Creación de la índice de búsqueda derecha y la puesta a punto de sus diversas configuraciones es muy esencial para el buen funcionamiento de cualquier Búsqueda de texto completo sistemas de producción. Estos aspectos operativos desempeñan un papel clave en la mejora del rendimiento de indexación y consulta de los sistemas de búsqueda. Animamos a todos los usuarios del servicio de búsqueda a que se familiaricen con los siguientes conceptos de gestión de índices y los utilicen con criterio en su clúster. Así que puede desplazarse más allá para explorar algunos consejos operativos eficaces en el servicio de búsqueda como cuota de memoria, particiones de índice, réplicas, alias y reequilibrio de recuperación tras fallos.
1. Provisión de una cuota de memoria suficiente
La cuota de memoria por defecto para el servicio de Búsqueda es de 512MB y esto no será suficiente para soportar cualquier sistema de búsqueda a escala de producción. Así que se recomienda revisar la cuota de RAM de búsqueda a valores más significativos como parte del dimensionamiento del clúster.
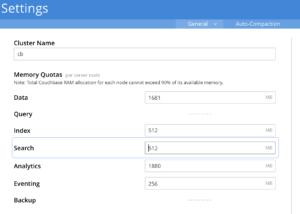
El servicio de búsqueda no impone ningún porcentaje mínimo de memoria residente para su índice. No obstante, se aconseja a los usuarios que reserven una cuota de memoria de búsqueda suficiente para que el índice tenga un índice residente saludable. De este modo, el sistema dispondrá de memoria suficiente para realizar la indexación, la consulta u otras operaciones del ciclo de vida, como reequilibrios, etc.
A continuación figuran algunos síntomas por cuota de memoria insuficiente en un clúster de búsqueda,
- Las consultas se rechazan debido al código de error HTTP 429 del servidor.
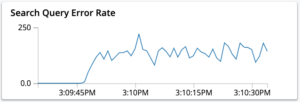
Esta limitación de velocidad se aplica para respetar la cuota de memoria configurada para el servicio de búsqueda. Rechaza una consulta entrante cuando no hay suficiente memoria disponible para servir la consulta sin exceder la cuota de memoria establecida. Es posible que notes un aumento de la tasa de errores de consulta en la página de monitorización del índice.
- Un número creciente de consultas lentas en el sistema.
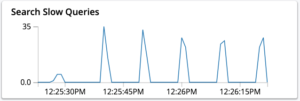
También podrían producirse picos de consultas lentas debido a la escasez de memoria operativa en el sistema.
- Aumento de la latencia media de las consultas.
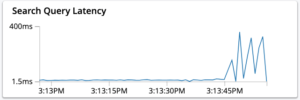
También podría producirse un aumento gradual de la latencia de las consultas debido a la falta de memoria operativa en el sistema.
Todas las estadísticas de consulta anteriores se pueden monitorizar a través de la página de estadísticas de índice incorporada en el servidor Couchbase.
2. Reserve suficiente memoria para la caché del sistema de archivos.
Otro aspecto fundamental a la hora de configurar la cuota de memoria de búsqueda es dejar suficiente margen de RAM para que el sistema operativo pueda gestionar la caché del sistema de archivos. Bajo el capó, la biblioteca interna de indexación de texto de Search (bleve) utiliza mapeo de memoria para los archivos de índice. Por lo tanto, disponer de suficiente memoria RAM para el sistema operativo ayuda a mantener las regiones calientes de los archivos de índice en la memoria caché del sistema de archivos. Esto ayuda a mejorar el rendimiento de la búsqueda.
La pauta habitual es fijar la cuota de memoria de Búsqueda en 60-70% de la RAM disponible en un nodo de Búsqueda.
Configurar suficiente memoria RAM en el sistema y asignar suficiente memoria de cuota de búsqueda es esencial para un rendimiento óptimo de la búsqueda.
Síntomas - El hecho de que el sistema operativo elimine el servicio de búsqueda de forma recurrente durante el proceso de indexación o consulta podría indicar también una falta de memoria RAM en el sistema.
3. Evitar la multitenencia de servicios con nodos de búsqueda
Alojar múltiples servicios en un único nodo conlleva el riesgo de una posible contención de recursos entre los servicios. Ni siquiera establecer una cuota de recursos para cada servicio ayudará a evitarlo por completo.
Por ejemplo, el servicio de búsqueda depende en gran medida de la memoria RAM disponible más allá de la cuota de memoria configurada para un mejor rendimiento de asignación de memoria. Pero otros servicios que se ejecutan en el mismo nodo podrían consumir esta memoria RAM disponible y afectar al rendimiento de la búsqueda de forma inadvertida. Lo mismo ocurre con los núcleos de CPU.
La depuración y resolución de problemas de rendimiento o el dimensionamiento inicial del sistema de búsqueda resultan mucho más sencillos con los nodos alojados en un único servicio.
De ahí que se anime a los usuarios a empezar al menos con nodos de búsqueda de un solo servicio durante el periodo inicial de despliegue.
4. Consideraciones sobre la topología del índice
-
Número de particiones del índice
En función de la cantidad de datos indexados, ajuste el número de particiones de índice y su distribución entre nodos/núcleos de CPU para optimizar el rendimiento del servicio.
Demasiadas particiones aumentan el coste de la dispersión, y muy pocas limitarían la paralelización de la búsqueda.
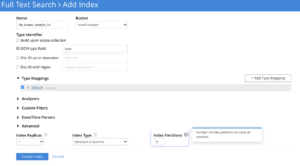
No existe un recuento genérico predefinido de particiones de índices que se ajuste a todos los casos de uso. Los usuarios tienen que explorar esto empíricamente para cada uno de sus casos de uso SLA.
Si el usuario sólo dispone de unos pocos millones de datos, se recomienda sustituir el recuento de particiones predeterminado de 6 por valores más pequeños, como 1 o 2.
Algunos puntos importantes a tener en cuenta con el número de particiones del índice son,
- Ayuda a asignar mejor las cargas de trabajo de indexación y consulta entre los nodos disponibles en función del tamaño del clúster.
- Las particiones relativamente pequeñas en múltiples nodos ayudan a realizar operaciones de reequilibrio más rápidas.
- Las particiones ayudan a aprovechar mejor el núcleo de la CPU.
- Dependiendo de la cantidad de datos que se indexen, es aconsejable ajustar el número de particiones para que no sean muy grandes.
-
Número de réplicas
La réplica sólo sirve para la alta disponibilidad del servicio de búsqueda hoy. Así, cuando un nodo se cae por cualquier motivo, los usuarios pueden realizar un reequilibrio de conmutación por error del nodo defectuoso. Esto serviría inmediatamente el tráfico en vivo de las particiones de réplica y el servicio se mantiene en vivo para los usuarios finales sin problemas.
Los números de réplica deben ser configurados explícitamente por el usuario durante la creación del índice.
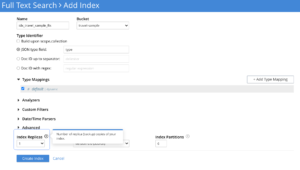
Por defecto, los servicios de búsqueda no habilitan las réplicas de partición durante el creación de índices.
Se recomienda a los usuarios configurar un número de réplicas de 1 o más dependiendo de los requisitos de alta disponibilidad.
-
Conmutación por error y recuperación
Si el usuario necesita sacar temporalmente un nodo del cluster para cualquier operación de mantenimiento de hardware o software, entonces podría intentar fallar sobre el nodo. Durante la conmutación por error de un nodo de búsqueda, se conservan todos los datos de la partición del índice que residen en el nodo.
Una vez finalizadas las operaciones de mantenimiento, puede probar la opción "Recuperar" para volver a añadirlo al clúster. Como aquí se está recuperando el mismo nodo, el servicio de búsqueda podrá reutilizar todos los datos existentes de la partición del índice que residen en el nodo recuperado. Y esto resultaría en una operación de recuperación de nodo realmente más rápida.

Con las particiones de réplica, el servicio de búsqueda debe ser capaz de conmutar por error y recuperar nodos para su mantenimiento sin ningún tiempo de inactividad del servicio.
5. Política de fusión más estricta para casos de uso intensivo de actualizaciones
Un índice de búsqueda suele constar de varios archivos de índice denominados segmentos. Estos segmentos son creados por las mutaciones de documentos (inserción/actualización/eliminación) que se producen en la fuente de datos/cubo. Al servir una petición de búsqueda, el FTS tiene que buscar en todos estos segmentos secuencialmente. Por lo tanto, cuanto mayor sea el número de segmentos, más lentas serán las operaciones de búsqueda en el índice.
En la capa de almacenamiento del índice, un proceso de fusión en segundo plano sigue fusionando estos archivos de segmentos de disco más pequeños en un conjunto estable de segmentos más grandes. Este comportamiento de fusión está controlado por la política de fusión que puede especificarse en la definición del índice. Una fusión demasiado agresiva podría robar más recursos (disco y CPU) de otros hilos competidores del ciclo de vida u operaciones de consulta en un índice. Por lo tanto, hemos mantenido la política de fusión por defecto para que sea lo suficientemente genérica como para trabajar con varios casos de uso.
En un momento dado, la política de fusión por defecto intentaría dar como resultado un montón de segmentos de índice que siguieran un patrón de escalera logarítmica de tamaños de segmento crecientes como el que se muestra a continuación.

Pero puede haber situaciones en las que valga la pena anular la política de fusión y vamos a explorarlas.
-
Recuperación más rápida del espacio en disco con una carga de trabajo rica en actualizaciones/borrados.
FTS tiene "sólo para anexos"que marcaría las entradas de documentos de los segmentos existentes como eliminadas/obsoletas mediante el cambio de un bit en cualquier operación de actualización/eliminación. La liberación real de espacio en disco sólo se producirá cuando estos segmentos se fusionen/compacten durante el ciclo de fusión concurrente. La política de fusión por defecto de FTS favorecerá la fusión de segmentos más pequeños sobre segmentos gigantes más grandes para optimizar el IO de disco y la CPU. Esto podría dejar un largo período de espera para recuperar el espacio en disco de los documentos actualizados/compactados que pertenecían a esos segmentos más grandes, ya que los segmentos más grandes se seleccionan para las operaciones de fusión con poca frecuencia.
La cantidad de espacio de disco recuperable en cualquier instante se expone a los usuarios a través de una estadística denominada num_bytes_utilizados_por_disco_raiz_recuperable.
Si el usuario ve sistemáticamente valores significativos para la estadística anterior, entonces indica la necesidad de una política de compactación más estricta para el índice. Los mandos de configuración de la fusión también permiten favorecer la selección de segmentos con más contenido obsoleto/borrado durante el proceso de compactación/fusión.
-
Mejor rendimiento de búsqueda para cargas de trabajo de lectura intensiva.
Ya hemos aprendido que cada petición de búsqueda se sirve después de consultar cada uno de estos ficheros de segmentos dentro de un índice. Por lo tanto, la sobrecarga de servir una búsqueda sería mayor con un mayor número de archivos de segmentos.
Un menor número de segmentos ayuda a mejorar el rendimiento de la búsqueda. Por ello, se recomienda reducir el número de archivos de segmentos siempre que sea posible. (horas valle)
La política de compactación puede anularse mediante la definición del índice actualizar el punto final restante. Por favor, Contacto para más detalles sobre cómo anular la política de compactación por defecto para un índice.
6. Utilizar alias de índices
En alias de índice apunta a uno o más índices de texto completo, o a alias adicionales: su propósito es, por tanto, algo comparable al de un enlace simbólico en un sistema de archivos. Las consultas a un alias de índice se realizan en todos los destinos finales y se proporcionan resultados combinados.
El uso de alias de índice permite indirección en la nomenclatura, mediante el cual las aplicaciones hacen referencia a un alias-nombre que nunca cambia, dejando libertad a los administradores para cambiar periódicamente la identidad del índice real al que apunta el alias. Esto puede resultar especialmente útil cuando es necesario actualizar un índice: para evitar tiempos de inactividad, mientras el índice actual sigue en servicio, se puede crear, modificar y probar un clon del índice actual. Entonces, cuando el clon esté listo, se puede volver a apuntar al alias existente, de modo que el clon se convierta en el índice actual; y se puede eliminar el índice (ahora) anterior.
Los detalles de la creación de alias de índice se encuentran en aquí
7. Consecuencias de la actualización de la definición del índice
Los usuarios tienen la opción de actualizar la definición del índice siempre que necesiten cambiar las propiedades del índice relacionadas con las asignaciones de tipos, las particiones, las réplicas, el almacenamiento o la persistencia.
Una cosa que hay que tener en cuenta al actualizar la definición de un índice es que pocas de las actualizaciones darían lugar a la reconstrucción del índice desde cero.
Actualizaciones de la reconstrucción del índice
Cualquier tipo de actualización relacionada con el mapeo o el recuento de particiones siempre reconstruye el índice. Por lo tanto, estos cambios afectarían al tráfico activo. Pero normalmente, este tipo de actualizaciones de definición de índices se producen en la fase inicial de despliegue del clúster.
Actualizaciones no relacionadas con la reconstrucción
El resto de las actualizaciones de las propiedades de índice serían instantáneas. Las actualizaciones sólo darían lugar a un reinicio o actualización de los componentes subyacentes. El índice debería estar en funcionamiento en un periodo de inactividad de sólo unos segundos. Por lo tanto, los usuarios pueden probarlos durante las horas de menor tráfico.
Las actualizaciones de la definición del índice, como el cambio del recuento de réplicas o las propiedades del motor de almacenamiento, pertenecen a esta categoría.
Para cualquier consulta relacionada con el sistema de búsqueda, los usuarios pueden ponerse en contacto con nosotros aquí.
Para cualquier consulta sobre el FTS, los usuarios pueden consultar lo siguiente blog,
Búsqueda de texto completo: 5 consejos para mejorar el rendimiento de las consultas
Gran artículo, Sreekanth.