Aprender SQL es fácil; aplicarlo, no tanto.
Halloween ha llegado y se ha ido. Pero, ¡los trucos del problema de Halloween están aquí para quedarse! Las bases de datos tienen que resolverlo cada día. SQL hizo la base de datos relacional fácil, accesible y exitosa. SQL puede ser fácil de escribir, pero su implementación esconde mucha complejidad. Desde los días de Sistema R a los sistemas NoSQL, todos implementamos SQL y lenguajes inspirados en SQL como N1QLEl lenguaje de consulta declarativo tiene que aprender las reglas y los requisitos para garantizar que sigue su curso. extraordinaria eficacia y corrección. Uno de estos problemas es el problema de Halloween. Describiré aquí brevemente el problema. Recomiendo encarecidamente la lectura de su historia en los Anales IEEE de la historia de la informática - segundo enlace en la sección de referencias más abajo.
El problema:
Consideremos una tabla y un índice sencillos:
|
1 2 |
CREATE TABLE t (empid int primary key, salary int); CREATE INDEX i1 ON t(salary); |
Imagina que has cargado unos datos y el índice i1 tiene este aspecto. La entrada del índice tiene el valor numérico del salario, seguido del rowid.

Ahora, con el ánimo de dar más a quien lo tiene, queremos aumentar el salario de todos los empleados que tengan (salario > 50).
UPDATE t SET salario = salario + 100 WHERE salario > 50;
Plan de consulta: Este es el plan general para ejecutar la consulta. En este caso, asumiremos que el planificador de consultas utilizará el índice i1 para calificar las filas) a actualizar.
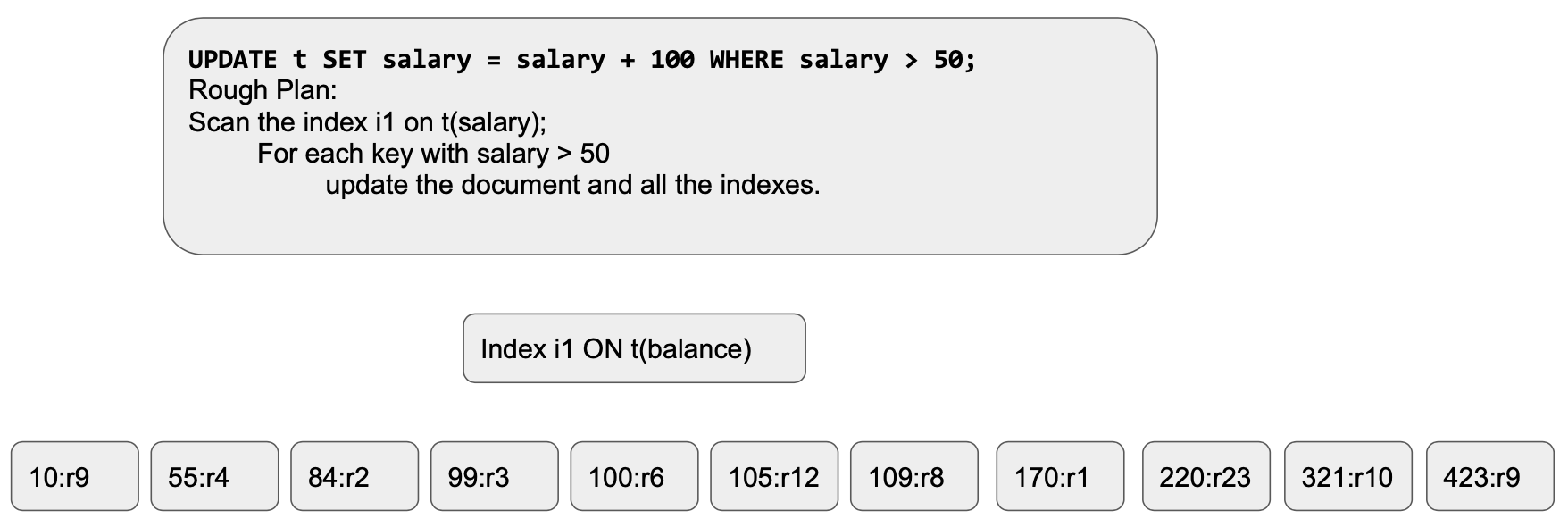
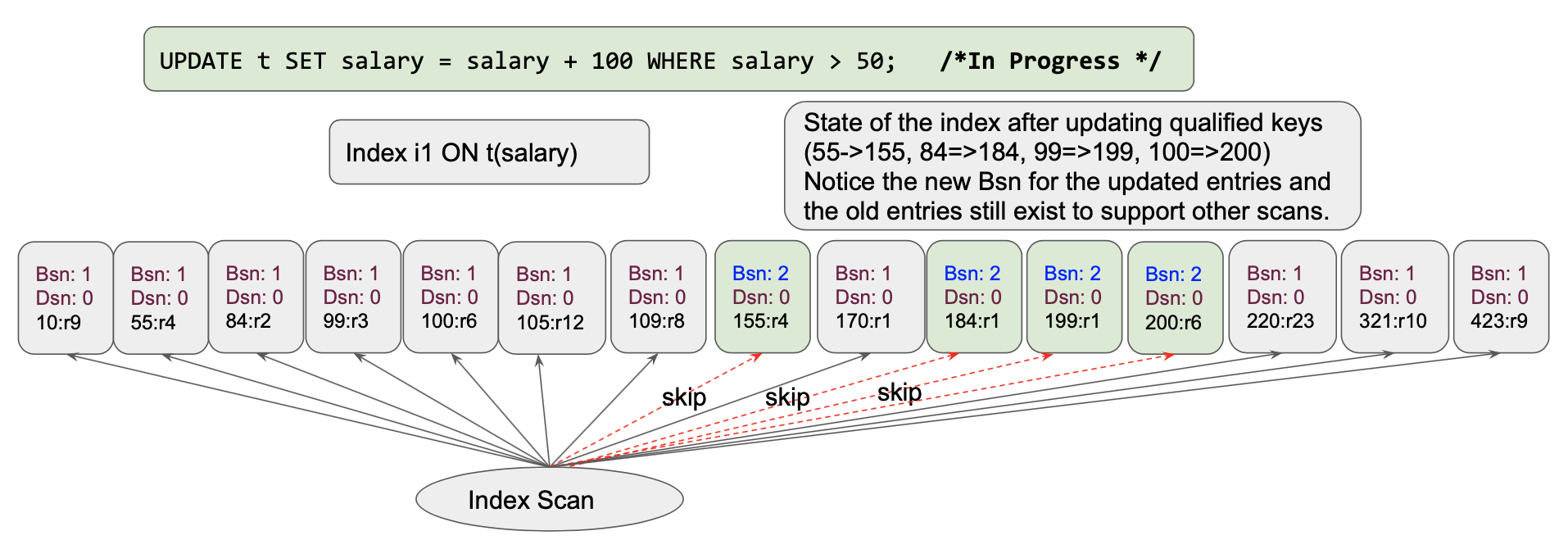
Ejecución de consultas: Una vez que esto comienza a ejecutarse, las filas de datos se actualizarán y el índice se actualizará de forma sincrónica. el índice se verá algo como esto. Cada clave cualificada se actualiza una a una [estamos escaneando de izquierda a derecha]. Este es el estado del índice después de actualizar las cuatro entradas iniciales: (55->155, 84=>184, 99=>199, 100=>200)

Veamos qué ocurre tras un par de cambios más.
Cuando pasamos al siguiente elemento[155,r2] se actualiza de nuevo a[255,r2]. Esto repetirá la actualización de múltiples claves varias veces. Eso viola las reglas de manipulación de conjuntos donde la intención es tomar el conjunto en la tabla t y actualizar los salarios calificados por 100.

Una manifestación adicional de los problemas de Halloween.
INSERT INTO t SELECT * FROM t WHERE balance > 0;
Solución:
En los RDBMS tradicionales (por ejemplo, Informix), la solución es bastante sencilla. Para cada una de las sentencias DML que dan lugar a una mutación, se mantiene una lista ordenada de los rowids actualizados dentro de esta sentencia. Antes de actualizar una fila, se comprueba si ya está actualizada y se omite. Para actualizaciones sencillas con escaneos de rangos limitados, esta sobrecarga de lectura apenas es perceptible. Para actualizaciones más grandes, el mantenimiento de una lista grande en memoria puede ser un problema. Normalmente, la lista se vuelca en disco una vez que alcanza un tamaño suficiente.
Solución Couchbase N1QL & GSI:
Couchbase es una base de datos distribuida con múltiples servicios. El servicio de consulta crea el eplan de ejecución y lo ejecuta. Esta es la visión general de la solución.
Veamos la consulta cuando tenemos un índice: CREAR ÍNDICE i1 EN t(salario)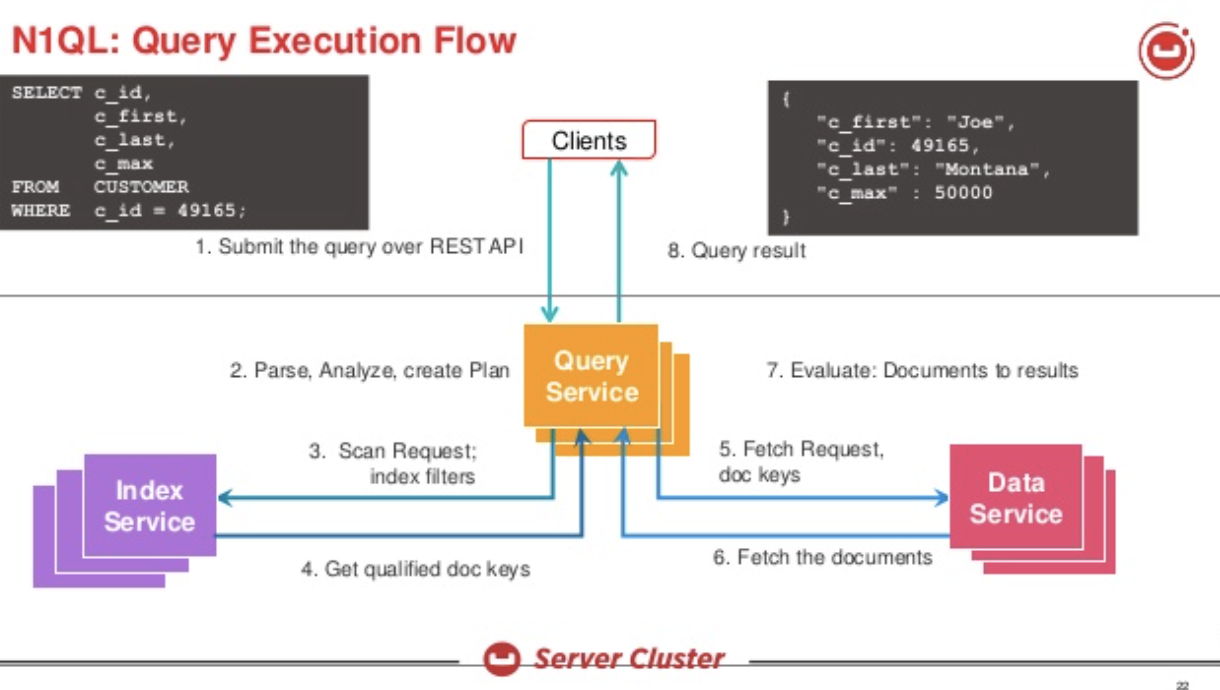 N1QL creará un plan como este: En la sentencia UPDATE, el plan usará el escaneo del índice para identificar los documentos a actualizar, buscar el documento, actualizarlo y escribirlo de vuelta. Es importante notar que esta actualización se hace a los documentos sincrónicamente. Estos cambios fluirán a través del DCP y las actualizaciones del índice se realizarán de forma asíncrona. Incluso entonces, para actualizaciones más grandes, el escaneo del índice y las actualizaciones pueden continuar mientras se realizan las actualizaciones al índice que se está escaneando.
N1QL creará un plan como este: En la sentencia UPDATE, el plan usará el escaneo del índice para identificar los documentos a actualizar, buscar el documento, actualizarlo y escribirlo de vuelta. Es importante notar que esta actualización se hace a los documentos sincrónicamente. Estos cambios fluirán a través del DCP y las actualizaciones del índice se realizarán de forma asíncrona. Incluso entonces, para actualizaciones más grandes, el escaneo del índice y las actualizaciones pueden continuar mientras se realizan las actualizaciones al índice que se está escaneando.
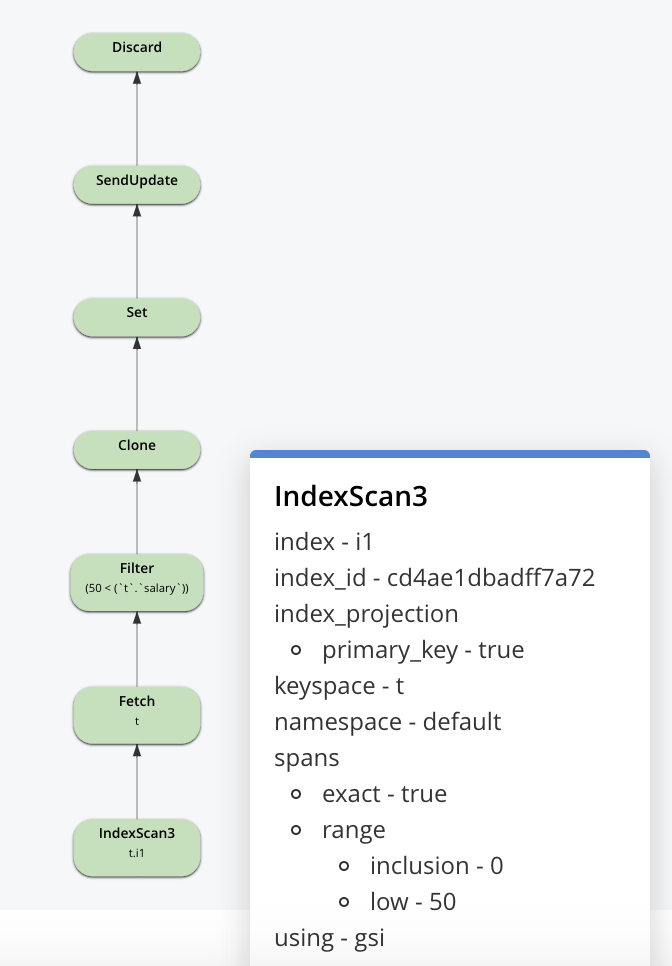
Veamos ahora el escaneo del índice en sí. Los índices pueden construirse sobre Índice Optimizado para Memoria (MOI) o Secundario Estándar (usando Plasma Storage Engine). Ambos tienen el concepto de instantánea. En lugar de actualizar los valores in situ, utilizamos MVCC para proporcionar la funcionalidad y el rendimiento necesarios.
He aquí un par de cosas del Nitro papel.
Instantáneas inmutables: Los redactores simultáneos añaden o eliminan elementos de la lista de esquí. Se puede crear una instantánea de los elementos actuales para proporcionar una vista puntual de la lista de esquí. Esto es útil para proporcionar exploraciones estables repetibles. Los usuarios pueden crear y gestionar varias instantáneas. Si una aplicación requiere atomicidad para un lote de operaciones de la lista de esquí, puede aplicar un lote de operaciones y crear una nueva instantánea. Los cambios serán invisibles hasta que se cree una nueva instantánea.
Instantáneas rápidas y de baja sobrecarga: Los lectores de la lista de esquí utilizan un gestor de instantáneas para realizar todas las consultas de búsqueda y rango. Una aplicación de indexación normalmente requiere que se creen muchas instantáneas cada segundo para dar servicio a las consultas del índice. Así que la sobrecarga de crear y mantener una instantánea debe ser mínima para dar servicio a la alta tasa de generación de instantáneas. Las instantáneas Nitro son muy baratas y es una operación O(1).
Para implementarlos, el índice utiliza dos cosas: La versión BornSnapshot y la versión DeadSnapshot. Veamos el estado del índice inicial.
 Como los cambios, el cambio en los valores simplemente añadir nuevos nodos en el skiplist con valores actualizados, bornSnapshot y deadSnapshot valores.
Como los cambios, el cambio en los valores simplemente añadir nuevos nodos en el skiplist con valores actualizados, bornSnapshot y deadSnapshot valores.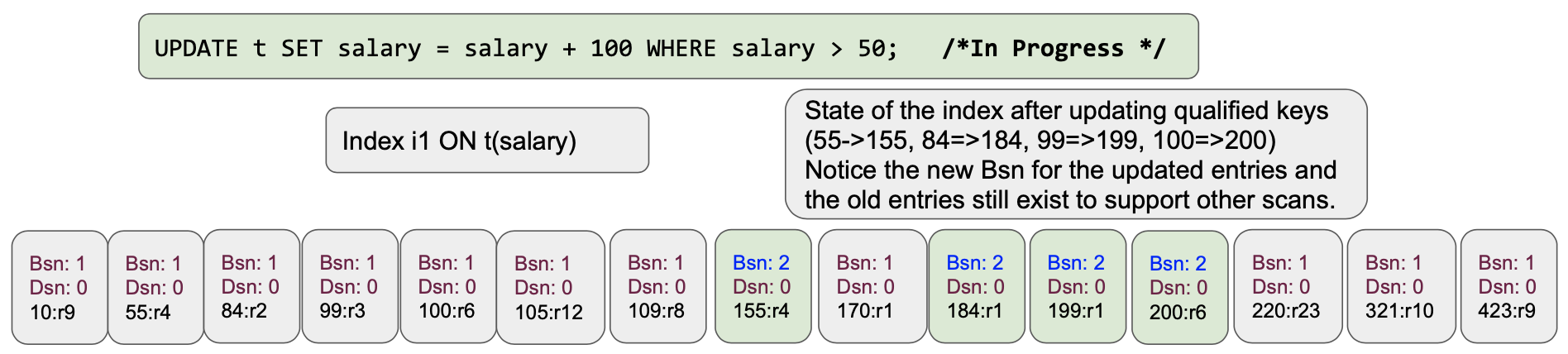
Usando las versiones bornSnapshot y deadSnapshot en las entradas, el escáner de índice (también conocido como iterador) simplemente elige las entradas correctas para calificar las entradas de índice a leer. Así crea una instantánea y no leerá el valor previamente actualizado en el mismo escaneo. Esto no sólo proporciona escaneos estables, ¡sino que también evita por completo el problema de Halloween! Esto también elimina la necesidad de mantener la lista de documentos actualizados en el servicio de consulta. La buena ingeniería soluciona el problema; la gran ingeniería lo evita por completo :-)
Por último, un arte de Halloween de David HaikneyVP de Atención al Cliente de Couchbase Vea el vídeo completo
Feliz Halloween a todos@couchbase¡! 🎃 pic.twitter.com/vqwW7sk3v6
- David Haikney (@dhaikney) 31 de octubre de 2020
Referencias
- Problema de Halloween
- Una consulta bienintencionada y el problema de HalloweenLaboratorio Nacional de Los Álamos, Anécdotas, IEEE Annals of the History of Computing
- Índice secundario global de Couchbase
- Nitro: Un motor de almacenamiento en memoria rápido y escalable para el índice secundario global NoSQL