladores Python. Este paquete simplifica la integración de las capacidades avanzadas de Couchbase en aplicaciones de IA generativa a través de LangChain, facilitando a los desarrolladores la implementación de potentes funciones como la búsqueda vectorial y el almacenamiento semántico en caché.
El paquete LangChain-Couchbase integra a la perfección las capacidades de búsqueda vectorial, caché semántico y caché conversacional de Couchbase en flujos de trabajo de IA generativa. Esta integración permite a los desarrolladores crear aplicaciones más inteligentes y conscientes del contexto con el mínimo esfuerzo.
Al proporcionar un paquete dedicado, Couchbase garantiza que los desarrolladores puedan acceder fácilmente a funciones avanzadas e implementarlas sin tener que lidiar con configuraciones complejas. El paquete está diseñado para ser fácil de usar por los desarrolladores, lo que permite una integración rápida y eficiente.
Características principales
El paquete LangChain-Couchbase ofrece varias funciones clave, entre ellas:
-
- Búsqueda vectorial - Recuperación eficiente de datos basada en incrustaciones vectoriales
- Caché estándar - Para coincidencias exactas más rápidas
- Caché semántico - Caché contextual para mejorar la pertinencia de la respuesta
- Caché de conversación - Gestión del contexto de la conversación para mejorar las interacciones de los usuarios
Casos prácticos y ejemplos
Las nuevas mejoras de Couchbase pueden aplicarse en varios escenarios, como:
-
- Chatbots de comercio electrónico - Ofrecer recomendaciones de compra personalizadas basadas en las preferencias del usuario
- Atención al cliente - Respuestas precisas y contextualizadas a las consultas de los clientes
Fragmentos de código o tutoriales
Los desarrolladores pueden encontrar fragmentos de código y tutoriales para implantar la caché semántica y el paquete LangChain-Couchbase en Sitio web de LangChain. También hay ejemplos de código de búsqueda vectorial en Couchbase's Repositorio GitHub. Estos recursos proporcionan orientación para ayudar a los desarrolladores a empezar rápidamente.
Beneficios
Las mejoras de Couchbase en la búsqueda vectorial y las ofertas de almacenamiento en caché para aplicaciones basadas en LLM proporcionan numerosos beneficios, incluyendo una mayor eficiencia, relevancia y personalización de las respuestas. Estas características están diseñadas para hacer frente a los desafíos de la construcción de aplicaciones de IA generativa fiables, escalables y rentables.
Couchbase está comprometido con la innovación continua, asegurando que nuestra plataforma permanezca a la vanguardia del desarrollo de aplicaciones de IA. Las futuras mejoras ampliarán aún más las capacidades de Couchbase, permitiendo a los desarrolladores crear aplicaciones aún más avanzadas e inteligentes.
Recursos adicionales
-
- Blog: Visión general de RAG
- Docs: Instalar la integración Langchain-Couchbase
- Docs: Couchbase como almacén vectorial con LangChain
- Vídeo: Búsqueda vectorial e híbrida
- Vídeo: Búsqueda vectorial para aplicaciones móviles
- Docs: Búsqueda vectorial en Capella DBaaS
- Modelos compatibles con LangChain y Couchbase
