Hay un gran blog sobre cómo obtener el máximo rendimiento de nuestro servicio de indexación: "Crear el índice adecuado, obtener el rendimiento adecuado".tanto ese blog como sus consejos han resistido el paso del tiempo. Así que, ¿por qué no tener un blog relacionado con las consultas en su homónimo?
En cualquier caso, creo que lo mismo puede decirse de nuestro servicio de consulta: para obtener el rendimiento adecuado, hay que elaborar la consulta adecuada. El servicio de índices puede recibir muchas críticas por ser el único que contribuye al rendimiento de las consultas. Pero a veces es necesario cambiar tanto la consulta como el índice que se utiliza.
Esperemos que aquí podamos mostrar un ejemplo en el que podría ser sólo un ajuste de consulta lo que tiene que suceder con el fin de obtener el rendimiento de nivel empresarial por el que Couchbase es conocido. El siguiente ejemplo se basa en una pregunta que nos hizo uno de nuestros clientes, así que esperamos que esto sea útil para un número de personas que utilizan Couchbase "en cólera".
Su entorno
Utilicemos un ejemplo, y además hagámoslo fácil de seguir, soy un gran fan de los blogs que permiten a los lectores seguirlos si lo desean. Para sentar las bases, aquí tienes algunos componentes que podrías utilizar para realizar este ejemplo:
- El siempre útil https://cloud.couchbase.com/sign-up entorno de desarrollo. ¿Pasando el rato en tu hamaca en una playa de Bali? Si enciendes tu propio contenedor docker de Couchbase, los ventiladores arderán y habrá arena directamente en tu Mojito. Siempre y cuando tengas conexión a Internet, podemos ofrecerte 30 minutos de entorno de desarrollo ¡gratis! Obviamente eres libre de usar cualquier entorno Couchbase que ya tengas.
- El conjunto de datos de la muestra de viajes
- Su documentación práctica sobre matrices N1QL
- Este práctico blog de referencia de bolsillo sobre el trabajo con matrices
N.B. Los ejemplos de N1QL utilizarán nuestra función de ámbitos/colecciones, por lo que el contexto de cubo se establece en el ámbito predeterminado del conjunto de datos de la muestra de viajes.
Contexto real
Para situar el escenario de este ejemplo, podemos utilizar un caso de uso común: la generación de campañas de marketing. Un ejemplo de esta consulta podría ser encontrar a los visitantes del hotel que han dejado una reseña y a los que les ha gustado el hotel: estos datos podrían darles derecho a recompensas de un programa de fidelización, a estancias en hoteles mejor orientadas/similares, o simplemente a una visión de los usuarios que tienen más probabilidades de dejar una reseña/me gusta. Todos estos datos son muy valiosos para ofrecer un mejor servicio a nuestros clientes.
El objetivo principal de este ejemplo específico es mostrarte las posibilidades de consultar múltiples arrays dentro de un único documento JSON, y de nuevo plantar la semilla de que a veces puedes sacar aún más rendimiento de tu servicio de consulta después de crear el índice adecuado. Después de todo, estás haciendo uso de un sistema que permite campos de datos dinámicos y las matrices son una gran parte de la flexibilidad del uso de JSON como formato de datos.
Humildes comienzos
Una forma común de consultar arrays en n1ql (como se explica en el blog enlazado), es a través de lo siguiente:
|
1 |
SELECT (ANY v IN [1, 2, 3, 4, 5] SATISFIES v > 4 END) as is_found, (ANY v IN [1, 2, 3, 4, 5] SATISFIES v = 7 END) as not_found; |
En este ejemplo estamos diciendo: "consígueme elementos del array, que coincidan con la condición de la sentencia SATISFIES".
Si aplicáramos este método a nuestros intentos de consultar múltiples matrices en un documento JSON, probablemente se parecería a lo siguiente:
|
1 2 3 |
SELECT public_likes, reviews FROM _default WHERE type="hotel" AND ANY r IN reviews SATISFIES r.author = "Ozella Sipes" END AND ANY l IN public_likes SATISFIES l = "Ozella Sipes" END LIMIT 1; |
Sin embargo, esto no conduciría a una consulta de alto rendimiento, ya que N1QL actualmente requiere que se construya un único array indexable a partir de los arrays del documento, como se señala aquí.
Creación de índices para múltiples campos de matriz
¿Cómo se construye un índice de este tipo? Veamos un ejemplo, utilizando nuestro caso de uso de recopilación de datos sobre huéspedes a los que les han gustado nuestros hoteles y han hecho reseñas sobre ellos.
|
1 2 3 4 5 |
CREATE INDEX `reviewers_likes_idx` ON `_default`( DISTINCT ARRAY ( DISTINCT ARRAY [l,r.author] FOR r IN reviews END) FOR l in public_likes END) WHERE type="hotel"; |
Lo que estamos haciendo aquí es crear un índice con un único array de likes y reviews combinados. Esta es la mejor práctica y apoya la nota en nuestra documentación. Sólo para mostrarle una manera en la que usted podría haber pensado que sería correcto: aquí está el no soportado y la forma de definitivamente no indexar múltiples campos de matriz:
|
1 |
CREATE INDEX `not_the_right_idx` ON `_default`( DISTINCT (ARRAY r.field FOR r in json_obj END), likes); |
Esto indexaría múltiples campos de array - no aconsejable.
Mejorar la consulta
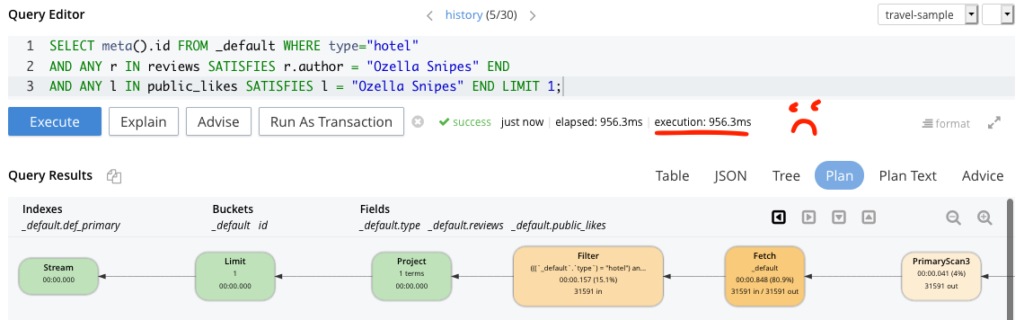
A continuación se muestran dos ejemplos de consultas que se han ejecutado en nuestro banco de trabajo de consultas. Utilizando mi consulta mejorada he conseguido reducir el tiempo de ejecución de 956,3 ms a ~4 ms. Pruébelo usted mismo, la consulta mejorada se encuentra al final de este blog.
Consulta no eficaz
Mejora del rendimiento de las consultas

En esencia, nuestras dos consultas funcionarían, pero los tiempos de ejecución de ambas difieren enormemente, y esto se debe a que en la última consulta estamos utilizando un índice cuidadosamente elaborado y basado en las mejores prácticas. Si has llegado hasta aquí, puedes ejecutarlo tú mismo. Ten en cuenta que he añadido a "Ozella Sipes" como autora de una reseña y como "likeer" público en uno de los documentos del hotel para comprobar que mi consulta funciona. Los resultados pueden variar en función del nombre que utilices.
|
1 2 3 4 5 |
SELECT META().id FROM _default WHERE type="hotel" AND ANY l IN public_likes SATISFIES ( ANY r IN reviews SATISFIES [l,r.author] = ["Ozella Sipes", "Ozella Sipes"] END) END LIMIT 1; |
Espero que este blog le haya sido útil y le haya dado una idea de que, en algunos casos, también hay que tener en cuenta el uso de la consulta correcta para obtener el rendimiento adecuado.