Transacciones ACID son imprescindibles cuando se tienen requisitos estrictos de coherencia de datos en la aplicación. Los costes de ejecutar transacciones en sistemas distribuidos pueden crear rápidamente cuellos de botella a escala. En este artículo, te daremos una visión general de algunos de los retos a los que se enfrentan las bases de datos NoSQL y NewSQL. Luego, profundizaremos en cómo Couchbase implementó un modelo de transacciones distribuidas escalable sin coordinación central y sin punto único de fallo. Además, también daré una breve visión general de cómo se ve el soporte para transacciones en N1QL en Couchbase 7.0.
Se han omitido algunos detalles menores en aras de la simplicidad.
Transacciones relacionales vs NewSQL vs NoSQL
Antes de empezar a explicar cómo Couchbase implementó el soporte para transacciones, necesito explicar primero las características inherentes de la atomicidad en bases de datos relacionales y NoSQL (usando modelos de datos semi-estructurados como JSON):
Atomicidad en RDBMS
Supongamos que necesita guardar un nuevo usuario en la base de datos. Naturalmente, como tiene muchas otras tablas asociadas, insertar un usuario también requerirá inserciones en muchas otras tablas:
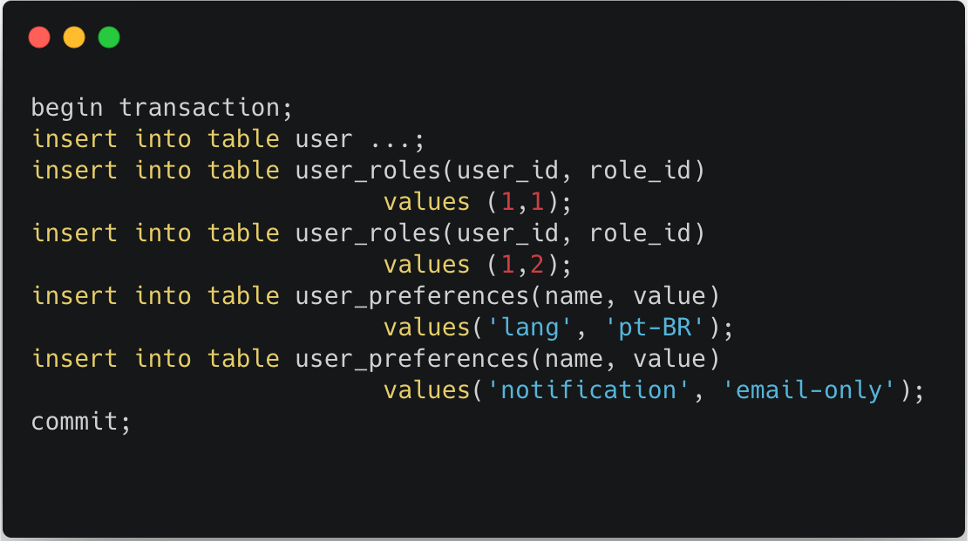
Dado que el modelo relacional te obliga a almacenar todo en "cajas" y a dividir tus datos en pequeños trozos, añadir un nuevo usuario siempre debe ejecutarse dentro de un contexto transaccional. De lo contrario, si una de tus inserciones falla, tu usuario acabará a medias. Observe cómo un RDBMS depende en gran medida de las transacciones, ya que las aplicaciones son mucho más complejas que cuando se diseñó originalmente el modelo relacional allá por los años setenta.
Por suerte, como estas bases de datos están diseñadas para ejecutarse en un único nodo, puede utilizar un coordinador de transacciones central para consignar los datos de una vez sin que ello afecte al rendimiento.
Atomicidad en NewSQL
En el lado NewSQL (relacional distribuida), las cosas son un poco más complicadas. Como la mayoría de estas bases de datos reutilizan el modelo relacional, los datos de tu entidad (o raíz agregada) tiende a repartirse entre varios nodos.
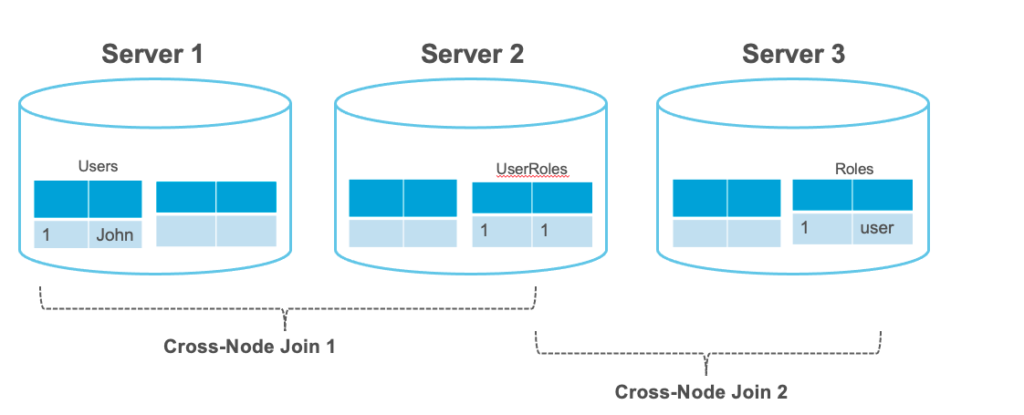
En la imagen de arriba, si necesitamos cargar el usuario en memoria, primero tendríamos que obtener el usuario del Servidor 1, luego cargar la asociación entre usuarios y roles en el Servidor 2 y finalmente cargar el rol de destino desde el Servidor 3. Esta simple operación requiere que los datos viajen al menos dos veces por la red, lo que en última instancia limitará su rendimiento de lectura. En un escenario real, un usuario tiene muchas más tablas asociadas a él. Esta es la razón por la que la relacional distribuida todavía no es práctica cuando se necesita leer/escribir lo más rápido posible.
Puedes intentar minimizar los problemas anteriores limitando el tamaño de tu clúster, confiando mucho en los índices para rastrear todas las relaciones, o mediante algunas técnicas de fragmentación para mantener todos los datos relacionados en el mismo nodo (lo cual es difícil de implementar en la práctica). Los dos últimos enfoques, aunque estén bien implementados, consumirán importantes recursos de la base de datos para ser gestionados adecuadamente.
Las transacciones ACID en bases de datos NewSQL requieren más coordinación que en NoSQL, ya que los datos relacionados con una entidad se dividen en múltiples tablas que pueden vivir en diferentes nodos. El modelo relacional, tal y como lo utilizamos hoy en día, requiere transacciones para la mayoría de las escrituras, actualizaciones y eliminaciones en cascada. La coordinación adicional que requiere la arquitectura NewSQL tiene el coste de reducir el rendimiento de las aplicaciones que requieren operaciones de baja latencia.
Atomicidad en las bases de datos de documentos
El uso de datos semiestructurados como JSON puede reducir drásticamente el número de "uniones entre nodos" y, por tanto, mejorar el rendimiento de lectura y escritura sin necesidad de recurrir en exceso a la indexación. Esta fue una de las principales conclusiones del estudio Papel Dynamo (publicado por primera vez hace ~13 años) que fue el catalizador para crear las bases de datos NoSQL tal y como las conocemos hoy.
Otra característica interesante de un modelo de datos semiestructurado es que es menos transaccional, ya que podrían caber todos los datos del usuario en un solo documento:
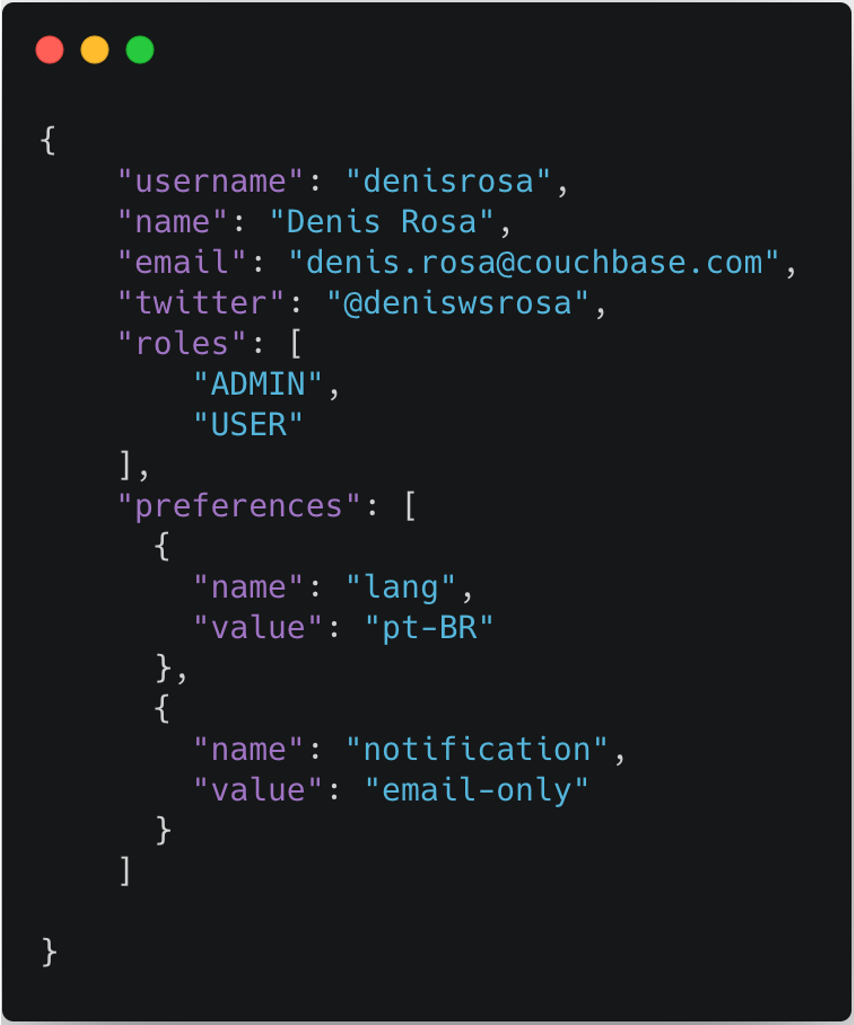
Como se puede ver en la imagen superior, las preferencias y roles de los usuarios caben fácilmente dentro de un "Documento de Usuario", por lo que no es necesaria una transacción para insertar o actualizar un usuario ya que la operación es atómica. O insertamos el documento o falla toda la operación. Lo mismo es válido para muchos otros casos de uso comunes: carros de la compra, productos, estructuras de árbol, y raíces agregadas en general.
En la mayoría de las aplicaciones que utilizan bases de datos de documentos, 90% de las operaciones transaccionales corresponderán a esta categoría de documento único. Pero... ¿qué pasa con los otros 10%? Bueno, para esas necesitaremos soporte transaccional multi-documento, que ha sido añadido en Couchbase desde la versión 6.5 y es el foco principal de este artículo.
Aquí tienes una presentación sobre transacciones que se realizó en Couchbase Connect 2020. Matt Ingenthron te da una explicación de cuándo y por qué podrías necesitar transacciones ACID multi-documento:
Vea la versión completa en https://www.youtube.com/watch?v=2fsZVe2cT3M&ab_channel=Couchbase
Transcripción del vídeo
Haga clic para leer la transcripción completa.
Vamos a hablar de cómo se aplica esto a un ejemplo ficticio, pero tal vez algo realista, de un modelo de documento para un sistema Couchbase. Así que hemos recaudado algo de dinero, y vamos a construir un juego de rol multijugador masivo en línea (un MMORPG), con jugadores y monstruos. Así que necesitamos un modelo de datos.
Vamos a tener jugadores que luchan contra monstruos y, a continuación, sobre la base de esa lucha, ganar o perder, van a. Si ganan, van a conseguir un arma, si pierden, eh, pierden algunos puntos de golpe para que nadie pueda morir. Siempre se puede volver a la vida, siempre se puede encontrar otro día. Pero sus jugadores luchar contra monstruos, y tenemos nuestra versión 1.0 construido. ¡Genial! Bien, conseguimos nuestra financiación, conseguimos nuestra 1.0 construida.
El problema es que nos olvidamos de la parte multijugador masivo. No hay juego colaborativo. No puedo tener múltiples jugadores luchando contra el mismo monstruo. Así que tengo que arreglar eso, ¿verdad? Así que vamos a lanzar una nueva versión. Así que los jugadores van a seguir luchando contra monstruos y ganando armas.
Así que lanzamos nuestra versión 2.0, y en la versión 2.0 los jugadores pueden luchar juntos contra los monstruos. Puedo coordinar con mis amigos, podríamos ir a buscar un monstruo, y podemos matar a ese monstruo.
Pero dejamos un error ahí. Es posible que varios jugadores asesten el golpe mortal y la razón de que eso sea un problema es que los jugadores del juego se dan cuenta. En lugar de luchar contra un monstruo juntos hasta la muerte, lo que hacen es, ellos, en este mundo multijugador masivo, luchar hasta casi la muerte, y luego un grupo de jugadores se reunirán, y todos ellos asestarán el golpe mortal o muchos asestarán el golpe mortal al mismo tiempo.
El problema es que ganan objetos, ganan múltiples objetos, y como los objetos tienen rareza, y si no tienes una cierta cantidad de rareza para un objeto, el juego no es muy interesante. Este error ha permitido que existan demasiados objetos en el mundo, y los jugadores se pasan el tiempo pirateando el juego, y luego se aburren y lo abandonan. Tenemos que mantener la jugabilidad interesante.
Así que pensemos en esto. ¿Cómo podemos arreglarlo? Creo que lo que tendremos que hacer es probablemente introducir un arreglo. Seguiremos permitiendo que jugadores y monstruos, varios jugadores luchen contra un monstruo. Pero lo que vamos a hacer es tomar uno de esos trucos que tenemos, vamos a tomar Couchbase CAS Operaciones.
Con el Operación CAS lo que ocurre es que ahora varios jugadores están luchando contra ese monstruo, reduciendo sus puntos de vida hasta que llega a cero. Pero sólo uno de esos jugadores será capaz de asestar el golpe mortal a ese monstruo y ganar un objeto.
Así que la forma en que esto funciona es si dos jugadores están tratando de dar ese golpe mortal, la aplicación servidor que está manejando la solicitud va a tratar de modificar el documento. Tiene que recoger una pequeña pieza de información opaca que llamamos el CAS (siglas de Check And Set)y eso significa que si ese opaque no coincide, entonces los documentos ya han sido modificados, por lo que hay que reintentar esa operación. En el escenario de que dos actores dentro del sistema están tratando de agarrar ese documento al mismo tiempo, lo que queremos es que uno tenga éxito y otro falle, y el CAS nos dará eso de una manera muy eficiente.
Sacamos ese truco, introducimos operaciones CAS, se arregla el fallo, la jugabilidad es ahora mucho más interesante y la 2.1 lo hace realmente bien, así que estupendo.
Así que ahora vamos a intentar un , eh, queremos seguir adelante, queremos hacer las cosas más interesantes. Imagina ahora que introduzco otra característica: "Los jugadores pueden seguir luchando juntos contra los monstruos, pero tienen que hacerlo fuera de la ciudad. Así que tienen que estar fuera de la muralla de la ciudad donde están los jugadores, y si entran en la ciudad, harán comercio en un bizarro"
Esto funciona muy bien al principio, pero luego los jugadores se dan cuenta de algo.
Así que imagina jugador1, tengo que recuperar el documento para jugador1. Luego tengo que recuperar el documento para el jugador2. Luego tengo que mover la espada del jugador1 al jugador2, eso es muy fácil de hacer en la lógica de la aplicación, y luego voy a almacenar ese cambio de nuevo al sistema con la operación CAS, y luego voy a almacenar el otro cambio de nuevo, ¿verdad? Suena como que va a ser grande. Excepto que hay un error.
El error aquí es que mis jugadores pueden empezar un intercambio y luego desconectarse, y entonces los objetos que podríamos querer que fueran raros no van a ser raros. Pueden ser duplicados dentro del sistema.
En los juegos de rol multijugador masivos en línea, se llama "Dup Bug". Si vas a Google y buscas "Dup Bug", encontrarás un montón de escenarios.
Aquí hay uno de hace sólo un par de semanas, donde Final Fantasy Crystal Chronicles en Switch tuvo que ser parcheado debido a un bug Dup. Y luego había uno sólo unos días antes de que, esto es de un blog donde un blogger juego mostrando a la gente cómo utilizar este glitch dup para recuperar... para obtener artículos adicionales dentro del juego.
Así que tenemos que arreglar este fallo. ¿Cómo vamos a hacerlo? Bueno, vamos a echar mano de nuestra bolsa de trucos de Couchbase.
Vamos a introducir las transacciones Couchbase. El modo de juego es casi exactamente el mismo. Pero, ¿qué vamos a hacer con las transacciones Couchbase? Y esta es la diapositiva donde voy a hablar un poco sobre el código.
Transacciones ACID distribuidas multidocumento en Couchbase
Ahora que entiendes cómo se comportan las transacciones en diferentes modelos de datos, es hora de profundizar en cómo lo hemos implementado en Couchbase y qué nos llevó a tomar nuestras decisiones de diseño. En primer lugar, vamos a repasar la sintaxis:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
transacciones.ejecute((ctx) -> { // obtener los documentos de cuenta para el usuarioA y el usuarioB TransactionJsonDocument usuarioA = ctx.getOrError(colección, "usuarioA"); JsonObject userAContent = usuarioA.contentAsObject(); int userABalance = userAContent.getInt("saldo_cuenta"); TransactionJsonDocument usuarioB = ctx.getOrError(colección, "Beth"); JsonObject userBContent = usuarioB.contentAsObject(); int userBBalance = userBContent.getInt("saldo_cuenta"); // si el usuarioB tiene fondos suficientes, realiza la transferencia si (userBBalance > transferAmount) { userAContent.poner("saldo_cuenta", userABalance + transferAmount); ctx.sustituir(usuarioA, userAContent); userBContent.poner("saldo_cuenta", userBBalance - transferAmount); ctx.sustituir(usuarioB, userBContent); } si no tirar nuevo InsufficientFunds(); }); |
El ejemplo Java anterior es el ejemplo clásico de cómo transferir dinero entre dos clientes. Observe que hemos decidido utilizar un función lambda para expresar la transacción. El manejo adecuado de errores puede ser un reto en este escenario y envolver tu transacción con una función anónima permite al SDK Java de Couchbase hacer ese trabajo por ti (es decir, reintentar si algo falla).
Cuando lanzamos por primera vez el soporte para transacciones, intentábamos evitar la verborrea. Así era la sintaxis de transacciones de un competidor:
![]()
Últimamente, parece que el manejo de transacciones dentro de funciones lambda se está convirtiendo en la norma para las bases de datos NoSQL.
Para aquellos que esperaban que fuera similar a la sintaxis relacional para las transacciones (por ejemplo, comandos SQL BEGIN/COMMIT/ROLLBACK), sigue leyendo: ¡también puedes ejecutar transacciones a través de N1QL! Ahora, vamos a tratar de entender lo que está sucediendo bajo el capó.
Revisión de la arquitectura de Couchbase
Para aquellos que no estén familiarizados con la arquitectura de Couchbase, necesito explicar rápidamente 4 conceptos importantes antes de seguir adelante:
- Couchbase es altamente escalable, puedes pasar fácilmente de 1 a 100 nodos en un solo cluster con el mínimo esfuerzo
- Los documentos JSON tienen un espacio "Meta" llamado xAttr donde puede almacenar metadatos sobre su documento.
- Dentro de cada Bucket (similar a un esquema en RDBMS), Couchbase distribuye automáticamente los datos en 1024 shards llamados vBuckets. La fragmentación es totalmente transparente para el desarrollador, y nosotros también nos encargamos de la estrategia de fragmentación. Nuestro algoritmo de fragmentación (CRC32) garantiza esencialmente que los documentos se distribuyan uniformemente entre estos vBuckets y que no sea necesario volver a fragmentarlos. Los vBuckets se distribuyen uniformemente entre los nodos de su clúster (por ejemplo, si usted tiene un clúster de 4 nodos, cada nodo contiene 256 vBuckets).
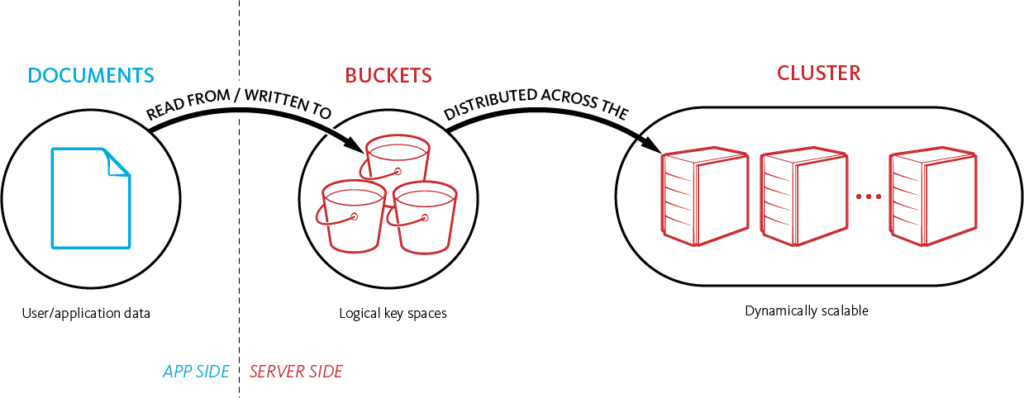
- El SDK del cliente almacena una copia del mapa del cluster, que es un hashmap de los vBuckets y el nodo responsable de ellos. Mediante el hash de la clave del documento, el SDK puede encontrar en qué vBucket debería encontrarse el documento. Y gracias al mapa de clúster puede hablar directamente con el nodo responsable del documento durante las operaciones de guardar/borrar/actualizar.
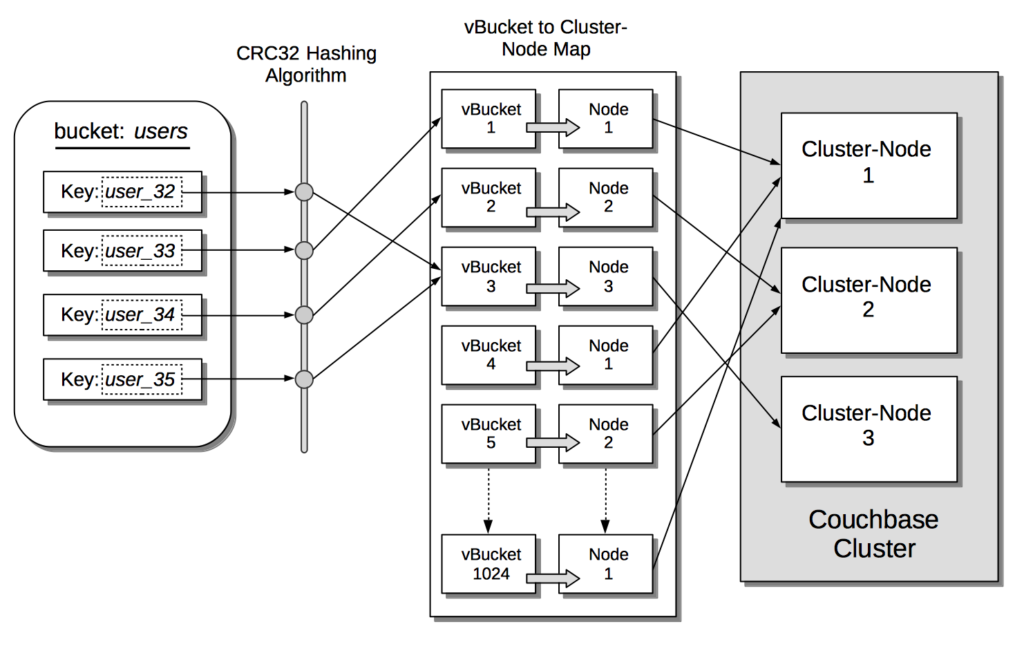
Las opciones de diseño anteriores permiten a Couchbase tener una arquitectura sin maestro (también denominada maestro/maestro) en lugar de la tradicional maestro/esclavo utilizada en otras bases de datos NoSQL. Hay una serie de ventajas de este tipo de arquitectura, pero las relevantes para nosotros ahora son las siguientes:
- El SDK ahorra "un salto de red" durante las operaciones de inserción/actualización/eliminación, ya que sabe dónde se encuentra un documento determinado (en la arquitectura maestro/esclavo hay que preguntar al maestro dónde está el documento).
- La base de datos en sí no tiene un coordinador central, por lo que no existe un único punto de fallo. En la práctica, el cliente actúa indirectamente como un coordinador ligero, ya que sabe exactamente con qué nodo del clúster debe hablar.
Transacciones distribuidas sin coordinador central
En la arquitectura de Couchbase, cada cliente es responsable de la coordinación de sus propias transacciones. Naturalmente, todo se hace en el SDK. En pocas palabras, si tienes 100 instancias de tu aplicación ejecutando transacciones, entonces tienes potencialmente ~100 coordinadores. Estos coordinadores no añaden prácticamente ninguna sobrecarga a tu aplicación, y pronto entenderás por qué.
Si reutilizamos el ejemplo de transferencia de dinero mostrado en nuestro ejemplo de código y suponemos que los 2 documentos implicados en esta transacción viven en dos nodos diferentes, desde una vista de 1.000 pies la transacción sigue estos pasos:
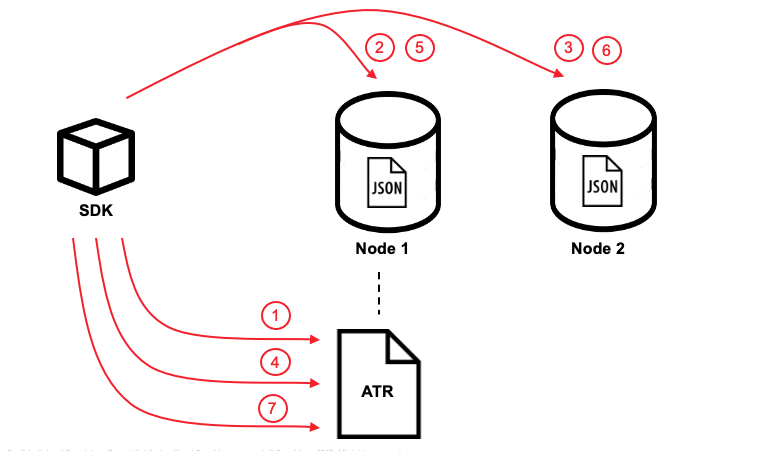
- Cada vBucket tiene un único documento responsable del registro de transacciones denominado Registro de transacciones activas (ATR). El ATR puede identificarse fácilmente por el _txn:atr- prefijo id. Antes de la primera mutación del documento ( ctx.sustituir(usuarioA, userAContent) en este caso), se añade una nueva entrada en la carpeta ATR en el mismo vBucket con el id de la transacción y el estado "Pendiente". Sólo una ATR por transacción.
- El Id de la transacción y el contenido de la primera mutación, ctx.sustituir(usuarioA, userAContent)se escenifica en el xAttrs del primer documento ("usuarioA").
- El Id de la transacción y el contenido de la segunda mutación, ctx.sustituir(usuarioB, userBContent)se escenifica en el xAttrs del segundo documento "usuarioB".
- La transacción se marca como "Comprometida" en el archivo ATR. También aprovechamos esta llamada para actualizar la lista de identificadores de documentos implicados en la transacción.
- El documento "usuarioA" no se ha preparado (se ha eliminado de xAttrs y sustituye el cuerpo del documento)
- El documento "userB" no está preparado (eliminado de xAttrs y sustituye el cuerpo del documento)
- La transacción se marca como "Completada" y se elimina de la carpeta ATR
Tenga en cuenta que esta aplicación no está limitada por ámbitos, colecciones, o shards (vBuckets). De hecho, puede incluso ejecutar transacciones a través de múltiples buckets. Siempre que disponga de permisos suficientes, cualquier documento dentro de su clúster puede formar parte de una transacción.
Llegados a este punto, supongo que tendrá muchas preguntas sobre todas las posibles situaciones de fallo. Vamos a tratar de cubrir aquí los temas más importantes. No dudes en dejar comentarios e intentaré actualizar el artículo en consecuencia.
Manipulación del aislamiento - Vista atómica monótona
Jepsen tiene un gráfico brillante que explica los modelos de coherencia más importantes para las bases de datos:
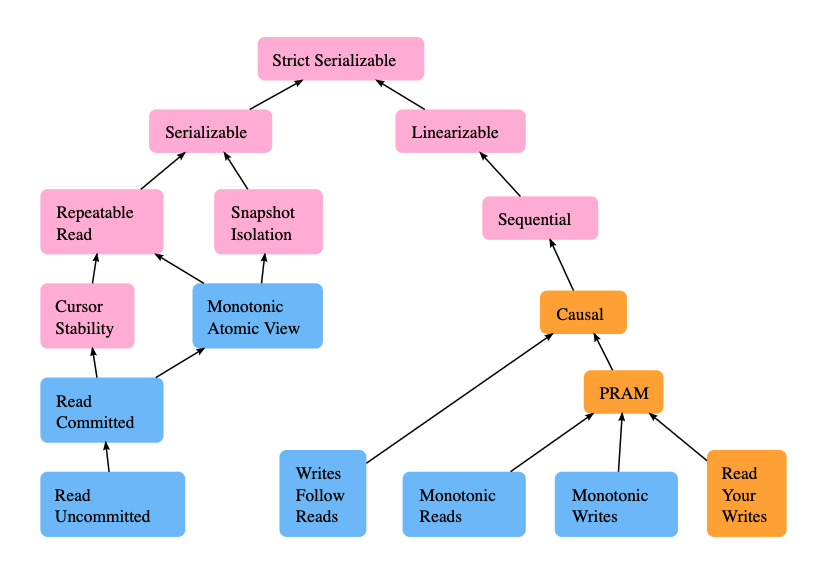
Couchbase es compatible con Leer Comprometidos/Vista atómica monotónica". Pero, ¿hasta qué punto es bueno? Bueno.., Leer Comprometidos es la opción por defecto en Postgres, MySQL, MariaDB y muchas otras bases de datos; si nunca has cambiado esa opción, eso es lo que estás usando ahora mismo.
Leer Comprometidos garantiza que tu aplicación no pueda leer datos no comprometidos, que es lo que probablemente esperas de tu base de datos, pero la parte interesante aquí es cómo ocurre realmente el proceso de commit. En las bases de datos relacionales, muy a menudo, hay una coordinación entre las nuevas versiones de las filas cambiadas en una transacción para tomar el relevo de las anteriores todas al mismo tiempo. Esto se conoce comúnmente como write-point commit. Para que eso ocurra, Control de concurrencia multiversión (MVCC) es necesario. Esto es problemático debido a todo el bagaje que conlleva, por no mencionar lo caro que resulta (en términos de rendimiento) implementarlo en una base de datos distribuida ACID donde las lecturas/escrituras rápidas son clave.
Otra desventaja de los commits de punto de escritura es que puedes gastar un tiempo valioso sincronizando tu commit pero... ningún otro hilo lo lee justo después, desperdiciando todo el esfuerzo gastado con la sincronización. Esto ocurre cuando Vista atómica monotónica (MAV) entra en juego. Se describió por primera vez en el Transacciones de alta disponibilidad: Virtudes y limitaciones papel y tuvo una gran influencia en nuestro diseño.
Con MAV podemos hacer un commit atómico en el punto de lectura, lo que mejora significativamente el rendimiento. Veamos cómo funciona en la práctica:
Lecturas repetibles y vistas atómicas monótonas
En nuestro ejemplo de transacción, hay una fracción de tiempo tras Paso 4 donde hemos establecido la transacción en el ATR como "Comprometida" pero aún no hemos desagrupado los datos de los documentos involucrados en la transacción. Entonces, ¿qué ocurre si otro cliente intenta leer los datos durante este intervalo?
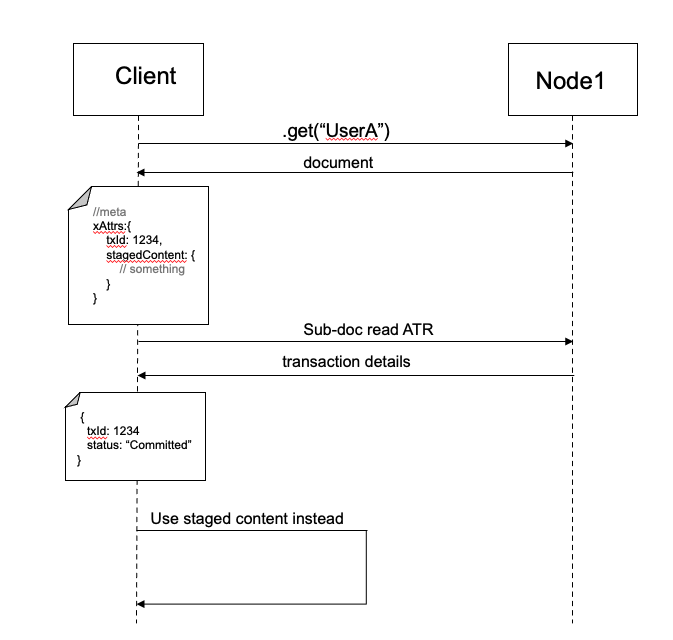
Internamente, si por casualidad el SDK encuentra un documento con contenido preparado, también leerá el ATR para obtener el estado de la transacción. Si el estado es "Comprometido", devolverá la versión preparada en su lugar. No hay necesidad de sincronizar las escrituras. No hay necesidad de sincronizar escrituras si puedes simplemente resolverlo CUANDO ocurre en tiempo de lectura.
Durabilidad en una base de datos distribuida
Una de las tareas más importantes de una base de datos es garantizar que lo que se escribe se queda escrito. Incluso en caso de fallo de un nodo, no se debería perder ningún dato. Esto se logra en Couchbase a través de dos características: Bucket Replicas y Durability en el SDK.
Durante la creación de su cubo, puede configurar cuántas réplicas (copias de seguridad) de cada documento desea (dos es la opción más común). Esta opción permite perder N número de nodos sin que ello implique una posible pérdida de datos.
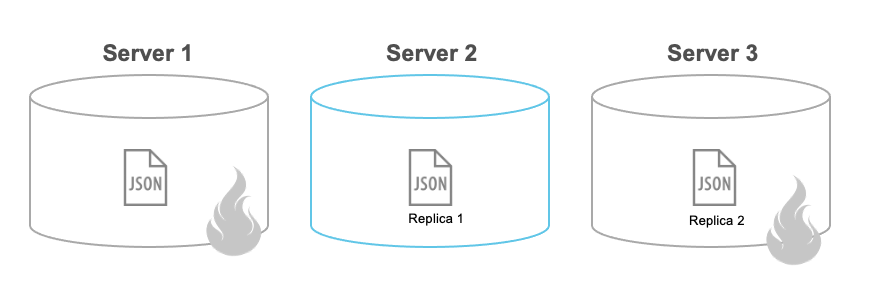
Couchbase está configurado por defecto para tomar siempre la aproximación más rápida, así que tan pronto como tus datos lleguen al servidor, un acuse de recibo será enviado de vuelta al cliente diciendo que tu escritura fue exitosa y toda la replicación de datos será manejada bajo el capó. Sin embargo, si tu servidor falla antes de que tenga la oportunidad de replicar los datos (estamos hablando de microsegundos a unos pocos milisegundos, ya que la replicación se realiza memoria a memoria), es posible que pierdas tu cambio. Esto puede estar bien para algunos datos de poco valor, pero... ¡eh! Esto viola totalmente la "durabilidad" en ACID. Por eso le permitimos especificar su requisitos de durabilidad:

En MAYORÍA (opción por defecto en la biblioteca de transacciones) en el código anterior significa que la mutación debe replicarse a (es decir, mantenerse en la memoria asignada al bucket en) una mayoría de los nodos del Servicio de Datos. Las otras opciones son: majorityAndPersistActive, y persistToMajority. Consulte a la documentación oficial sobre requisitos de durabilidad para entender mejor cómo funciona. Esta función también puede utilizarse fuera de una transacción en caso de que necesite garantizar de forma pesimista que un documento se ha guardado.
¿Qué ocurre si algo falla durante una transacción?
Puede configurar el tiempo que debe durar la transacción antes de ser revertida. El valor por defecto es de 15 segundos. Dentro de este plazo, si hay problemas de concurrencia o de nodo, utilizaremos una combinación de espera y reintento hasta que la transacción alcance este tiempo.
Si el cliente que gestiona la transacción se desconecta repentinamente, es posible que deje algún contenido escenificado en los metadatos del documento. Sin embargo, otros clientes que intenten modificar el mismo documento pueden reconocer que el contenido escenificado puede sobrescribirse, ya que forma parte de una transacción que ya ha caducado.
Además, la biblioteca de transacciones realizará periódicamente limpiezas para eliminar las transacciones no activas de las ATR para mantenerla lo más pequeña posible.
Transacciones SQL distribuidas con N1QL
N1QL es un lenguaje de consulta que implementa la especificación SQL++, es compatible con SQL92 pero está diseñado para documentos JSON estructurados y flexibles. Más información en este tutorial interactivo de N1QL.
La solución de transacciones distribuidas que hemos discutido hasta ahora es genial para las transacciones a nivel de aplicación. Pero, a veces necesitamos ejecutar cambios de datos ad hoc. O, debido al número de documentos involucrados en la operación, manipularlos en la memoria de la aplicación se convierte en una operación cara (por ejemplo, añadir 10 créditos a las cuentas de todos los usuarios). En Couchbase Server 7.0, puedes ejecutar transacciones a través de N1QL con prácticamente la misma sintaxis SQL que la mayoría de bases de datos relacionales:
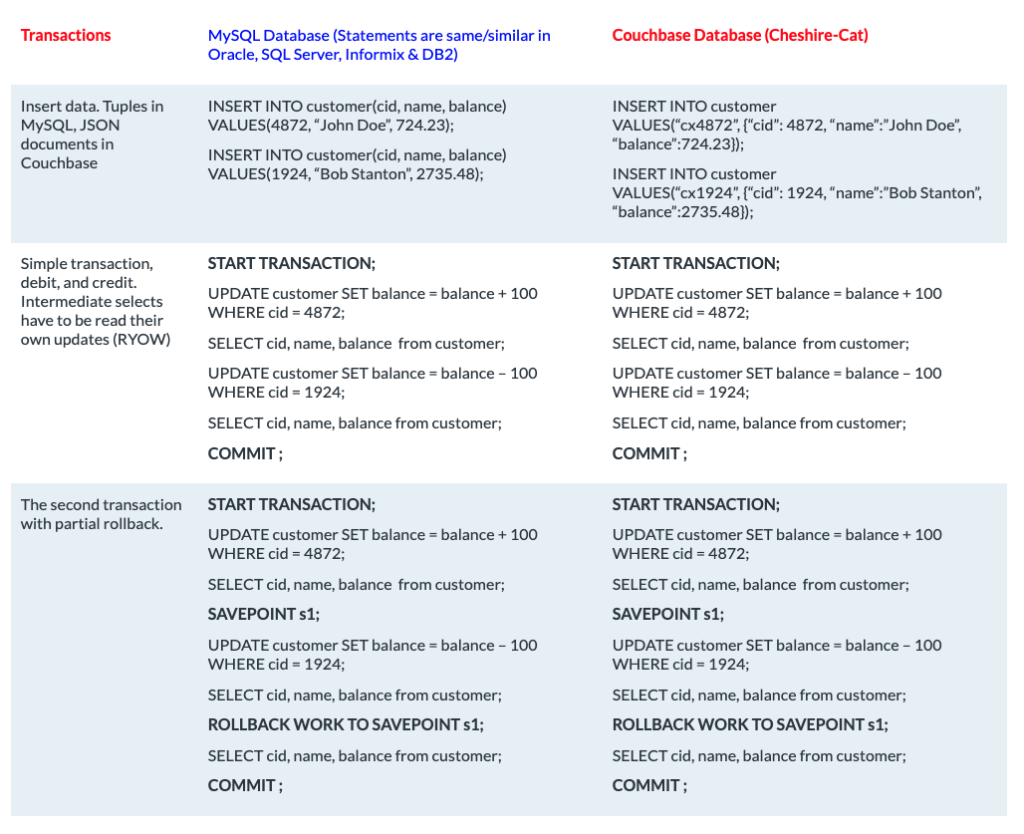
Las transacciones N1QL ya se han introducido correctamente en Transacciones Couchbase con N1QL y "Casos de uso y mejores prácticas para transacciones distribuidas a través de N1QL"por lo que no profundizaré en este tema. Desde una vista de mil pies, la transacción es gestionada por el servicio de consulta. Como Couchbase es modular, puedes aumentar el rendimiento de las transacciones ampliando o reduciendo los nodos que ejecutan el servicio de consultas.
Puede utilizar las transacciones N1QL y Lambda a la vez, pero es preferible utilizar sólo la biblioteca de transacciones siempre que sea posible.
Conclusión: El mejor NoSQL para transacciones
Couchbase ya tiene soporte para operaciones atómicas de documento único y Bloqueo optimista y pesimista desde hace mucho tiempo. El año pasado, introdujimos soporte transaccional rápido independientemente de buckets, colecciones, ámbitos o shards. Con Couchbase 7.0 puedes incluso usar la misma sintaxis transaccional relacional tradicional. La combinación de todas estas características hace que Couchbase, el mejor NoSQL para transacciones a escala.
Bajo coste - Pague por lo que use
La sobrecarga transaccional total es simplemente el número de mutaciones de documentos + 3 (ATR marcados como Pendiente, Comprometido y Completado). Por ejemplo, ejecutar el ejemplo de transferencia de dinero en un contexto transaccional le costará hasta 5 llamadas adicionales a la base de datos.
La biblioteca de transacciones es una capa sobre el SDK, hemos añadido soporte para transacciones con cero impacto en el rendimiento (algo que otros jugadores no pueden reclamar fácilmente). Esto solo se pudo conseguir gracias a nuestra sólida arquitectura.
No hay gestor central de transacciones ni coordinador central
Dada la arquitectura masterless de Couchbase y el hecho de que los clientes se encargan de gestionar sus propias transacciones, nuestra implementación no tiene coordinación central ni punto único de fallo. Incluso durante un fallo de nodo, las transacciones que no están tocando documentos en el servidor defectuoso pueden completarse con éxito. De hecho, con un tiempo máximo de transacción adecuado, incluso si se tocan documentos en un nodo que está fallando, Node Failover de Couchbase puede ser lo suficientemente rápido como para aislar el servidor defectuoso y promover un nuevo nodo antes de que expire su transacción.
Sin reloj global interno y sin MVCC
Algunas implementaciones de transacciones requieren el concepto de reloj global, que puede ser caro de mantener sin hardware dedicado en un entorno distribuido. En algunos casos, puede incluso hacer caer la base de datos si la desviación del reloj es superior a ~250 milisegundos.
Con el control de concurrencia multiversión (MVCC) y los relojes globales, técnicamente se pueden alcanzar mayores niveles de coherencia. Por otro lado, lo más probable es que afecte al rendimiento general de la base de datos. Couchbase soporta el modelo de consistencia Read Committed, que es el mismo que las bases de datos relacionales soportan por defecto.
Flexibilidad
Puede utilizar la función opciones de durabilidad dentro y fuera de un contexto transaccional, utilice bloqueo optimista y pesimista para evitar posibles problemas de concurrencia, y utilizar transacciones en el SDK y/o a través de N1QL. Hay mucha flexibilidad para construir cualquier tipo de aplicación sobre Couchbase y ajustar el rendimiento a las necesidades de tu negocio.
¿Y ahora qué?
Aquí tienes algunos enlaces para saber más sobre lo que acabamos de hablar y para empezar a trabajar con Couchbase:
| Más información sobre las transacciones | https://www.couchbase.com/transactions |
| Transacciones del SDK de Java | https://docs.couchbase.com/java-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html |
| Transacciones del SDK de .NET | https://docs.couchbase.com/dotnet-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html |
| Transacciones del SDK de C | https://docs.couchbase.com/cxx-txns/current/distributed-acid-transactions-from-the-sdk.html |
| Transacciones N1QL | https://www.couchbase.com/blog/couchbase-transactions-with-n1ql/ |
| Descargar Couchbase | https://www.couchbase.com/downloads |
| Novedades de Couchbase 7.0 | https://docs.couchbase.com/server/7.0/introduction/whats-new.html |
¡Buen post!