Los clientes utilizan XDCR para diversos casos de uso, desde alta disponibilidad hasta localización de datos, recuperación en caso de catástrofe o migración a la nube y despliegues de nube híbrida. Para satisfacer estos casos de uso, hay una serie de circunstancias en las que querrían replicar sólo un subconjunto de datos a un clúster diferente. Hace un par de años introdujimos el filtrado basado en claves para permitir la replicación filtrada. Con la versión 6.5, ampliamos esta funcionalidad para proporcionar capacidades de filtrado avanzadas con XDCR. claves, valores y metadatos utilizando una sintaxis similar a N1QL en la que puede construir expresiones de filtrado para filtrar datos basándose en su lógica de negocio.
El filtrado avanzado ofrece la posibilidad de filtrar la replicación en dos categorías diferentes:
a.Filtrado basado en expresiones
Las expresiones de filtrado se aplican a los datos del bucket de origen. El filtrado avanzado admite varias construcciones de lenguaje para crear filtros como regex, operadores aritméticos, lógicos y relacionales, palabras clave, expresiones, funciones numéricas, funciones de fecha, lookahead negativo, etc., sobre claves, valores, metadatos y CAS. Al igual que los predicados de las consultas N1QL, las expresiones pueden construirse utilizando las construcciones de lenguaje soportadas.
Creemos que este filtrado basado en expresiones es extremadamente útil para filtrar datos mediante la construcción de expresiones relevantes para las necesidades del negocio, como los casos de uso de geo-vallas.
A continuación se muestra el campo donde se introduce la expresión y el ID del documento para probar la expresión del filtro
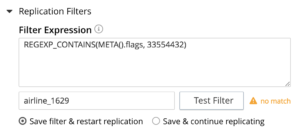
Una vez que tenga una expresión de filtro, puede probar la expresión especificando el ID del documento en el campo mencionado. Si el documento concreto coincide con la expresión de filtrado, recibirá una notificación al respecto. Si no, puede utilizar otro ID de documento para validar. Si la expresión no coincide, recibirá una notificación de no coincidencia. Puede modificar el filtro o utilizar un ID de documento diferente para validar el filtro.
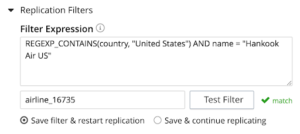
Si la expresión coincide con el filtro, se le notificará la coincidencia, que es una validación de la expresión del filtro.
Edición de la expresión del filtro
Los filtros también pueden editarse sobre la marcha y la replicación continuará sin pausa/reanudación.
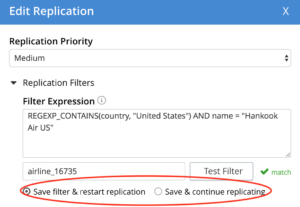
Una vez editado el filtro, los clientes pueden elegir reiniciar la replicación o continuar replicando sin reiniciar. Por defecto se reinicia la replicación.
XDCR, por defecto, no vaciará ningún cubo cuando se modifiquen los filtros. Este paso debe ser ejecutado manualmente por el administrador si es necesario.
b. Filtrado por supresión
Por diseño, XDCR replica todo, incluidos los borrados, para mantener la coherencia. Con el filtrado avanzado en 6.5, estamos proporcionando la capacidad de replicar filtrando los borrados / documentos con TTL o eliminar los TTL y la replicación para que los documentos de destino no tengan TTL. También puede optar por eliminar el TTL de los documentos y replicarlos.
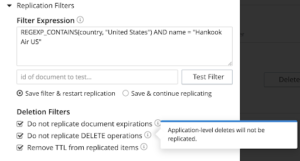
Esta capacidad abre las puertas a nuevos casos de uso de XDCR, como un clúster frío y caliente en el que se desea replicar sólo los documentos activos o eliminar TTL y almacenarlo con fines de archivo.
Si tu versión de Couchbase es inferior a 6.5, sólo podrás filtrar por claves.
Si utiliza la versión 6.5 o superior, puede filtrar por claves, valores, metadatos ampliados o una combinación de los tres.
Al replicar sólo lo necesario, los clientes pueden tener una mejor utilización de los recursos en términos de ancho de banda, almacenamiento y rendimiento.
Recursos
Descargar
Descargar Couchbase Server 6.5
Documentación
Notas de la versión de Couchbase Server 6.5
Novedades de Couchbase Server 6.5
Blogs
Blog: Anuncio de Couchbase Server 6.5 - Novedades y mejoras
Blog: Couchbase lleva las Transacciones Distribuidas Multidocumento ACID a NoSQL
Hola Chaitra,
Usted ha mencionado "Por defecto es réplication reinicio". ¿Qué significa eso exactamente?
Gracias