Estou apenas começando a usar o NiFi, uma ferramenta para automatizar o fluxo de dados. É uma ferramenta para migração, sincronização e outros tipos de processamento de dados. Ela me foi apresentada por um dos mais novos clientes do Couchbase: o Cincinnati Reds.
Neste post, descreverei para que os Reds estão usando o NiFi e mostrarei como começar a trabalhar com um fluxo de dados muito básico do SQL Server para o Couchbase Server.
NiFi e os Reds
Os Reds querem criar algumas visualizações dos ingressos que estão sendo escaneados no dia do jogo no Great American Ball Park.
A equipe de dados tem acesso a um banco de dados do SQL Server que é usado para armazenar dados ao vivo sobre um jogo. Sempre que um ingresso é escaneado no portão, os dados são colocados nesse banco de dados. (Esse banco de dados também rastreia concessões e outros dados).
Os Reds poderiam consultar os dados diretamente do SQL Server, mas uma visualização em tempo real durante a carga pesada do jogo resultaria em uma visualização lenta ou em uma carga excessiva para o banco de dados, ou ambos. Em vez disso, eles gostariam de copiar esses dados em um cluster Couchbase e usar o cluster como backend para a visualização.
Há várias maneiras de mover dados para o Couchbase, mas os Reds já estão usando o Apache NiFi de código aberto com o SQL Server, e seria ideal se eles pudessem usar essa mesma combinação para este projeto. Felizmente, o NiFi já é compatível com o Couchbase, portanto é muito fácil fazer isso.
Primeiros passos com o NiFi e o Couchbase
Para começar a fazer experimentos com o NiFi localmente, decidi usar o Docker. No host do Docker, posso facilmente criar uma instância de cada um deles:
- Servidor Couchbase (é claro)
- Apache Nifi (Link do hub do Docker)
- Microsoft SQL Server (para Linux - acho que os Reds não estão usando o SQL para Linux, mas é o suficiente)
Você não precisa usar o Docker, mas ele tornou muito fácil para mim começar a trabalhar e ser produtivo imediatamente.
Aqui estão os comandos que usei para executar as imagens do Docker:
|
1 2 3 4 5 |
docker run -d --name db55beta -p 8091-8094:8091-8094 -p 11210:11210 couchbase:5.5.0-beta docker run -d --name NiFi -p 8080:8080 apache/nifi:latest docker run -d -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=<use a strong password here>' -p 1433:1433 microsoft/mssql-server-linux:2017-latest |
Observe que a senha que você fornece para SA_PASSWORD deve atender aos requisitos de senha forte do SQL Server. Caso contrário, você não conseguirá usar o SQL Server e ficará um pouco frustrado e confuso por cerca de 20 minutos.
Começando com o SQL Server
Usei o SQL Server Management Studio para me conectar à instância do SQL Server no Docker (localhost, porta 1433). Como (ainda) não tenho acesso ao servidor real do Reds, criei meu próprio esquema para fazer uma aproximação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE [dbo].[TicketCheck]( [Id] [uniqueidentifier] NOT NULL, [FullName] [varchar](100) NOT NULL, [Section] [varchar](10) NOT NULL, [Row] [varchar](10) NOT NULL, [Seat] [varchar](10) NOT NULL, [GameDay] [datetime] NOT NULL, CONSTRAINT [PK_TicketCheck] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[TicketCheck] ADD CONSTRAINT [DF_TicketCheck_Id] DEFAULT (newid()) FOR [Id] GO |
Mais tarde, vou preenchê-lo com um INSERIR declaração dessa forma:
|
1 2 3 4 5 6 7 |
INSERT INTO TicketCheck (FullName, Section, [Row], Seat, GameDay) VALUES ( 'Joey Votto', '429', 'C', '11', GETDATE() ) |
Configuração do Couchbase
Depois que fiz login no Couchbase pela primeira vez (localhost:8091) e criei um cluster, fiz duas coisas:
- Criei um bucket chamado "tickets". É para lá que quero que vão os dados do SQL Server.
- Criei um usuário também chamado "tickets", com a permissão adequada para o bucket. É importante que o usuário tenha o mesmo nome do bucket.
A razão pela qual você precisa criar um usuário com o mesmo nome é que o processador NiFi Couchbase está um pouco desatualizado, portanto, essa é uma solução alternativa. O NiFi ainda não foi atualizado para lidar com os novos recursos RBAC do Couchbase. Consulte Apache Nifi Edição 5054 para obter mais informações.
Configuração do NiFi
O NiFi é uma ferramenta de fluxo de dados visual baseada na Web. Sou um desenvolvedor, estou acostumado a códigos e linhas de comando, mas definitivamente aprecio uma interface visual agradável quando aplicável.
Se você usou o Docker, basta acessar localhost:8080/NiFi. Você verá o que parece ser uma grande folha de papel quadriculado com algumas barras de ferramentas/janelas na parte superior.
Vou pular um pouco a cabeça e mostrar o fluxo de dados completo que criei:
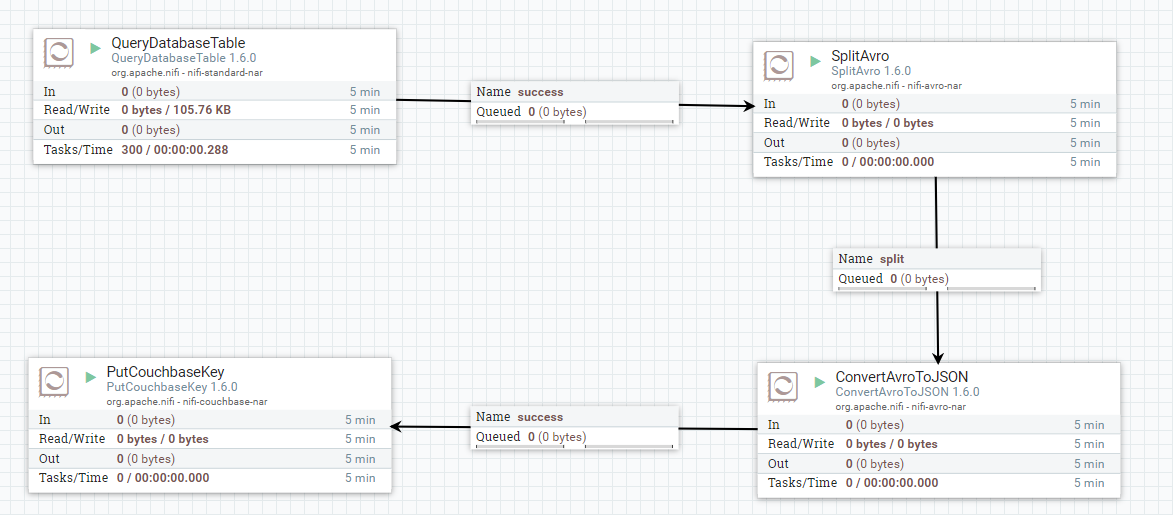
Vou explicar isso passo a passo, mas lembre-se de que não sou especialista em NiFi.
Em um nível mais alto, cada uma dessas caixas é um "processador". Cada uma delas obtém dados de algum lugar, processa os dados de alguma forma e grava os dados em outro lugar. Esse "fluxo" de dados pode vir de uma fonte externa, uma fila NiFi, ou ser gravado em uma fonte externa. Cada processador pode ser "Iniciado" e "Parado".
Serviço de pooling de conexões de banco de dados
Antes de criarmos um processador, vamos informar ao NiFi sobre os bancos de dados que usaremos.
Há uma janela "Operate" (Operar) que está flutuando sobre o papel gráfico. Clique no ícone de configurações para abrir a janela NiFi Flow Configuration (Configuração do NiFi Flow).
Observe a guia Controller Services. Penso nisso como uma coleção de fontes de dados externas às quais os processadores podem se conectar. Vamos adicionar dois serviços de controle: um para o SQL Server e outro para o Couchbase.
DBCPConnectionPool
Clique no botão "+" para adicionar. Vamos começar com o SQL Server: localize DBCPConnectionPool e clique em "Add". Ele deve aparecer na lista. Clique no ícone de engrenagem e navegue até a guia de propriedades:
- URL de conexão com o banco de dados - Digite um valor como
jdbc:sqlserver://172.17.0.4. - Nome da classe do driver de banco de dados - Se você estiver usando o SQL Server, é
com.microsoft.sqlserver.jdbc.SQLServerDriver - Local(is) do driver do banco de dados - Entrar
file:///usr/share/java/mssql-jdbc-6.4.0.jre8.jar. Observe que o NiFi não vem com esse driver pronto para uso (pelo menos não a imagem do Docker). Faça o download desse driver da Microsoft e coloque-o na pasta /usr/share/java em seu servidor NiFi (você pode usar odocker cpse você estiver usando o Docker como eu). - Usuário do banco de dados e Senha - As credenciais do SQL Server que você precisa para se conectar.
Depois de adicioná-lo, você precisará "habilitá-lo" (clique no ícone de raio) para usá-lo. Se precisar fazer alterações no futuro, você precisará desativá-lo primeiro.
CouchbaseClusterService
Em seguida, vamos informar ao NiFi sobre o Couchbase. Novamente, clique no botão "mais" para adicionar. Procure o CouchbaseClusterService. Novamente, navegue até a guia de propriedades. Deve haver uma propriedade chamada Cadeia de conexão. Digite algo como couchbase://172.17.0.3. Em seguida, clique no botão "mais" nessa guia e crie uma nova propriedade chamada "Bucket Password for tickets". Observe que o nome da propriedade deve ter o formato "Senha do balde para ". O valor dessa propriedade deve ser a senha do usuário do Couchbase que você criou anteriormente.
Agora, o NiFi conhece o SQL Server e o Couchbase. Vamos colocar isso em prática.
Tabela QueryDatabase
Começarei com a fonte dos dados: um SQL Server. Mais especificamente, uma tabela no SQL Server. E, ainda mais especificamente, apenas novas linhas de dados nessa tabela (mais sobre como definir isso mais tarde).
Primeiro, arraste o ícone "processor" do canto superior esquerdo para o papel milimetrado. Em seguida, localize o processador QueryDatabaseTable e clique em "add". Nesse momento, você terá um processador no quadro com um ícone de aviso que indica que é necessário fazer algumas configurações.
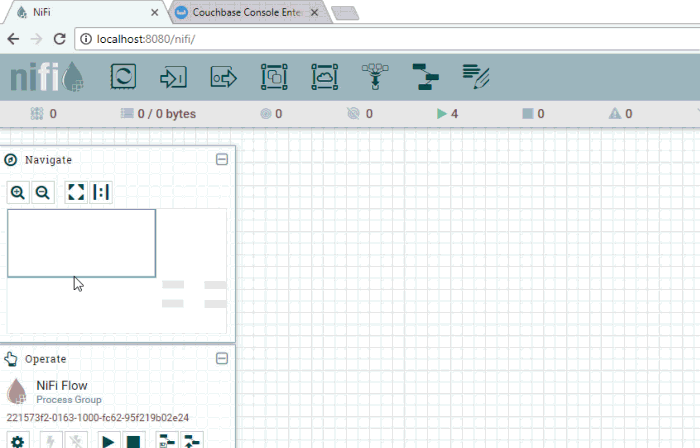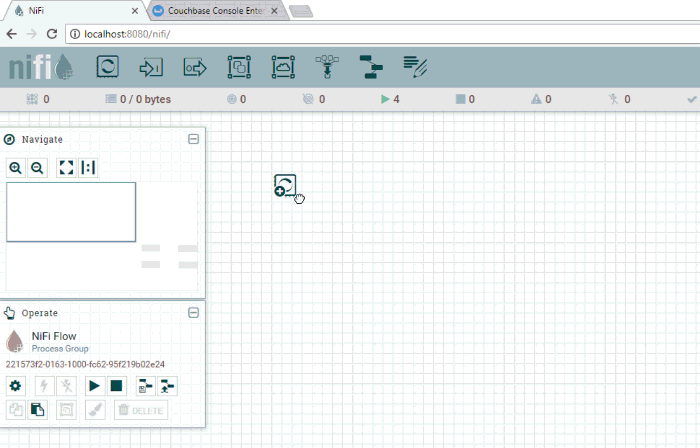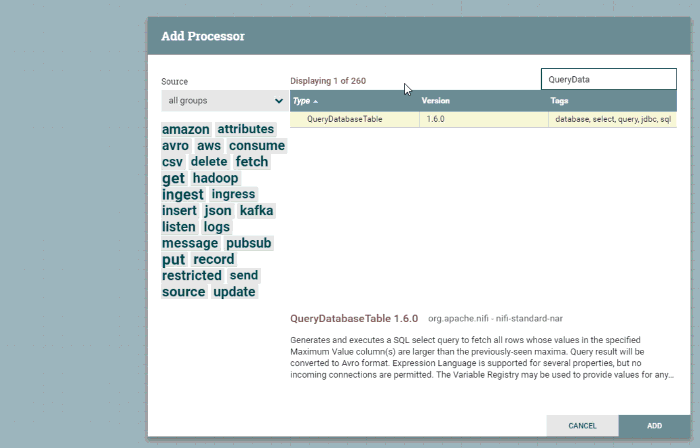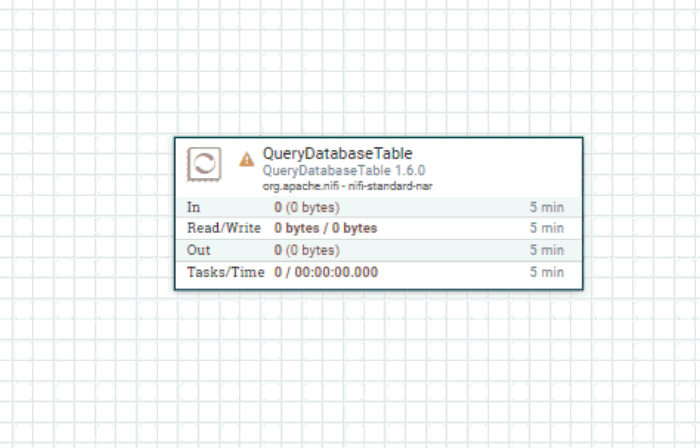
Você pode clicar duas vezes nesse processador para exibir seus detalhes. Estou interessado principalmente na guia "Properties" (Propriedades). Nessa guia, direi a esse processador a que banco de dados se conectar e como consultar os dados dele:
As propriedades de interesse:
- Serviço de pooling de conexões de banco de dados - Selecione o DBCPConnectionPool que foi criado anteriormente.
- Tipo de banco de dados - Selecionei o MS SQL 2008, que parece funcionar bem com o MS SQL para Linux, mas também há opções para o MS SQL 2012+ e "Genérico".
- Nome da tabela - Digite o nome da tabela a ser consultada.
TicketChecké a que eu usei. - Colunas de valor máximo - Eu entrei
Dia de jogo. Essa é a coluna que o NiFi verificará para encontrar dados novos/atualizados na tabela. Talvez você queira usar um campo autoincrementado, um carimbo de data/hora ou alguma outra combinação. O processador NiFi armazenará o valor mais recente em seu "estado" à medida que avança.
PutCouchbaseKey
Vamos avançar um pouco e criar outro processador. Desta vez, será um processador PutCouchbaseKey. Tudo o que esse processador faz é pegar um pedaço de dados que está fluindo para ele e criar/atualizar um documento do Couchbase com esses dados.
Para configurá-lo, defina estas propriedades:
- Serviço de controlador de cluster do Couchbase - selecione o CouchbaseClusterService que foi criado anteriormente.
- Nome do balde - ingressos
Como ir do ponto A ao ponto B
Nesse ponto, o NiFi é capaz de extrair dados do SQL Server e colocar documentos no Couchbase. Para finalizar, eles precisam estar conectados. Mas ainda há um pouco de trabalho a fazer. O processador QueryDatabaseTable gera dados "Avro", que são projetados para o Hadoop, mas também são usados pelo Spark e, é claro, pelo Nifi. Poderíamos alimentá-los diretamente no Couchbase, mas eles seriam armazenados como dados binários, e não como JSON. Portanto, há algumas etapas intermediárias para colocá-los no formato JSON puro.
Adicionei um processador SplitAvro e um processador ConvertAvroToJSON ao papel gráfico.
O processador SplitAvro dividirá o arquivo de dados Avro (potencialmente grande) em arquivos menores. Isso pode não ser estritamente necessário, mas é uma boa precaução a ser tomada e ajuda a dividir os dados para facilitar a visualização e a depuração. As propriedades padrão desse processador estão corretas.
O processador ConvertAvroToJSON faz exatamente o que diz. Isso preparará os dados do Avro para o Couchbase. Eu alterei o Opções do contêiner JSON propriedade de matriz para nenhum. Eu só quero um documento JSON simples, e não uma matriz contendo um único documento.
Conectando tudo
Agora que você tem essas quatro peças no lugar, é necessário conectá-las.
Primeiro, passe o mouse sobre o QueryDatabaseTable até ver um ícone de seta. Clique e arraste essa seta até o processador SplitAvro. Aparecerá uma fila entre eles chamada "success" (sucesso).
Repita esse procedimento com os outros processadores. Um processador pode ter uma variedade de pontos de término que definem a relação. Por exemplo, quando você arrasta uma conexão entre SplitAvro e ConvertAvroToJSON, são apresentadas três opções: falha, original e divisão. Isso varia de processador para processador, mas a ideia é a seguinte:
- falha - O SplitAvro falhou na conversão, então ele enviará os dados para "failure" (falha)
- original - O SplitAvro pode canalizar os dados originais da seguinte maneira
- dividir - Os dados reais da divisão são apresentados desta forma. É isso que você deve alimentar no ConvertAvroToJSON.
Com as outras conexões, você poderia canalizar os dados de volta para o processo para tentar novamente ou talvez canalizá-los para algum processador de notificação ou depuração.
Ativar o fluxo NiFi
Para iniciar um processador, clique nele e, em seguida, clique no botão "start" (iniciar) na janela Operate (parece o botão play de um videocassete). Talvez você queira experimentar com apenas um processador por vez e observar os dados começarem a se acumular nas filas. Por fim, quando você começar a inserir linhas na tabela do SQL Server, elas deverão acabar como novos documentos no Couchbase Server.
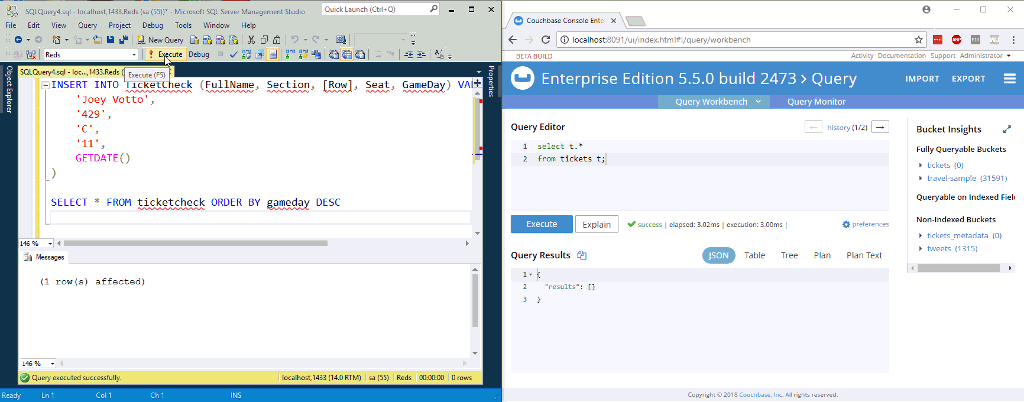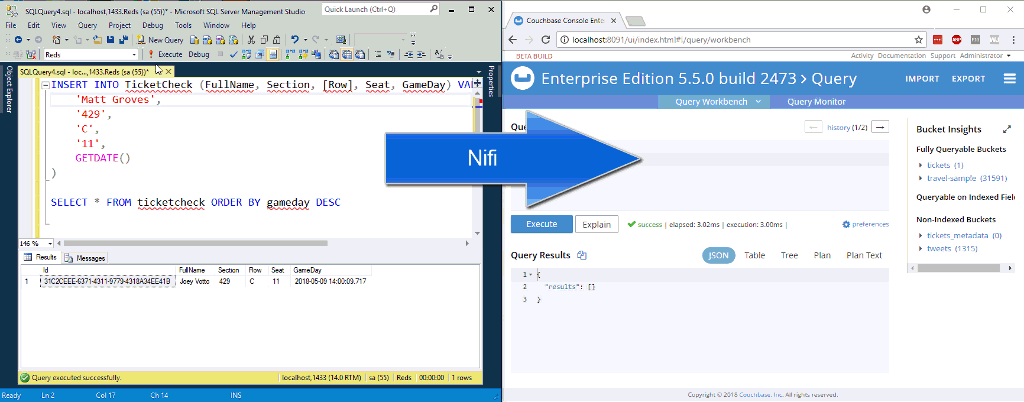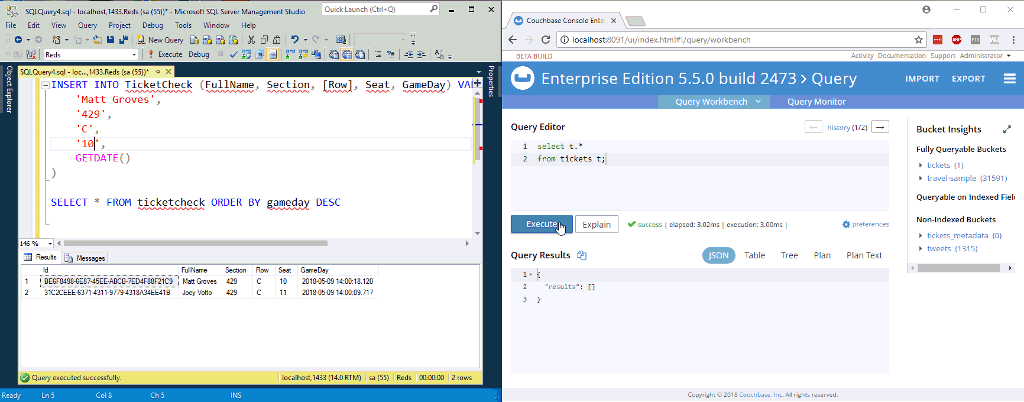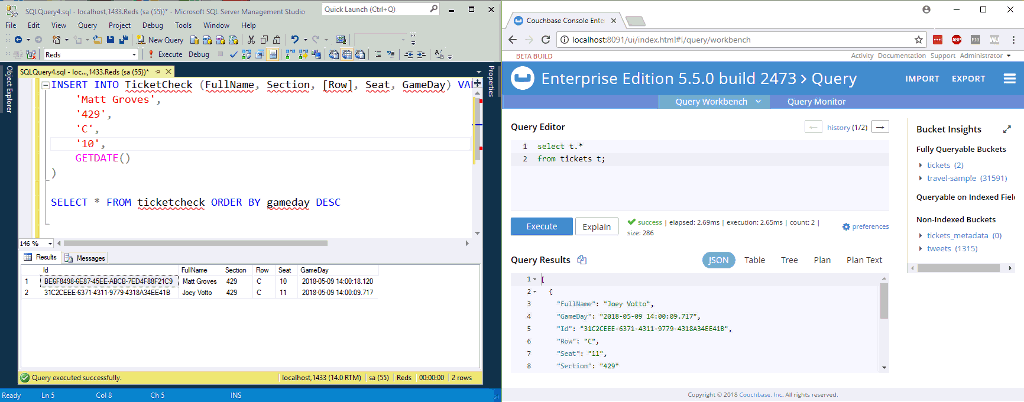
Na animação acima, estou inserindo duas novas linhas em uma tabela no SQL Server. O NiFi (não ilustrado) está processando-as e colocando-as no Couchbase.
Resumo
Esta postagem do blog fornece informações básicas sobre como começar a usar o NiFi. Há muito que você pode fazer. Se você estiver em uma empresa com uma variedade de fontes de dados, o NiFi é uma ótima ferramenta para orquestrar todos esses fluxos de dados. O Couchbase Server também é uma ótima opção:
- A flexibilidade do JSON permite que você ingira dados de praticamente qualquer fonte
- A arquitetura memory-first ajuda a maximizar o desempenho de seu fluxo de dados
- Os recursos de dimensionamento do Couchbase permitem que você aumente sua capacidade sem precisar colocar seu fluxo off-line
Estou aprendendo o NiFi pela primeira vez e já estou adorando a interface gráfica e a simplicidade dos primeiros passos. Ainda tenho muito a aprender, mas espero que este post ajude você a usar o processador Couchbase no NiFi.
Se você estiver usando o NiFi e o Couchbase, quero ouvir sua opinião. O conector do Couchbase poderia ser atualizado (consulte a edição 5054), e quanto mais vocês me contarem, mais fácil será justificar o tempo gasto trabalhando nisso.
Se você tiver dúvidas sobre o Couchbase, consulte a seção Fóruns do Couchbase Server. Se você tiver dúvidas sobre o NiFi, consulte o Apache Nifi site do projeto.
Também ficarei feliz em conversar com você sobre todos os itens acima. Você pode deixar um comentário abaixo ou me encontrar em Twitter @mgroves.