Este artigo se baseia na sessão "When Couchbase meets Splunk, the real-time, AI-driven data analytics platform" apresentada no Couchbase Connect Online 2020 por James Powenski e Andrea Vasco.
O Muro da Confusão
Desde que eu era estudante universitário, sempre fui fascinado pela ciência de dados. Naquela época, isso ainda não era algo de que alguém pudesse se gabar, mas ainda me lembro de como me senti na primeira vez em que me deparei com a teoria da estimativa.
Vivemos agora na Era de Ouro dos Dados, uma era em que os conjuntos de dados cresceram exponencialmente, tornando-se publicamente disponíveis; hoje, muitas plataformas excelentes oferecem maneiras simplificadas de aproveitar o aprendizado de máquina e as técnicas de aprendizado profundo para levar o processo de tomada de decisão a um nível sobre-humano.
Dimensionamento multidimensional (MDS) é um dos meus recursos preferidos do Couchbase, com um ponto fraco para o isolamento de cargas de trabalho de indexação, consulta e análise: Passei vários anos minerando dados em bancos de dados relacionais em busca de padrões e correlações em grandes conjuntos de dados, e muitas vezes me vi - nem é preciso dizer - executando consultas complexas que geravam atritos com os DBAs sobre bloqueios, degradação do desempenho e assim por diante.
Eu me concentrei muito no chamado Muro de ConfusãoAcho que sim. Esse problema era (e é) tão caro para mim que, em 2013, nós escreveu um artigo sobre a desmistificação da caracterização da carga de trabalho da Oracle.
Preparando o cenário: trazendo a Inteligência Contínua para o ACME
Em 2019, a Gartner identificou Inteligência contínua como um Tendência das 10 principais análisesestimando que até 2022 "mais de 50% de todas as iniciativas de negócios exigirão inteligência contínua, aproveitando os dados de fluxo contínuo para aprimorar a tomada de decisões em tempo real".
Neste artigo (e na série), vamos orientá-lo sobre uma maneira prática de começar a usar a Inteligência Contínua com o Couchbase, com o objetivo de revolucionar sua empresa rumo à transformação digital sem afetar significativamente suas operações diárias; vamos fingir ser um Engenheiro de confiabilidade do site (SRE) na ACME Inc., com a missão de implementar a Inteligência Contínua para a loja on-line da ACME.
Vamos supor que você tenha uma familiaridade básica com Análise do Couchbase. Conforme mostrado na figura abaixo, o Couchbase Analytics permite criar, em tempo real, cópias de sombra dos dados armazenados no KV Engine em uma arquitetura de MPP (Massive Parallel Processing, processamento paralelo maciço), que pode ser usada para consultar os dados de sombra usando uma linguagem semelhante a SQL (SQL++) e expor conjuntos de dados grandes e pré-agregados a soluções de terceiros para processamento adicional.
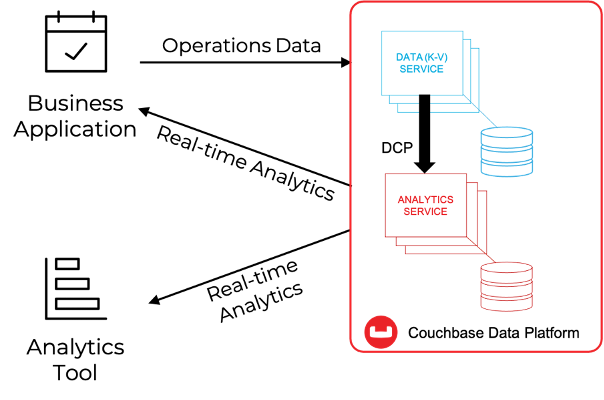
O Couchbase fornece a tecnologia básica necessária para dar o pontapé inicial na jornada da ACME rumo à Inteligência Contínua: a flexibilidade do NoSQL incorporada a uma plataforma capaz de realizar operações em sub-milissegundos, isolamento da carga de trabalho, escalabilidade linear multidimensional e integração com soluções de terceiros, tudo isso combinado em uma plataforma elegante que abrange desde a multinuvem até a borda.
Como SRE da ACME, podemos entender facilmente como o Couchbase pode fornecer um plano de dados corporativos de classe mundial para a loja on-line de última geração. Mas e a lógica de negócios?
Bem, isso depende do tipo de lógica de negócios que é necessária em nossa empresa: O Couchbase fornece, pronto para uso, um conjunto completo de recursos necessários para recuperar documentos individuais de forma programática ou executar consultas ad-hoc/a priori (consultar ou analisar). Mas, para a loja on-line de última geração da ACME, talvez queiramos elevar nosso jogo e buscar sinergias com as muitas soluções empresariais do mercado atual que oferecem todo o arsenal analítico: exploração de dados, observabilidade, navegação de dados, painéis de controle em tempo real, aprendizado de máquina e IA.
Não é preciso dizer que o Couchbase foi projetado para se integrar a eles e, no exemplo de hoje, usaremos APIs REST do Couchbase Analytics para integrar com Splunk.
Por que a Splunk? Aqui estão alguns motivos convincentes, sem entrar em muitos detalhes:
- Nível de adoção e maturidade: O Splunk é um líder de mercado na área de ITOMPortanto, é provável que sua organização já tenha habilidades e ambientes para que você faça experiências
- Versão de avaliação localSe você estiver com um orçamento apertado, poderá instalar o Splunk localmente e usá-lo gratuitamente por um período de teste de 60 dias
- Facilidade de uso: Splunk Linguagem de processamento de pesquisa (SPL) é bastante fácil de aprender, mas poderoso, e há muitos recursos disponíveis para você começar
- Aplicativos Splunk: O Splunk vem com um ecossistema vibrante de aplicativos de instalação com um clique, incluindo um Kit de ferramentas de aprendizado de máquina capaz de desbloquear modelos de ML sem a necessidade de codificação - uma ferramenta ideal para iniciantes e para aqueles que não estão totalmente familiarizados com bibliotecas como Pytorch, Pandas e TensorFlow.
Como um SRE do ACME, podemos nos perguntar: Uma implementação simples será capaz de gerar resultados significativos? Espera-se que os cientistas de dados estejam dispostos a confirmar que, no estado atual do setor, a necessidade de IA do mercado não exige necessariamente os algoritmos mais recentes e de ponta; como se vê, técnicas tradicionais como regressão, detecção de outlier, agrupamento e análise de sentimentos são as ferramentas mais eficazes que uma organização pode implementar hoje para impulsionar a transformação digital.
Naturalmente, é uma boa prática ter uma compreensão básica da teoria por trás dessas técnicas. Em contrapartida, você não precisará saber sobre redes convolucionais, aprendizagem por reforço, redes adversárias generativas, Blenders e assim por diante.
Bem, parece que já temos o plano - é hora de colocar a mão na massa! Nos próximos parágrafos, veremos:
- Gerar e importar para o Couchbase uma série de documentos JSON representativos das transações realizadas na loja on-line;
- Replicar essas informações em um conjunto de dados do Analytics
- Use o SQL++ para executar consultas nesse conjunto de dados e coletar os resultados no Splunk por meio das APIs REST do Analytics.
- Use o Splunk para criar painéis para exibir dados operacionais e previsões de aprendizado de máquina em tempo real[1]
Pegue uma xícara de chá e prepare-se: estamos prestes a decolar. Vamos lá!
6 etapas para a inteligência contínua
Etapa #1: Geração de dados
Para garantir a conformidade com os regulamentos de dados, usaremos uma ferramenta on-line chamada Gerador de JSON[2] para gerar documentos JSON representativos de transações na loja on-line da ACME; veja abaixo como configuramos os parâmetros de geração[3]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[ '{{repeat(120 ,2000 )}}', { _id: 'order_{{objectId()}}', orderId:'{{integer(90000,1256748321)}}', transaction:'{{random("declined","approved")}}', name: '{{firstName()}} {{surname()}}', gender: '{{gender()}}', email: '{{email()}}', country: '{{country()}}', city: '{{city()}}', phone: '{{phone()}}', ts: Date.now()+600000, product: [ '{{repeat(1,9)}}', 'product: {{random("apples", "tea bags", "butter", "milk", "kale", "wine", "cookies", "hamburgers", "sweet potatoes", "brown rice", "barley" ) }}' ] } ] |
Quando você clicar em "Generate" (Gerar), a ferramenta responderá com um conjunto variável de documentos JSON (entre 120 e 2.000), conforme a captura de tela abaixo.
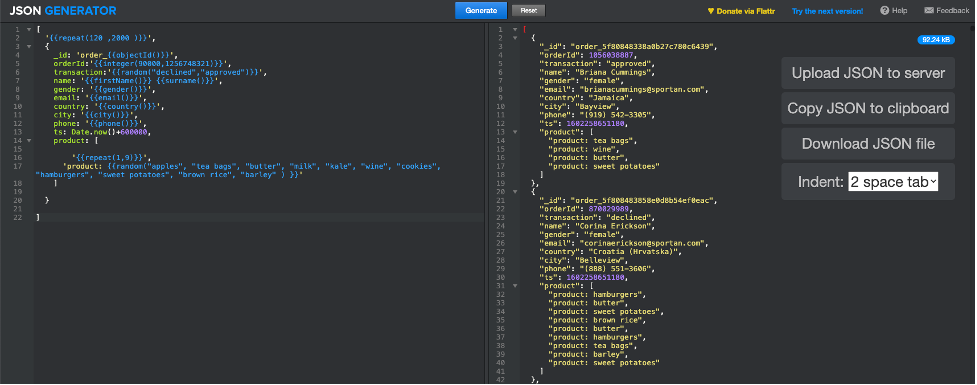
Temos nossa linha de base, é hora de mudar para o Couchbase!
Etapa #2: Importando dados no Couchbase
Presumimos que já exista um cluster do Couchbase disponível, executando pelo menos os dados e o serviço de análise.
Como primeira etapa, vamos criar um balde nomeado couchmart (sinta-se à vontade para nomeá-lo como quiser) no qual os documentos JSON serão carregados.
Em seguida fazer upload dos arquivos JSON para o cluster do Couchbaseescolha um nó que esteja executando o serviço de dadose importe os arquivos para o /tmp (você pode usar qualquer pasta que desejar). Se você tiver SCP disponível, execute este comando no terminal de seu computador local:
|
1 |
Scp <jsonfile> <couchbaseuser>@<couchbaseserver>:/tmp |
Apenas certifique-se de definir , e de acordo com seu ambiente.
Por último, vamos importar os arquivos JSON para o bucket do couchmart, usando o cbimport (mais informações aqui); primeiro, faça login no nó de dados para o qual você carregou os arquivos anteriormente via SSH:
|
1 |
ssh <couchbaseuser>@<couchbaseserver> |
Depois de fazer o login com sucesso, execute o comando cbimport conforme descrito abaixo, certificando-se de definir os campos entre de acordo com seu ambiente:
|
1 2 |
$CBHOME/bin/cbimport json -c couchbase://localhost -b <bucketname> -u <user> - p <password> -f list -d file:///tmp/<jsonfile> -g %_id% -t 4 |
A importação deve ser concluída em um piscar de olhos, pois o Couchbase pode lidar com ordens de magnitude maiores. Você deve confirmar que o nosso bucket agora tem alguns documentos na interface de usuário do administrador do Couchbase na seção buckets - veja a captura de tela abaixo.
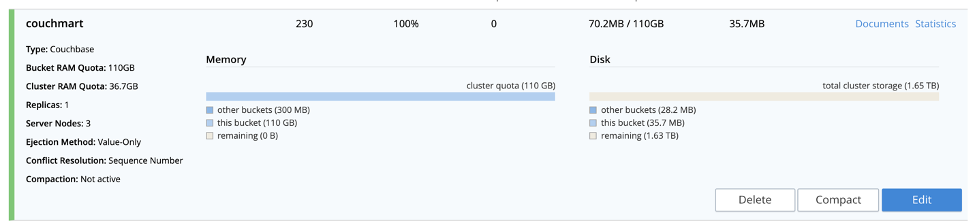
Temos dados; é hora de fazer análises!
Etapa #3: Criar e testar conjuntos de dados do Analytics
Como primeira etapa, vamos criar um conjunto de dados chamado acmeorders (adivinhe? você pode dar o nome que quiser!) como uma réplica da sombra da caçamba do couchmartEsse conjunto de dados conterá todas as informações expostas no downstream do Splunk.
Se você não estiver familiarizado com a criação de conjuntos de dados, recomendamos que consulte A documentação e este tutorial. Dois comandos SQL++ são suficientes para criar uma réplica completa dos buckets do couchmart:
|
1 |
CREATE DATASET acmeorders ON couchmart; |
seguido por:
|
1 |
CONNECT LINK Local; |
Não há nada mais fácil do que isso!
Como vamos usar as APIs restantes, agora é um bom momento para testá-las usando o prático comando curl abaixo; como sempre, verifique novamente os valores dentro de e a porta configurada para o serviço de análise:
|
1 |
curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders;" https://<couchbaseserver>:8095/analytics/service |
Se esse comando funcionar, o Couchbase está pronto para funcionar. Antes de passarmos para o Splunk, lembre-se de que:
- O serviço Couchbase Analytics depende de um arquitetura de processamento paralelo massivo (MPP) que se dimensiona linearmente; isso significa que, se você precisar dobrar o desempenho, basta dobrar os nós.
- Na versão 6.6, introduzimos muitos recursos excelentes no serviço do Analytics; faça não deixe de dar uma olhada neles!
Muito bem, o Couchbase está nos apoiando, é hora de obter alguma inteligência acionável!
Etapa #4: Instalação e configuração do Splunk
No restante deste documento, assumiremos que o Splunk está sendo executado no Linux, portanto, os caminhos podem mudar se você estiver no Mac ou no Windows.
Se você não tiver uma instância do Splunk disponível, poderá instalar uma instância local aproveitando uma avaliação gratuita de 60 dias. Uma instalação local totalmente nova não deve levar mais do que 10 minutos para ser concluída.
Certifique-se de instalar o Kit de ferramentas de aprendizado de máquina da SplunkSe você precisar saber mais sobre como instalar um aplicativo Splunk, clique aqui - É super simples!
Para configurar efetivamente a integração com o Couchbase (ou qualquer outra fonte), é fundamental configurar o Splunk para interpretar corretamente a saída da chamada REST do Couchbase e armazenar as informações em um formato eficaz para o SPL. Para isso, criaremos um novo tipo de fonteEm resumo, um tipo de fonte define como o Splunk analisa os dados na entrada; não vamos nos aprofundar em como criar um tipo de fonte, mas forneceremos uma solução viável.
Conecte-se via SSH ao seu servidor Splunk e, em seguida, navegue até:
|
1 |
Cd $SPLUNKBASE/etc/system/local |
Crie um novo arquivo chamado props.conf da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[couchbase] SEDCMD-remove_header = s/(.+\"results\":\s\[\s)//g SEDCMD-remove_trailing_commas = s/\},/}/g SEDCMD-remove_footer = s/(\],\s\"plans\".+)//g TIME_PREFIX = \" ts\":\s+ category = Structure disabled = false pulldown_type = 1 BREAK_ONLY_BEFORE_DATE = DATETIME_CONFIG = LINE_BREAKER = (,)\s\{ NO_BINARY_CHECK = true SHOULD_LINEMERGE = false |
Uma vez salvo, reiniciar o Splunk. Agora você deve ser capaz de usar um novo tipo de fonte chamado couchbaseBasta navegar em Settings > Source Types para verificar se tudo está correto:
Agora é hora de criar um novo índice de eventos Splunk que usaremos para capturar as transações da loja ACME conforme consultadas no Couchbase; no Splunk, navegue em Configurações > Índices e clique em Novo e, em seguida, configure um novo índice da seguinte forma:
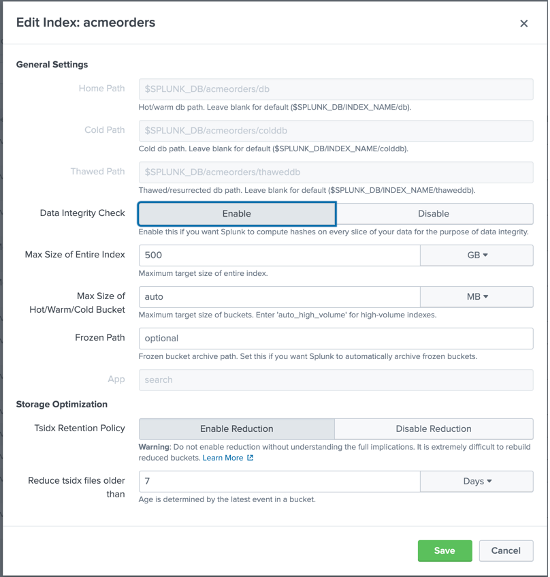
Observe que nomeamos o índice pedidos de acmee mesmo que você possa nomeá-lo como quiser, recomendamos enfaticamente que você mantenha o mesmo nome - para que você possa usar os arquivos que compartilharemos com você sem modificar o código SPL subjacente.
O Splunk está pronto; vamos abrir os portões e deixar o Couchbase alimentar alguns dados!
Etapa #5: Importando dados para o Splunk
A importação de dados para o Splunk se resume à definição de um nova entrada de dados. Observe que muitas extensões do Splunk estão disponíveis para lidar com entradas REST; no entanto, para simplificar, vamos configurar um entrada local baseada em script[4].
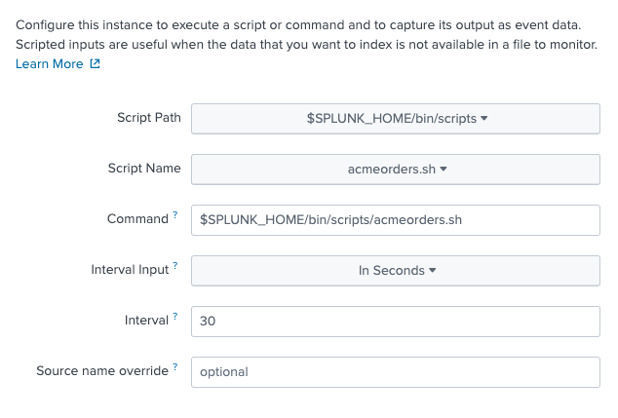
Primeiro, precisamos criar um scriptConecte-se via SSH ao seu servidor Splunk e, em seguida, navegue até:
|
1 |
Cd $SPLUNKBASE/bin/scripts |
Crie um novo arquivo chamado acmeorders.sh da seguinte forma; certifique-se de conceder permissões de execução ao usuário do splunk:
|
1 2 |
#!/bin/bash curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000;" https:// <couchbasenode>:8095/analytics/service |
Como você deve ter notado, o script usa o mesmo comando curl que usamos anteriormente ao testar o conjunto de dados acmeorders, com uma ressalva: uma condição where. É importante limitar a quantidade de dados que estão sendo importados em cada execução para evitar a duplicação maciça de dados, pois estaremos pesquisando o Couchbase a cada 30 segundos.
A condição where do SQL++:
|
1 |
Where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000 |
recuperará apenas os documentos cujo registro de data e hora seja pelo menos 90 segundos; em outras palavras, poderemos sobreviver a duas pesquisas com falha sem perder nenhum dado.
Antes de prosseguir, é importante destacar como essa abordagem pode funcionar bem para executar uma prova de conceito, enquanto que, para a produção, você deve considerar maneiras mais eficientes de usar placeholders e marcadores para garantir que somente os novos dados sejam lidos a qualquer momento, ou considerar um eventos-estratégia baseada em se aplicável.
Teste o script com uma solicitação no terminal:
|
1 |
$SPLUNKBASE/bin/scripts/acmescript.sh |
Se esse teste for bem-sucedido, é hora de configurar a nova entrada de dados. No Splunk, navegue em Configurações > Entradas de dados e escolha uma nova entrada local com base em um script.
Clique em Scripts, depois em New Local Scripts e configure um novo script da seguinte forma: primeiro, configure o caminho do script e a frequência de sondagem:
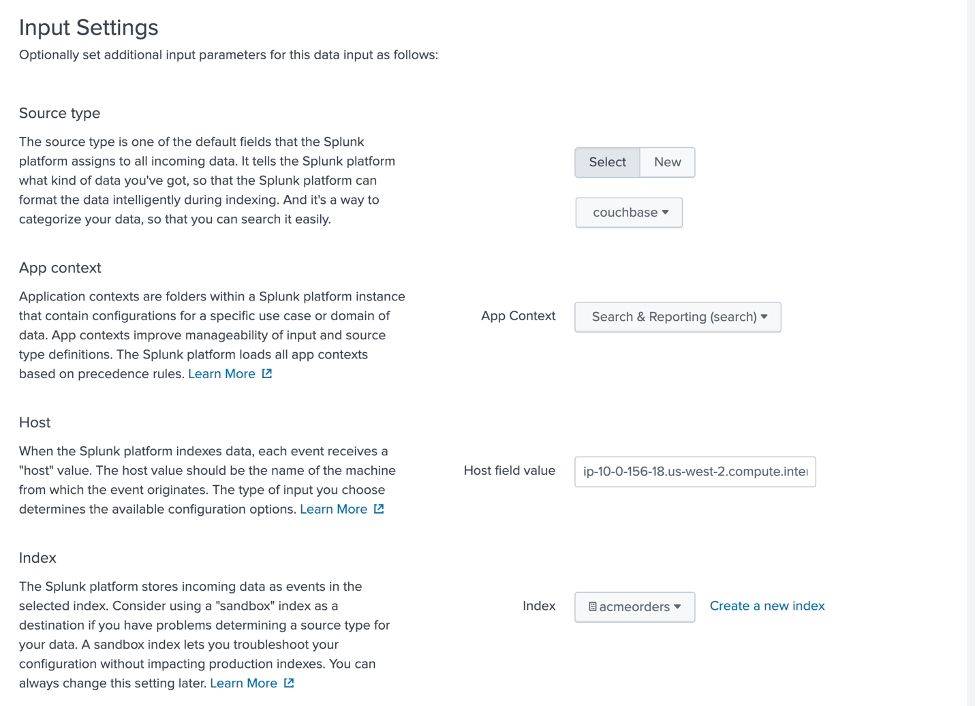
Em seguida, defina as configurações de entrada conforme mostrado abaixo, prestando atenção para selecionar couchbase como um tipo de fonte, Pesquisa e relatórios como Contexto do aplicativoe pedidos de acme como um índice.
Revise e envie para salvar. Para garantir que os dados estejam fluindo corretamente para o SplunkAcesse o aplicativo Search and Reporting:
e tente a seguinte consulta SPL, certificando-se de selecionar Todo o tempo em vez de Últimas 24 horas na caixa de combinação do filtro de tempo:
|
1 |
index="acmeorders" sourcetype="couchbase" | dedup acmeorders.orderId | search acmeorders.product{}=* | table _time, acmeorders.name, acmeorders.gender, acmeorders.country, acmeorders.gender, acmeorders.city, acmeorders.orderId, acmeorders.product{} , acmeorders.transaction | rename acmeorders.product{} as product | rename acmeorders.gender as gender | rename "acmeorders.transaction" as approval | rename acmeorders.orderId as orderId | rename acmeorders.name as name | rename acmeorders.country as country | rename acmeorders.city as city |
Você deverá ver algo semelhante à imagem abaixo:
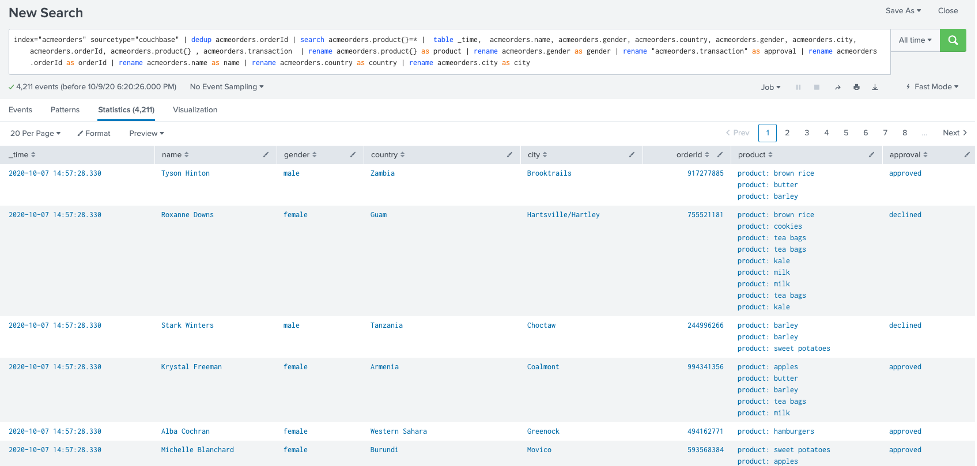
Se esse teste for bem-sucedido... Parabéns! Você integrou o Splunk ao Couchbase!
Uma etapa final: Liberar a Inteligência Contínua!
Etapa #6: Implantação de um painel do Splunk com detecção de anomalias orientada por ML
Para não perdermos tempo, não vamos nos aprofundar em como criar painéis e modelos de aprendizado de máquina no Splunk; em vez disso, forneceremos a você um painel totalmente funcional configurado para se atualizar a cada 30 segundos, aproveitando o recurso Referência de XML simples em destaque no Splunk.
Para importar o painel de modelosFaça login no Splunk e, no aplicativo Search and Reporting, clique em Dashboards e, em seguida, em "Create a New Dashboard" (Criar um novo painel); dê a ele um nome de sua escolha e clique em "Create Dashboard" (Criar painel).
Na parte superior da tela, você deve ver o botão "Source" - clique nele:

Basta colar o código XML contido neste arquivo. Quando terminar, clique em Salvar e relaxe... Estamos prontos!
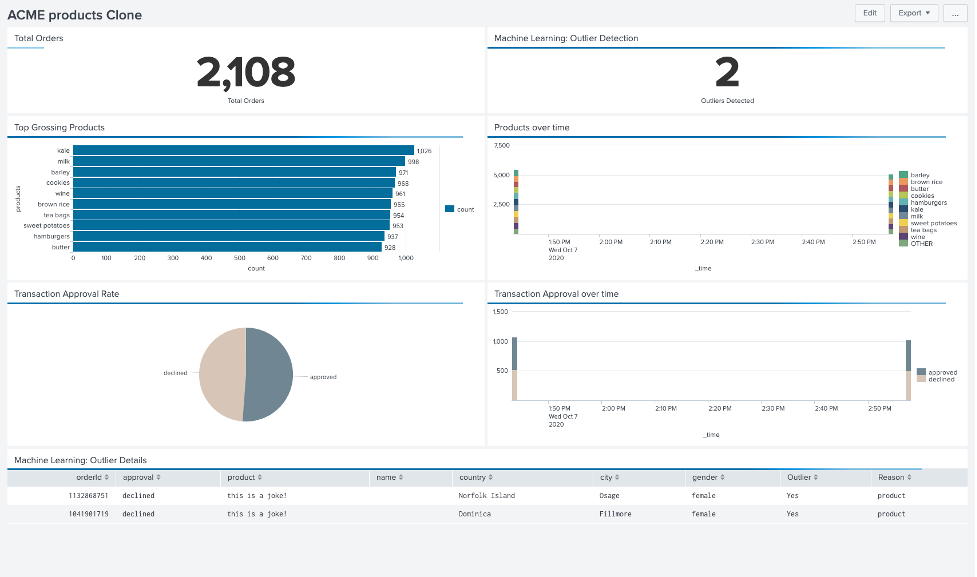
Como na imagem abaixo, agora você deve ter acesso a um painel que mostra o total de pedidos ingeridos, informações sobre produtos e aprovações de transações, além de outliers detectados usando o Machine Learning. atualizado em tempo real!
Chamado à ação: tire o gênio da garrafa!
Antes de deixá-lo ir, solte-o Inteligência contínua em sua organização, aqui está nosso apelo à ação para você:
- Revisar a sessão James Powesnki e eu fomos os anfitriões do Couchbase Connect 2020, "Quando o Couchbase encontra a Splunk/ a plataforma de análise de dados em tempo real e orientada por IA."
- Executar várias novas importações de dados usando Gerador de JSON e o mesmo procedimento que usamos antes (ou qualquer solução equivalente) para melhor avaliar a rapidez com que as mudanças são propagadas no downstream
- Experimente com valores discrepantes, no exemplo de execução Gerador de JSON com a configuração mostrada abaixo, que gerará até dois documentos, com um nulo e um nome de produto fictício que deve acionar a detecção de outlier:
123456789101112131415161718['{{repeat(1,2)}}',{_id: 'order_{{objectId()}}',orderId:'{{integer(90000,1256748321)}}',transaction:'{{random("declined","approved")}}',name: '',gender: '{{gender()}}',email: '{{email()}}',country: '{{country()}}',city: '{{city()}}',phone: '{{phone()}}',ts: Date.now()+600000,product: ['this is a joke']}] - Faça experiências com outros insights orientados por ML! Para fins deste artigo, nos concentramos na detecção de outlier, pois é a única análise que pode ser facilmente exportada para XML; no entanto, há muitas outras rotas de valor que vale a pena explorar:
- Agrupamento: para segmentar a base de clientes
- Previsões: para prever a demanda por produtos, levando em conta a sazonalidade
- Previsões por categoria: para antecipar as necessidades dos clientes e promover a retenção
- Aprimorar os conjuntos de dados analíticos aproveitando as vantagens do Novos recursos de Links Remotos e Dados Externos introduzido no Couchbase 6.6
Obrigado por ler a postagem completa; espero que você a tenha achado interessante. Se tiver alguma dúvida, sinta-se à vontade para Entre em contato comigo ou entre em contato com o representante da Couchbase mais próximo!
Agora, vá em frente e leve sua empresa para o próximo nível!
[1] Atualizar a cada 30 segundos
[2] Falsa também seria uma ótima opção, mais poderosa, porém um pouco mais complicada
[3] Ajustamos o registro de data e hora ts para corresponder ao relógio do cluster do Couchbase; sinta-se à vontade para modificá-lo de acordo com suas necessidades
[4] Dependendo de suas necessidades, essa pode não ser a solução mais eficiente, mas é uma maneira fácil de começar