Os blogs anteriores deram uma melhor compreensão de como nossa abordagem para Observabilidade em tempo real (RTO) em geral ajuda a solucionar problemas de sistemas distribuídos e por que escolhemos o OpenTracing como base e API pública. Se ainda não o fez, você pode dar uma olhada nesses blogs aqui e aqui.
Neste blog, você aprenderá como o RTO funciona com o Java SDK e como você pode usá-lo hoje para seu benefício.
Primeiros passos
Assim que a versão do Java SDK 2.6.0 (ou posterior) for lançada, você poderá obtê-la da maneira usual, conforme descrito aqui. Como essa versão está agora em um estado de lançamento prévio, você precisa acessá-la em nosso próprio repositório maven. Por meio de um maven pom.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<dependencies> <dependency> <groupId>com.couchbase.client</groupId> <artifactId>java-client</artifactId> <version>2.6.0-dp1</version> </dependency> </dependencies> <repositories> <repository> <id>cb-pre</id> <name>Couchbase Prerelease Repo</name> <url>https://files.couchbase.com/maven2</url> </repository> </repositories> |
A única diferença que você notará é uma nova dependência chamada API de rastreamento sobre o qual falaremos daqui a pouco. Como esta não é uma versão principal, todo o código anterior funcionará como antes e você se beneficiará dos aprimoramentos imediatamente.
Se precisar personalizar o próprio rastreador ou algumas de suas configurações, você poderá fazer isso por meio do comando CouchbaseEnvironment.Builder como em todas as outras configurações. Aqui está um exemplo de como personalizar nosso rastreador padrão para reduzir o intervalo de tempo em que as informações são registradas:
|
1 2 3 4 5 6 7 |
Tracer tracer = ThresholdLogTracer.create(ThresholdLogReporter.builder() .logInterval(10, TimeUnit.SECONDS) // log every 10 seconds .build()); CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); |
Explicação sobre o registro em log de limite
Para nos familiarizarmos com o rastreador de registro de limiares (que está ativado por padrão), vamos personalizar um pouco suas configurações e reduzir os limiares a um nível tão baixo que praticamente todas as solicitações e respostas serão cobertas. Obviamente, essa não é uma boa ideia para a produção, mas nos ajudará a chegar rapidamente à saída de registro desejada e a afirmar sua funcionalidade.
Aplique a seguinte configuração, conforme descrito acima:
|
1 2 3 4 5 6 |
Tracer tracer = ThresholdLogTracer.create(ThresholdLogReporter.builder() .kvThreshold(1) // 1 micros .logInterval(1, TimeUnit.SECONDS) // log every second .sampleSize(Integer.MAX_VALUE) .pretty(true) // pretty print the json output in the logs .build()); |
Isso definirá nosso limite para operações de chave/valor para um microssegundo, registrará as operações encontradas a cada segundo e definirá o tamanho da amostra para um valor muito grande para que tudo seja registrado. Por padrão, o registro será feito a cada minuto (se algo for encontrado) e apenas uma amostra das 10 operações mais lentas. O limite padrão para a operação de chave/valor é de 500 milissegundos.
Com essas configurações em vigor, estamos prontos para executar algumas operações. Sinta-se à vontade para ajustar a configuração a seguir para que ela aponte para o seu servidor e aplique as credenciais apropriadas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// Connect CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); Cluster cluster = CouchbaseCluster.create(env, "127.0.0.1"); Bucket bucket = cluster.openBucket("travel-sample"); // Load a couple of docs and write them back for(int i = 0; i < 5; i++) { JsonDocument doc = bucket.get("airline_1" + i); if (doc != null) { bucket.upsert(doc); } } Thread.sleep(TimeUnit.MINUTES.toMillis(1)); |
Neste código simples, estamos lendo alguns documentos do amostra de viagem e, se encontrado, escreva-o de volta com um upsert. Isso nos permite, de forma simples, realizar operações de leitura e gravação. Quando o código for executado, você verá uma saída (semelhante) nos registros:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
Apr 04, 2018 9:42:57 AM com.couchbase.client.core.tracing.ThresholdLogReporter logOverThreshold WARNING: Operations over threshold: [ { "top" : [ { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x6", "dispatch_us" : 315, "remote_address" : "127.0.0.1:11210", "total_us" : 576 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x5", "dispatch_us" : 319, "remote_address" : "127.0.0.1:11210", "total_us" : 599 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x4", "dispatch_us" : 332, "remote_address" : "127.0.0.1:11210", "total_us" : 632 }, { "server_us" : 11, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x3", "dispatch_us" : 392, "remote_address" : "127.0.0.1:11210", "total_us" : 762 }, { "server_us" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 9579, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 16533 }, { "server_us" : 56, "encode_us" : 12296, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "upsert:0x2", "dispatch_us" : 1280, "remote_address" : "127.0.0.1:11210", "total_us" : 20935 } ], "service" : "kv", "count" : 6 } ] |
Este é o nosso repórter de registro de limite em ação! Para cada serviço (somente kv com base nessa carga de trabalho), ele mostrará a quantidade total de operações registradas (por meio de contagem) e lhe dará as operações mais lentas classificadas por sua latência. Como somente companhia aérea_10 existe no bucket, você vê 5 buscas de documentos, mas apenas uma mutação acontecendo.
Vamos dar uma olhada em uma operação específica e discutir cada campo com um pouco mais de detalhes:
|
1 2 3 4 5 6 7 8 9 10 |
{ "server_us" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 1203, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 1525 } |
Ele nos diz o seguinte:
total_us: O tempo total que levou para executar a operação completa: aqui, cerca de 1,5 milissegundosserver_us: O servidor informou que seu trabalho realizado levou 23 microssegundos (isso não inclui o tempo de rede ou o tempo no buffer antes de ser coletado no cluster)decodificar_us: A decodificação da resposta levou 1,2 milissegundos para o clientedispatch_us: O tempo em que o cliente enviou a solicitação e obteve a resposta levou cerca de 1 milissegundo.endereço_local: O soquete local usado para essa operação.endereço_remoto: O soquete remoto no servidor usado para essa operação. Útil para descobrir qual nó foi afetado.operation_id: Uma combinação de tipo de operação e id (nesse caso, o valor opaco), útil para diagnosticar e solucionar problemas em combinação com olocal_id.local_id: Com o Server 5.5 e posterior, esse ID é negociado com o servidor e pode ser usado para correlacionar informações de registro em ambos os lados de forma mais simples.
Observe que o formato exato desse registro ainda está um pouco em fluxo e mudará entre as versões dp1 e beta/GA.
É possível ver que, se os limites forem definidos da maneira correta com base nos requisitos de produção, sem muito esforço as operações lentas poderão ser registradas e identificadas com mais facilidade do que antes.
No entanto, há uma peça faltando no quebra-cabeça que abordaremos a seguir: como isso se relaciona com o temido TimeoutException.
Visibilidade do tempo limite
Anteriormente, quando uma operação demorava mais do que o tempo limite especificado permitia, uma mensagem TimeoutException é lançado. Em geral, tem a seguinte aparência:
|
1 2 3 4 5 6 |
Exception in thread "main" java.lang.RuntimeException: java.util.concurrent.TimeoutException at com.couchbase.client.java.util.Blocking.blockForSingle(Blocking.java:77) at com.couchbase.client.java.CouchbaseBucket.get(CouchbaseBucket.java:131) at Main.main(Main.java:34) Caused by: java.util.concurrent.TimeoutException ... 3 more |
Observando esse rastreamento de pilha, você pode deduzir algumas coisas, como, por exemplo, que a operação de tempo limite foi uma ObterSolicitação. Se, em tempo de execução, você precisar de mais informações, costumava envolvê-las com base em seu próprio contexto. Por exemplo:
|
1 2 3 4 5 6 7 |
try { bucket.get("foo", 1, TimeUnit.MICROSECONDS); } catch (RuntimeException ex) { if (ex.getCause() instanceof TimeoutException) { throw new RuntimeException(new TimeoutException("id: foo, timeout: 1ms")); } } |
Isso é muito tedioso e ainda não lhe dá uma visão do comportamento interno conforme necessário.
Para remediar essa situação, o novo cliente faz (aproximadamente) a coisa acima para você de forma transparente, mas acrescenta ainda mais informações sem que você precise fazer nada. O mesmo tempo limite no novo SDK terá a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 |
Exception in thread "main" java.lang.RuntimeException: java.util.concurrent.TimeoutException: localId: 2C12AAA6637FB4FF/00000000147B092F, opId: 0x1, local: 127.0.0.1:60389, remote: 127.0.0.1:11210, timeout: 1000us at rx.exceptions.Exceptions.propagate(Exceptions.java:57) at rx.observables.BlockingObservable.blockForSingle(BlockingObservable.java:463) at rx.observables.BlockingObservable.singleOrDefault(BlockingObservable.java:372) at com.couchbase.client.java.CouchbaseBucket.get(CouchbaseBucket.java:131) at SimpleReadWrite.main(SimpleReadWrite.java:64) Caused by: java.util.concurrent.TimeoutException: localId: 2C12AAA6637FB4FF/00000000147B092F, opId: 0x1, local: 127.0.0.1:60389, remote: 127.0.0.1:11210, timeout: 1000us at com.couchbase.client.java.bucket.api.Utils$1.call(Utils.java:75) at com.couchbase.client.java.bucket.api.Utils$1.call(Utils.java:71) *snip* |
Talvez você se lembre de alguns dos campos da descrição do registro acima, e isso é intencional. Agora, o próprio tempo limite fornece informações valiosas, como os soquetes locais e remotos, o ID da operação, bem como o tempo limite definido e o ID local usado para solução de problemas. Sem esforço extra, você pode pegar essas informações e correlacioná-las com as operações mais lentas no log de limite.
O TimeoutException agora fornece mais informações sobre "o que" deu errado e, em seguida, você pode examinar o registro para descobrir "por que" ele estava lento.
Troca do Tracer
Por fim, há mais um recurso incorporado a isso. Conforme mencionado anteriormente, o novo API de rastreamento vem incluído por um motivo. Ele fornece apenas uma descrição da interface, mas isso é suficiente para abrir todas essas métricas e estatísticas para todo um universo de implementações de rastreamento compatíveis com o OpenTracing. Você pode escolher uma das implementações de código aberto disponíveis, como jaegerVocê pode usar um fornecido pelos fornecedores de APM ou até mesmo criar o seu próprio. O ponto principal aqui é que o SDK usa uma interface aberta e padronizada à qual você pode conectar outras coisas, incluindo um Tracer básico e útil.
Como exemplo, veja como você pode trocar o nosso rastreador padrão por um do jaeger:
|
1 2 3 4 5 6 7 8 9 10 |
Tracer tracer = new Configuration( "my_app", new Configuration.SamplerConfiguration("const", 1), new Configuration.ReporterConfiguration( true, "localhost", 5775, 1000, 10000) ).getTracer(); CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); |
Sem nenhuma alteração no aplicativo real, todos os rastreamentos e intervalos agora serão alimentados em um mecanismo de rastreamento distribuído, no qual você tem interfaces de usuário agradáveis para visualizar o comportamento do cenário do aplicativo.
Uma operação de obtenção, como no exemplo acima, pode ter a seguinte aparência na página de visão geral do jaeger:
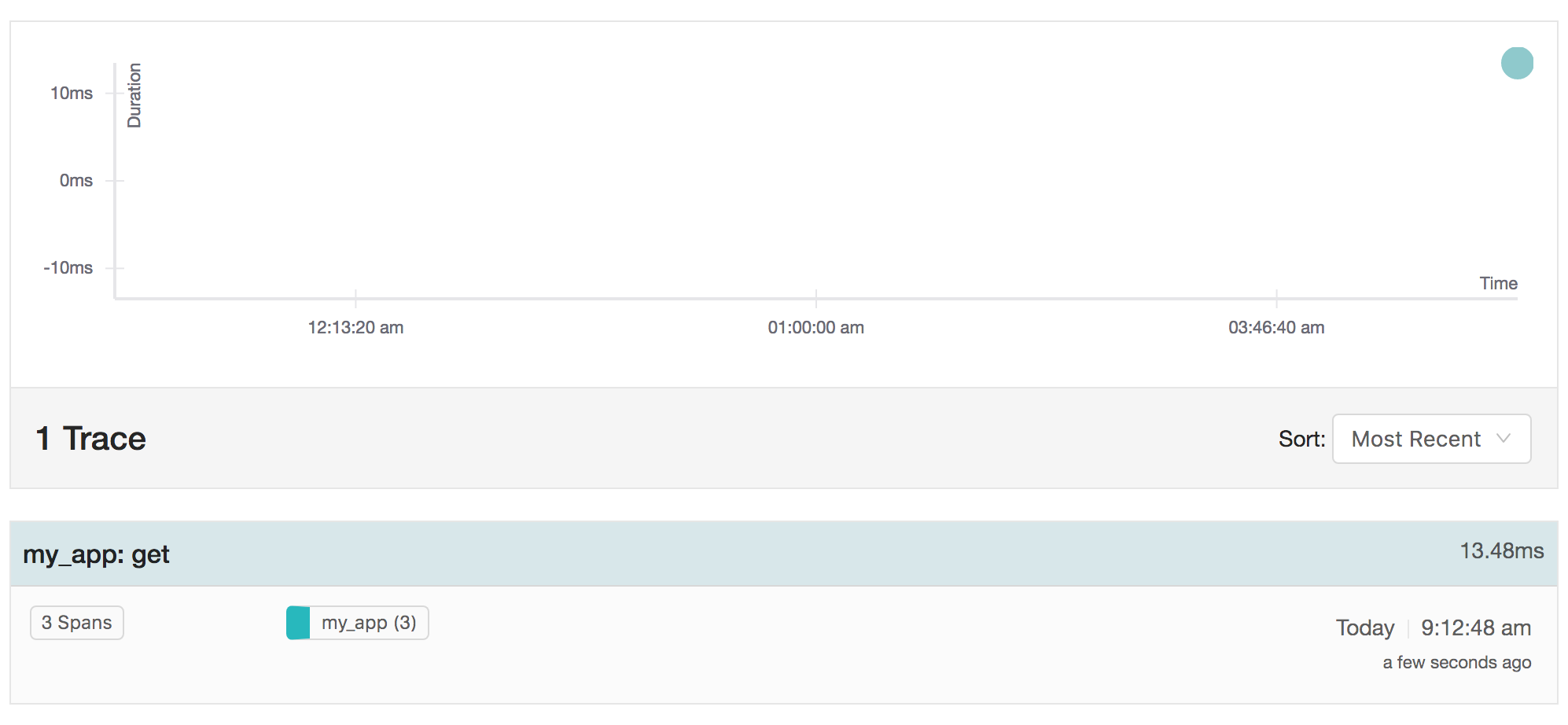
Ao analisar o traço específico, os tempos individuais do span e do sub-span se tornam visíveis:
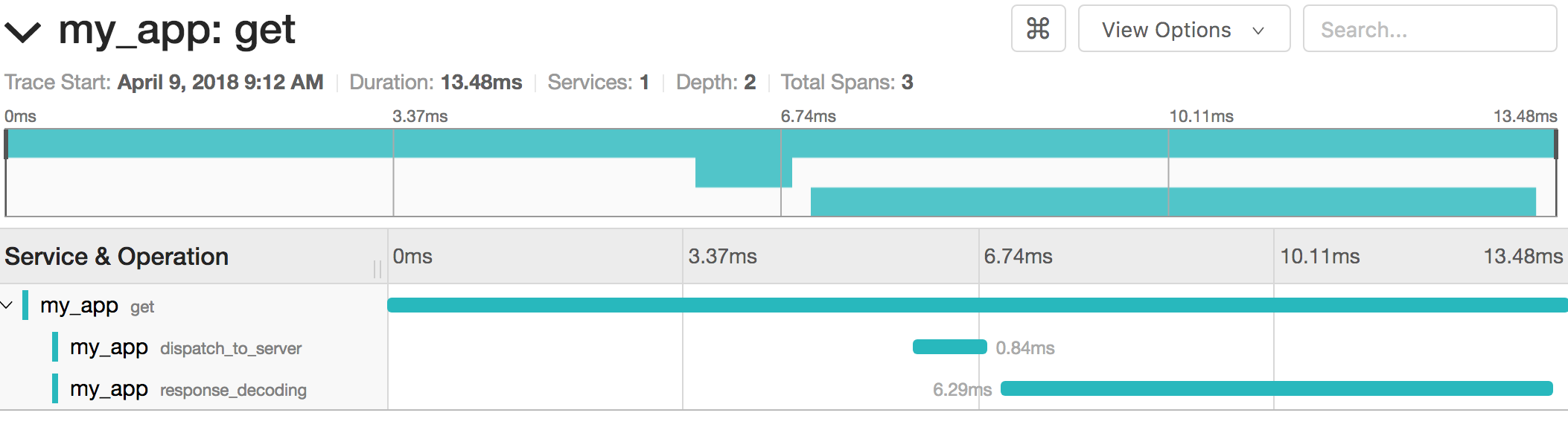
Cada intervalo também contém tags que o SDK anexa para filtragem e análise avançadas:
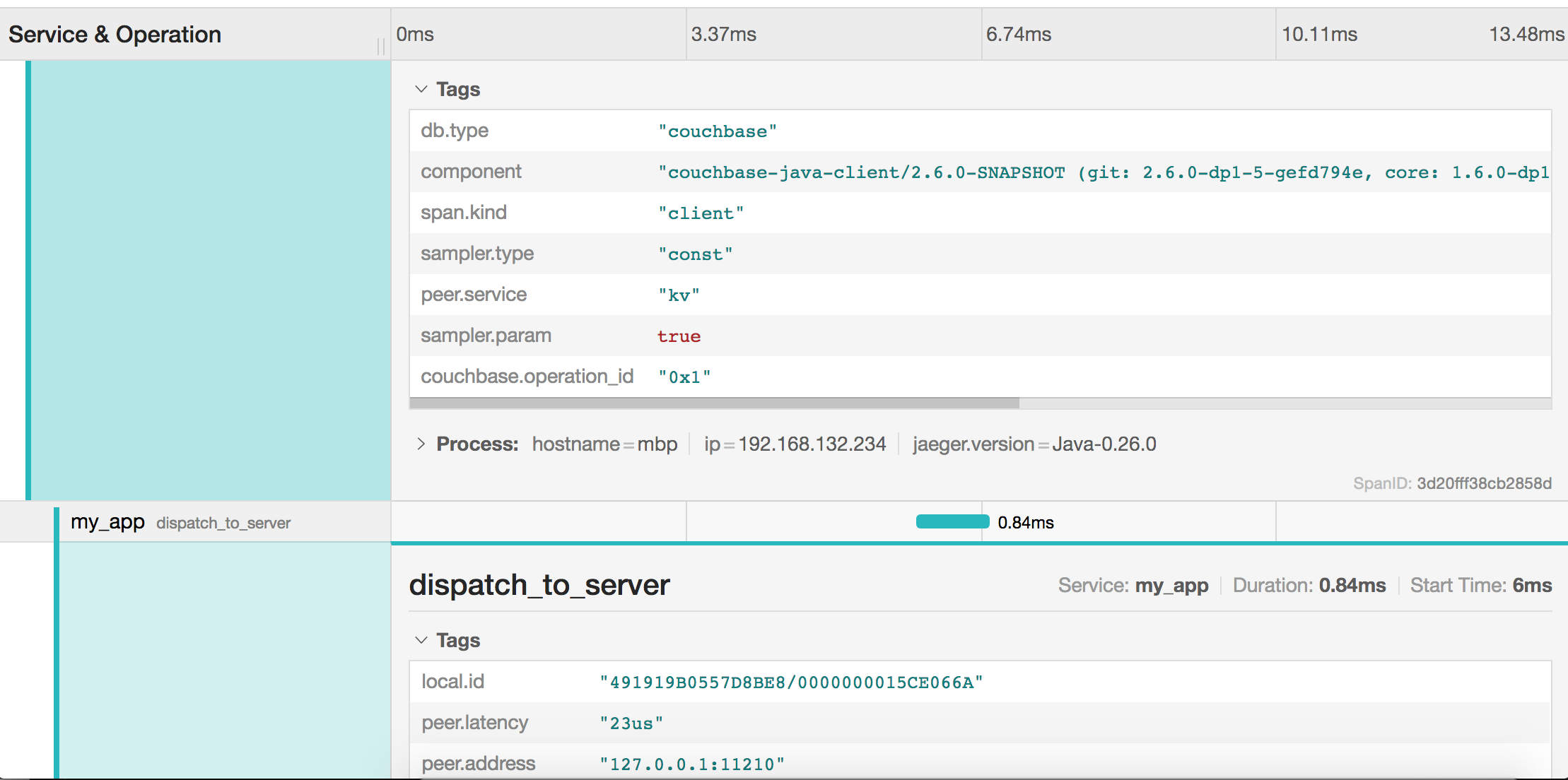
Resumo
Aprimorando nossos SDKs com o Response Time Observability, agora podemos fornecer informações mais detalhadas sobre o que e por que algo não está funcionando/desempenhando conforme o esperado. Contando com o OpenTracing como interface, além disso, podemos torná-lo independente do fornecedor e abrir a possibilidade de conectar a ferramenta APM/rastreamento compatível de sua preferência, se houver necessidade.