Um RDBMS com um esquema bem estabelecido serve bem quando as funções do aplicativo permanecem estáticas. Embora essa estrutura rígida possa garantir a estabilidade, ela não se presta a requisitos comerciais que mudam rapidamente. Atualmente, as organizações devem considerar a modernização de sua infraestrutura de aplicativos e a mudança do RDBMS para o NoSQL.
Este artigo analisa alguns benefícios do modelo de documento NoSQL e como os dados e os índices podem ser organizados para otimizar o desempenho da consulta e a configuração do índice. Também discutirei a estratégia de índice que você pode considerar ao migrar seu modelo de dados RDBMS para o banco de dados NoSQL do Couchbase e como o recurso FLATTEN_KEYS do Couchbase 7.1 pode ajudar a melhorar o desempenho da consulta e reduzir o número de índices.
Uma estratégia de índice eficaz é um dos fatores mais importantes na operação de um banco de dados. Ela nos ajuda a obter o equilíbrio certo entre o desempenho da consulta e o gerenciamento de recursos. O banco de dados não deve apenas capturar dados de forma eficiente, mas também fornecer o melhor acesso a esses dados. Os bancos de dados NoSQL não são diferentes dos RDBMS quando se trata de uma estratégia de índice eficaz.
Um caso de uso de RDBMS
Vamos considerar o hotel no objeto do Couchbase amostra de viagem conjunto de dados e suponha que usemos o modelo RDBMS para capturar essas informações. O modelo relacional teria a seguinte aparência:
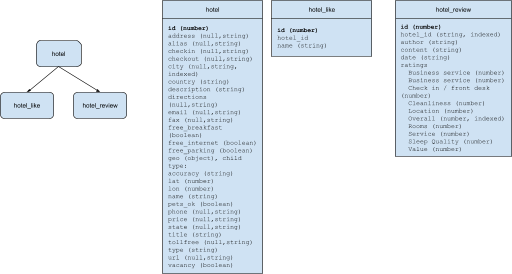
O hotel tem todas as informações detalhadas sobre o objeto hotel. Há também um tipo_de_hotel que registra os nomes dos clientes que clicaram em como na página de mídia social do hotel. Há também um revisão do hotel objeto que registra todas as avaliações de hotéis, incluindo comentários e classificações detalhadas dos diferentes serviços e comodidades.
Requisito comercial
Crie uma consulta para permitir que os usuários tenham uma visão resumida de todos os hotéis em uma determinada cidade que planejam visitar. O resumo deve incluir as classificações de avaliação de cada hotel e quantas pessoas já se hospedaram nele. gostou o hotel. Para restringir a lista, a consulta deve se concentrar nas avaliações recentes (2015 para esse conjunto de dados) e as classificações das avaliações devem ser de 4 ou mais (5 é a classificação mais alta).
A consulta do modelo relacional
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT h.name hotel, count(distinct l.name) liked_by, count(distinct r.author) review_author, avg(r.ratings.Overall) avg_ratings FROM hotel h INNER JOIN hotel_review r ON r.hotel_id = h.id INNER JOIN hotel_like l ON l.hotel_id = h.id WHERE h.city='London' AND r.ratings.Overall >= 4 AND r.date > '2015-01-01' GROUP BY h.name ORDER BY avg(r.ratings.Overall) DESC |
O índice para uma consulta de modelo relacional
hotel: Como há um filtro na cidade e no nome, deve haver um índice. Observe que o hotel id é anexado ao índice porque pode ajudar com o JOIN.
|
1 |
CREATE INDEX adv_city_name_id ON `hotel`(`city`,`name`,`id`) |
revisão do hotel: Há dois filtros nas avaliações de hotéis: a data da avaliação e as classificações da avaliação. Também é necessário eliminar a contagem dupla, pois não há relação explícita entre tipo_de_hotel e revisão do hotelPortanto, o autor da revisão é adicionado aqui para essa finalidade. O hotel_id também é adicionado ao índice porque é a chave estrangeira e pode ajudar com o JUNTAR.
|
1 |
CREATE INDEX adv_ratings_Overall_date_hotel_id_author ON `hotel_review`(`ratings`.`Overall`,`date`,`hotel_id`,`author`) |
revisão do hotel: Embora não haja filtros no tipo_de_hotelEm relação à avaliação, é necessário eliminar a contagem dupla de curtidas, pois não há relação entre avaliação e curtida. A hotel_id é adicionado ao índice porque é a chave estrangeira e pode ajudar no JOIN.
|
1 |
CREATE INDEX adv_hotel_id_name ON `hotel_like`(`hotel_id`,`name`) |
O plano de execução da consulta de modelo relacional
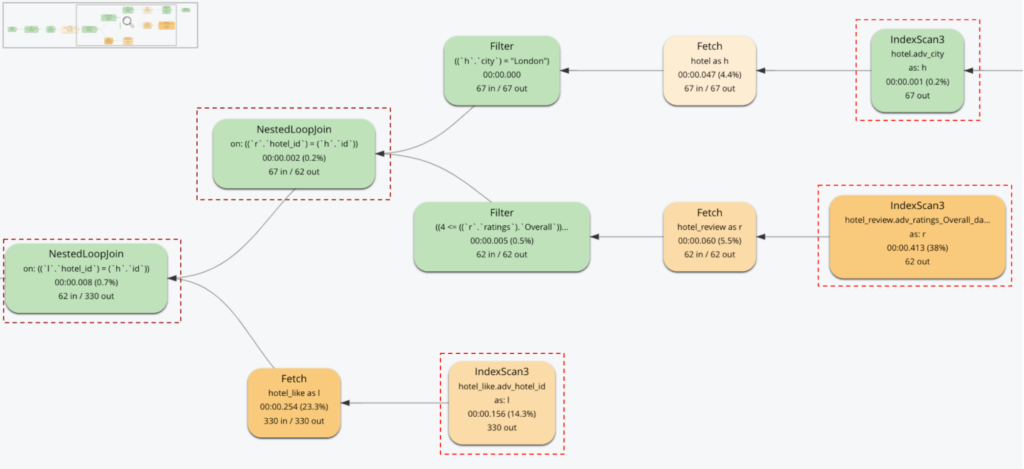
Observe a necessidade de desempenho:
-
- Dois JOINs
- Três varreduras de índice (uma para cada objeto)
A visualização do modelo de documento
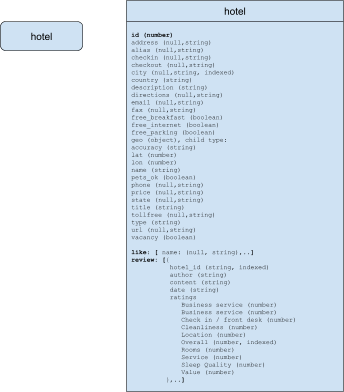
Para o modelo de documento, tanto o tipo_de_hotel e o revisão do hotel são armazenados como arrays no objeto hotel. Não há uma regra rígida que determine que você sempre deve incluir objetos filhos como uma matriz no objeto pai, mas faz sentido fazê-lo nesse caso porque esses objetos são sempre acessados juntos.
A consulta do modelo de documento desnormalizado
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT h.name hotel, COUNT(distinct l) liked_by, COUNT(distinct r.author) review_author, AVG(r.ratings.Overall) avg_ratings FROM hotel h UNNEST h.reviews AS r UNNEST h.public_likes AS l WHERE h.city='London' AND r.ratings.Overall >= 0 AND r.date > '2015-01-01' GROUP BY h.name ORDER BY avg(r.ratings.Overall) DESC |
O índice do modelo de documento desnormalizado
|
1 2 3 4 5 6 |
CREATE INDEX adv_ALL_reviews_ratings_Overall_date_city ON `hotel`( ALL ARRAY FLATTEN_KEYS(`r`.`ratings`.`Overall`,`r`.`date` DESC) FOR r IN `reviews` END, `city`) |
Alguns pontos a serem observados:
-
- O SQL++ faz referência a uma única consulta hotel portanto, não há necessidade de realizar nenhum JOIN explícito entre o objeto pai hotel e o objeto filho como ou rvisão geral
- A consulta usa um único índice que abrange todos os predicados da consulta, ou seja, o índice hotel.city, o comentários.classificaçõese o reviews.date
- Quando uma matriz é indexada, o índice só pode estar em uma única chave. FLATTEN_KEYS() permite campos compostos da matriz, permitindo assim que os predicados estejam em vários campos da matriz.
O plano de execução da consulta de modelo de documento

Observe a necessidade de realizar
-
- Dois UNNEST (não são necessários JOINs, pois estão em um único documento)
- Apenas uma varredura de índice
Resumo
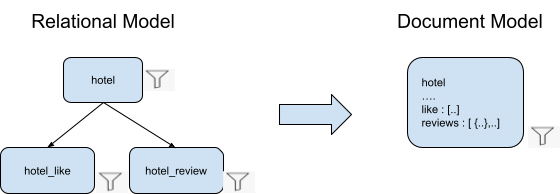
Quando um modelo relacional é desnormalizado em um único objeto no modelo de documento:
-
- A consulta SQL++ é mais simples porque não há necessidade de realizar nenhum JOIN
- Vários índices de modelos relacionais podem ser combinados em um único modelo de documento
- O recurso FLATTEN_KEYS do Couchbase 7.1 combina vários predicados de elementos de matriz em um único índice.
Esse é apenas um dos novos recursos que fornecemos recentemente - leia mais sobre O que há de novo no Couchbase Server 7.1.