Ya se ha hablado mucho de los microservicios en los últimos años, pero veo con frecuencia que se desarrollan nuevos sistemas distribuidos con la vieja mentalidad de los monolitos. El efecto secundario de construir algo nuevo sin la comprensión de algunos conceptos clave es que terminarás con más problemas que antes, lo que definitivamente no es el objetivo que tenías en mente.
En este artículo, me gustaría abordar algunos conceptos que históricamente damos por sentados y que podrían conducir a una arquitectura deficiente cuando se aplican a los microservicios:
Realizar sólo llamadas síncronas
En una arquitectura monolítica, estamos acostumbrados a la disponibilidad "todo o nada", siempre podemos llamar a cualquier servicio en cualquier momento. Sin embargo, en un mundo de microservicios, no hay garantías de que un servicio del que dependemos esté en línea. Podría ser incluso peor, ya que un servicio lento puede ralentizar potencialmente todo el sistema, ya que cada hilo estará bloqueado durante un cierto tiempo mientras espera la respuesta del servicio externo.
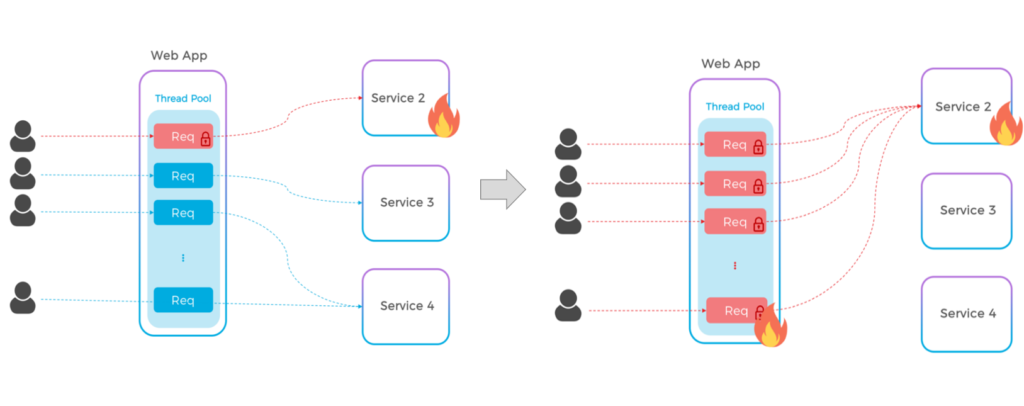
Cómo los subprocesos bloqueados/lentos acaban consumiendo todo tu pool de subprocesos
Todavía estamos aprendiendo cómo implementar correctamente las comunicaciones entre servicios, pero la regla general es hacer que todo sea asíncronoY ahí es donde surge uno de los primeros retos, porque históricamente no hemos ejercitado lo suficiente nuestra capacidad de transformar un flujo síncrono en asíncrono.
Afortunadamente, la mayoría de los casos de uso pueden implementarse de forma asíncrona con el esfuerzo adecuado. Amazon, por ejemplo, implementó todo su sistema de pedidos de esa manera, y apenas siente ello. Es casi seguro que le permitirán realizar un pedido con éxito, pero si hay algún problema con el pago o si el producto está agotado, recibirá una notificación por correo electrónico unos minutos u horas más tarde informándole de ello y de las medidas que debe tomar. La ventaja de este enfoque es clara: aunque el servicio de pago o de existencias no funcione, no impedirá que los usuarios hagan un pedido. Es lo bueno de la comunicación asíncrona.
Por supuesto, no todo en tu sistema puede ser asíncrono, y para hacer frente a los problemas comunes de las llamadas síncronas como la inestabilidad de la red, la alta latencia o la indisponibilidad temporal de los servicios, tuvimos que idear un conjunto de patrones para evitar fallos en cascada como cachés locales, tiempos de espera, reintentos, interruptores automáticos, mamparas, etc. Existen muchos frameworks que implementan estos conceptos, pero el Netflix Hystrix es actualmente la biblioteca más conocida.
No hay nada esencialmente malo en este enfoque; funciona bastante bien para varias empresas. El único inconveniente es que estamos imponiendo una responsabilidad adicional a cada servicio, lo que hace que tu microservicio sea aún menos "micro". En los dos últimos años se han propuesto algunas opciones para resolver este problema. El patrón Service Mesh, por ejemplo, intenta externalizar esta complejidad en forma de contenedor sidecar :
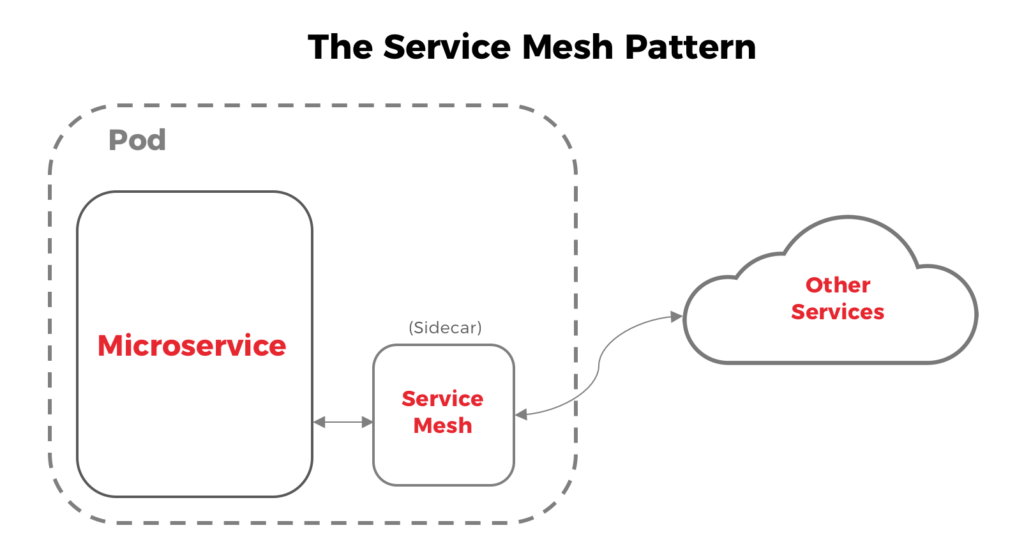
Personalmente me gusta este enfoque, especialmente porque es agnóstico al lenguaje, lo que significa que funcionará para todos tus microservicios independientemente del lenguaje en el que estén escritos. Otra ventaja son las métricas estandarizadas, ya que diferentes librerías/frameworks pueden usar un algoritmo ligeramente diferente para reintentos, tiempos de espera, interrupciones de circuito, etc. Esas pequeñas diferencias podrían impactar significativamente en las métricas generadas, haciendo imposible tener una visión fiable del comportamiento del sistema.
ACTUALIZACIÓN: Si quieres leer más sobre el patrón Service Mesh, consulte esta excelente presentación.

En resumen, pensar en cómo se comunicarán los servicios entre sí es esencial para el éxito de una arquitectura, y debe planificarse con antelación para evitar una cadena de dependencias. Cuanto menos se conozcan los servicios entre sí, mejor será la arquitectura.
Utilizar RDBMS para todo
Tras 30 años de monopolio de los RDBMS, es comprensible que mucha gente siga pensando así. Sin embargo, hoy en día, prácticamente cada día nace una nueva base de datos (y dos frameworks de JavaScript). Si antaño elegir una base de datos era cuestión de escoger una entre cinco, hoy la misma tarea exige mucha más atención.
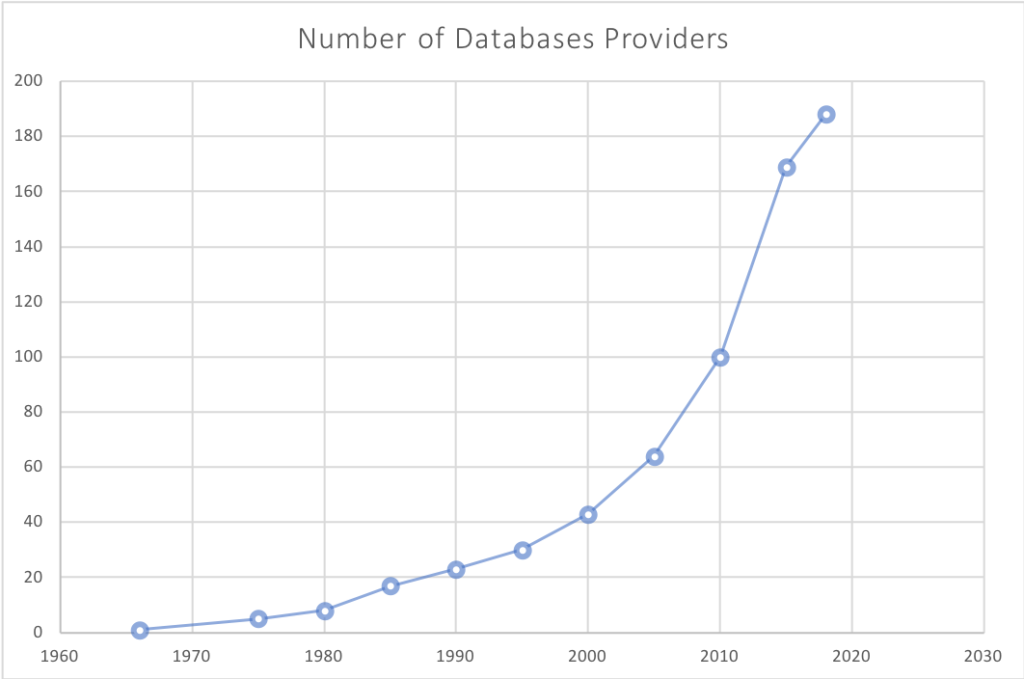
Fuente: db-engines.com - fechas de lanzamiento iniciales
En Martin Fowler dijo Hace 12 años, la elección de un sistema de almacenamiento especializado ofrecía muchas ventajas: mayor rendimiento, menor coste, etc. No voy a perder el tiempo repasando todos los inconvenientes de los RDBMS (lecturas lentas, datos dispersos, desajuste de impedancias, uniones, etc.). Más bien, me gustaría destacar una vez más que la base de datos desempeña un papel fundamental en el rendimiento general del sistema, y que una elección inadecuada acabará costándole mucho más dinero.
Las ventajas de la persistencia políglota están muy claras, y la madurez de las soluciones ha quedado demostrada por numerosos casos de uso crítico con éxitosólo por nombrar algunos: Pokémon Go, AirBnB, Viber, eBay, Cielo, Amadeus, Amazon, Google, LinkedIn y Netflix
Hace cinco años habría estado de acuerdo con el argumento de la "curva de aprendizaje" de por qué aún no se ha empezado con NoSQL. Sin embargo, desde entonces, mucho ha cambiado, y algunas empresas han puesto mucho esfuerzo en hacer que sea realmente fácil para los desarrolladores y DBAs, como el Couchbase Spring Boot/Spring Data o el recientemente lanzado Operador de Kubernetes que pretende automatizar la mayor parte del trabajo de los DBA.
No pensar en la depuración y la observabilidad
Un día, acabas teniendo un fallo distribuido que propaga las incoherencias por todo tu sistema. Entonces, te das cuenta de que no hay una manera fácil de entender dónde están fallando las cosas: ¿Fue un error? ¿Fue un problema de red? ¿El servicio no estaba disponible temporalmente?
Por eso tienes que planificar de antemano cómo vas a depurar tu sistema. Con suerte, para redes un Service Mesh podría ser una solución rápida, y para registro distribuido, herramientas como FluentD o Logstash son útiles. Pero, cuando hablamos de entender cómo una entidad ha llegado a un estado concreto, o incluso de cómo correlacionar datos entre servicios, no existe ninguna herramienta fácil.
Para solucionar este problema, puede utilizar Registro de eventos. En este patrón, cada servicio almacena (y valida) todos los cambios en el estado de la aplicación en un objeto de eventos y, naturalmente, siempre que necesites comprobar qué ha pasado con una entidad en particular, todo lo que tienes que hacer es navegar por todo el registro de eventos relacionados con ella.
Si además añades el versionado a tu estado, arreglar las inconsistencias será aún más fácil ahora, ya que tendrás la posibilidad de arreglar los mensajes inconsistentes simplemente estableciendo el estado del objeto al que estaba antes, y luego volver a reproducir todos los mensajes recibidos desde el problemático en adelante.
Tanto el versionado como el registro pueden hacerse de forma asíncrona, y probablemente no consultes estos datos a menudo, lo que lo convierte en una solución interna barata para depurar/auditar tu sistema. Voy a publicar la próxima semana una inmersión profunda en este patrón, así que espera una semana.
Hay muchos otros frameworks/patrones para ayudarte a depurar tus microservicios, pero todos ellos suelen exigir una única estrategia distribuida para funcionar. Desafortunadamente, en el momento en que te das cuenta de que necesitas tal cosa, ya es demasiado tarde y tendrás que pasar una cantidad significativa de tiempo refactorizando todo el asunto. Esa es una de las principales razones por las que necesitas definir cómo vas a observar/depurar tu sistema antes incluso de empezar.
Si tiene alguna pregunta, no dude en tuitearme en @deniswsrosa