Couchbase con Windows y .NET - Parte 2 - Lingo
Este artículo es la segunda parte de una serie. En la Parte 1 se explica cómo instalar y configurar Couchbase en Windows..
En parte 1 - Configuraciónmostré lo más básico de cómo conseguir Servidor Couchbase en marcha. Si eres como yo, estás impaciente por empezar a codificar y ver lo que puedes hacer. Pero antes de ir allí, quiero repasar algo de la jerga de Couchbase. No es una herramienta difícil de usar, pero es diferente de los sistemas RDBMS como SQL Server a los que probablemente estés acostumbrado. Así que esta serie de entradas de blog es tanto para ti como para mí: Estoy aprendiendo sobre la marcha.
Esta es la versión resumida desde el punto de vista de un desarrollador: Un Couchbase grupo contiene nodos. Los nodos contienen cubos. Los cubos contienen documentos. Los documentos pueden recuperarse de múltiples formas: por sus claves, consultándolos con N1QLy también usando Views (que usan map/reduce). (Con Couchbase 4.5, piezas de documentos puede actualizarse con el subdocumento API). Veamos ahora cada elemento con más detalle.
Grupo
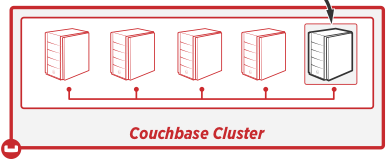
Para empezar, hablemos de un "grupo." Uno de los puntos fuertes de Couchbase es su capacidad de ampliación: añadir servidores adicionales para manejar más datos de forma eficiente. Esto contrasta con la ampliación, que consiste en sustituir un servidor por otro más potente y rápido (algo que también se puede hacer con Couchbase). Un cluster es una colección de nodos relacionados que se coordinan entre sí y actúan como un servidor lógico. Cuando usas Couchbase, siempre estás tratando con un cluster, incluso si sólo tienes un nodo en ese cluster. "Couch" es un acrónimo de "Cluster Of Unreliable Commodity Hardware".
Nodo
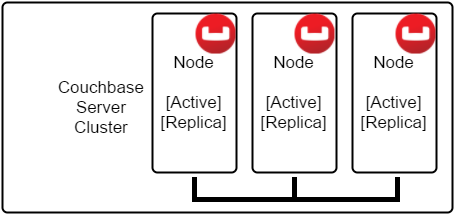
Un nodo es un componente individual de un clúster. Suele corresponder a un servidor. Cuando se define un cluster, se define una cuota de RAM (por cada servicio). Esta es la cantidad de RAM que cada nodo del cluster utilizará para proporcionar un servicio determinado. Así, si la cuota de RAM de datos es de 2gb, entonces cada nodo del cluster que proporcione un servicio de datos tendrá 2gb de RAM con los que trabajar. Cada nodo también contribuye con espacio en disco al cluster.
Un nodo proporciona uno o varios servicios: almacenamiento de datos, indexación, consulta y búsqueda de texto completo. Puede configurar su clúster como desee: un nodo que proporcione todos los servicios hasta un nodo para cada tipo de servicio, y luego puede escalar hacia fuera y/o hacia arriba. (Ejemplo: Podría añadir 5 nodos más para el almacenamiento de datos, 1 nodo más para la indexación y utilizaré un único servidor muy potente para las consultas).
Los nodos también almacenan réplicas de datos de otros nodos. De este modo, si otro nodo se cae, los datos de réplica pueden "promocionarse" a activos y tu aplicación puede seguir su alegre camino.
Desde la perspectiva de la escritura de código, todo este comportamiento debería ser transparente. La configuración de los nodos de un clúster puede cambiar (y cambiará), pero el código no tiene por qué hacerlo.
Cubo
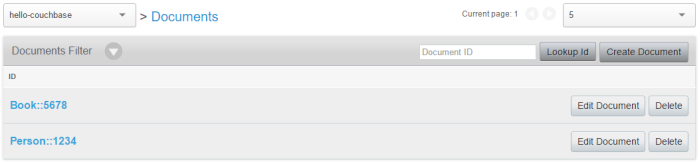
A cubo es un lugar para almacenar documentos. Cada documento tiene una clave. Dentro de un cubo, cada clave debe ser única. Los documentos dentro de un cubo no tienen que ser similares en absoluto. Puede almacenar un documento que contenga información sobre un usuario, y un documento con información sobre un edificio. Puede configurar varios buckets en un nodo, pero se recomienda que se limite a 10 buckets o menos. Utilizando una analogía con una base de datos relacional, un bucket es más parecido a una instancia o catálogo de una base de datos. No es como una tabla.
La razón por la que Couchbase es tan rápido es porque cada bucket almacena muchos de sus documentos en RAM. Cuando llega una petición de un documento, es probable que el documento (o al menos los metadatos del documento) ya esté en RAM, listo para usarse, sin necesidad de acceder al disco. Cuando llega un documento nuevo o actualizado, se actualiza en RAM y se pone en cola para escribirlo en disco y replicarlo a otros nodos. Cuando es necesario liberar memoria para otros documentos, los metadatos permanecen en la RAM para su posterior recuperación: sólo se expulsa el valor (a menos que usted configurar el cubo de otro modo).
Documento
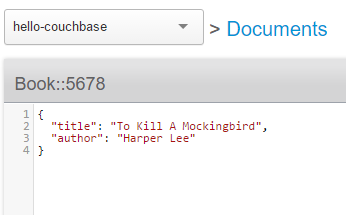
En un sentido muy básico, un cubo Couchbase es sólo un diccionario gigante . Puedes usar lo que quieras para la clave (siempre que sea única), y puedes poner lo que quieras en el valor. Sin embargo, si decides almacenar JSON en el valor, entonces también obtienes funcionalidad adicional: estructura, indexación, N1QL, vistas, etc. Así que aunque es posible y soportado usar valores no JSON, típicamente la mayoría de los valores serán almacenados como JSON. Por eso Couchbase se llama "base de datos de documentos". Cada bucket contiene documentosque son un valor y metadatos asociados (como la clave).
Así que, en inglés, tendría sentido decir cosas como:
- "Hey Couchbase cluster X, en el bucket 'foo', por favor dame el valor del documento con la clave 'bar'"
- "Hey Couchbase cluster X, en el bucket 'foo', aquí hay un nuevo documento con valor 'baz', tiene una clave de 'qux'
- "Hey Couchbase cluster X, in bucket 'foo', please change the value of the document with key 'corge' to have a value of 'grault'
N1QL
Couchbase reconoce que las bases de datos relacionales han sido una gran parte de la carrera de muchos desarrolladores. Muchos desarrolladores se sienten cómodos escribiendo SQL. Sin embargo, las bases de datos de documentos no funcionan realmente de la misma manera que las bases de datos relacionales, por lo que a menudo tienen que aprender una forma completamente nueva de hacer las cosas. Con Couchbase Server, sin embargo, si estás usando documentos JSON, puedes escribir consultas en un lenguaje llamado N1QL (N1QL son las siglas de "Non-first Normal Form Query Language, y se pronuncia "nickel"). N1QL es un superconjunto de SQL. Esto significa que, básicamente, si sabes SQL, entonces sabes N1QL. Existen algunas diferencias y algunas palabras clave adicionales, pero aquí tienes un ejemplo para que veas lo similares que son:
|
1 2 3 4 |
SELECCIONE nombre, autor DESDE `libros-cubo` DONDE AÑO(publicado) >= 1998 |
Eso devolverá algo como:
|
1 2 3 4 5 6 7 |
{ "resultados": [ { "nombre" : "El pequeño libro de la calma", "autor" : "Manny Bianco" }, { "nombre" : "AOP en .NET, "autor" : "Matthew D. Groves" } ] } |
Como te mostraré en posteriores entradas del blog, la Linq2Base aprovecha N1QL para ofrecerte un proveedor de Linq muy similar a Entity Framework, NHibernate.Linq u otros proveedores de Linq a los que estés acostumbrado.
Índices
Índices en Couchbase son tan importantes como en las bases de datos relacionales. Probablemente más, debido al volumen de datos que Couchbase puede manejar a medida que se amplía.
Para habilitar las consultas N1QL en un bucket, como mínimo necesitas crear un índice primario. Se trata de un índice sobre el propio bucket. Aquí se explica cómo crear uno con N1QL: CREATE PRIMARY INDEX ON mi-bucket;
Si utilizas documentos JSON, puedes crear índices basados en los campos de los documentos JSON. Por ejemplo, si tienes muchos documentos que tienen "nombre" o "autor", y a menudo realizarás consultas basadas en estos campos, puedes crear índices para ellos. Estos se llaman "índices secundarios".
Conclusión
Estoy tan ansioso como tú por meterme de lleno en el código, pero antes es bueno dominar la jerga. He intentado centrarme en los conceptos más importantes a expensas de algunos detalles. Así que, si tienes preguntas, déjame un comentario a continuación, contacta conmigo en twittero envíame un correo electrónico a través de matthew.groves AT couchbase DOT com. Me encantaría saber de ti.