La replicación de datos tradicional requería gestionar un montón de piezas móviles en su aplicación. La replicación de datos moderna la lleva a la nube, donde los sistemas backend hacen la mayor parte del trabajo pesado. Pero la replicación de datos en la nube es algo más que sincronizar datos o hacer copias de seguridad en servidores remotos. Esta guía presenta algunos casos de uso comunes para la replicación de datos en la nube, revisa algunos métodos para implementarla e identifica cómo cambia las reglas del juego para el desarrollo de aplicaciones modernas.
¿Qué es la replicación de datos en Cloud Computing?
La replicación de datos es el proceso de mantener copias redundantes de los datos primarios. Esto es importante por varias razones, como la tolerancia a fallos, la alta disponibilidad, las aplicaciones de lectura intensiva, la reducción de la latencia de la red o el apoyo a los requisitos de soberanía de datos.
Tolerancia a fallos: La replicación de datos es necesaria cuando las aplicaciones deben preservar los datos en caso de fallo del hardware o de la red debido a causas que van desde que alguien tropiece con un cable eléctrico hasta una catástrofe regional como un terremoto. Así pues, toda aplicación necesita la replicación de datos para resistir y mantener la coherencia.
Alta disponibilidad: Los datos a los que acceden con frecuencia muchos usuarios o sesiones concurrentes necesitan replicación de datos. En este caso, los datos replicados deben mantener la coherencia con su líder y otras réplicas.
Reduzca la latencia: La replicación de datos también ayuda a las modernas aplicaciones en nube a ejecutar datos distribuidos en diferentes redes o regiones geográficas que sirven mejor al usuario final.
En resumen, no se trata sólo de la gestión de copias de seguridad y desastres, sino también del rendimiento de las aplicaciones. Sumerjámonos en cómo funciona la replicación y comprendamos estas necesidades un poco más a fondo.
¿Cómo funciona la replicación de datos?
Un plan de replicación adecuado instituye políticas que mantienen una o más copias de cada pieza de datos, de modo que si se pierde cualquier pieza, al menos una, idealmente más, alternativas están disponibles.
A nivel de aplicación, esto se parece a almacenar algunos registros de datos en una ubicación maestra y que el sistema backend mantenga copias de esos datos como réplicas. Puede ser complicado crear un servicio personalizado para copiar todos los datos a otro sitio; mantenerlos sincronizados es un serio reto de ingeniería. Asimismo, almacenar todas las réplicas en la misma ubicación hace que sea vulnerable a desastres en esa ubicación, que acaben con todas las réplicas.
Por lo tanto, la replicación divide los conjuntos de datos primarios en piezas virtuales más pequeñas, conocidas como particiones. Cada partición se replica, idealmente en diferentes ubicaciones del disco, en otras redes, en volúmenes de almacenamiento redundantes o utilizando varias plataformas en la nube y diferentes servidores remotos en bastidores segregados.
El potencial de complejidad es a menudo el factor limitante para las empresas que tratan de aplicar las mejores prácticas de replicación de datos: contar con sistemas frontales y de backend que lo gestionen de forma transparente es esencial.
Replicación de datos en la nube frente a replicación de datos tradicional
Hay varios niveles de opciones de replicación de datos: la replicación de datos en la nube es uno de ellos. La replicación de datos tradicional tiene algunas opciones para replicar datos hacia y desde otras fuentes, como de un dispositivo móvil a un PC local o de un PC local a una base de datos en red. Una base de datos en red también puede replicarse a una red externa con fines de copia de seguridad.
La mayoría de estos casos de uso eran sencillos y sólo pretendían preservar los datos en caso de fallo, pero requerirían trabajo manual para volver a ensamblar las piezas mientras se estaba fuera de línea. Por lo general, las aplicaciones no podían acceder directamente a las réplicas hasta que los nodos primarios fallaban y las réplicas se convertían en "activas" y tomaban el relevo de ese maestro.
La replicación de datos en la nube la lleva un nivel más arriba, permitiendo a las aplicaciones enviar datos a múltiples servicios de almacenamiento o datos basados en la nube que, a su vez, envían réplicas a otros recursos basados en la nube. Estos recursos imitan en algunos aspectos la replicación de datos tradicional, pero la extienden a la nube.
Subamos por la pila desde los escenarios más básicos a los más avanzados para la planificación de recursos en la nube.
La replicación más básica utilizaría varias máquinas basadas en la nube en el mismo centro de datos, es decir, un clúster de base de datos con varios nodos, tal vez incluso en el mismo rack de servidores en la misma red. A continuación, la distribución a nivel de bastidor distribuye los nodos de datos en más de un bastidor de hardware.
La siguiente etapa reparte los datos entre distintas ubicaciones geográficas de una red, por ejemplo, regiones o zonas. Una base de datos puede almacenar los datos maestros en San Francisco y réplicas en Nueva York y Londres. Esto es replicación entre centros de datoscomo se ve en sistemas como Couchbase, que gestionan la distribución de nodos entre bastidores.
¿Qué es la replicación de datos de nube a nube?
Otro nivel en la escalera de la replicación es entre múltiples nubes. La replicación en la nube en AWS puede parecer similar a la de Google Cloud, pero las aplicaciones sofisticadas pueden beneficiarse significativamente al tener servicios de datos replicados entre más de un proveedor de servicios en la nube.
Una opción moderna de nube híbrida utiliza su red local como copia maestra y múltiples servicios en la nube o distintas regiones dentro de una nube como parte de la replicación. Lo ideal es que todos los nodos de este diseño sean accesibles a las aplicaciones (para lectura y escritura) incluso cuando no hay ningún desastre en juego.
Antes de entrar en más detalles, es importante saber que hay muchas maneras de diseñar una topología de replicación para diferentes niveles de redundancia y rendimiento. Los diferentes diseños incluyen unidireccional, bidireccional, hub y spoke, circular, etc. Esta guía no prescribe una topología específica en detalle, sino que comparte algunos de los conceptos subyacentes en general.
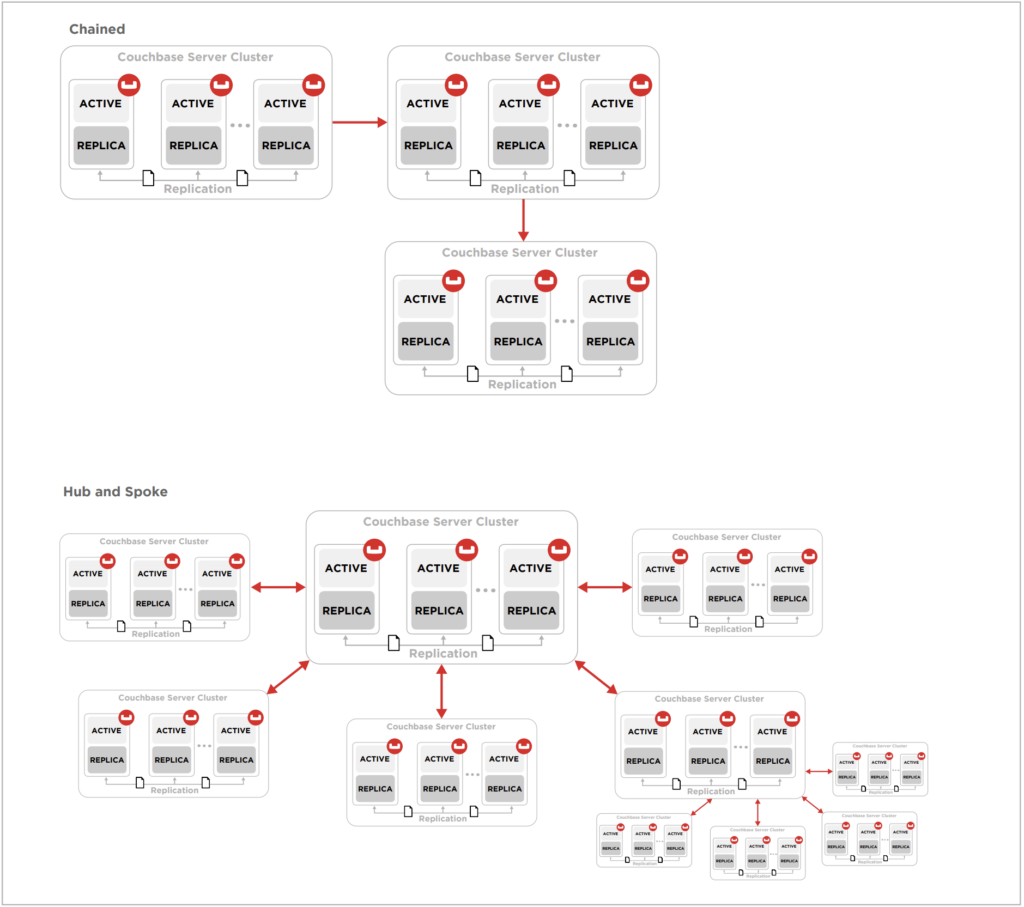
Algunas de las topologías de replicación más complejas
¿Por qué replicar los datos en la nube?
Hay diferentes razones para replicar datos en la nube. La red privada de una empresa puede ser redundante, pero necesita una mayor distribución geográfica. La replicación en la nube permite a la organización mantener los datos de su red privada pero disponer de redundancia en caso de desastre. Los distintos niveles de redundancia basada en la nube descritos anteriormente ayudan a prevenir los daños provocados por distintos niveles de desastres: locales, específicos del centro de datos, fallos de bastidores, etc.
La replicación en la nube añade otro nivel de redundancia, lo que contribuye a la alta disponibilidad, pero también le ayuda a evitar la dependencia del proveedor. Si un proveedor de servicios en la nube tiene problemas, puede cambiar rápidamente a otro con una interrupción mínima.
Ventajas en el rendimiento de las aplicaciones
Los escenarios de desastre no son la única razón para utilizar la replicación de datos en la nube, también puede hacer que sus aplicaciones funcionen más rápido, especialmente las aplicaciones móviles. Los sistemas modernos permiten a las aplicaciones utilizar las réplicas como fuentes de datos para las aplicaciones. Los métodos tradicionales las mantenían como meras copias de seguridad que podían activarse en caso necesario, simplificando intencionadamente la sincronización al tener una sola copia maestra.
Con las réplicas activas disponibles, los desarrolladores de aplicaciones pueden elegir si se ejecutan sobre datos en una ubicación o red diferente. Esto es fundamental para reducir la latencia de la red en aplicaciones de alto rendimiento.
Los juegos, por ejemplo, requieren operaciones de alta velocidad y gran ancho de banda, por lo que las aplicaciones se dirigen al servidor más cercano siempre que sea posible. Las réplicas de los datos siguen estando disponibles en todo el mundo, pero se prefiere una ubicación. Por ejemplo, acceder a los datos en Norteamérica llevaría más tiempo que si hubiera una copia disponible en Asia, donde vive el usuario.
Replicación de datos en la nube para recuperación en caso de catástrofe
Las necesidades modernas de recuperación en caso de catástrofe exigen algo más que simples copias de datos repartidas por todo el mundo. Las políticas de recuperación eficaces exigen que los datos estén distribuidos de forma redundante para evitar catástrofes geográficas, pero también deben estar disponibles para el cambio en tiempo real cuando se produce un fallo.
Las empresas no pueden permitirse esperar a que se produzca un fallo para enviar a su equipo a repararlo. En su lugar, los arquitectos diseñan sistemas de datos que anticipan los fallos, los mitigan mediante la conmutación por error inteligente a nuevos nodos y ayudan a los equipos de DevOps a solucionar el problema lo antes posible. La intervención manual suele significar tiempo de inactividad, algo que nadie desea, por lo que los backends automatizados para la conmutación por error y la recuperación son esenciales.
Lo anterior se aplica tanto a los datos en la nube como a los locales, con la salvedad de que los sistemas pueden utilizar recursos basados en la nube para ayudar a identificar y solucionar fallos de varias formas distintas.
El backend de los servicios en la nube puede ayudar a mantener actualizados entre sí los nodos distribuidos gracias a la sólida interconectividad de sus redes. Múltiples nodos en Google Cloud, por ejemplo, aunque estén distribuidos geográficamente, pueden hacer que sea rápido y sencillo mantener la sincronización sin necesidad de que los servidores locales de la empresa envíen datos a otras ubicaciones.
Apoyar el crecimiento de los servicios de datos
Los servicios en nube también están diseñados para ser elásticos y crecer según las necesidades. Por ejemplo, si falla el disco de un nodo, el servicio en nube puede poner en marcha un nuevo recurso, replicar los datos y eliminar el que falla. Los sistemas automatizados de la nube pueden hacer esto más rápido de lo que tarda un gestor de datos en darse cuenta de que hay un problema.
Asimismo, dado que los recursos son prácticamente ilimitados en la nube, a medida que crece el uso de recursos/datos, el servicio en la nube puede reajustar la partición y cambiar a máquinas más grandes o añadir más nodos según sea necesario.
Como los servicios en nube existen a escala mundial, las aplicaciones pueden probar y descubrir qué réplicas de sus datos serían las mejores para usuarios concretos, en función de su ubicación. Si un servicio de datos deja de estar disponible o la latencia alcanza un determinado umbral, las aplicaciones pueden trasladarse a otra región y seguir funcionando.
Código personalizado para gestionar la replicación
Como puede ver, el potencial de replicación de datos inquebrantable se ha hecho posible con los servicios basados en la nube. Sin embargo, la codificación de la inteligencia en su aplicación puede ser un reto, ya que el aumento del potencial también aumenta la complejidad.
El desarrollo personalizado de una solución sólida es costoso y complejo de mantener. Lo ideal sería que su backend de gestión de datos se encargara de todo por usted. Compruebe si sus sistemas disponen de opciones fáciles de usar para configurar réplicas entre nodos, bastidores, regiones, etc. Si no es así, considere la posibilidad de encontrar una alternativa mejor antes de comprometerse a invertir las miles de horas necesarias para crear la suya propia.
Couchbase es un ejemplo de base de datos que ayuda a gestionar todo esto por ti, proporcionando opciones para elegir cómo equilibrar entre alta disponibilidad y alto rendimiento. Contar con estas opciones permite aplicar planes de recuperación ante desastres desde el primer día y gestionar los costes de infraestructura en el futuro.
Más información
En resumen, la replicación tradicional puede exigir servidores cada vez más grandes, pero la replicación de datos en la nube permite flexibilidad a medida que crece y ofrece opciones para que todo funcione sin problemas. Lea nuestro artículo técnico: Alta disponibilidad y recuperación ante desastres para datos distribuidos globalmente para más información sobre las distintas topologías y enfoques que recomendamos.
¿Está listo para probar las ventajas de la replicación de datos en la nube con sus propias aplicaciones?
Empieza con Couchbase Capella:
-
- Comienza tu prueba gratuita y vea lo fácil que es empezar con Couchbase
- Más información sobre Capella y ver el vídeo de demostración
- Vea más vídeos sobre Couchbase en nuestra Canal YouTube