
Scalable AI search
Hyperscale vector index for billion-scale data and is ideal for RAG, agents, and recommendations applications.
Couchbase 8.0 unifies on-premises and cloud data management with massive vector scalability, built-in AI query intelligence, and new enterprise-grade operational controls. It’s the only data platform supporting transactional, analytical, and AI workloads together optimized for both developers and DevOps.
Hyperscale vector index for billion-scale data and is ideal for RAG, agents, and recommendations applications.

Composite vector index for search applications where prefiltering massive data is needed.

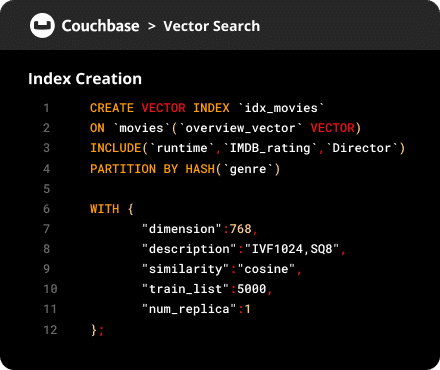
Search vector index combines multiple methods – lexical (keyword) with semantic (vector) for context-rich retrieval.

Operate across on premises, DBaaS, Kubernetes, and embedded in mobile apps.
Couchbase 8.0 introduces major advances for developing and managing AI and other critical applications at scale. From billion-scale vector indexing to new failover logic and encryption at rest, every service is faster, smarter, and easier to manage.

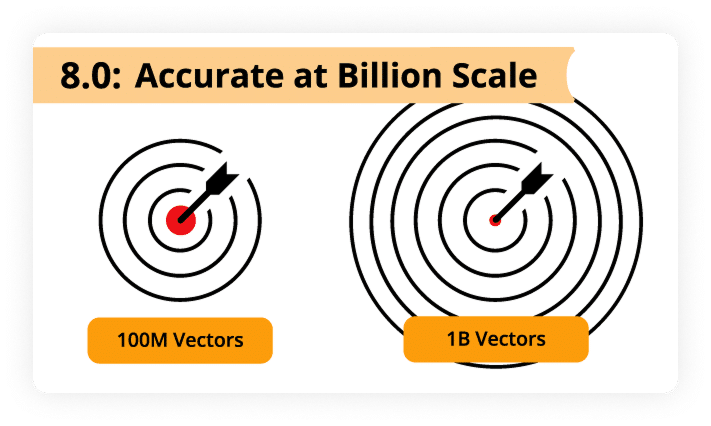
Billion-scale vectors for exceptional accuracy, speeds, and latency. Other types to match your use case.

8.0 delivers out-of-the-box encryption at rest.

8.0 makes data querying easier with new natural language capabilities for SQL++.

Improved replication conflict resolution & mobile sync integration.

Improved failover capabilities, query insights, and SDK metric visibility.
Couchbase 8.0 lets developers move from concept to production AI faster than ever. They can build fast AI-powered applications with huge datasets at low TCO, get started quickly with natural language queries, and ensure quick queries with new troubleshooting tools.
Use natural language to query with SQL++ extensions.
Search with developer-defined synonyms to have a smarter search.
Built-in workload repository and performance insights.
Compatible with popular AI frameworks.
Improving operational excellence with smarter cluster management, advanced security capabilities, dynamic rebalancing, and faster failover for continuous service availability.
Out-of-the-box native encryption at rest makes data safer and life simpler.
Dynamically adjust non-KV services without adding or removing nodes, eliminating rebalance delays.
Aggregate information from your SDK client telemetry for improved end-to-end monitoring and faster troubleshooting.
Auto-failover of non-responsive data nodes to improve application uptime. Serve requests while caches warm up.


“Couchbase’s new 8.0 vector search capabilities transform how we deliver context-aware video discovery for enterprises.”

“What Couchbase has done with SQL++ has been one of the most innovative things done in the database space in decades.”

“Couchbase is a highly scalable, distributed data store that plays a critical role in LinkedIn’s systems.”
It supports billions of vectors with millisecond retrieval speeds using a DiskANN-based design.
Encryption at rest, KMIP key management, and event monitoring ensure data integrity and compliance.
Yes. Use the search vector index for hybrid vector + lexical queries.
Automatic failover, rebalancing, and faster startup ensure continuous operations.
By reviewing the Couchbase 8.0 announcement blog.
Hyperscale helps RAG-style use cases when you cannot anticipate what a prompt is going to ask an LLM, while Composite vector indexes use prefiltering parameters to narrow the vectors to include in a prompt. Both offer millisecond response so RAG workflows do not slow down.
Achieve high performance and accuracy at billion-scale vector for AI agents, RAG workflows, contextual memory and recommendation systems – on premises or in Capella.

Check out our developer portal to explore NoSQL, browse resources, and get started with tutorials.
Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.
Want to learn more about Couchbase offerings? Let us help.