Nesta série de postagens do blog, apresentarei as considerações sobre a mudança para um banco de dados de documentos quando você tem um histórico relacional. Especificamente, o Microsoft SQL Server em comparação com o Servidor Couchbase.
Em três partes, abordarei o assunto:
- Modelagem de dados (esta postagem do blog)
- Os dados em si
- Aplicativos que usam os dados
O objetivo é estabelecer algumas diretrizes gerais que podem ser aplicadas ao planejamento e ao design do seu aplicativo.
Se você quiser acompanhar, criei um aplicativo que demonstra o Couchbase e o SQL Server lado a lado. Obtenha o código-fonte no GitHube certifique-se de Faça o download de uma prévia para desenvolvedores do Couchbase Server.
Por que eu faria isso?
Antes de começarmos, gostaria de falar um pouco sobre a motivação. Há três motivos principais pelos quais alguém pode considerar o uso de um armazenamento de dados de documentos em vez de (ou além de) um banco de dados relacional. Sua motivação pode ser uma ou todas as três:
- Velocidade: O Couchbase Server usa um arquitetura memory-first que pode proporcionar um grande aumento de velocidade em comparação com um banco de dados relacional
- Escalabilidade: O Couchbase Server é um banco de dados distribuídoque permite que você aumente (e diminua) a capacidade simplesmente acumulando hardware de commodity. Os recursos incorporados do Couchbase, como auto-sharding, replicação e balanceamento de carga, tornam o dimensionamento muito mais suave e fácil do que os bancos de dados relacionais.
- Flexibilidade: Alguns dados se encaixam perfeitamente em um modelo relacional, mas alguns dados podem se beneficiar do modelo relacional. flexibilidade do uso de JSON. Ao contrário do SQL Server, a manutenção do esquema não é mais um problema. Com o JSON: o esquema se dobra conforme sua necessidade.
Por esses e outros motivos, A Gannett mudou do SQL Server para o Couchbase Server. Se estiver pensando em fazer isso, definitivamente Confira a apresentação completa da Gannett.
[youtube https://www.youtube.com/watch?v=mor2p0UqZ14&w=560&h=315]
Deve-se observar que os bancos de dados de documentos e os bancos de dados relacionais podem ser complementares. Seu aplicativo pode ser melhor atendido por um, por outro ou por uma combinação de ambos. Em muitos casos, simplesmente não é possível remover completamente os bancos de dados relacionais do seu projeto, mas um banco de dados de documentos como o Couchbase Server ainda pode trazer os benefícios acima para o seu software. O restante desta série do blog pressupõe que você tenha experiência com o SQL Server e esteja substituindo, complementando ou iniciando um novo projeto greenfield usando o Couchbase.
A facilidade ou a dificuldade de fazer a transição de um aplicativo existente varia muito com base em vários fatores. Em alguns casos, pode ser extremamente fácil; em outros, será demorado e difícil; em alguns casos (em número cada vez menor), pode nem ser uma boa ideia.
Entendendo as diferenças
A primeira etapa é entender como os dados são modelados em um banco de dados de documentos. Em um banco de dados relacional, os dados são normalmente armazenados em uma tabela e recebem uma estrutura com chaves primárias e estrangeiras. Como um exemplo simples, vamos considerar um banco de dados relacional para um site que tenha um carrinho de compras e recursos de mídia social. (Neste exemplo, esses recursos não estão relacionados para manter as coisas simples).
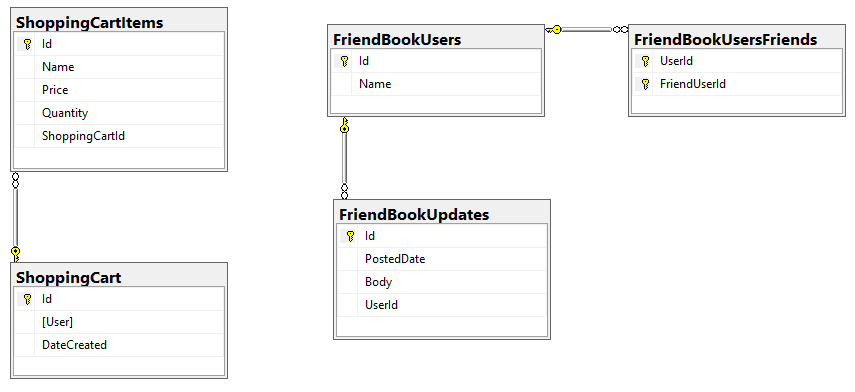
Em um banco de dados de documentos, os dados são armazenados como chaves e valores. Um bucket do Couchbase contém documentos; cada documento tem uma chave exclusiva e um valor JSON. Não há chaves estrangeiras (ou, mais precisamente, não há restrições de chave estrangeira).
Aqui está uma comparação de alto nível dos recursos/nomeação do SQL Server em relação ao Couchbase:
| SQL Server | Servidor Couchbase |
|---|---|
|
Servidor |
Aglomerado |
|
Banco de dados |
Balde |
|
Linha(s) da(s) tabela(s) |
Documento |
|
Coluna |
Chave/valor JSON |
|
Chave primária |
Chave do documento |
Essas comparações são um ponto de partida metafórico. Olhando para essa tabela, pode ser tentador adotar uma abordagem simplista. "Tenho 5 tabelas, portanto, vou criar 5 tipos diferentes de documentos, com um documento por linha." Isso é o equivalente a traduzir literalmente um idioma escrito. Essa abordagem pode funcionar às vezes, mas não leva em conta todo o poder de um banco de dados de documentos que usa JSON. Assim como uma tradução literal de um idioma escrito não leva em conta o contexto cultural, as expressões idiomáticas e o contexto histórico.
Devido à flexibilidade do JSON, os dados em um banco de dados de documentos podem ser estruturados mais como um objeto de domínio em seu aplicativo. Portanto, você não tem uma incompatibilidade de impedância que geralmente é resolvida por ferramentas de OR/M como Entity Framework e NHibernate.
Há duas abordagens principais que você pode usar ao modelar dados no Couchbase e que examinaremos mais detalhadamente:
- Desnormalização - Em vez de dividir os dados entre tabelas usando chaves estrangeiras, agrupe os conceitos em um único documento.
- Referencial - Os conceitos recebem seus próprios documentos, mas fazem referência a outros documentos usando a chave do documento.
Exemplo de desnormalização
Vamos considerar a entidade "carrinho de compras".
Para representar isso em um banco de dados relacional, provavelmente seriam necessárias duas tabelas: uma tabela ShoppingCart e uma tabela ShoppingCartItem com uma chave estrangeira para uma linha no ShoppingCart.
Ao criar o modelo para um banco de dados de documentos, é preciso decidir se continuaremos a modelá-lo como duas entidades separadas (por exemplo, um documento de carrinho de compras e os documentos correspondentes de item de carrinho de compras) ou se "desnormalizaremos" e combinaremos uma linha de ShoppingCart e linha(s) de ShoppingCartItem em um único documento para representar um carrinho de compras.
No Couchbase, usando uma estratégia de desnormalização, um carrinho de compras e os itens nele contidos seriam representados por um único documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "user": "mgroves", "dateCreated": "2017-02-02T15:28:11.0208157-05:00", "items": [ { "name": "BB-8 Sphero", "price": 80.18, "quantity": 1 }, { "name": "Shopkins Season 5", "price": 59.99, "quantity": 2 } ], "type": "ShoppingCart" } |
Observe que o relacionamento entre os itens e o carrinho de compras agora está implícito no fato de estarem contidos no mesmo documento. Não há mais necessidade de um ID nos itens para representar um relacionamento.
Em C#, você provavelmente definiria ShoppingCart e Item para modelar esses dados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class ShoppingCart { public Guid Id { get; set; } public string User { get; set; } public DateTime DateCreated { get; set; } public List Items { get; set; } } public class Item { public Guid Id { get; set; } // necessary for SQL Server, not for Couchbase public string Name { get; set; } public decimal Price { get; set; } public int Quantity { get; set; } } |
Essas classes ainda fariam sentido com o Couchbase, portanto, você pode reutilizá-las ou projetá-las dessa forma. Porém, com um banco de dados relacional, esse design não corresponde diretamente.
Daí a necessidade de OR/Ms como NHibernate ou Entity Framework. A maneira como o modelo acima pode ser mapeado para um banco de dados relacional é representada no Entity Framework* da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public class ShoppingCartMap : EntityTypeConfiguration { public ShoppingCartMap() { this.HasKey(m => m.Id); this.ToTable("ShoppingCart"); this.Property(m => m.User); this.Property(m => m.DateCreated); this.HasMany(m => m.Items) .WithOptional() .HasForeignKey(m => m.ShoppingCartId); } } public class ShoppingCartItemMap : EntityTypeConfiguration { public ShoppingCartItemMap() { this.HasKey(m => m.Id); this.ToTable("ShoppingCartItems"); this.Property(m => m.Name); this.Property(m => m.Price); this.Property(m => m.Quantity); } } |
*Outras OR/Ms terão mapeamentos semelhantes
Com base nesses mapeamentos e em uma análise dos casos de uso, eu poderia decidir que ele seria modelado como um único documento no Couchbase. ShoppingCartItemMap só existe para que o OR/M saiba como preencher o Itens propriedade em ShoppingCart. Além disso, é improvável que o aplicativo faça leituras do carrinho de compras sem também necessidade de ler os itens.
Em uma postagem posterior, as OR/Ms serão discutidas mais detalhadamente, mas, por enquanto, posso dizer que a ShoppingCartMap e ShoppingCartItemMap não são necessárias ao usar o Couchbase, e as classes Id campo de Item não é necessário. De fato, o SDK do Couchbase .NET pode preencher diretamente um ShoppingCart sem um OR/M em uma única linha de código:
|
1 2 3 4 |
public ShoppingCart GetCartById(Guid id) { return _bucket.Get(id.ToString()).Value; } |
Isso não quer dizer que o uso do Couchbase sempre resultará em códigos mais curtos e fáceis de ler. Mas, para determinados casos de uso, isso pode ter um impacto definitivo.
Exemplo de referência
Nem sempre é possível ou ideal desnormalizar relações como a ShoppingCart exemplo. Em muitos casos, um documento precisará fazer referência a outro documento. Dependendo de como seu aplicativo espera fazer leituras e gravações, talvez você queira manter seu modelo em documentos separados usando referências.
Vamos dar uma olhada em um exemplo em que a referência pode ser a melhor abordagem. Suponha que seu aplicativo tenha alguns elementos de mídia social. Os usuários podem ter amigos e podem publicar atualizações de texto.
Uma maneira de modelar isso:
- Usuários como documentos individuais
- Atualizações como documentos individuais que fazem referência a um usuário
- Amigos como uma matriz de chaves em um documento do usuário
Com dois usuários e duas atualizações, teríamos 4 documentos no Couchbase com a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
[ // Key: "7fc5503f-2092-4bac-8c33-65ef5b388f4b" { "friends": [ "c5f05561-9fbf-4ab0-b68f-e392267c0703" ], "name": "Matt Groves", "type": "User" }, // Key: "c5f05561-9fbf-4ab0-b68f-e392267c0703" { "friends": [ ], "name": "Nic Raboy", "type": "User" }, // Key: "5262cf62-eb10-4fdd-87ca-716321405663" { "body": "Nostrum eligendi aspernatur enim repellat culpa.", "postedDate": "2017-02-02T16:19:45.2792288-05:00", "type": "Update", "user": "7fc5503f-2092-4bac-8c33-65ef5b388f4b" }, // Key: "8d710b83-a830-4267-991e-4654671eb14f" { "body": "Autem occaecati quam vel. In aspernatur dolorum.", "postedDate": "2017-02-02T16:19:48.7812386-05:00", "type": "Update", "user": "c5f05561-9fbf-4ab0-b68f-e392267c0703" } ] |
Decidi modelar "amigos" como um relacionamento unidirecional (como o Twitter) para este exemplo, e é por isso que Matt Groves tem Nic Raboy como amigo, mas não vice-versa. (Não dê muita importância a isso, Nic :).
A maneira de modelar isso no C# poderia ser:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public class FriendbookUser { public Guid Id { get; set; } public string Name { get; set; } public virtual List Friends { get; set; } } public class Update { public Guid Id { get; set; } public DateTime PostedDate { get; set; } public string Body { get; set; } public virtual FriendbookUser User { get; set; } public Guid UserId { get; set; } } |
O Atualização para Usuário do Friendbook pode ser modelado como um Guia ou como outro Usuário do Friendbook objeto. Esse é um detalhe de implementação. Você pode preferir um, o outro ou ambos, dependendo das necessidades do seu aplicativo e/ou de como o seu OR/M funciona. Em ambos os casos, o modelo subjacente é o mesmo.
Aqui está o mapeamento que usei para essas classes no Entity Framework. Sua milhagem pode variar, dependendo de como você usa o EF ou outras ferramentas de OR/M. Concentre-se no modelo subjacente e não nos detalhes da ferramenta de mapeamento de OR/M.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
public class UpdateMap : EntityTypeConfiguration { public UpdateMap() { this.HasKey(m => m.Id); this.ToTable("FriendBookUpdates"); this.Property(m => m.Body); this.Property(m => m.PostedDate); this.HasRequired(m => m.User) .WithMany() .HasForeignKey(m => m.UserId); } } public class FriendbookUserMap : EntityTypeConfiguration { public FriendbookUserMap() { this.HasKey(m => m.Id); this.ToTable("FriendBookUsers"); this.Property(m => m.Name); this.HasMany(t => t.Friends) .WithMany() .Map(m => { m.MapLeftKey("UserId"); m.MapRightKey("FriendUserId"); m.ToTable("FriendBookUsersFriends"); }); } } |
Se, em vez de armazenar essas entidades como documentos separados, aplicássemos a mesma desnormalização do exemplo do carrinho de compras e tentássemos armazenar um usuário e as atualizações em um único documento, teríamos alguns problemas.
- Duplicação de amigosCada usuário armazenaria os detalhes de seus amigos. Isso não é sustentável, porque agora as informações de um usuário seriam armazenadas em vários locais, em vez de ter uma única fonte de verdade (ao contrário do carrinho de compras, em que ter o mesmo item em mais de um carrinho de compras provavelmente não faz sentido em termos de domínio). Isso pode ser aceitável ao usar o Couchbase como cache, mas não como armazenamento de dados primário.
- Tamanho das atualizações: Durante um período de uso regular, um usuário individual pode publicar centenas ou milhares de atualizações. Isso pode resultar em um documento muito grande que pode tornar as operações de E/S mais lentas. Isso pode ser atenuado com a função API de subdocumentomas observe também que o Couchbase tem um limite máximo de 20 MB por documento.
Observação: Há um problema de N+1 aqui também (amigos de amigos, etc.), mas não vou perder tempo abordando isso. É um problema que não é exclusivo de nenhum dos bancos de dados.
Além disso, pode não ser que, quando o aplicativo lê ou grava um usuário, ele precise ler ou gravar amigos e atualizações. E, ao escrever uma atualização, é pouco provável que o aplicativo precise atualizar um usuário. Como essas entidades muitas vezes podem ser lidas/gravadas por conta própria, isso indica que elas precisam ser modeladas como documentos separados.
Observe a matriz no Amigos no documento do usuário e o valor no campo Usuário no documento de atualização. Esses valores podem ser usados para recuperar os documentos associados. Mais adiante neste post, discutirei como fazer isso com operações de chave/valor e como fazer isso com N1QL.
Em resumo, há duas maneiras de modelar dados em um banco de dados de documentos. O exemplo do carrinho de compras usou objetos aninhadosenquanto o exemplo de mídia social usou documentos separados. Nesses exemplos, a escolha foi relativamente simples. Quando estiver tomando suas próprias decisões de modelagem, aqui está uma folha de dicas útil:
| Se ... | Então, considere... |
|---|---|
|
O relacionamento é de 1 para 1 ou de 1 para muitos |
Objetos aninhados |
|
O relacionamento é de muitos para 1 ou de muitos para muitos |
Documentos separados |
|
As leituras de dados são, em sua maioria, campos pai |
Documento separado |
|
As leituras de dados são, em sua maioria, campos pai + filho |
Objetos aninhados |
|
As leituras de dados são, em sua maioria, parentais ou filho (não ambos) |
Documentos separados |
|
As gravações de dados são, em sua maioria, pai e criança (ambos) |
Objetos aninhados |
Operações de chave/valor
Para obter documento(s) no Couchbase, a maneira mais simples e rápida é solicitá-los por chave. Quando você tiver uma das chaves Usuário do Friendbook documentos acima, você pode executar outra operação para obter os documentos associados. Por exemplo, eu poderia pedir ao Couchbase que me fornecesse os documentos das chaves 2, 3 e 1031 (como uma operação em lote). Isso me forneceria os documentos de cada amigo. Em seguida, posso repetir isso para Atualizaçõese assim por diante.
A vantagem disso é a velocidade: as operações de chave/valor são muito rápidas no Couchbase, e você provavelmente obterá valores diretamente da RAM.
A desvantagem é que isso envolve pelo menos duas operações (obter o documento FriendbookUser e, em seguida, obter as atualizações). Portanto, isso pode envolver alguma codificação extra. Também pode exigir que você pense com mais cuidado sobre como construir chaves de documentos (mais sobre isso adiante).
N1QL
No Couchbase, você pode escrever consultas usando N1QL, que é SQL para JSON. Isso inclui o JUNTAR palavra-chave. Isso me permite, por exemplo, escrever uma consulta para obter as 10 atualizações mais recentes e os usuários que correspondem a elas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public List GetTenLatestUpdates() { var n1ql = @"SELECT up.body, up.postedDate, { 'id': META(u).id, u.name} AS `user` FROM `sqltocb` up JOIN `sqltocb` u ON KEYS up.`user` WHERE up.type = 'Update' ORDER BY STR_TO_MILLIS(up.postedDate) DESC LIMIT 10;"; var query = QueryRequest.Create(n1ql); query.ScanConsistency(ScanConsistency.RequestPlus); var result = _bucket.Query(query); return result.Rows; } |
O resultado dessa consulta seria:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[ { "body": "Autem occaecati quam vel. In aspernatur dolorum.", "postedDate": "2017-02-02T16:19:48.7812386-05:00", "user": { "id": "c5f05561-9fbf-4ab0-b68f-e392267c0703", "name": "Bob Johnson" } }, { "body": "Nostrum eligendi aspernatur enim repellat culpa eligendi maiores et.", "postedDate": "2017-02-02T16:19:45.2792288-05:00", "user": { "id": "7fc5503f-2092-4bac-8c33-65ef5b388f4b", "name": "Steve Oberbrunner" } }, // ... etc ... ] |
O N1QL permite que você tenha grande flexibilidade na recuperação de dados. Não preciso ficar restrito apenas ao uso de chaves. Também é fácil de aprender, pois é um superconjunto de SQL com o qual os usuários do SQL Server se sentirão confortáveis rapidamente. Entretanto, a desvantagem aqui é que a indexação é importante. Ainda mais do que a indexação do SQL Server. Se você fosse escrever uma consulta no banco de dados Nome por exemplo, você deve ter um índice como:
|
1 |
CREATE INDEX IX_Name ON `SocialMedia` (Name) USING GSI; |
Caso contrário, a consulta não será executada (se você não tiver indexação) ou não terá desempenho (se você tiver criado apenas um índice primário).
Há prós e contras na decisão de usar ou não as referências. Os valores em amigos e usuário são semelhantes às chaves estrangeiras, pois fazem referência a outro documento. Mas não há imposição de valores pelo Couchbase. O gerenciamento dessas chaves deve ser feito adequadamente pelo aplicativo. Além disso, embora o Couchbase forneça transações ACID para operações com um único documento, não há nenhuma transação ACID para vários documentos disponível.
Há maneiras de lidar com essas ressalvas em sua camada de aplicativo que serão discutidas em postagens posteriores do blog nesta série, portanto, fique atento!
Principais diferenciações de design e documentos
Em bancos de dados relacionais, as linhas de dados (normalmente, nem sempre) correspondem a uma chave primária, que geralmente é um número inteiro ou um Guid e, às vezes, uma chave composta. Essas chaves não têm necessariamente nenhum significado: elas são usadas apenas para identificar uma linha em uma tabela. Por exemplo, duas linhas de dados em duas tabelas diferentes podem ter a mesma chave (um valor inteiro de 123, por exemplo), mas isso não significa necessariamente que os dados estejam relacionados. Isso ocorre porque o esquema imposto pelos bancos de dados relacionais geralmente transmite significado por si só (por exemplo, um nome de tabela).
Em bancos de dados de documentos como o Couchbase, não há nada equivalente a uma tabela, por si só. Cada documento em um bucket deve ter uma chave exclusiva. Mas um bucket pode ter uma variedade de documentos. Portanto, muitas vezes é aconselhável criar uma maneira de diferenciar os documentos em um bucket.
Chaves significativas
Por exemplo, é perfeitamente possível ter um Usuário do Friendbook com uma chave de 123e um Atualização com uma chave de 456. No entanto, talvez seja aconselhável adicionar mais algumas informações semânticas à chave. Em vez de 123use uma chave de FriendbookUser::123. Os benefícios de colocar informações semânticas em sua chave incluem:
- Legibilidade: Em uma rápida olhada, você pode saber para que serve um documento.
- Capacidade de referência: Se você tiver um
FriendbookUser::123então você poderia ter outro documento com uma chaveFriendbookUser::123::Atualizaçõesque tem uma associação implícita.
Se você planeja usar N1QL, talvez não precise que as chaves sejam tão significativas do ponto de vista semântico. Em termos de desempenho, quanto mais curta for a chave, mais delas poderão ser armazenadas na RAM. Portanto, só use esse padrão se estiver planejando fazer uso intenso de operações de chave/valor em vez de consultas N1QL.
Campos de discriminação
Ao usar o N1QL, outra tática que pode ser usada além ou em vez de chaves significativas é adicionar campo(s) a um documento que seja(m) usado(s) para diferenciar o documento. Isso geralmente é implementado como um tipo em um documento.
|
1 2 3 4 5 6 |
{ "address" : "1800 Brown Rd", "city" : "Groveport", "state" : "OH", "type" : "address" } |
Não há nada de mágico no tipo campo. Não é uma palavra reservada em um documento e não é tratada de forma especial pelo Couchbase Server. Ele poderia facilmente ser chamado de documentType, theTypeetc. Mas ele pode ser útil em seu aplicativo ao usar o N1QL para consultar documentos de um determinado tipo.
|
1 2 3 |
SELECT d.* FROM `default` d WHERE d.type = 'address' |
Você pode até dar um passo adiante e adicionar um objeto incorporado aos seus documentos para atuar como uma espécie de "metadados" falsos:
|
1 2 3 4 5 6 7 8 9 10 |
{ "address" : "1800 Brown Rd", "city" : "Groveport", "state" : "OH", "documentInfo" : { "type" : "address", "lastUpdated" : "1/29/2017 1:31:10 PM", "lastUpdatedBy" : "mgroves" } } |
Isso pode ser um exagero para alguns aplicativos. É semelhante a um padrão que vi em bancos de dados relacionais: uma tabela "raiz" para simular a herança em um banco de dados relacional, ou talvez os mesmos campos anexados a todas as tabelas.
Conclusão da parte 1
Esta postagem do blog abordou a modelagem de dados usando desnormalização, modelagem de dados usando referências, design de chaves e campos discriminados. A modelagem de dados em um banco de dados de documentos é um processo de pensamento, uma espécie de forma de arte, e não um processo mecânico. Não há uma receita de como modelar seus dados em um banco de dados de documentos: isso depende muito de como seu aplicativo interage com os dados.
Você pode obter o código-fonte de toda a série do blog no GitHub agoraque foi apresentado nesta postagem do blog. Se você tiver dúvidas sobre várias partes desse código, fique à vontade para deixar um comentário abaixo ou abrir um problema no GitHub.
Fique atento ao próximo blog da série, no qual serão discutidos dados e migração de dados.
Se você tiver alguma dúvida, deixe um comentário abaixo, entre em contato comigo no Twitterou use o Fóruns do Couchbase.
[...] Modelagem de dados [...]
[...] voltando à primeira postagem do blog sobre modelagem de dados, a necessidade de transações com vários documentos é frequentemente reduzida ou eliminada, em comparação com um sistema relacional [...]
[...] do SQL Server para o Couchbase - Parte 1 (modelagem de dados), Parte 2 (migração de dados), Parte 3 [...]
[...] a modelagem de dados JSON é algo que abordei na primeira parte da minha série "Mudando do SQL Server para o Couchbase". Desde aquela postagem no blog, chamou-me a atenção algumas novas ferramentas da Hackolade, que recentemente [...]