Uma construção de dados que aparece com frequência em aplicativos de negócios é a estrutura de dados hierárquica. A hierarquia captura a relação pai-filho, muitas vezes entre o mesmo objeto. Por exemplo, a estrutura de uma empresa capta a linha de reporte entre os funcionários. A organização empresarial captura o relacionamento entre as empresas controladoras e as subsidiárias. Hierarquias de território em vendas. Livro de contas em aplicativos financeiros.
Devido à natureza de autorreferência da hierarquia, consultar a estrutura de forma eficiente, juntamente com os dados associados, pode ser um desafio para o RDBMS, especialmente do ponto de vista do desempenho. Neste artigo, discutirei como o RDBMS tradicional lida com consultas hierárquicas. Os desafios com os quais ele tem de lidar e como esse problema pode ser tratado de forma semelhante com o Couchbase N1QL e o Couchbase GSI.
Estrutura hierárquica em aplicativos
O principal motivo para reunir informações em uma estrutura hierárquica é melhorar a compreensão das informações. A estrutura de relatórios da empresa é projetada não apenas para ajudar na forma como a organização é gerenciada, mas também para fornecer uma estrutura para medir e otimizar a eficácia de cada grupo. Em uma grande organização, o desempenho de vendas é geralmente avaliado, não apenas em nível individual, mas também em nível de equipe de vendas. Em resumo, as empresas organizam as informações em uma estrutura hierárquica para que possam ter uma melhor compreensão do desempenho dos negócios. Para atingir esse objetivo, as empresas precisam de um meio eficiente de consultar os dados hierárquicos.
Representação da hierarquia da empresa
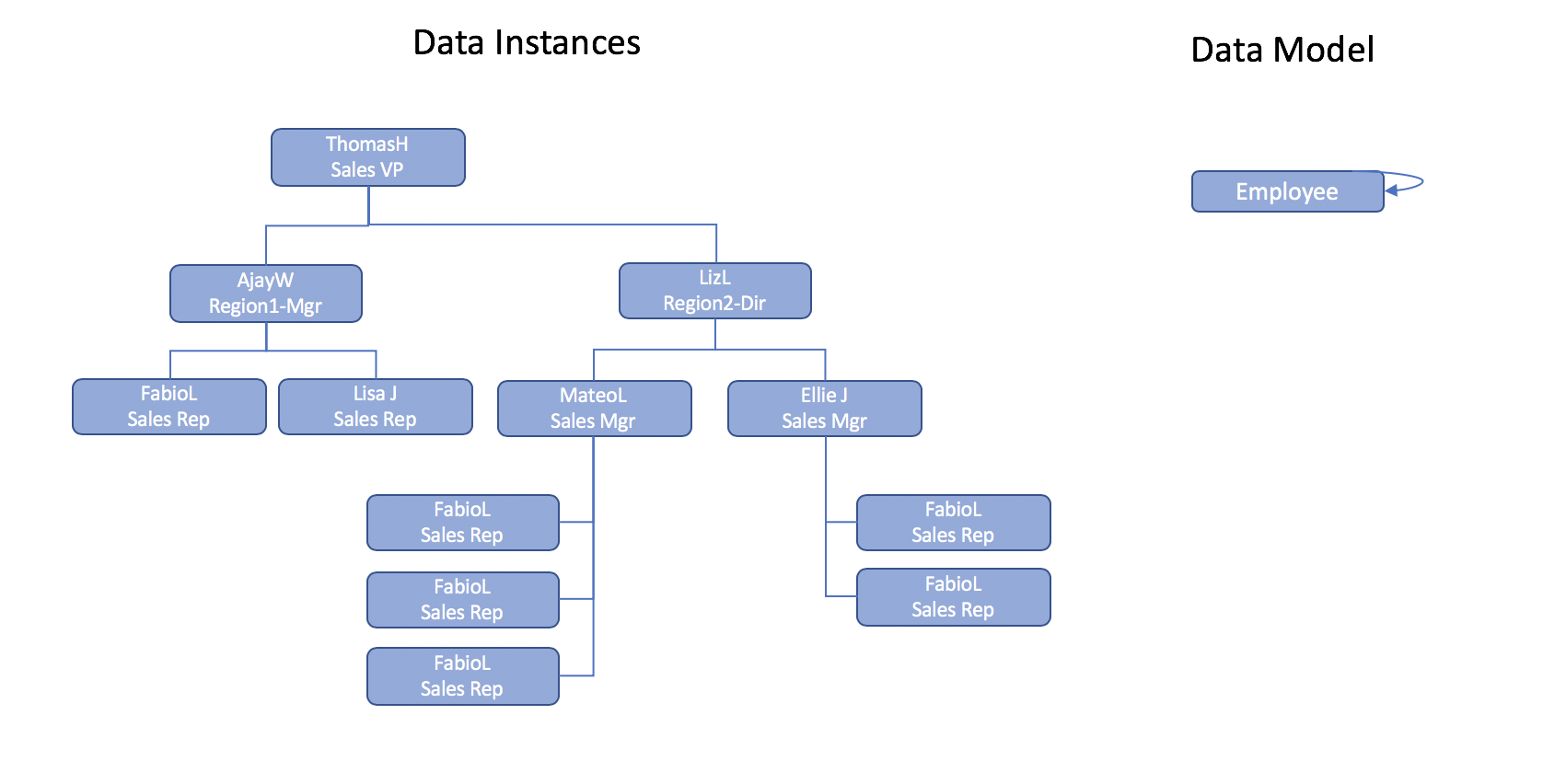
Embora o modelo de dados do banco de dados seja capaz de capturar com eficiência a estrutura hierárquica, a dificuldade surge quando você precisa consultar os dados hierárquicos e as informações relacionadas.
Considere este requisito: Obter um valor total do pedido de vendas para todos os representantes de vendas que se reportam a ThomasH - VP de vendas
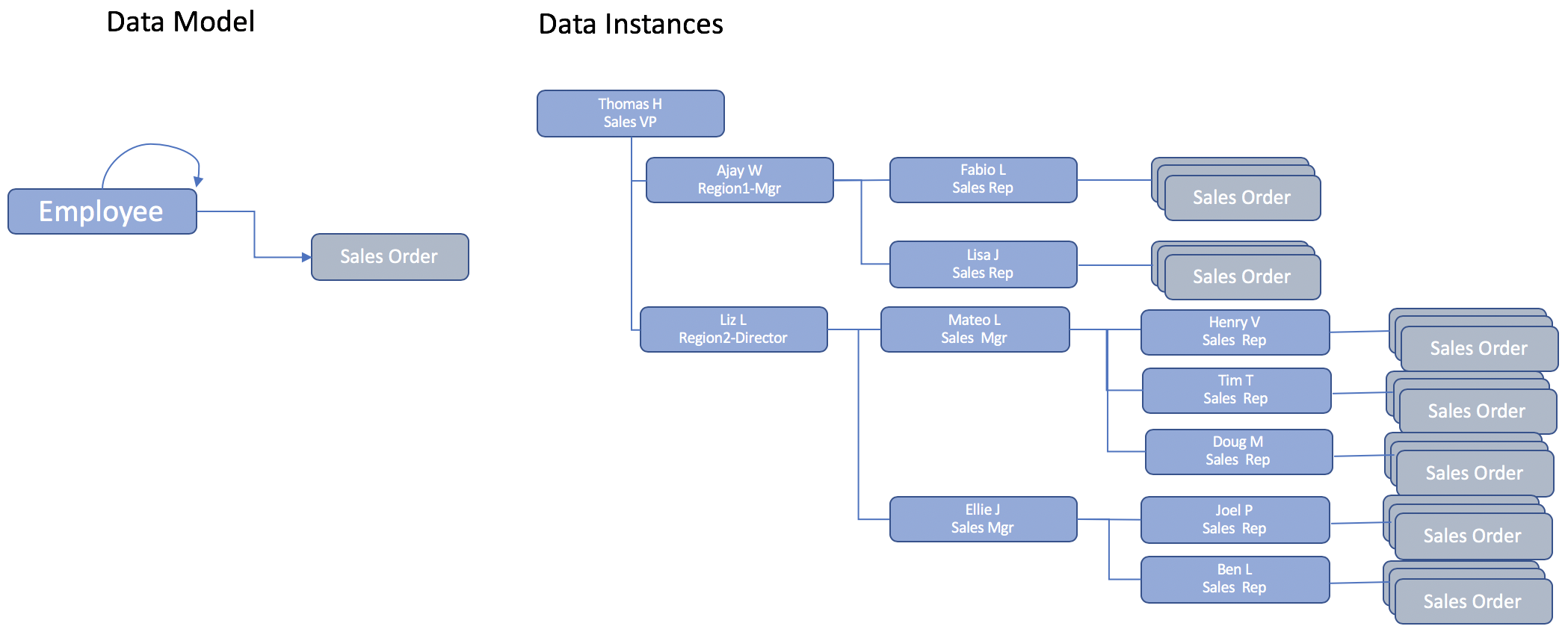
Embora o modelo de dados seja relativamente simples. A natureza hierárquica da organização de vendas sugere uma estrutura dinâmica inerente na hierarquia de relatórios. AjayW, que lidera o território da Região 1, também gerencia diretamente os membros da equipe de vendas. Por outro lado, na Região2, Liz L gerencia dois gerentes, que, por sua vez, gerenciam a equipe de vendas. Isso é típico na maioria das hierarquias de dados de aplicativos.
Abordagem RDMBS
Para consultar dados hierárquicos, os RDBMS mais estabelecidos, como Oracle e SQLSever, fornecem a construção CONNECT BY / START WITH para permitir que uma única consulta percorra recursivamente a estrutura hierárquica de funcionários.
|
1 2 3 4 5 6 7 8 |
Query: Sales orders generated by members who report up to ThomasH-Sales VP</strong></span> SELECT e.EmpID, e.Name, e.ManagerID, sum(o.orderVal) FROM employee e INNER JOIN sales_order o ON o.EmpID = o.EmpId START WITH EmpID = 101 CONNECT BY PRIOR EmpID = ManagerID GROUP BY e.EmpID, e.Name, e.ManagerID; |
Embora a consulta acima possa parecer simples, é difícil melhorar o desempenho da consulta com índices devido à natureza recursiva da implementação do CONNECT BY. Por esse motivo, essa técnica não é popular no desenvolvimento de aplicativos para sistemas com grande volume de dados. Em vez disso, os aplicativos corporativos dependem de uma estrutura de objeto pré-reformulada para obter um desempenho de consulta mais previsível. A técnica de hierarquia achatada é descrita na seção N1QL do Couchbase abaixo.
Couchbase N1QL
Para obter o melhor desempenho de consulta, os aplicativos N1QL devem usar a estrutura de hierarquia achatada. A abordagem oferece um desempenho mais previsível, além de aproveitar melhor a GSI do Couchbase. O diagrama abaixo mostra um exemplo da transformação de achatamento de uma estrutura hierárquica de autorreferência, como o objeto employee. Também incluí um trecho de código python abaixo que você pode usar para achatar a estrutura hierárquica. A estrutura achatar_hierarquia usa um objeto JSON hierárquico de autorreferência e gera dois novos objetos no mesmo espaço de chave, mas com valores de tipo diferentes
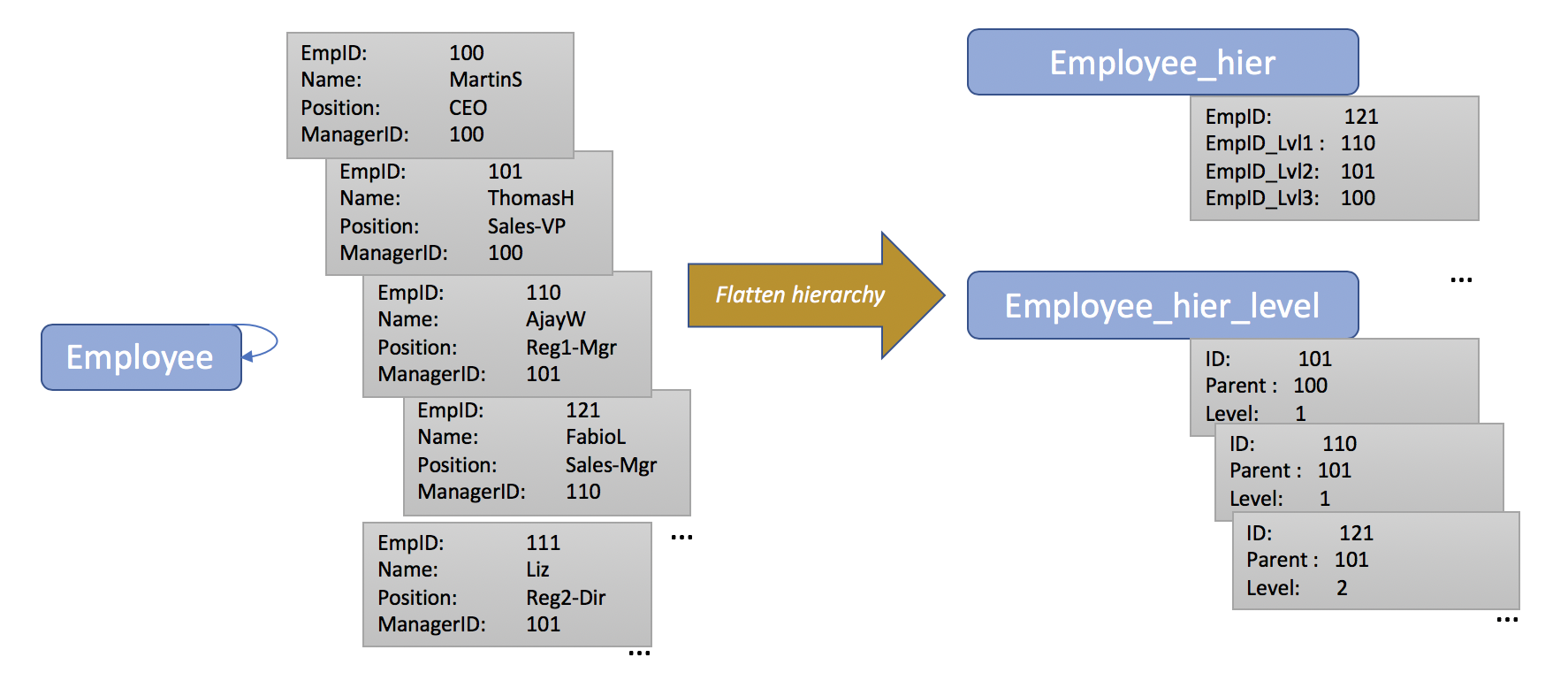
- O camada_objeto A estrutura funciona com consultas de BI agregadas, em que os resultados da consulta podem ser acumulados para cada nível.
- O nível_do_objeto fornece o mesmo resultado que a cláusula CONNECT BY/START WITH, que retorna todos os objetos filhos de um determinado nó. Esse é o objeto que usaremos em nossa consulta N1QL para fornecer a solução da consulta.
|
1 2 3 4 5 6 7 8 9 10 |
N1QL Query: Sales orders generated by members who report up to ThomasH-Sales VP SELECT e.id,sum(a.value) FROM crm a INNER JOIN ( SELECT uhl.id FROM crm uhl WHERE uhl.type ='_employee_hier_level' AND uhl.parent='101') e USE HASH(probe) ON a.owner = e.id WHERE a.type='sales_order' GROUP BY e.id |
Índice GS recomendado:
|
1 |
CREATE INDEX `crm_employee_hier_level` ON `crm`(`parent`) WHERE (`type` = "_employee_hier_level") |
Observações:
- A consulta principal recupera todos os pedidos de vendas no
crmbalde com valor de tipo = 'salesorder' - A consulta executa um HASH JOIN com outra consulta (recurso N1QL 6.5) que recupera todos os IDs de funcionários que se reportam ao user101, ou seja, ThomasH-SalesVP
- Os índices de cobertura adicionais também podem melhorar o desempenho da consulta
- A consulta usa o N1QL 6.5 ANSI JOIN Support for Expression and Subquery Term
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# Python code to flatten a JSON document in Couchbase bucket from couchbase.cluster import Cluster from couchbase.cluster import PasswordAuthenticator from couchbase.exceptions import NotFoundError from couchbase.bucket import Bucket from couchbase.n1ql import N1QLQuery def flatten_hierarchy(cb,bucketname,src_doc_type,num_hier_level,node_id_col, parent_id_col): # Example: flatten_hierarchy(cb,args.bucket,'user',4,'id','managerid') # cb - couchbase bucket handle # bucketname - name of the bucket for the source and target documents # src_doc_type - the type value of the source document # num_hier_level - specifies the number of levels that are needed. Should be the max depth of the hierarchy # node_id - the field name in the document for the key node id # parent_node_id - the parent field # gen_doc_type = '_'+src_doc_type+'_hier' if (num_hier_level > 1): qstr_ins = 'INSERT into '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "type":"'+gen_doc_type+'"' for i in range(1,num_hier_level+1): qstr_sel += ',"id'+str(i)+'":l'+str(i)+'.'+node_id_col qstr_sel += '} ndoc' qstr_sel_one = ' SELECT '+node_id_col+','+parent_id_col+' FROM '+bucketname+' WHERE type="'+src_doc_type+'"' for i in range(1,num_hier_level+1): if (i==1): qstr_sel += ' FROM ('+qstr_sel_one+') l'+str(i) else: qstr_sel += ' LEFT OUTER JOIN ('+qstr_sel_one qstr_sel += ') l'+str(i)+' ON l'+str(i-1)+'.'+parent_id_col+' = l'+str(i)+'.'+node_id_col try: #q = N1QLQuery(qstring) rows = cb.n1ql_query(qstr_ins+qstr_sel).execute() except Exception as e: print("query error",e) # generate connect by if (num_hier_level > 1): qstr_ins = 'INSERT into '+bucketname+' (KEY UUID(), VALUE ndoc) ' qstr_sel = 'SELECT { "id":ll.child,"parent":ll.parent,"level":ll.level ,"type":"'+gen_doc_type+'_level" } ndoc FROM (' for i in range(1,num_hier_level): if (i>1): qstr_sel += 'UNION ALL ' qstr_sel += 'SELECT id'+str(i+1)+' parent, id1 child,'+str(i)+' level FROM '+bucketname+' WHERE type="'+gen_doc_type+'" and id'+str(i+1)+' IS NOT NULL ' qstr_sel += ') ll' try: rows = cb.n1ql_query(qstr_ins+qstr_sel).execute() except Exception as e: print("query error",e) return |
Recursos
- Baixar: Faça o download do Couchbase Server 6.5
- Documentação: Couchbase Server 6.5 O que há de novo
- Todos os blogs 6.5
Gostaríamos muito de saber se você gostou dos recursos da versão 6.5 e como ela beneficiará sua empresa no futuro. Compartilhe seu feedback por meio dos comentários ou na seção fórum.
A consulta N1QL com INNER JOIN não funciona mais no CB6 conforme escrito.
[
{
"code": 3000,
"msg": "ANSI JOIN deve ser feito em um espaço de chave. - at where \n Erro ao analisar: erro de tempo de execução: endereço de memória inválido ou desreferência de ponteiro nulo - at where",
"query_from_user": "SELECT uhl.id FROM test uhl \r\nINNER JOIN (SELECT e.id,sum(a.
valor)\r\nFROM test a\r\n WHERE a.type='sales_order' ) e ON a.owner = e.id\r\nwhere uhl.type ='_employee_hier_level'\r\n AND uhl.parent='101'\r\nGROUP BY e.id"}
]
Além disso, a palavra-chave
valorprecisa sercitadoou erro de sintaxe. Algo comoSELECT e.id,sum(a.
valor), (SELECT uhl.id FROM test uhl WHERE uhl.type ='_employee_hier_level'AND uhl.parent='101′) e
DE teste a
WHERE a.type='sales_order' and a.owner = e.id
GROUP BY e.id
funciona, mas não tenho certeza sobre o USE HASH...
A consulta usa um novo recurso do N1QL 6.5 - Suporte ANSI JOIN para Expression Term e Subquery Term. A versão 6.5 está planejada para entrar em beta no final de maio. Se estiver interessado em uma versão inicial para experimentar, entre em contato comigo. Também estou procurando uma maneira de disponibilizar o conjunto de dados.
Obrigado,
-binh
Sugerir alguns dados JSON de amostra também seria bom
Bem, o Oracle ATP e o MS SQL Server também oferecem uma função de hierarquia e um tipo de dados de hierarquia especial. Você poderia esclarecer as diferenças em relação ao CouchBase? O ANSI SQL e/ou o CouchBase adicionam essas palavras-chave do SQL: "CONNECT BY" e "LEVEL"? TIA.
Oi CM27,
A consulta do Couchbase não é compatível com a palavra-chave "CONNECT BY". O recurso de passagem de relacionamento está em nosso plano. Na mesma observação, o CONNECT BY é um recurso específico do Oracle, enquanto o CTE recursivo é a abordagem ANSI para consulta de relacionamento.
-binh