Observação: esta postagem do blog é uma revisão do artigo de Matthew Revell Mudança do MongoDB para o Couchbase Server
Este é um guia focado no desenvolvedor para mover o armazenamento de dados do seu aplicativo do MongoDB para o Servidor Couchbase. Se você estiver interessado em migrar de um banco de dados relacional para o Couchbase, comece com o artigo de Laurent guia para fazer a mudança do PostgreSQLe estarei trabalhando em uma postagem sobre migração para o SQL Server no futuro.
Embora este guia não cubra todos os casos, ele oferece dicas sobre o que deve ser considerado ao planejar a migração. Se você estiver interessado em aprender sobre por que você faria essa migração, ou aprender sobre um cliente do Couchbase que tenha feito essa migração, confira o Viber.
Se você usa atualmente o MongoDB e está usando o Mongoose ODM com o Node, aqui está um vídeo da conferência Connect 2016 sobre migração do MongoDB com Ottoman.js.
Versões
Este guia foi escrito para o Couchbase Server 4.5 e o MongoDB 3.4.
Principais diferenças
O Couchbase Server e o MongoDB são armazenamentos de documentos que podem operar em um ou vários servidores. No entanto, eles abordam as coisas de maneiras significativamente diferentes.
Ao iniciar sua migração do MongoDB para o Couchbase Server, você precisará considerar as seguintes diferenças:
|
Servidor Couchbase |
MongoDB |
|
|
Modelos de dados |
Documento, valor-chave |
Documento |
|
Consulta |
N1QL (SQL para JSON), visualizações de mapa/redução, valor-chave |
Consulta ad-hoc, agregação de mapa/redução |
|
Concorrência |
Bloqueio otimista e pessimista |
Bloqueio otimista e pessimista (com WiredTiger) |
|
Modelo de escala |
Mestre-mestre distribuído |
Mestre-escravo com conjuntos de réplicas |
Modelo de dados
O Couchbase Server é um armazenamento de documentos e um armazenamento de valores-chave.
Tudo começa com chave-valor, pois cada documento tem uma chave que você pode usar para obter e definir o conteúdo do documento. No entanto, você pode usar o Couchbase Server como um banco de dados de documentos, indexando e consultando o conteúdo dos documentos. Observação: se você estiver interessado em usar o Couchbase como um simples armazenamento de valores-chave, leia minha postagem no blog sobre Uso do Couchbase para armazenar dados não JSON.
Diferenças entre BSON e JSON
É provável que seu aplicativo armazene documentos do tipo JSON no MongoDB, portanto, começaremos por ele.
O MongoDB armazena dados no formato BSON, que é um formato binário semelhante ao JSON. A principal diferença ao migrar é que o BSON registra informações adicionais de tipo.
Quando você exporta dados do MongoDB usando uma ferramenta como mongoexportaçãoa ferramenta produzirá JSON que preserva essas informações de tipo em um formato chamado Extended JSON.
Vamos dar uma olhada em um exemplo de JSON estendido:
|
1 2 3 4 5 |
{ "myInt": { "$numberLong": "123" } } |
Como você pode ver, o JSON estendido ainda é um JSON válido. Isso significa que você pode armazenar, indexar, consultar e recuperá-lo usando o Couchbase Server. No entanto, você precisará manter essas informações adicionais de tipo (no exemplo acima, o JSON estendido está armazenando um número inteiro longo como uma cadeia de caracteres, por exemplo) na camada do aplicativo.
Como alternativa, você pode converter o JSON estendido em JSON padrão antes (ou depois) de importá-lo para o Couchbase Server. Com as consultas N1QL, isso deve ser relativamente simples, embora potencialmente tedioso. Aqui está um exemplo que converte o campo "myInt" acima em um campo de número JSON padrão:
|
1 2 3 |
ATUALIZAÇÃO `padrão` CONJUNTO myInt = TONUMBER(myInt.`$numberLong`) ONDE myInt.`$numberLong` IS NÃO FALTANDO |
O que resultaria em:
|
1 2 3 |
{ "myInt": 123 } |
Dados não JSON
Tanto o MongoDB quanto o Couchbase Server podem armazenar dados binários opacos.
Embora a representação interna dos dados binários seja muito diferente entre os dois, você pode continuar a armazenar no Couchbase Server os dados binários que vinha armazenando no MongoDB.
A principal diferença é que o Couchbase Server pode armazenar binários de até 20 MB, enquanto o MongoDB oferece uma camada de conveniência para dividir arquivos muito grandes em vários documentos.
Há fortes argumentos contra o armazenamento de binários grandes em seu banco de dados. Quando você tem muitos binários muito grandes, pode considerar o uso de um serviço de armazenamento de objetos dedicado para armazená-los e usar o Couchbase para manter os metadados desses binários.
Arquitetura
Fragmentação
O Couchbase Server fragmenta os dados e dimensiona horizontalmente, distribuindo automaticamente um espaço de hash entre os nós em um cluster.
Em seguida, ele usa a chave de seu documento para decidir em que parte do espaço de hash - e, portanto, em que nó do cluster - esse documento reside. Como desenvolvedor, isso é abstraído para você pelo SDK do cliente.
Com o MongoDB, você precisa escolher um método de fragmentação e uma chave de fragmentação. A chave de fragmento é um campo indexado dentro de seu documento que determina onde o documento reside no cluster.
A principal diferença aqui é que o Couchbase Server lida automaticamente com toda a fragmentação para você, enquanto o MongoDB lhe dá a opção de escolher o método de fragmentação e a chave de fragmentação. Se os seus aplicativos dependerem de uma distribuição específica de dados no cluster, será necessário ajustá-los para permitir a distribuição baseada em hash usada pelo Couchbase.
O sharding baseado em hash simplifica muito o dimensionamento em comparação com o MongoDB. Como desenvolvedor, você pode pensar que isso não lhe diz respeito e é um problema de operações. No entanto, isso significa que é mais fácil confiar no Couchbase Server caso o uso do seu software cresça.
Replicação e consistência
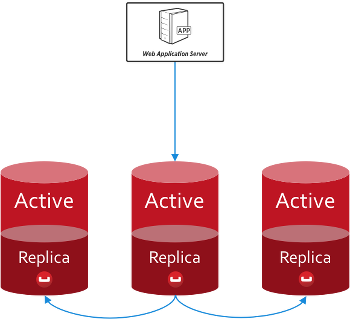
O Couchbase Server mantém uma única cópia ativa de cada documento e, em seguida, até três réplicas; você pode configurar o número de réplicas em um bucket ou por operação.
Isso significa que, durante a operação normal, você lida com a mesma cópia ativa sempre que escreve ou lê um documento. Como resultado, você não precisa lidar com versões conflitantes de documentos. As réplicas entram em ação somente quando a cópia ativa não está disponível.
Como desenvolvedor, a distribuição e a replicação de documentos são abstraídas para você. Você escreve, lê e consulta usando sua conexão com o bucket, e o SDK cuida exatamente de onde esses dados estão armazenados. Não há necessidade de levar em conta conjuntos de réplicas ou esquemas de sharding.
Se você conhece o Teorema CAPEntão você também sabe que favorecer a consistência afeta a disponibilidade. No caso de falha de um nó, seus documentos ativos ficarão indisponíveis por um curto período de tempo para permitir que o cluster promova as réplicas apropriadas ao status ativo. Em seu código, tudo o que você precisa fazer é tentar novamente uma operação que falhou.
Indexação
O Couchbase Server oferece dois tipos amplos de índice:
- GSI: índices secundários globais
- visualizações: geradas por consultas de redução de mapas. A diferença é mais do que um detalhe de implementação, pois você cria e gerencia os dois tipos de índice de forma diferente. Em geral, você usará os índices GSI para replicar os índices do MongoDB.
|
MongoDB |
Servidor Couchbase |
|
Campo único |
|
|
Índice composto |
|
|
Índice de várias chaves |
|
|
Índice geoespacial |
|
|
Índice de texto |
Tipos de nós
Quando você ultrapassa o limite de um servidor MongoDB, é necessário introduzir processos de roteador e servidores de configuração.
Com o Couchbase Server, essas duas funções são encontradas no SDK do cliente. Quando você se conecta ao cluster a partir do seu aplicativo, o SDK recebe um mapa de onde cada fragmento está localizado no cluster. O Couchbase Server atualiza automaticamente o mapa do cluster sempre que a forma do cluster muda. Cada solicitação acontece diretamente do servidor do aplicativo para o nó relevante do Couchbase.
Quando o cluster crescer, você poderá optar por executar nós especializados em dados, consultas e indexação. Leia mais sobre escalonamento multidimensional.
Tudo isso acontece de forma transparente para você, como desenvolvedor.
Baldes e coleções
Tanto o Couchbase Server quanto o MongoDB permitem que você divida seu conjunto de dados em grupos de documentos: O Couchbase tem buckets e o MongoDB tem coleções.
Enquanto as coleções do MongoDB têm um escopo equivalente ao das tabelas relacionais, os buckets do Couchbase Server talvez sejam mais equivalentes a um banco de dados relacional.
Essa distinção é importante porque, normalmente, você não quer mais do que dez buckets em um único cluster do Couchbase. Isso faz com que eles não sejam adequados como namespaces. Em vez disso, eles servem como uma maneira de compartilhar decisões de configuração e modelagem entre tipos semelhantes de documentos.
Isso tem duas consequências principais:
- Você precisa de outra maneira de atribuir nomes aos seus documentos
- Você precisa pensar em quando é apropriado criar um novo bucket.
Quando usar vários buckets
Primeiro, precisamos pensar em como você pode alocar recursos para os buckets. As duas grandes considerações são:
- RAM
- Visualizações e índices.
Ao criar um bucket, você aloca a ele uma parte da RAM de cada máquina. A RAM que você atribui a um bucket deve ser grande o suficiente para armazenar o conjunto de trabalho desses dados mais os poucos bytes de metadados associados a cada documento.
Isso significa que você pode alocar diferentes quantidades de RAM adequadamente para diferentes conjuntos de dados com base em como você os acessa.
Da mesma forma, as exibições e os índices do Couchbase são executados nos documentos dentro de um bucket, da mesma forma que uma consulta de redução de mapa do MongoDB é executada em uma única coleção.
Se você tiver alguns documentos que não precisam de indexação, porque você só os acessa por meio da chave deles, e tiver alguns grupos de documentos com velocidades diferentes, será prudente nunca executar indexadores no primeiro conjunto de dados e executar os indexadores com intervalos apropriados no restante.
Dividir nossos dados em diferentes compartimentos nos permite fazer bom uso da RAM e do tempo de CPU necessário para os indexadores.
Vejamos um exemplo de um aplicativo de comércio eletrônico: os dados que você armazenaria, seu perfil e como responderia a isso na configuração do seu bucket.
|
Tipo de dados |
Perfil de dados |
Perfil da caçamba |
|
Sessões |
Respostas rápidas, acesso a valores-chave, sessões simultâneas previsíveis |
RAM para atender ao número típico de sessões ao vivo, sem indexação |
|
Perfis de usuário |
Respostas rápidas enquanto os usuários estão ativos, os dados mudam lentamente |
RAM para atender aos perfis de usuário para o número típico de sessões ao vivo, indexação em |
|
Dados do pedido |
Leitura intensa após a criação inicial, vida útil curta |
RAM para atender a pedidos de um número típico de sessões ao vivo, indexação em |
|
Dados do produto |
Necessidade de respostas rápidas, leitura pesada |
RAM para caber todo o catálogo, indexação em |
É um pouco mais complicado do que decidir se a indexação está ativada ou desativada. Em vez disso, você escolhe os tipos de índice, e a velocidade das atualizações decide a frequência de execução dos indexadores. A combinação de dados de movimentação lenta e rápida pode ser ineficiente, pois os indexadores de um compartimento são executados em todos os documentos desse compartimento, inclusive os que não foram alterados.
Namespacing de documentos
Se não pudermos usar compartimentos como namespaces, como poderemos distinguir facilmente os diferentes tipos de documentos?
Você deve usar uma combinação de:
- Nomeação de chaves
- Usar um "tipo" em seu documento JSON.
Uso de prefixos e sufixos semânticos em seus nomes de chaves é uma maneira fácil de atribuir nomes aos seus documentos, especialmente quando você estiver usando o Couchbase para valores-chave.
A exigência de um tipo em seus esquemas de documentos fornece os dados necessários para criar consultas que se aplicam somente a determinados tipos de documentos.
Modelo de programação
Há três maneiras de trabalhar com o Couchbase Server:
- Acesso simples a valores-chave: consistência forte, respostas em menos de um milissegundo
- Visualizações: geradas por consultas de redução de mapas
- N1QL: Consultas semelhantes a SQL (com JOINs)
Vindo do MongoDB, você pode ficar tentado a traduzir todas as suas consultas do MongoDB para o N1QL. No entanto, vale a pena pensar sobre os méritos relativos de cada um e, em seguida, usar a combinação que atenda às suas necessidades.
Você pode ir muito longe com o acesso a valores-chave, por exemplo, usando índices secundários manuais.
Consulta
O Couchbase Server oferece N1QL. O N1QL é uma linguagem semelhante ao SQL e é bem diferente da consulta no MongoDB.
Vejamos um exemplo em que retornamos o nome dos funcionários do escritório de Mountain View que trabalharam lá por dois anos ou mais, ordenados por data de início:
|
1 2 3 4 5 6 |
SELECIONAR nome DE `hr` ONDE escritório='Mountain View' E tipo='funcionário' E DATA_DIFERENÇA_MILLIS(startDate, NOW_MILLIS) >= 63113904000 ORDEM BY startDate; |
Se você já trabalhou com SQL, o N1QL deve ser muito familiar para você. Você poderá traduzir suas consultas do MongoDB para N1QL com relativamente pouco esforço.
Antes de começar a reescrever suas consultas, você deve considerar uma grande vantagem que o N1QL oferece: você pode executar JOINs em todos os documentos. Vamos usar nossa consulta acima e também retornar o nome do gerente de cada pessoa.
|
1 2 3 4 5 6 7 |
SELECIONAR r.nome, s.nome AS gerente DE `hr` r JUNTAR `hr` s ON CHAVES r.gerente ONDE r.escritório='Mountain View' E r.tipo='funcionário' E DATA_DIFERENÇA_MILLIS(r.startDate, NOW_MILLIS) >= 63113904000 ORDEM BY r.startDate; |
Concorrência
No Couchbase Server, o bloqueio sempre ocorre no nível do documento e há dois tipos:
- Pessimista: nenhum outro ator pode escrever nesse documento até que ele seja liberado ou que o tempo limite seja atingido
- Otimista: use valores CAS (check-and-set) para verificar se o documento foi alterado desde a última vez que você o tocou e aja de acordo.
Bloqueio otimista pode ser mais eficiente, mas o bloqueio pessimista pode ser necessário às vezes. Leia mais sobre como escolher o tipo certo de trava.
Bibliotecas e integrações
Existem SDKs com suporte oficial para todas as principais linguagens, incluindo Java, .NET, NodeJS, Python, Go, Ruby e C. Você também encontrará bibliotecas de clientes desenvolvidas pela comunidade para linguagens como Erlang.
Da mesma forma, há integrações oficiais com Dados do Spring, Spark, Hadoop, Kafka, Talend, Elasticsearch e ODBC/JDBC, Linq2Couchbase para .NET, e há um NodeJS ODM chamado Ottoman. Se você usa atualmente o Mongoose para MongoDB, assista a este vídeo Vídeo sobre migração do MongoDB com Ottoman.js.
Conclusão
A mudança de um armazenamento de documentos para outro é relativamente simples, pois a forma geral dos dados não precisa mudar muito (ao contrário de uma migração relacional).
Como desenvolvedor que está fazendo a portabilidade de um aplicativo do MongoDB para o Couchbase Server, suas principais considerações são que você precisa:
- Substitua o espaçamento de nomes de coleções por nomes de chaves e tipos de documentos
- Simplifique suas consultas usando N1QL JOINs
- Considere onde o acesso a valores-chave pode ser a melhor opção.
Se você está mudando do MongoDB para o Couchbase Server, certamente não é o primeiro. Essa é uma ótima notícia para você, pois encontrará pessoas que já fizeram a mudança antes em os fóruns do Couchbase.
Se tiver alguma dúvida, comentário ou se encontrar algo impreciso, deixe um comentário ou entre em contato com eu no Twitter.