Una de las muchas ventajas de utilizar una base de datos basada en documentos como Couchbase es la capacidad de utilizar un modelo de datos flexible para almacenar datos sin las restricciones de un esquema rígido y predeterminado. Muchos clientes eligen una base de datos NoSQL para soportar la ingestión de datos de múltiples fuentes. Pero, ¿qué ocurre si necesita que los datos se transformen para que coincidan con los existentes? Tal vez los necesite en un formato uniforme para la elaboración de informes. Sea cual sea la razón, este es un uso perfecto para la base de datos Servicio de concursos en Couchbase.
Servicio de eventos Couchbase
El servicio de eventos es una característica integrada de Couchbase Enterprise Edition que permite la aplicación de funciones JavaScript, o lambdasque responden a los eventos de mutación. Cada vez que se crea, modifica o elimina un documento, se puede realizar una acción por ejecutar lógica de negocio pura en JavaScript. Hay una serie de acciones que pueden llevarse a cabo, como el enriquecimiento de datos, la llamada a flujos de trabajo externos (mediante llamadas a API RESTful) y eventos basados en temporizadores (reanudación de la ejecución en el futuro). Piense en los eventos como una base de datos heredada postgatillo con esteroides.
Consolidación de datos
En este ejemplo simplificado, imagine que acaba de adquirir dos nuevas fuentes de datos de clientes. Estos datos pueden proceder de una fuente normalizada, de un archivo plano o de ambos, y desea que coincidan con los datos de clientes existentes almacenados en un formato desnormalizado.
La primera fuente de datos es una base de datos normalizada (limpio y preciso) que contiene clientes de Canadá. Cada registro de cliente apunta a una dirección de facturación y otra de envío, y cada dirección está normalizada para eliminar la redundancia de datos de ciudad y provincia:
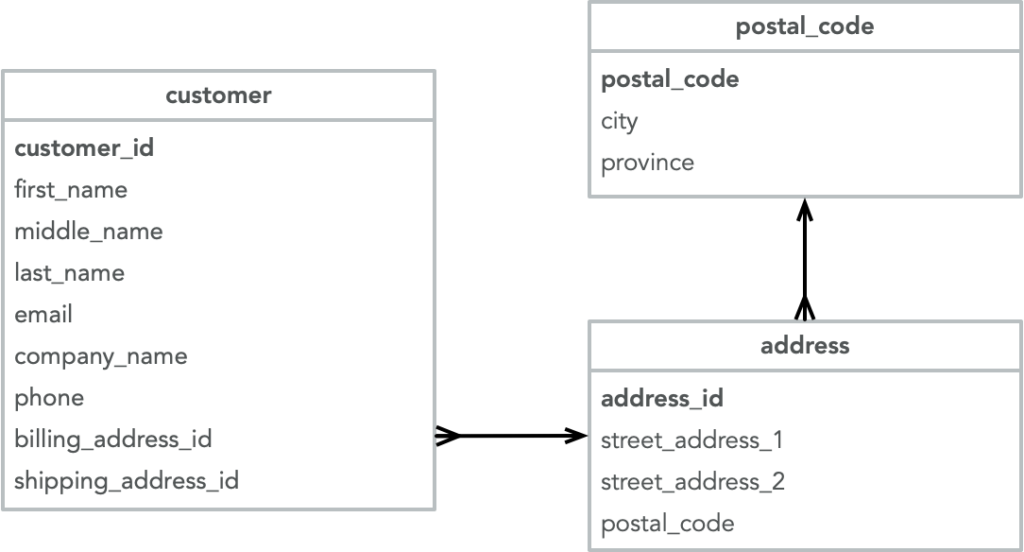
La segunda fuente de datos es un archivo plano que también contiene clientes canadienses, pero que no registra por separado las direcciones de facturación y de envío. Como puede ver, un único elemento de datos de dirección se almacena en el registro del cliente:

Tenemos que transformar estos datos a medida que llegan para que coincidan con nuestra base de datos de clientes existente, que está desnormalizada de forma que las direcciones de facturación y envío se adjuntan a los datos del cliente (de la segunda fuente) como subdocumentos:

Empecemos por un fácil solución en primer lugar, la importación de ficheros planos. El proceso de transformación de estos datos consiste en copiar los datos del cliente (nombre, correo electrónico, teléfono, nombre de la empresa) en un nuevo documento. A continuación, los datos de la dirección deben copiarse en subdocumentos para las direcciones de facturación y postal. Como sólo tenemos una dirección por cliente, copiaremos esta dirección tanto en el subdocumento de facturación como en el de dirección postal:

Código JavaScript para consolidar las tablas
El código Eventing para lograr esto es bastante simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
1 function OnUpdate(doc, meta) { 2 const new_doc = {}; // New customer document 3 const address = {}; // New address document 4 5 new_doc['first_name'] = doc.first_name; 6 new_doc['last_name'] = doc.last_name; 7 new_doc['email'] = doc.email; 8 new_doc['phone'] = doc.phone; 9 new_doc['company_name'] = doc.company_name; 10 11 address['street_address_1'] = doc.street_address_1; 12 address['street_address_2'] = doc.street_address_2; 13 address['city'] = doc.city; 14 address['state'] = doc.province; 15 address['zip_code'] = doc.postal_code; 16 17 // Add address document to customer document as subdocuments 18 new_doc['billing_address'] = address; 19 new_doc['mailing_address'] = address; 20 21 // This creates the new document in the destination bucket 22 dest_bkt[doc.email] = new_doc; 23 24 // Delete original document - uncomment below 25 // delete sch2[meta.id]; 26 27 log("Doc created/updated", meta.id); 28 } |
El código anterior debería ser lo suficientemente fácil de entender, incluso para los codificadores no JavaScript, pero voy a romper esto por sección sólo para estar seguro.
-
- Línea 1 se ejecuta cada vez que se muta (crea o modifica) un documento del bucket de origen. A continuación veremos cómo definimos el bucket de origen.
- Las líneas 2-3 crean objetos JavaScript para contener el nuevo documento de cliente y el documento de dirección que se utilizarán como subdocumentos dentro del documento de cliente.
- Líneas 5-15 copiar las propiedades del documento original en los objetos cliente y dirección.
- Líneas 18 y 19 asignar el documento de dirección como subdocumentos de cliente para las propiedades de dirección postal y de facturación.
- Línea 22 crea el documento en el bucket de destino de Couchbase. A continuación veremos cómo definimos el bucket de destino.
- Por último, la línea 25 borrará el documento original, aunque aquí está comentado.
- Línea 27 registra la operación. Es posible que desee comentar / eliminar esto después de la prueba.
Configurar el entorno
Para probar este script, necesitaremos configurar nuestro entorno Couchbase. En primer lugar, necesitaremos un clúster Couchbase que ejecute el servicio de datos, así como el servicio de eventos. Esto puede ser tan pequeño como un cluster de un solo nodo ejecutándose en Docker, o un cluster más grande de múltiples nodos ejecutándose en Capella.
Una vez que tengamos el clúster en funcionamiento, tendremos que crear los buckets para importar datos y un bucket de destino final. El servicio de eventos también requiere un bucket de metadatos. Cree los siguientes cuatro buckets, cada uno con la cuota mínima requerida de 100mb:
-
- esquema1
- esquema2
- cliente
- eventing_merge
También recomiendo activar descarga para este ejercicio.
Creación de una función de eventos
Ahora tenemos que crear la función de eventos. Selecciona la función concurso y, a continuación, haga clic en Añadir función. Utilice los siguientes ajustes:
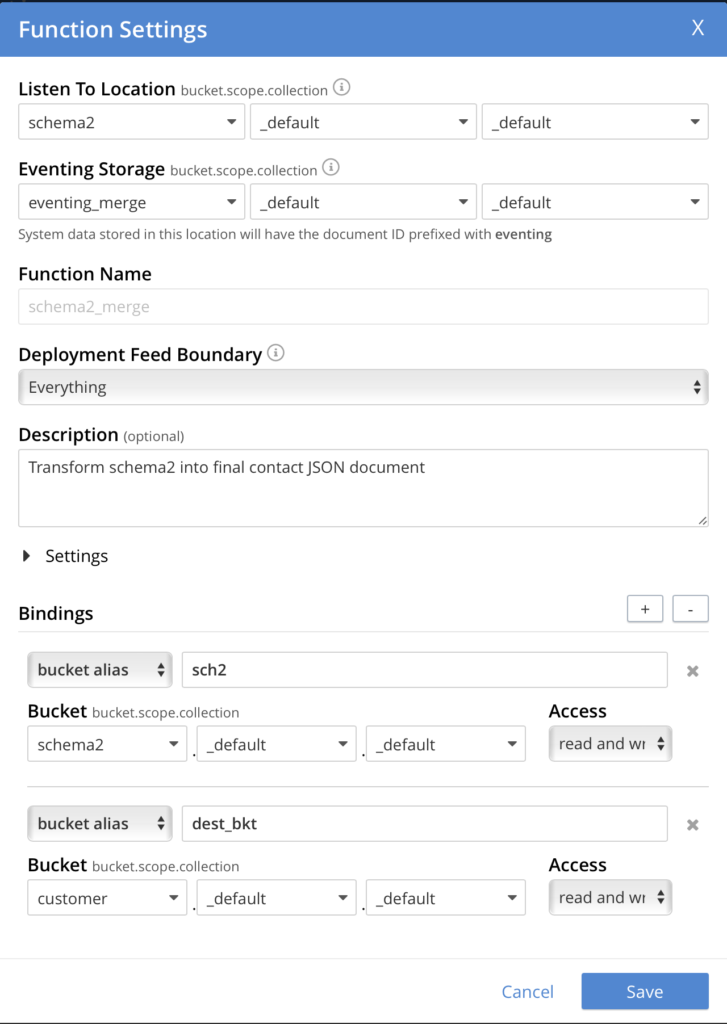
A continuación, haga clic en Siguiente Añadir código y sustituir el valor por defecto OnUpdate con el código anterior. Haga clic en Guardar y Retorno. En este punto el código ha sido almacenado, pero la función necesita ser desplegada para que comience a procesar datos. Haz clic en el nombre de la función para abrir su configuración y despliega la función ahora.
Creación de documentos JSON de prueba
Ahora vamos a probarlo creando un documento en el directorio esquema2 cubo. Añada un documento utilizando wile.e.coyote@acmecorp.com como clave del documento, y con el siguiente cuerpo del documento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "customer_id": null, "first_name": "Wile", "middle_name": "E", "last_name": "Coyote", "email": "wile.e.coyote@acmecorp.com", "title": "Genius", "company_name": "Acme Corporation", "phone": "123-555-1212", "street_address_1": "694 York Circle", "street_address_2": "", "city": "Hackettstown", "province": "NJ", "postal_code": "07840" } |
En un momento, deberías ver que las estadísticas del evento indican éxito:

Ahora mira en el cliente y verá que el documento anterior se ha transformado. Observe cómo la dirección existe ahora como subdocumentos dentro de las propiedades dirección_facturación y dirección postal:

Transformación en subdocumentos
Ahora abordemos la transformación más compleja del esquema. La migración de la estructura relacional para que coincida con nuestra estructura de subdocumentos se parece a esto:
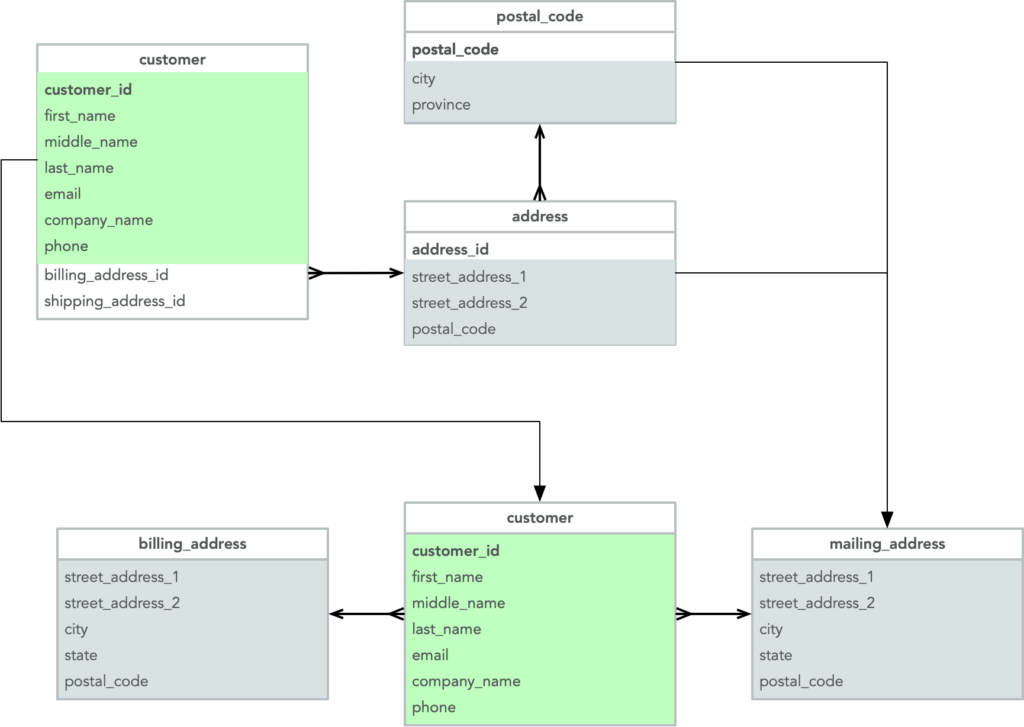
Tendremos que desnormalizar las tablas de direcciones y códigos postales en un único subdocumento, uno para las direcciones de envío y otro para las de facturación. En este caso, los datos de las tres tablas se almacenan en colecciones dentro del bucket.
Código JavaScript para la desnormalización
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
1 function OnUpdate(doc, meta) { 2 let new_doc = {}; 3 let bill_addr = {}; 4 let mail_addr = {}; 5 6 new_doc['first_name'] = doc.first_name; 7 new_doc['last_name'] = doc.last_name; 8 new_doc['email'] = doc.email; 9 new_doc['phone'] = doc.phone; 10 new_doc['company_name'] = doc.company_name; 11 12 bill_addr = bkt_addr[doc.billing_address_id]; 13 mail_addr = bkt_addr[doc.shipping_address_id]; 14 15 bill_addr['city'] = bkt_pc[bkt_addr[doc.billing_address_id].postal_code].city; 16 mail_addr['city'] = bkt_pc[bkt_addr[doc.shipping_address_id].postal_code].city; 17 18 bill_addr['state'] = bkt_pc[bkt_addr[doc.billing_address_id].postal_code].province; 19 mail_addr['state'] = bkt_pc[bkt_addr[doc.shipping_address_id].postal_code].province; 20 21 new_doc['billing_address'] = bill_addr; 22 new_doc['mailing_address'] = mail_addr; 23 24 log(new_doc); 25 26 dest_bkt[doc.email] = new_doc; 27 28 // Delete existing customer (leave address/postal_code for other customers who share this) 29 // delete bkt_cust[meta.id]; 30 log("Doc created/updated", meta.id); 31 } |
Desglosaremos este código de nuevo como antes.
-
- Líneas 2-4 crear objetos JavaScript para almacenar el nuevo documento, así como los subdocumentos para las direcciones de correo y facturación.
- Líneas 6-10 copia las propiedades del contacto en el nuevo documento.
- Líneas 12 y 13 copia los datos de la dirección desde la colección de direcciones utilizando la clave de documento almacenada en la propiedad address_id del contacto.
- Líneas 15-19 extrae los datos de ciudad y provincia de la colección de provincias, utilizando el provincial_id del documento de dirección como clave del documento.
- Líneas 21 y 22 a continuación, adjunte estos objetos de documento como subdocumentos al nuevo documento de contacto.
- Por fin, línea 26 escribe el nuevo documento en el bucket de destino.
- Línea 29si no se comenta, se eliminará el documento de contacto original del bucket de origen. Ten en cuenta que no queremos eliminar también los documentos de dirección y provincia asociados porque pueden ser utilizados por otros contactos.
Creación de la función eventing para la desnormalización
Cree esta función de eventos utilizando la siguiente configuración y pegue el código anterior para reemplazar la función OnUpdate función. Cuando haya terminado, siga adelante y despliegue la función.
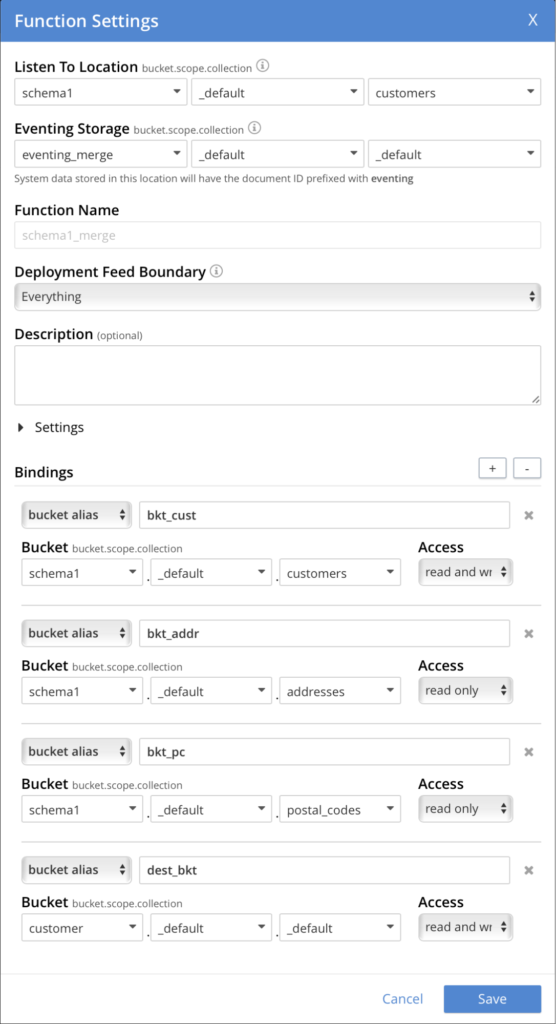
Para probar esta función, tendremos que crear colecciones en el directorio esquema1 (utilice el botón por defecto scope) con los nombres: direcciones, clientes, códigos postales. A continuación, cree los siguientes documentos (en este orden, de lo contrario fallarán las búsquedas en la función):
Códigos postales con ID de documento 43062:
|
1 2 3 4 5 |
{ "postal_code": "43062", "city": "Pataskala", "province": "OH" } |
Códigos postales con ID de documento 23228:
|
1 2 3 4 5 |
{ "postal_code": "23228", "city": "Henrico", "province": "VA" } |
Direcciones con ID de documento 000071:
|
1 2 3 4 5 6 |
{ "address_id": "000071", "street_address_1": "85 Hartford Road", "street_address_2": "", "postal_code": "23228" } |
Direcciones con ID de documento 000086:
|
1 2 3 4 5 6 |
{ "address_id": "000086", "street_address_1": "460 Broad Dr.", "street_address_2": "", "postal_code": "43062" } |
Por último, en el clientes con ID de documento blinded_by@science.com:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "customer_id": null, "first_name": "Thomas", "middle_name": null, "last_name": "Dolby", "email": "blinded_by@science.com", "title": null, "phone": "867-5309", "billing_address_id": "000086", "shipping_address_id": "000071", "company_name": "The Golden Age of Wireless" } |
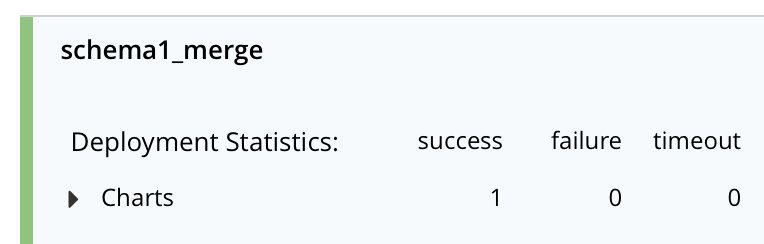
Rápidamente debería ver que las estadísticas de esta función muestran el éxito:
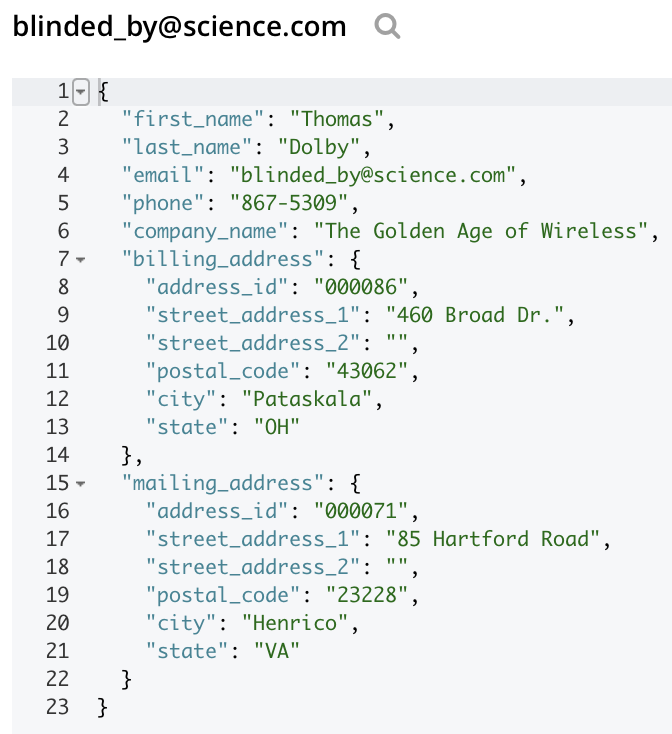
Y si miras el documento en el bucket de clientes, deberías ver la siguiente transformación con las dos direcciones desnormalizadas en subdocumentos.
Reflexiones finales
Este es un ejemplo muy simplista. En un entorno de producción, es probable que agregue código para manejar excepciones.
También puede aumentar el número de trabajadores de 1 al número de vCPUs si tiene un gran conjunto de datos y requiere un mayor rendimiento.
Las funciones de eventing utilizadas en este blog pueden encontrarse en el siguiente repositorio de github: https://github.com/djames42/cb_eventing_merge. En este repositorio también hay un par de scripts (tanto de Bash como de Python) que se pueden utilizar para crear un clúster de un solo nodo con las funciones de eventos y los conjuntos de datos de muestra más grandes precargados.
Recursos
-
- Descargar: Descargar Couchbase Server 7.1
- GitHub: https://github.com/djames42/cb_eventing_merge.
Referencias