Estamos encantados de anunciar el lanzamiento de Couchbase 7.6una actualización innovadora que está a punto de redefinir el panorama de la tecnología de bases de datos. Esta última versión es un testimonio de nuestro compromiso con la mejora de la tecnología de bases de datos, con un salto significativo en la integración de la IA y el aprendizaje automático con... Búsqueda vectorialLa integración de LangChain permite a los desarrolladores crear aplicaciones más inteligentes y con mayor capacidad de respuesta.
La clave de esta versión es la introducción de funciones avanzadas de Graph Traversal, que abren nuevas vías para las relaciones de datos complejas y el análisis de redes. Mejora la eficiencia de los desarrolladores e integra a la perfección los casos de uso de RDBMS con la agilidad y escalabilidad de NoSQL.
Junto a estas innovaciones, nos hemos centrado en mejorar la experiencia del usuario con una supervisión mejorada del rendimiento de las consultas y las búsquedas, garantizando una eficiencia y una capacidad de respuesta óptimas en las operaciones de datos en tiempo real. Esta versión también amplía nuestras capacidades de BI con herramientas de visualización de BI enriquecidas, lo que permite una visión más profunda de los datos y análisis más potentes.
Couchbase 7.6 no es sólo una actualización; es una transformación, que ofrece las herramientas y características que los desarrolladores, SREs y científicos de datos necesitan para impulsar el futuro de la tecnología de bases de datos. Estas son algunas de ellas.
Integración de la IA
Búsqueda vectorial
Couchbase introduce una nueva capacidad de búsqueda vectorial con la versión 7.6, una mejora significativa de nuestras capacidades de búsqueda que se alinea con las demandas tecnológicas en evolución de las aplicaciones modernas. A medida que aumenta la complejidad de los datos, la necesidad de mecanismos de búsqueda avanzados se vuelve crítica. Vector Search ofrece una solución que permite a los desarrolladores implementar búsquedas semánticas, enriquecer modelos de aprendizaje automático y dar soporte a aplicaciones de IA directamente en su entorno Couchbase.
Con la búsqueda vectorial, la búsqueda va más allá de la coincidencia de palabras clave o la búsqueda por frecuencia de términos. Permite que la búsqueda se base en el significado semántico, el contexto en el que se utiliza en las consultas. En efecto, capta la intención de las consultas, proporcionando resultados más pertinentes incluso cuando las palabras clave o los términos exactos no están presentes en el contenido.
Para más información, consulte el Documentación de Couchbase.
Búsqueda vectorial con SQL
Puedes utilizar las capacidades de base de datos NoSQL de Couchbase para almacenar cualquier contenido, como perfiles de usuario, datos históricos de interacción o metadatos de contenido. A continuación, utiliza un modelo de aprendizaje automático, como OpenAI, para generar las incrustaciones. Couchbase Vector Search puede entonces indexar las incrustaciones y proporcionar búsquedas semánticas e híbridas.
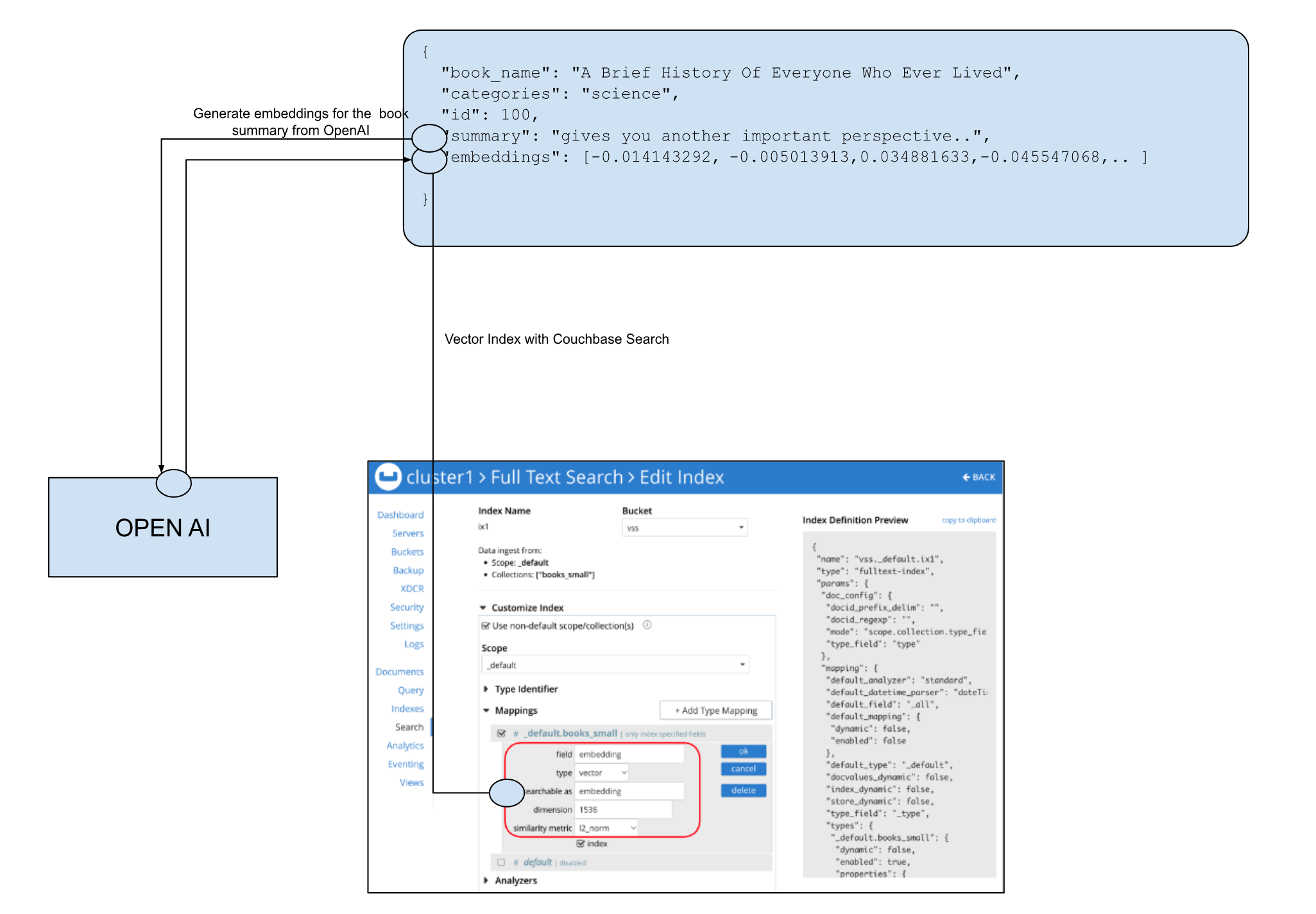
También puedes usar SQL++ para realizar la búsqueda vectorial directamente, y combinar los predicados de búsqueda con la flexibilidad de Couchbase SQL++ para una búsqueda híbrida:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT b.book_name, b.categories, b.summaries FROM `books` AS b WHERE SEARCH(b, { /* calling Couchbase SEARCH() */ "query": {"match_none": {} }, "knn": [{ "field": "embedding", "vector": [ -0.014143292,-0.005013913,..], "k": 3 }], "fields": ["book_name", "summaries"], "sort": ["-_score"], "limit": 5 }) AND b.catogories='Non fiction'; |
¿Por qué no queremos añadir una sección sobre cómo obtener las incrustaciones para la consulta anterior? La razón es que hacerlo en una UDF requeriría que UDF/JS soportara CURL, algo que no está soportado en Capella. Los usuarios pueden obtener las incrustaciones en su capa de aplicación.
CTE recursivo
Recorrido de gráficos
La introducción de Recursive CTE a las capacidades de Couchbase SQL++, significa que ahora puedes realizar análisis y manipulación de datos complejos, particularmente en el área de datos gráficos. Puedes navegar sin esfuerzo y analizar estructuras de datos jerárquicas y en red, desbloqueando conocimientos con una facilidad y eficiencia sin precedentes. Ya se trate de explorar redes sociales, jerarquías organizativas o sistemas interconectados, nuestra nueva función simplifica estas tareas, haciendo que su análisis de datos sea más intuitivo y productivo que nunca.
A continuación se muestra un ejemplo de consulta CTE recursiva SQL++ de Couchbase para encontrar todos los vuelos de LAX a MAD con menos de dos escalas de este conjunto de datos de muestra. Nótese que estos datos de la muestra no se basan en la muestra de viajes, sino en una versión simplificada de las rutas AA de 2008.
| código_aeropuerto_fuente | código_aeropuerto_destino | aerolínea |
| LAX | MAD | AA |
| LAX | LHR | AA |
| LHR | MAD | AA |
| LAX | OPO | AA |
| OPO | MAD | AA |
| MAD | OPO | AA |
| Consulta SQL | Resultados |
| /* Lista de todas las rutas de LAX a MAD con < 2 paradas */ CON RouteCTE RECURSIVO COMO ( SELECCIONE [r.source_airport_code, r.destination_airport_code] AS ruta, r.código_aeropuerto_destino AS últimaParada, 1 AS profundidad DESDE rutas r DONDE r.source_airport_code = LAX UNIÓN TODOS SELECCIONE ARRAY_APPEND(r.ruta,f.código_aeropuerto_destino) AS ruta, f.código_aeropuerto_destino AS últimaParada, r.profundidad + 1 AS profundidad DESDE RutaCTE r ÚNASE A rutas f EN r.ultimaParada = f.codigo_aereo_fuente DONDE f.código_aeropuerto_destino != LAX Y r.profundidad < 3 )OPCIONES {"niveles":3} SELECCIONE r.* DESDE RouteCTE AS r DONDE r.últimaParada = MAD AND r.depth < 3; |
[ { "ruta": [ "LAX", "MAD" ] }, { "ruta": [ "LAX", "LHR", "MAD" ] }, { "ruta": [ "LAX", "OPO", "MAD" ] } ] |
Estructura jerárquica de datos
También puede utilizar CTE recursivo para recorrer una estructura de datos jerárquica, como la jerarquía de una organización.
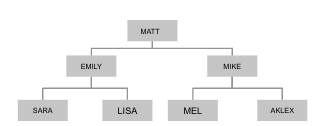
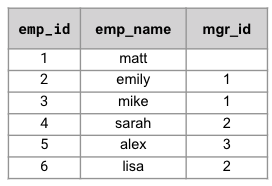
| Consulta SQL | Resultados |
| /* Lista de todos los empleados y su jerarquía org */ CON orgHier RECURSIVO como ( SELECCIONE [e.emp_name] hier, e.emp_id, 0 lvl DESDE empleado e DONDE e.manager_id es null UNIÓN SELECCIONE ARRAY_APPEND(o.hier, e1.emp_name) hier, e1.emp_id, o.lvl+1 lvl DESDE empleado e1 ÚNASE A orgHier o EN e1.manager_id=o.emp_id ) SELECCIONE o.* DESDE orgHier o; |
[ { "emp_id": 1, "hier": [ "matt" ], "lvl": 0 }, { "emp_id": 2, "hier": [ "matt", "emily" ], "lvl": 1 }, { "emp_id": 3, "hier": [ "matt", "mike" ], "lvl": 1 }, { "emp_id": 5, "hier": [ "matt", "mike", "alex" ], "lvl": 2 }, { "emp_id": 4, "hier": [ "matt", "emily", "sarah" ], "lvl": 2 }, { "emp_id": 6, "hier": [ "matt", "emily", "lisa" ], "lvl": 2 } ] |
Para más información, consulte la documentación de Couchbase en consulta recursiva.
Eficiencia de los promotores
Exploración de la gama KV
Las operaciones clave/valor (K/V) en Couchbase son la forma más eficiente de acceder a los datos almacenados en la base de datos. Estas operaciones utilizan la clave única de un documento para realizar acciones de lectura, escritura y actualización. Sin embargo, estas operaciones funcionan sobre la base de un documento individual. Para casos de uso de recuperación de datos más grandes, recomendamos usar el SQL++ del servicio Query para tus aplicaciones.
Sin embargo, hay casos en los que no es económicamente viable configurar nodos de consulta e indexación, ahora tiene la opción de utilizar KV Range Scan. La nueva función permite a sus aplicaciones iterar sobre todos los documentos basándose en un rango de claves, un prefijo de claves o un muestreo aleatorio. Las API envían internamente las solicitudes a múltiples vbuckets basándose en el moneda_máxima para equilibrar la carga entre los nodos de datos. A continuación, los flujos vbucket se fusionan lógicamente y se devuelven como uno solo flujo a la aplicación.
| KV Obtener | Exploración de la gama KV |
| público clase CouchbaseReadHotelExample { público estático void principal(String[] args) { // Conectarse al clúster Cluster cluster = Cluster.connect("couchbase://localhost", "nombre de usuario", "contraseña"); // Obtener una referencia al cubo 'muestra-viaje Bucket bucket = cluster.bucket("viaje-muestra"); // Acceder al ámbito "inventario" y a la colección "hotel Ámbito inventarioÁmbito = bucket.scope("inventario"); Colección hotelCollection = inventoryScope.collection("hotel"); Cadena documentKey = "hotel_12345"; GetResult getResult = hotelCollection.get(documentKey); |
public static void main(String... args) { Cluster cluster = Cluster.connect("couchbase://localhost", "nombre de usuario", "contraseña"); Bucket bucket = cluster.bucket("muestra-viaje"); Alcance = bucket.scope("_default"); Colección colección = scope.collection("_default"); System.out.println("\nEjemplo: [rango-escaneo-rango]"); // tag::rangeEscanearTodosLosDocumentos[] |
Para más información, consulte el Documentación de Couchbase KV Operations.
Consulta Exploración secuencial
Basándose en la funcionalidad KV Range Scan, Query Sequential Scan permite ahora realizar todas las operaciones CRUD de la base de datos utilizando SQL++ sin necesidad de un índice. Esta capacidad permite a los desarrolladores empezar a trabajar con la base de datos con conjuntos de datos pequeños sin tener que considerar los índices necesarios para las operaciones.
Desde el punto de vista de la consulta, el plan de consulta elegirá cualquier índice disponible para la consulta. Pero si no se encuentra ninguno, volverá a utilizar la búsqueda secuencial. El plan de consulta también mostrará el uso de la búsqueda secuencial en lugar de la búsqueda de índices.
| // Número de vuelos desde SFO->LHR por aerolínea SELECCIONE a.nombre, recuento_de_arreglos(r.horario) vuelos DESDE ruta r INTERIOR ÚNASE A aerolínea a EN r.aerolínea = a.iata DONDE r.sourceairport=OFS Y r.aeropuertodestino=LHR; |
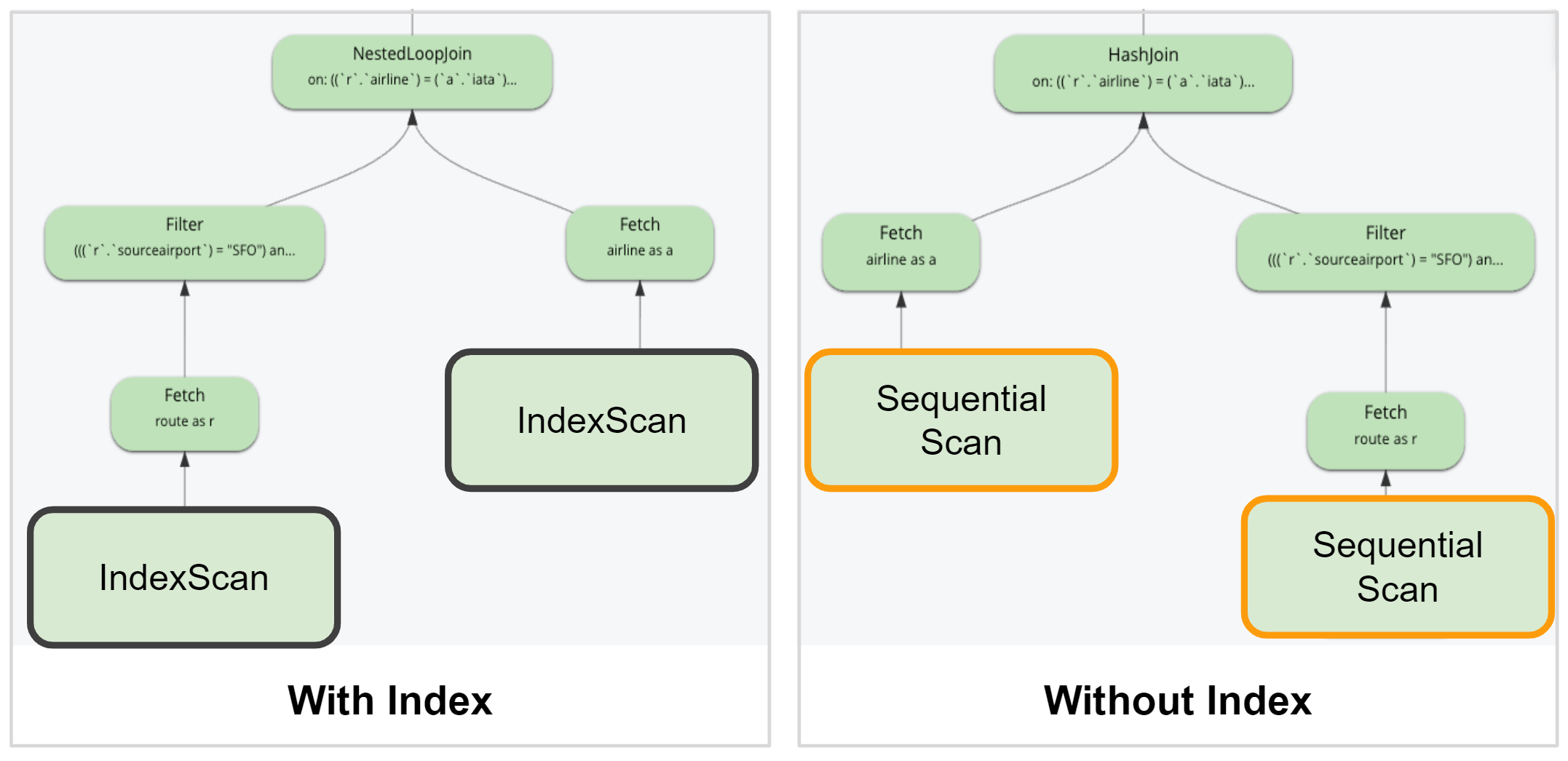
Tenga en cuenta que la búsqueda secuencial es adecuada para pequeños conjuntos de datos de desarrollo. Los índices deben seguir utilizándose cuando el rendimiento de la consulta sea una prioridad.
Para más información, consulte la documentación de Couchbase en exploraciones secuenciales.
Consulta de lectura de la réplica
La lectura desde réplica es parte de la característica de Alta Disponibilidad que está disponible con todos los servicios de Couchbase. Cuando se utiliza el SDK para las operaciones KV, una lectura desde réplica permite a la aplicación leer desde un nodo de datos con réplica vbucket cuando la copia activa podría no estar disponible, como por ejemplo durante un failover.
| pruebe { // Intento de lectura del nodo activo GetResult resultado = collection.get(documentKey); System.out.println("Documento del nodo activo: " + result.contentAsObject()); } captura (DocumentNotFoundException activeNodeException) { System.out.println("Falló la lectura del nodo activo, intentando lectura de réplica..."); // Si la lectura del nodo activo falla, intenta leer desde cualquier réplica disponible pruebe { GetReplicaResult replicaResult = collection.getAnyReplica(documentKey); System.out.println("Documento de réplica: " + replicaResult.contentAsObject()); } captura (Excepción replicaReadException) { System.err.println("Error al obtener el documento de la réplica: " + replicaReadException.getMessage()); } |
Sin embargo, este enfoque no puede aplicarse cuando la aplicación utiliza el SDK para ejecutar una consulta SQL++. Esto se debe a que la operación de obtención de datos ocurre en la capa de servicio de consulta. En el ejemplo de abajo, sin Query Read from Replica, si hay un problema con el nodo de datos activo desde el que se está obteniendo la consulta, la consulta devolverá un error de tiempo de espera a la aplicación. Realizar un reintento en la aplicación de abajo significaría volver a ejecutar toda la consulta de nuevo.
| pruebe { // Ejecutar una consulta N1QL Cadena statement = "SELECT * FROM QueryResult result = cluster.query(statement); // Iterar por las filas del conjunto de resultados para (filaConsulta : resultado.filas()) { System.out.println(fila); } } captura (QueryException e) { System.err.println("Consulta fallida: " + e.getMessage()); } |
Couchbase 7.6 ahora soporta Query Read from Replica. Esto significa que el servicio de consulta podría cambiar la conexión a un nodo de datos alternativo, si recibe un kvTimeout del nodo de datos del que se estaba obteniendo. La lógica de cambio a un nodo de datos diferente se realiza de forma transparente dentro del servicio de consulta, no se requiere ninguna acción por parte de la aplicación.
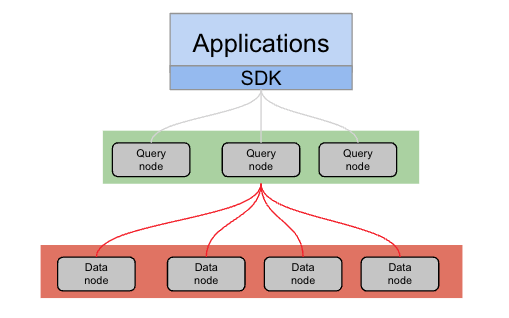
Al utilizar la lectura de consultas desde la réplica, las aplicaciones deben tener en cuenta las posibles incoherencias de los datos, especialmente en entornos con mucha actividad de escritura. La replicación continua de datos a través de nodos de datos significa que, a medida que el servicio de consulta cambia entre nodos durante las operaciones de obtención, pueden surgir incoherencias. Este escenario es más probable en sistemas que experimentan frecuentes actualizaciones de datos, donde el proceso de replicación podría provocar ligeros retrasos en la sincronización entre nodos.
Por esta razón, la aplicación tiene la opción de controlar la consulta de lectura desde la réplica. Esto se puede activar/desactivar en la configuración de nivel de solicitud, nodo o clúster.
Para más información, consulte el Documentación sobre la configuración de consultas de Couchbase.
Secuencia SQL
Ahora puedes usar SQL++ para crear un objeto secuencia que se mantiene dentro del servidor Couchbase. El objeto de secuencia genera una secuencia de valores numéricos que están garantizados para ser únicos dentro de la base de datos. Las aplicaciones pueden usar la secuencia SQL++ de Couchbase para asegurar un único contador para servir a múltiples clientes.
| // Crear sintaxis SEQUENCE
CREAR SECUENCIA [SI NO EXISTE] [SI NO EXISTE] [ CON ] |
Para más información, consulte el Documentación de secuencias de Couchbase.
Gracias por leer, esperamos que disfrute de estas nuevas funciones. Pronto publicaremos más artículos relacionados con la versión 7.6.