Nos últimos anos, notamos como o aprendizado de máquina foi comprovado como uma tecnologia na qual as empresas deveriam investir maciçamente. Você pode encontrar facilmente dezenas de artigos falando sobre como a empresa X economizou muito dinheiro ao adicionar algum nível de IA em seu processo.
Surpreendentemente, ainda percebo que muitos setores são céticos em relação a ele e outros acham que é "legal", mas ainda não têm nada em mente.
Acredito que o motivo dessa dissonância se deve a dois fatores principais: Muitas empresas não têm ideia de como a IA se encaixa em seus negócios e, para a maioria dos desenvolvedores, ela ainda soa como magia negra.
É por isso que eu gostaria de mostrar hoje como você pode começar a usar o aprendizado de máquina com quase nenhum esforço.
Regressão linear
No nível mais básico do aprendizado de máquina, temos algo chamado Regressão Linear, que é basicamente um algoritmo que tenta "explicar" um número atribuindo peso a um conjunto de recursos:
- O preço de uma casa pode ser explicado por fatores como tamanho, localização, número de quartos e banheiros.
- O preço de um carro pode ser explicado por seu modelo, ano, quilometragem, condição, etc.
- O tempo gasto em uma determinada tarefa pode ser previsto pelo número de subtarefas, nível de dificuldade, experiência do funcionário etc
Há muitos casos de uso em que a regressão linear (ou outros tipos de regressão) pode ser usada, mas vamos nos concentrar no primeiro, relacionado a preços de imóveis.
Imagine que estamos administrando uma empresa imobiliária em uma determinada região do país. Como somos uma empresa antiga, há algum registro de dados sobre quais casas foram vendidas no passado e por quanto.
Nesse caso, cada linha em nossos dados históricos terá a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "id": 7129300520, "date": "20141013T000000", "price": 221900, "bedrooms": 3, "bathrooms": 1, "sqft_living": 1180, "sqft_lot": 5650, "floors": 1, "waterfront": 0, "view": 0, "condition": 3, "grade": 7, "sqft_above": 1180, "sqft_basement": 0, "yr_built": 1955, "yr_renovated": 0, "zipcode": 98178, "lat": 47.5112, "long": -122.257, "sqft_living15": 1340, "sqft_lot15": 5650 } |
O problema - Como definir o preço de um imóvel
Agora, imagine que você acabou de entrar na empresa e precisa vender a seguinte casa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "id": 1000001, "date": "20150422T000000", "bedrooms": 6, "bathrooms": 3, "price": null, "sqft_living": 2400, "sqft_lot": 9373, "floors": 2, "waterfront": 0, "view": 0, "condition": 3, "grade": 7, "sqft_above": 2400, "sqft_basement": 0, "yr_built": 1991, "yr_renovated": 0, "zipcode": 98002, "lat": 47.3262, "long": -122.214, "sqft_living15": 2060, "sqft_lot15": 7316 } |
Por quanto você o venderia?
A pergunta acima seria muito desafiadora se você nunca tivesse vendido uma casa semelhante no passado. Felizmente, você tem a ferramenta certa para o trabalho: Uma Regressão Linear.
A resposta - Previsão de preços de imóveis com regressão linear
Antes de prosseguir, você precisará instalar os seguintes itens:
- Servidor Couchbase 5
- Spark 2.2
- SBT (já que estamos usando Scala)
Carregando o conjunto de dados
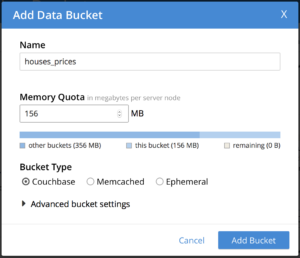
Com seu Couchbase Server em execução, acesse o portal administrativo (geralmente em https://127.0.0.1:8091) e crie um novo bucket chamado preços_de_casas
Agora, vamos clonar o código do nosso tutorial:
|
1 |
git clone https://github.com/couchbaselabs/couchbase-spark-mllib-sample.git |
Na pasta raiz, há um arquivo chamado house_prices_train_data.zipÉ o nosso conjunto de dados, que peguei emprestado de um antigo curso de aprendizado de máquina sobre Coursera. Descompacte-o e execute o seguinte comando:
|
1 |
./cbimport json -c couchbase://127.0.0.1 -u YOUR_USER -p YOUR_PASSWORD -b houses_prices -d <PATH_TO_UNZIPED_FILE>/house_prices_train_data -f list -g key::%id% -t 4 |
DICA: Se você não estiver familiarizado com cbimport por favor Confira este tutorial
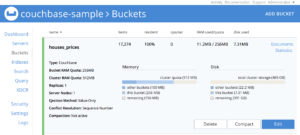
Se o comando foi executado com êxito, você deve notar que seu preços_de_casas foi preenchido:
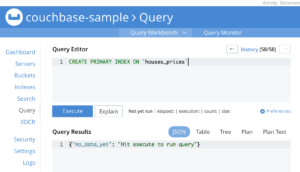
Vamos também adicionar rapidamente um índice primário para ele:
|
1 |
CREATE PRIMARY INDEX ON `houses_prices` |
Hora de programar!
Nosso ambiente está pronto, é hora de codificar!
No LinearRegressionExample começamos criando o contexto do Spark com nossas credenciais de bucket:
|
1 2 3 4 5 6 7 8 9 |
val spark = SparkSession .builder() .appName("SparkSQLExample") .master("local[*]") // use the JVM as the master, great for testing .config("spark.couchbase.nodes", "127.0.0.1") // connect to couchbase on localhost .config("spark.couchbase.bucket.houses_prices", "") // open the houses_prices bucket with empty password .config("com.couchbase.username", "YOUR_USER") .config("com.couchbase.password", "YOUR_PASSWORD") .getOrCreate() |
e, em seguida, carregamos todos os dados do banco de dados:
|
1 |
val houses = spark.read.couchbase() |
Como o Spark usa uma abordagem preguiçosa, os dados não são carregados até que sejam realmente necessários. Você pode ver claramente a beleza do Conector do Couchbase acima, acabamos de converter um documento JSON em um Dataframe do Spark sem nenhum esforço.
Em outros bancos de dados, por exemplo, seria necessário exportar os dados para um arquivo CSV com alguns formatos específicos, copiá-lo para a máquina, carregá-lo e fazer alguns procedimentos extras para convertê-lo em um dataframe (sem mencionar os casos em que o arquivo gerado é muito grande).
Em um mundo real, você precisaria fazer alguma filtragem em vez de apenas obter todos os dados. Novamente, nosso conector está à sua disposição, pois você pode até mesmo executar algumas consultas N1QL com ele:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//loading documents by its type val airlines = spark.read.couchbase(EqualTo("type", "airline")) //loading data using N1QL // This query groups airports by country and counts them. val query = N1qlQuery.simple("" + "select country, count(*) as count " + "from `travel-sample` " + "where type = 'airport' " + "group by country " + "order by count desc") val schema = StructType( StructField("count", IntegerType) :: StructField("country", StringType) :: Nil ) val rdd = spark.sparkContext.couchbaseQuery(query).map( r => Row(r.value.getInt("count"), r.value.getString("country"))) spark.createDataFrame(rdd, schema).show() |
DICA: Há vários exemplos de como usar o conector do Couchbase aqui.
Nosso dataframe ainda se parece exatamente com o que tínhamos em nosso banco de dados:
|
1 |
houses.show(10) |

Há dois tipos diferentes de dados aqui, "números escalares", como banheiros e sqft_living e "variáveis categóricas", como código postal e yr_renovated. Essas variáveis categóricas não são apenas números simples, elas têm um significado muito mais profundo, pois descrevem uma propriedade; no caso do CEP, por exemplo, ele representa a localização da casa.
A regressão linear não gosta desse tipo de variável categórica, portanto, se realmente quisermos usar o CEP em nossa regressão linear, pois parece ser um campo relevante para prever o preço de uma casa, teremos que convertê-lo em um variável fictíciaque é um processo bastante simples:
- Distingue todos os valores da coluna de destino. Ex: SELECT DISTINCT(ZIPCODE) FROM HOUSES_PRICES
- Converta cada linha em uma coluna. Ex: zipcode_98002, zipcode_98188, zipcode_98059
- Atualize essas novas colunas com 1s e 0s de acordo com o valor do conteúdo do CEP:
Ex:
![]()
A tabela acima será transformada em:
![]()
É isso que estamos fazendo na linha abaixo:
|
1 |
val df = transformCategoricalFeatures(houses) |
A conversão de variáveis categóricas é um procedimento muito padrão e o Spark já tem alguns utilitários para fazer esse trabalho para você:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def transformCategoricalFeatures(dataset: Dataset[_]): DataFrame = { val df1 = encodeFeature("zipcode", "zipcodeVec", dataset) val df2 = encodeFeature("yr_renovated", "yr_renovatedVec", df1) val df3 = encodeFeature("condition", "conditionVec", df2) encodeFeature("grade", "gradeVec", df3) } def encodeFeature(featureName: String, outputName: String, dataset: Dataset[_]): DataFrame = { val indexer = new StringIndexer() .setInputCol(featureName) .setOutputCol(featureName + "Index") .fit(dataset) val indexed = indexer.transform(dataset) val encoder = new OneHotEncoder() .setInputCol(featureName + "Index") .setOutputCol(outputName) encoder.transform(indexed) } |
OBSERVAÇÃO: O dataframe final não será exatamente igual ao exemplo mostrado acima, pois já está otimizado para evitar o Matriz esparsa problema.
Agora, podemos selecionar os campos que gostaríamos de usar e agrupá-los em um vetor chamado recursospois essa implementação de regressão linear espera um campo chamado rótulotambém temos que renomear o preço coluna :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//just using almost all columns as features, no special feature engineering here val features = Array("sqft_living", "bedrooms", "gradeVec", "waterfront", "bathrooms", "view", "conditionVec", "sqft_above", "sqft_basement", "sqft_lot", "floors", "yr_built", "zipcodeVec", "yr_renovatedVec") val assembler = new VectorAssembler() .setInputCols(features) .setOutputCol("features") //the Linear Regression implementation expect a feature called "label" val renamedDF = assembler.transform(df.withColumnRenamed("price", "label")) |
Você pode brincar com esses recursos, removendo-os/adicionando-os conforme desejar. Mais tarde, você pode tentar, por exemplo, remover o "sqft_living" para ver como o algoritmo tem um desempenho muito pior.
Por fim, usaremos apenas casas em que o preço não é nulo para treinar nosso algoritmo de aprendizado de máquina, pois nosso objetivo é fazer com que nossa regressão linear "aprenda" a prever o preço por meio de um determinado conjunto de recursos.
|
1 |
val data = renamedDF.select("label", "features").filter("price is not null") |
Aqui é onde a mágica acontece, primeiro dividimos nossos dados em treinamento (80%) e teste (20%), mas, para os fins deste artigo, vamos ignorar os dados de teste e, em seguida, criaremos nossa instância LinearRegression e ajuste nossos dados nele.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//let's split our data into test and training (a common thing during model selection) val splits = data.randomSplit(Array(0.8, 0.2), seed = 1L) val trainingData = splits(0).cache() //let's ignore the test data for now as we are not doing model selection val testData = splits(1) val lr = new LinearRegression() .setMaxIter(1000) .setStandardization(true) .setRegParam(0.1) .setElasticNetParam(0.8) val lrModel = lr.fit(trainingData) |
O lrModel variável já é um modelo treinado capaz de prever os preços dos imóveis!
Antes de começarmos a fazer previsões, vamos verificar algumas métricas do nosso modelo treinado:
|
1 2 3 4 5 6 7 |
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}") val trainingSummary = lrModel.summary println(s"numIterations: ${trainingSummary.totalIterations}") println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]") trainingSummary.residuals.show() println(s"RMSE: ${trainingSummary.rootMeanSquaredError}") println(s"r2: ${trainingSummary.r2}") |
O que você deve se preocupar aqui é chamado RMSE - Root Mean Squared Error (Erro médio quadrático) que, grosso modo, é o desvio médio do que nosso modelo prevê X o preço real vendido.
|
1 2 |
RMSE: 147556.0841305963 r2: 0.8362288980410875 |
Em média, erramos o preço real em $147556.0841305963o que não é nada ruim, considerando que quase não fizemos nada engenharia de recursos ou removido quaisquer valores atípicos (algumas casas podem ter preços inexplicavelmente altos ou baixos e isso pode atrapalhar sua Regressão Linear)
Há apenas uma casa com preço ausente nesse conjunto de dados, exatamente aquela que apontamos no início:
|
1 2 3 4 |
val missingPriceData = renamedDF.select("features") .filter("price is null") missingPriceData.show() |
E agora podemos finalmente prever o preço esperado do imóvel:
|
1 2 3 |
//printing out the predicted values val predictedValues = lrModel.transform(missingPriceData) predictedValues.select("prediction").show() |
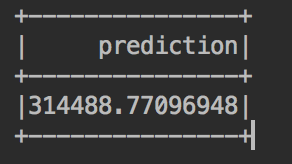
Incrível, não é?
Para fins de produção, você ainda precisaria fazer um seleção de modelos Primeiro, verifique outras métricas de sua regressão e salve o modelo em vez de treiná-lo em tempo real, mas é incrível o quanto pode ser feito com menos de 100 linhas de código!
Se você tiver alguma dúvida, fique à vontade para me perguntar no Twitter em @deniswsrosa ou em nosso fóruns.